 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKaixiong Zhou
Compress, Then Prompt: Improving Accuracy-Efficiency Trade-off of LLM Inference with Transferable Prompt
May 17, 2023
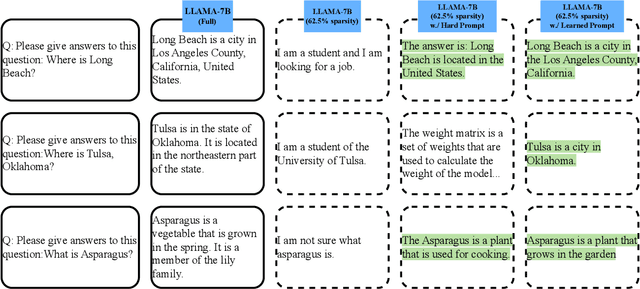
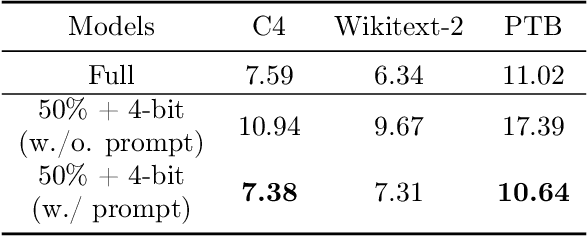
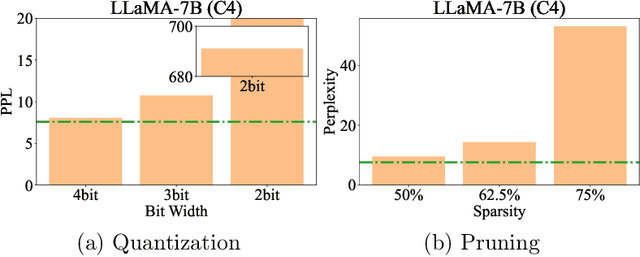
Large Language Models (LLMs), armed with billions of parameters, exhibit exceptional performance across a wide range of Natural Language Processing (NLP) tasks. However, they present a significant computational challenge during inference, especially when deploying on common hardware such as single GPUs. As such, minimizing the latency of LLM inference by curtailing computational and memory requirements, though achieved through compression, becomes critically important. However, this process inevitably instigates a trade-off between efficiency and accuracy, as compressed LLMs typically experience a reduction in predictive precision. In this research, we introduce an innovative perspective: to optimize this trade-off, compressed LLMs require a unique input format that varies from that of the original models. Our findings indicate that the generation quality in a compressed LLM can be markedly improved for specific queries by selecting prompts with precision. Capitalizing on this insight, we introduce a prompt learning paradigm that cultivates an additive prompt over a compressed LLM to bolster their accuracy. Our empirical results imply that through our strategic prompt utilization, compressed LLMs can match, and occasionally even exceed, the accuracy of the original models. Moreover, we demonstrated that these learned prompts have a certain degree of transferability across various datasets, tasks, and compression levels. These insights shine a light on new possibilities for enhancing the balance between accuracy and efficiency in LLM inference. Specifically, they underscore the importance of judicious input editing to a compressed large model, hinting at potential advancements in scaling LLMs on common hardware.
Context-aware Domain Adaptation for Time Series Anomaly Detection
Apr 15, 2023
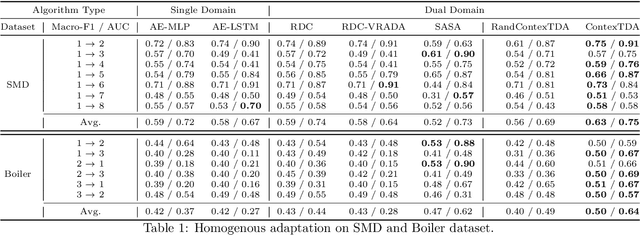
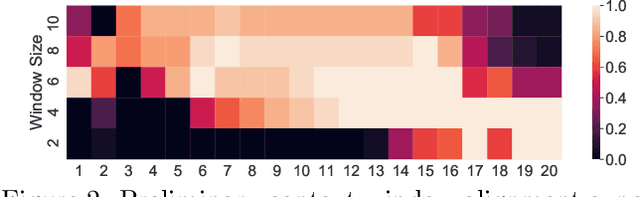

Time series anomaly detection is a challenging task with a wide range of real-world applications. Due to label sparsity, training a deep anomaly detector often relies on unsupervised approaches. Recent efforts have been devoted to time series domain adaptation to leverage knowledge from similar domains. However, existing solutions may suffer from negative knowledge transfer on anomalies due to their diversity and sparsity. Motivated by the empirical study of context alignment between two domains, we aim to transfer knowledge between two domains via adaptively sampling context information for two domains. This is challenging because it requires simultaneously modeling the complex in-domain temporal dependencies and cross-domain correlations while exploiting label information from the source domain. To this end, we propose a framework that combines context sampling and anomaly detection into a joint learning procedure. We formulate context sampling into the Markov decision process and exploit deep reinforcement learning to optimize the time series domain adaptation process via context sampling and design a tailored reward function to generate domain-invariant features that better align two domains for anomaly detection. Experiments on three public datasets show promise for knowledge transfer between two similar domains and two entirely different domains.
A Survey of Graph Prompting Methods: Techniques, Applications, and Challenges
Mar 13, 2023

While deep learning has achieved great success on various tasks, the task-specific model training notoriously relies on a large volume of labeled data. Recently, a new training paradigm of ``pre-train, prompt, predict'' has been proposed to improve model generalization ability with limited labeled data. The main idea is that, based on a pre-trained model, the prompting function uses a template to augment input samples with indicative context and reformalizes the target task to one of the pre-training tasks. In this survey, we provide a unique review of prompting methods from the graph perspective. Graph data has served as structured knowledge repositories in various systems by explicitly modeling the interaction between entities. Compared with traditional methods, graph prompting functions could induce task-related context and apply templates with structured knowledge. The pre-trained model is then adaptively generalized for future samples. In particular, we introduce the basic concepts of graph prompt learning, organize the existing work of designing graph prompting functions, and describe their applications and challenges to a variety of machine learning problems. This survey attempts to bridge the gap between structured graphs and prompt design to facilitate future methodology development.
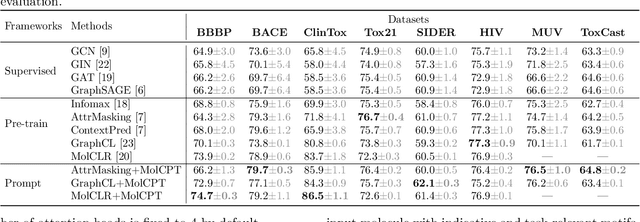
MolCPT: Molecule Continuous Prompt Tuning to Generalize Molecular Representation Learning
Dec 20, 2022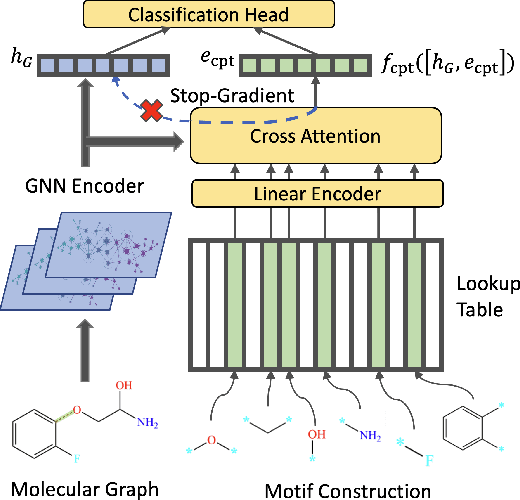
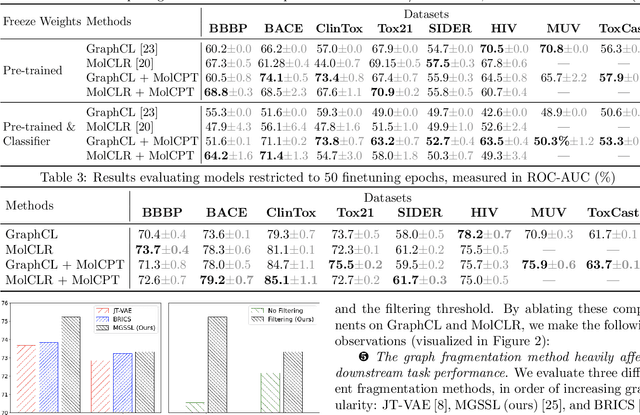

Molecular representation learning is crucial for the problem of molecular property prediction, where graph neural networks (GNNs) serve as an effective solution due to their structure modeling capabilities. Since labeled data is often scarce and expensive to obtain, it is a great challenge for GNNs to generalize in the extensive molecular space. Recently, the training paradigm of "pre-train, fine-tune" has been leveraged to improve the generalization capabilities of GNNs. It uses self-supervised information to pre-train the GNN, and then performs fine-tuning to optimize the downstream task with just a few labels. However, pre-training does not always yield statistically significant improvement, especially for self-supervised learning with random structural masking. In fact, the molecular structure is characterized by motif subgraphs, which are frequently occurring and influence molecular properties. To leverage the task-related motifs, we propose a novel paradigm of "pre-train, prompt, fine-tune" for molecular representation learning, named molecule continuous prompt tuning (MolCPT). MolCPT defines a motif prompting function that uses the pre-trained model to project the standalone input into an expressive prompt. The prompt effectively augments the molecular graph with meaningful motifs in the continuous representation space; this provides more structural patterns to aid the downstream classifier in identifying molecular properties. Extensive experiments on several benchmark datasets show that MolCPT efficiently generalizes pre-trained GNNs for molecular property prediction, with or without a few fine-tuning steps.
TinyKG: Memory-Efficient Training Framework for Knowledge Graph Neural Recommender Systems
Dec 08, 2022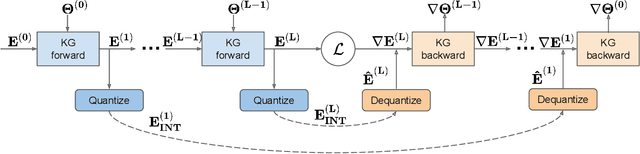
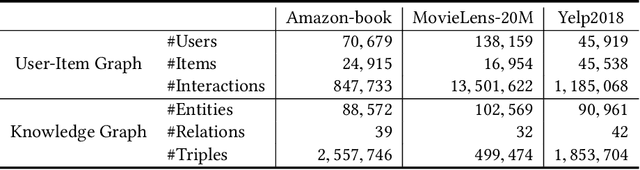
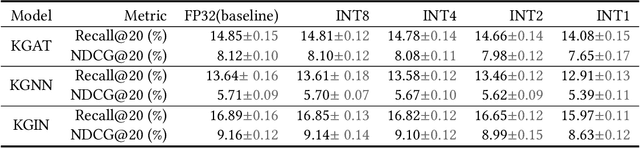
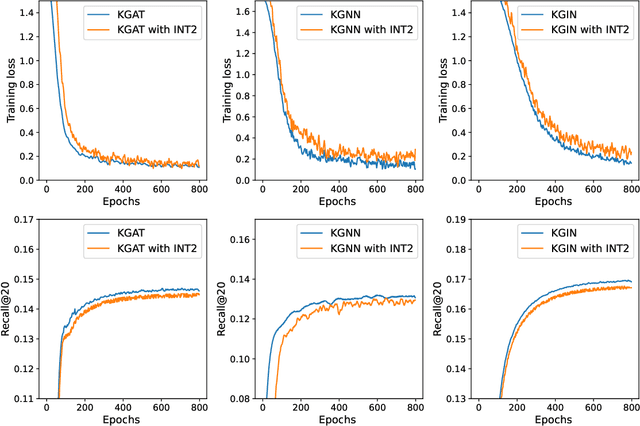
There has been an explosion of interest in designing various Knowledge Graph Neural Networks (KGNNs), which achieve state-of-the-art performance and provide great explainability for recommendation. The promising performance is mainly resulting from their capability of capturing high-order proximity messages over the knowledge graphs. However, training KGNNs at scale is challenging due to the high memory usage. In the forward pass, the automatic differentiation engines (\textsl{e.g.}, TensorFlow/PyTorch) generally need to cache all intermediate activation maps in order to compute gradients in the backward pass, which leads to a large GPU memory footprint. Existing work solves this problem by utilizing multi-GPU distributed frameworks. Nonetheless, this poses a practical challenge when seeking to deploy KGNNs in memory-constrained environments, especially for industry-scale graphs. Here we present TinyKG, a memory-efficient GPU-based training framework for KGNNs for the tasks of recommendation. Specifically, TinyKG uses exact activations in the forward pass while storing a quantized version of activations in the GPU buffers. During the backward pass, these low-precision activations are dequantized back to full-precision tensors, in order to compute gradients. To reduce the quantization errors, TinyKG applies a simple yet effective quantization algorithm to compress the activations, which ensures unbiasedness with low variance. As such, the training memory footprint of KGNNs is largely reduced with negligible accuracy loss. To evaluate the performance of our TinyKG, we conduct comprehensive experiments on real-world datasets. We found that our TinyKG with INT2 quantization aggressively reduces the memory footprint of activation maps with $7 \times$, only with $2\%$ loss in accuracy, allowing us to deploy KGNNs on memory-constrained devices.
QuanGCN: Noise-Adaptive Training for Robust Quantum Graph Convolutional Networks
Nov 09, 2022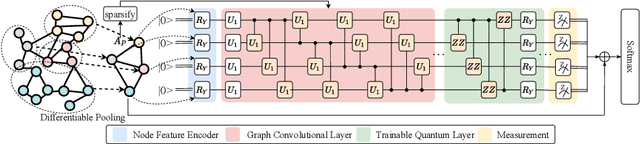
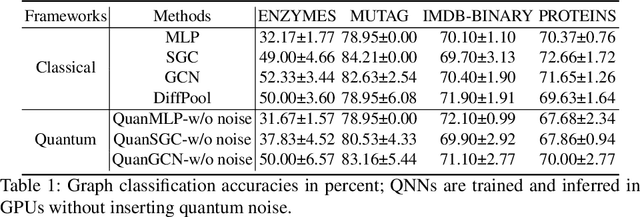
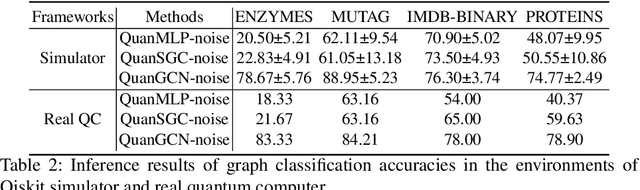
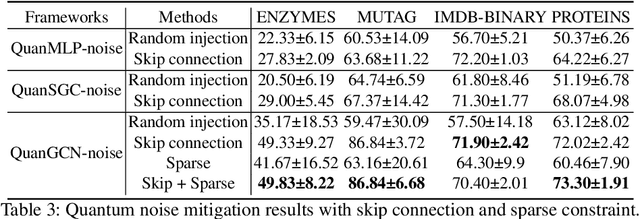
Quantum neural networks (QNNs), an interdisciplinary field of quantum computing and machine learning, have attracted tremendous research interests due to the specific quantum advantages. Despite lots of efforts developed in computer vision domain, one has not fully explored QNNs for the real-world graph property classification and evaluated them in the quantum device. To bridge the gap, we propose quantum graph convolutional networks (QuanGCN), which learns the local message passing among nodes with the sequence of crossing-gate quantum operations. To mitigate the inherent noises from modern quantum devices, we apply sparse constraint to sparsify the nodes' connections and relieve the error rate of quantum gates, and use skip connection to augment the quantum outputs with original node features to improve robustness. The experimental results show that our QuanGCN is functionally comparable or even superior than the classical algorithms on several benchmark graph datasets. The comprehensive evaluations in both simulator and real quantum machines demonstrate the applicability of QuanGCN to the future graph analysis problem.
RSC: Accelerating Graph Neural Networks Training via Randomized Sparse Computations
Oct 19, 2022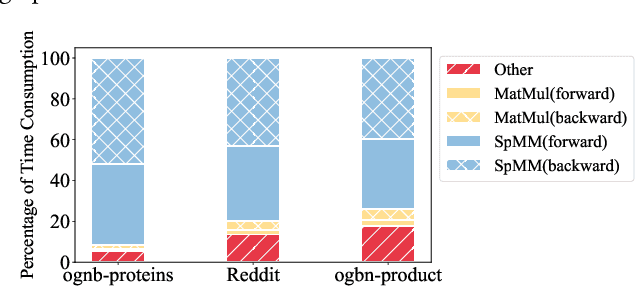

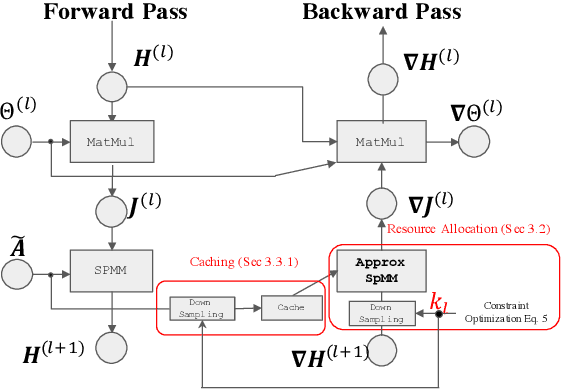
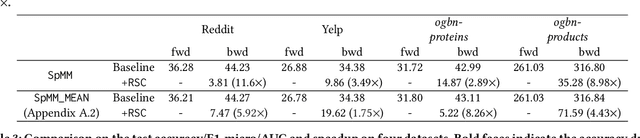
The training of graph neural networks (GNNs) is extremely time consuming because sparse graph-based operations are hard to be accelerated by hardware. Prior art explores trading off the computational precision to reduce the time complexity via sampling-based approximation. Based on the idea, previous works successfully accelerate the dense matrix based operations (e.g., convolution and linear) with negligible accuracy drop. However, unlike dense matrices, sparse matrices are stored in the irregular data format such that each row/column may have different number of non-zero entries. Thus, compared to the dense counterpart, approximating sparse operations has two unique challenges (1) we cannot directly control the efficiency of approximated sparse operation since the computation is only executed on non-zero entries; (2) sub-sampling sparse matrices is much more inefficient due to the irregular data format. To address the issues, our key idea is to control the accuracy-efficiency trade off by optimizing computation resource allocation layer-wisely and epoch-wisely. Specifically, for the first challenge, we customize the computation resource to different sparse operations, while limit the total used resource below a certain budget. For the second challenge, we cache previous sampled sparse matrices to reduce the epoch-wise sampling overhead. Finally, we propose a switching mechanisms to improve the generalization of GNNs trained with approximated operations. To this end, we propose Randomized Sparse Computation, which for the first time demonstrate the potential of training GNNs with approximated operations. In practice, rsc can achieve up to $11.6\times$ speedup for a single sparse operation and a $1.6\times$ end-to-end wall-clock time speedup with negligible accuracy drop.
A Comprehensive Study on Large-Scale Graph Training: Benchmarking and Rethinking
Oct 14, 2022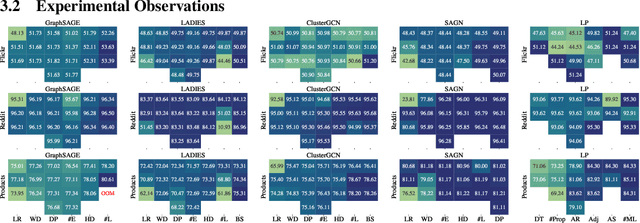
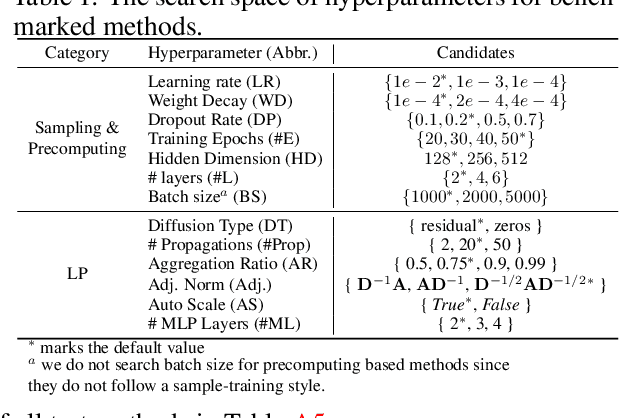

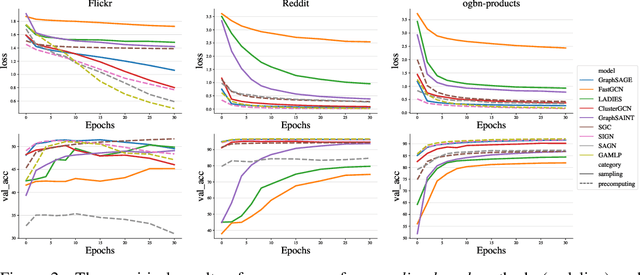
Large-scale graph training is a notoriously challenging problem for graph neural networks (GNNs). Due to the nature of evolving graph structures into the training process, vanilla GNNs usually fail to scale up, limited by the GPU memory space. Up to now, though numerous scalable GNN architectures have been proposed, we still lack a comprehensive survey and fair benchmark of this reservoir to find the rationale for designing scalable GNNs. To this end, we first systematically formulate the representative methods of large-scale graph training into several branches and further establish a fair and consistent benchmark for them by a greedy hyperparameter searching. In addition, regarding efficiency, we theoretically evaluate the time and space complexity of various branches and empirically compare them w.r.t GPU memory usage, throughput, and convergence. Furthermore, We analyze the pros and cons for various branches of scalable GNNs and then present a new ensembling training manner, named EnGCN, to address the existing issues. Remarkably, our proposed method has achieved new state-of-the-art (SOTA) performance on large-scale datasets. Our code is available at https://github.com/VITA-Group/Large_Scale_GCN_Benchmarking.
Differentially Private Counterfactuals via Functional Mechanism
Aug 04, 2022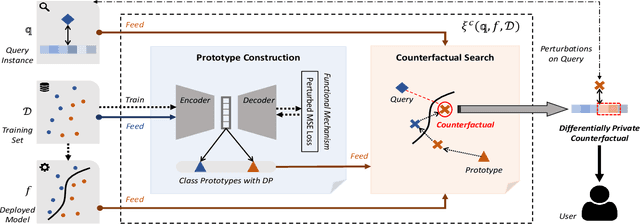
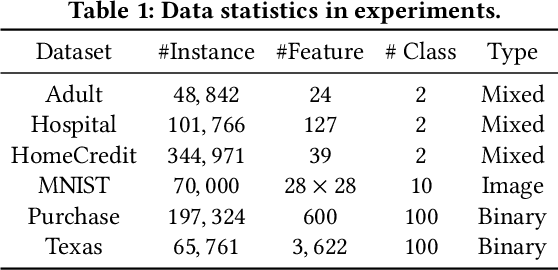
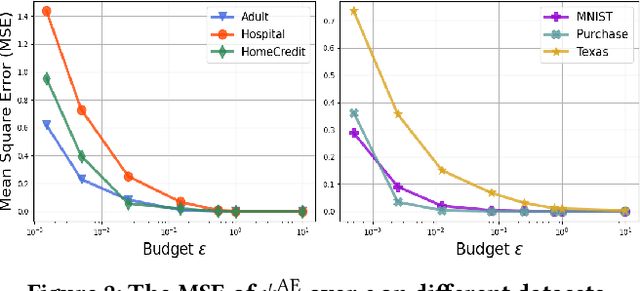
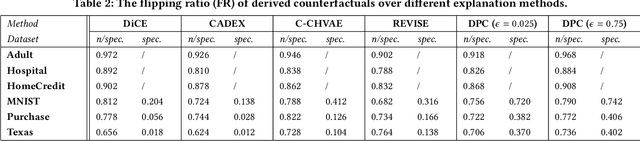
Counterfactual, serving as one emerging type of model explanation, has attracted tons of attentions recently from both industry and academia. Different from the conventional feature-based explanations (e.g., attributions), counterfactuals are a series of hypothetical samples which can flip model decisions with minimal perturbations on queries. Given valid counterfactuals, humans are capable of reasoning under ``what-if'' circumstances, so as to better understand the model decision boundaries. However, releasing counterfactuals could be detrimental, since it may unintentionally leak sensitive information to adversaries, which brings about higher risks on both model security and data privacy. To bridge the gap, in this paper, we propose a novel framework to generate differentially private counterfactual (DPC) without touching the deployed model or explanation set, where noises are injected for protection while maintaining the explanation roles of counterfactual. In particular, we train an autoencoder with the functional mechanism to construct noisy class prototypes, and then derive the DPC from the latent prototypes based on the post-processing immunity of differential privacy. Further evaluations demonstrate the effectiveness of the proposed framework, showing that DPC can successfully relieve the risks on both extraction and inference attacks.
Towards Similarity-Aware Time-Series Classification
Jan 06, 2022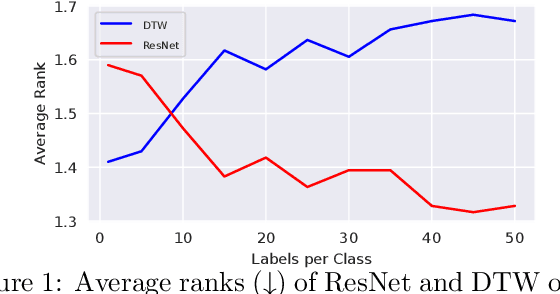

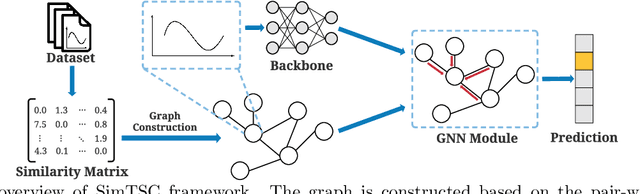
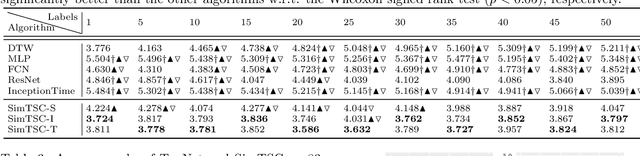
We study time-series classification (TSC), a fundamental task of time-series data mining. Prior work has approached TSC from two major directions: (1) similarity-based methods that classify time-series based on the nearest neighbors, and (2) deep learning models that directly learn the representations for classification in a data-driven manner. Motivated by the different working mechanisms within these two research lines, we aim to connect them in such a way as to jointly model time-series similarities and learn the representations. This is a challenging task because it is unclear how we should efficiently leverage similarity information. To tackle the challenge, we propose Similarity-Aware Time-Series Classification (SimTSC), a conceptually simple and general framework that models similarity information with graph neural networks (GNNs). Specifically, we formulate TSC as a node classification problem in graphs, where the nodes correspond to time-series, and the links correspond to pair-wise similarities. We further design a graph construction strategy and a batch training algorithm with negative sampling to improve training efficiency. We instantiate SimTSC with ResNet as the backbone and Dynamic Time Warping (DTW) as the similarity measure. Extensive experiments on the full UCR datasets and several multivariate datasets demonstrate the effectiveness of incorporating similarity information into deep learning models in both supervised and semi-supervised settings. Our code is available at https://github.com/daochenzha/SimTSC