 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePanoptic Video Scene Graph Generation
Nov 28, 2023Towards building comprehensive real-world visual perception systems, we propose and study a new problem called panoptic scene graph generation (PVSG). PVSG relates to the existing video scene graph generation (VidSGG) problem, which focuses on temporal interactions between humans and objects grounded with bounding boxes in videos. However, the limitation of bounding boxes in detecting non-rigid objects and backgrounds often causes VidSGG to miss key details crucial for comprehensive video understanding. In contrast, PVSG requires nodes in scene graphs to be grounded by more precise, pixel-level segmentation masks, which facilitate holistic scene understanding. To advance research in this new area, we contribute the PVSG dataset, which consists of 400 videos (289 third-person + 111 egocentric videos) with a total of 150K frames labeled with panoptic segmentation masks as well as fine, temporal scene graphs. We also provide a variety of baseline methods and share useful design practices for future work.
Octopus: Embodied Vision-Language Programmer from Environmental Feedback
Oct 12, 2023Large vision-language models (VLMs) have achieved substantial progress in multimodal perception and reasoning. Furthermore, when seamlessly integrated into an embodied agent, it signifies a crucial stride towards the creation of autonomous and context-aware systems capable of formulating plans and executing commands with precision. In this paper, we introduce Octopus, a novel VLM designed to proficiently decipher an agent's vision and textual task objectives and to formulate intricate action sequences and generate executable code. Our design allows the agent to adeptly handle a wide spectrum of tasks, ranging from mundane daily chores in simulators to sophisticated interactions in complex video games. Octopus is trained by leveraging GPT-4 to control an explorative agent to generate training data, i.e., action blueprints and the corresponding executable code, within our experimental environment called OctoVerse. We also collect the feedback that allows the enhanced training scheme of Reinforcement Learning with Environmental Feedback (RLEF). Through a series of experiments, we illuminate Octopus's functionality and present compelling results, and the proposed RLEF turns out to refine the agent's decision-making. By open-sourcing our model architecture, simulator, and dataset, we aspire to ignite further innovation and foster collaborative applications within the broader embodied AI community.
OpenOOD v1.5: Enhanced Benchmark for Out-of-Distribution Detection
Jun 17, 2023Out-of-Distribution (OOD) detection is critical for the reliable operation of open-world intelligent systems. Despite the emergence of an increasing number of OOD detection methods, the evaluation inconsistencies present challenges for tracking the progress in this field. OpenOOD v1 initiated the unification of the OOD detection evaluation but faced limitations in scalability and usability. In response, this paper presents OpenOOD v1.5, a significant improvement from its predecessor that ensures accurate, standardized, and user-friendly evaluation of OOD detection methodologies. Notably, OpenOOD v1.5 extends its evaluation capabilities to large-scale datasets such as ImageNet, investigates full-spectrum OOD detection which is important yet underexplored, and introduces new features including an online leaderboard and an easy-to-use evaluator. This work also contributes in-depth analysis and insights derived from comprehensive experimental results, thereby enriching the knowledge pool of OOD detection methodologies. With these enhancements, OpenOOD v1.5 aims to drive advancements and offer a more robust and comprehensive evaluation benchmark for OOD detection research.
Contextual Object Detection with Multimodal Large Language Models
May 29, 2023Recent Multimodal Large Language Models (MLLMs) are remarkable in vision-language tasks, such as image captioning and question answering, but lack the essential perception ability, i.e., object detection. In this work, we address this limitation by introducing a novel research problem of contextual object detection -- understanding visible objects within different human-AI interactive contexts. Three representative scenarios are investigated, including the language cloze test, visual captioning, and question answering. Moreover, we present ContextDET, a unified multimodal model that is capable of end-to-end differentiable modeling of visual-language contexts, so as to locate, identify, and associate visual objects with language inputs for human-AI interaction. Our ContextDET involves three key submodels: (i) a visual encoder for extracting visual representations, (ii) a pre-trained LLM for multimodal context decoding, and (iii) a visual decoder for predicting bounding boxes given contextual object words. The new generate-then-detect framework enables us to detect object words within human vocabulary. Extensive experiments show the advantages of ContextDET on our proposed CODE benchmark, open-vocabulary detection, and referring image segmentation. Github: https://github.com/yuhangzang/ContextDET.
Semi-Supervised and Long-Tailed Object Detection with CascadeMatch
May 24, 2023This paper focuses on long-tailed object detection in the semi-supervised learning setting, which poses realistic challenges, but has rarely been studied in the literature. We propose a novel pseudo-labeling-based detector called CascadeMatch. Our detector features a cascade network architecture, which has multi-stage detection heads with progressive confidence thresholds. To avoid manually tuning the thresholds, we design a new adaptive pseudo-label mining mechanism to automatically identify suitable values from data. To mitigate confirmation bias, where a model is negatively reinforced by incorrect pseudo-labels produced by itself, each detection head is trained by the ensemble pseudo-labels of all detection heads. Experiments on two long-tailed datasets, i.e., LVIS and COCO-LT, demonstrate that CascadeMatch surpasses existing state-of-the-art semi-supervised approaches -- across a wide range of detection architectures -- in handling long-tailed object detection. For instance, CascadeMatch outperforms Unbiased Teacher by 1.9 AP Fix on LVIS when using a ResNet50-based Cascade R-CNN structure, and by 1.7 AP Fix when using Sparse R-CNN with a Transformer encoder. We also show that CascadeMatch can even handle the challenging sparsely annotated object detection problem.
What Makes Good Examples for Visual In-Context Learning?
Feb 01, 2023



Large-scale models trained on broad data have recently become the mainstream architecture in computer vision due to their strong generalization performance. In this paper, the main focus is on an emergent ability in large vision models, known as in-context learning, which allows inference on unseen tasks by conditioning on in-context examples (a.k.a.~prompt) without updating the model parameters. This concept has been well-known in natural language processing but has only been studied very recently for large vision models. We for the first time provide a comprehensive investigation on the impact of in-context examples in computer vision, and find that the performance is highly sensitive to the choice of in-context examples. To overcome the problem, we propose a prompt retrieval framework to automate the selection of in-context examples. Specifically, we present (1) an unsupervised prompt retrieval method based on nearest example search using an off-the-shelf model, and (2) a supervised prompt retrieval method, which trains a neural network to choose examples that directly maximize in-context learning performance. The results demonstrate that our methods can bring non-trivial improvements to visual in-context learning in comparison to the commonly-used random selection.
Learning to Augment via Implicit Differentiation for Domain Generalization
Oct 25, 2022Machine learning models are intrinsically vulnerable to domain shift between training and testing data, resulting in poor performance in novel domains. Domain generalization (DG) aims to overcome the problem by leveraging multiple source domains to learn a domain-generalizable model. In this paper, we propose a novel augmentation-based DG approach, dubbed AugLearn. Different from existing data augmentation methods, our AugLearn views a data augmentation module as hyper-parameters of a classification model and optimizes the module together with the model via meta-learning. Specifically, at each training step, AugLearn (i) divides source domains into a pseudo source and a pseudo target set, and (ii) trains the augmentation module in such a way that the augmented (synthetic) images can make the model generalize well on the pseudo target set. Moreover, to overcome the expensive second-order gradient computation during meta-learning, we formulate an efficient joint training algorithm, for both the augmentation module and the classification model, based on the implicit function theorem. With the flexibility of augmenting data in both time and frequency spaces, AugLearn shows effectiveness on three standard DG benchmarks, PACS, Office-Home and Digits-DG.
OpenOOD: Benchmarking Generalized Out-of-Distribution Detection
Oct 13, 2022
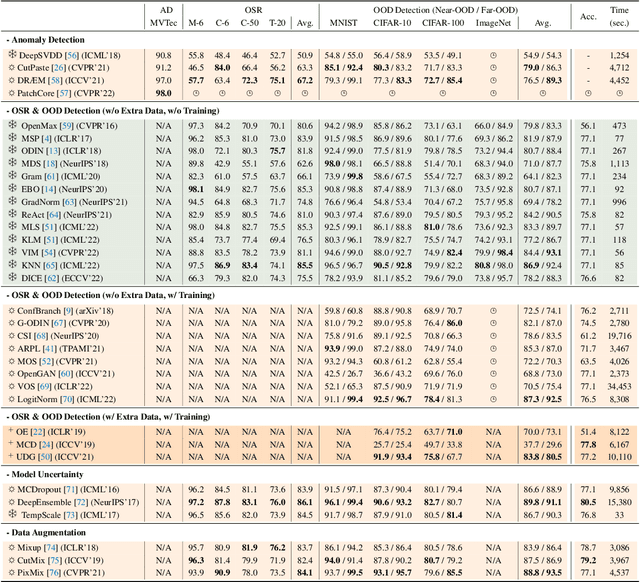
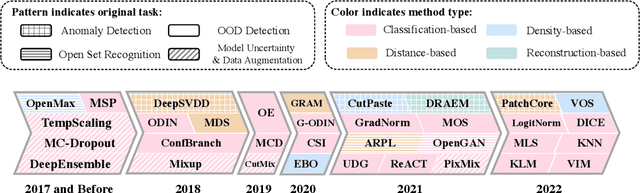
Out-of-distribution (OOD) detection is vital to safety-critical machine learning applications and has thus been extensively studied, with a plethora of methods developed in the literature. However, the field currently lacks a unified, strictly formulated, and comprehensive benchmark, which often results in unfair comparisons and inconclusive results. From the problem setting perspective, OOD detection is closely related to neighboring fields including anomaly detection (AD), open set recognition (OSR), and model uncertainty, since methods developed for one domain are often applicable to each other. To help the community to improve the evaluation and advance, we build a unified, well-structured codebase called OpenOOD, which implements over 30 methods developed in relevant fields and provides a comprehensive benchmark under the recently proposed generalized OOD detection framework. With a comprehensive comparison of these methods, we are gratified that the field has progressed significantly over the past few years, where both preprocessing methods and the orthogonal post-hoc methods show strong potential.
Unified Vision and Language Prompt Learning
Oct 13, 2022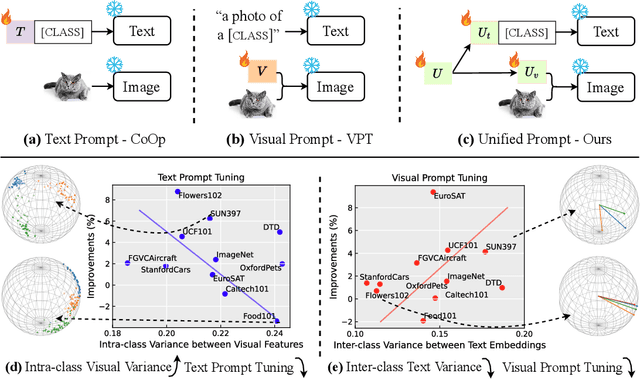
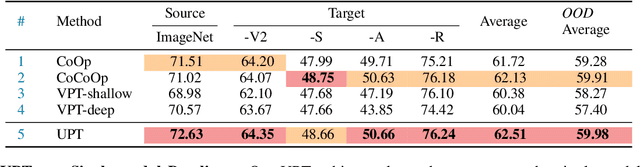
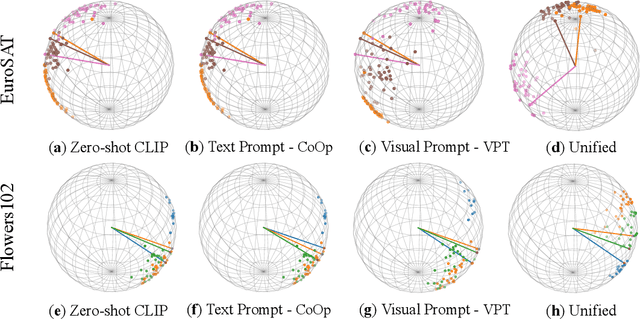
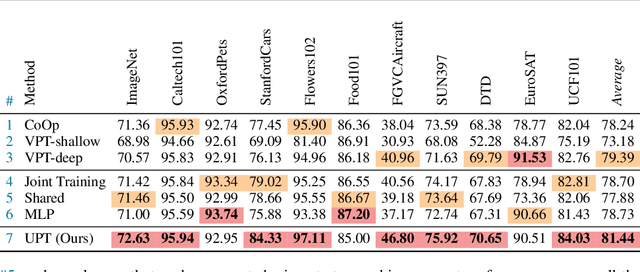
Prompt tuning, a parameter- and data-efficient transfer learning paradigm that tunes only a small number of parameters in a model's input space, has become a trend in the vision community since the emergence of large vision-language models like CLIP. We present a systematic study on two representative prompt tuning methods, namely text prompt tuning and visual prompt tuning. A major finding is that none of the unimodal prompt tuning methods performs consistently well: text prompt tuning fails on data with high intra-class visual variances while visual prompt tuning cannot handle low inter-class variances. To combine the best from both worlds, we propose a simple approach called Unified Prompt Tuning (UPT), which essentially learns a tiny neural network to jointly optimize prompts across different modalities. Extensive experiments on over 11 vision datasets show that UPT achieves a better trade-off than the unimodal counterparts on few-shot learning benchmarks, as well as on domain generalization benchmarks. Code and models will be released to facilitate future research.
On-Device Domain Generalization
Sep 15, 2022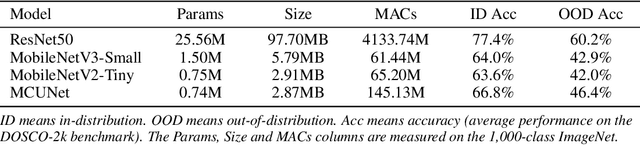
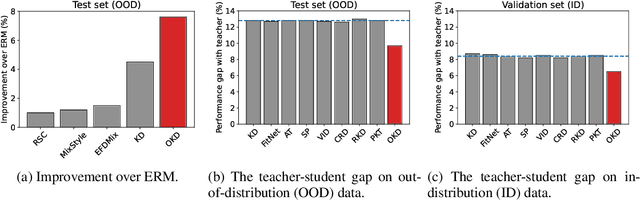
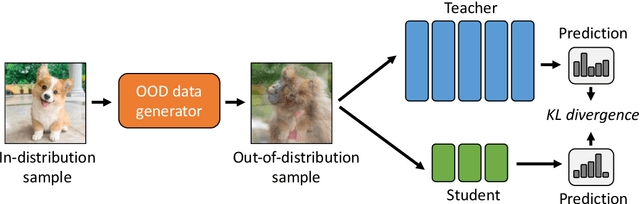
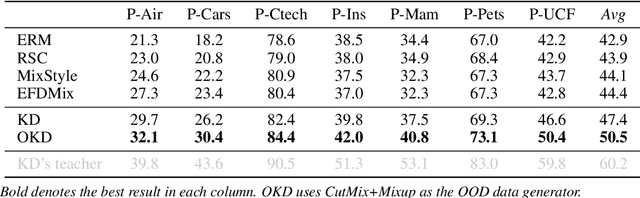
We present a systematic study of domain generalization (DG) for tiny neural networks, a problem that is critical to on-device machine learning applications but has been overlooked in the literature where research has been focused on large models only. Tiny neural networks have much fewer parameters and lower complexity, and thus should not be trained the same way as their large counterparts for DG applications. We find that knowledge distillation is a strong candidate for solving the problem: it outperforms state-of-the-art DG methods that were developed using large models with a large margin. Moreover, we observe that the teacher-student performance gap on test data with domain shift is bigger than that on in-distribution data. To improve DG for tiny neural networks without increasing the deployment cost, we propose a simple idea called out-of-distribution knowledge distillation (OKD), which aims to teach the student how the teacher handles (synthetic) out-of-distribution data and is proved to be a promising framework for solving the problem. We also contribute a scalable method of creating DG datasets, called DOmain Shift in COntext (DOSCO), which can be applied to broad data at scale without much human effort. Code and models are released at \url{https://github.com/KaiyangZhou/on-device-dg}.