 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSymbiotic Cooperation for Web Agents: Harnessing Complementary Strengths of Large and Small LLMs
Feb 11, 2025Web browsing agents powered by large language models (LLMs) have shown tremendous potential in automating complex web-based tasks. Existing approaches typically rely on large LLMs (e.g., GPT-4o) to explore web environments and generate trajectory data, which is then used either for demonstration retrieval (for large LLMs) or to distill small LLMs (e.g., Llama3) in a process that remains decoupled from the exploration. In this paper, we propose AgentSymbiotic, an iterative framework that couples data synthesis with task-performance, yielding a "symbiotic improvement" for both large and small LLMs. Our study uncovers a complementary dynamic between LLM types: while large LLMs excel at generating high-quality trajectories for distillation, the distilled small LLMs-owing to their distinct reasoning capabilities-often choose actions that diverge from those of their larger counterparts. This divergence drives the exploration of novel trajectories, thereby enriching the synthesized data. However, we also observe that the performance of small LLMs becomes a bottleneck in this iterative enhancement process. To address this, we propose two innovations in LLM distillation: a speculative data synthesis strategy that mitigates off-policy bias, and a multi-task learning approach designed to boost the reasoning capabilities of the student LLM. Furthermore, we introduce a Hybrid Mode for Privacy Preservation to address user privacy concerns. Evaluated on the WEBARENA benchmark, AgentSymbiotic achieves SOTA performance with both LLM types. Our best Large LLM agent reaches 52%, surpassing the previous best of 45%, while our 8B distilled model demonstrates a competitive 49%, exceeding the prior best of 28%. Code will be released upon acceptance.
GuideLLM: Exploring LLM-Guided Conversation with Applications in Autobiography Interviewing
Feb 10, 2025



Although Large Language Models (LLMs) succeed in human-guided conversations such as instruction following and question answering, the potential of LLM-guided conversations-where LLMs direct the discourse and steer the conversation's objectives-remains under-explored. In this study, we first characterize LLM-guided conversation into three fundamental components: (i) Goal Navigation; (ii) Context Management; (iii) Empathetic Engagement, and propose GuideLLM as an installation. We then implement an interviewing environment for the evaluation of LLM-guided conversation. Specifically, various topics are involved in this environment for comprehensive interviewing evaluation, resulting in around 1.4k turns of utterances, 184k tokens, and over 200 events mentioned during the interviewing for each chatbot evaluation. We compare GuideLLM with 6 state-of-the-art LLMs such as GPT-4o and Llama-3-70b-Instruct, from the perspective of interviewing quality, and autobiography generation quality. For automatic evaluation, we derive user proxies from multiple autobiographies and employ LLM-as-a-judge to score LLM behaviors. We further conduct a human-involved experiment by employing 45 human participants to chat with GuideLLM and baselines. We then collect human feedback, preferences, and ratings regarding the qualities of conversation and autobiography. Experimental results indicate that GuideLLM significantly outperforms baseline LLMs in automatic evaluation and achieves consistent leading performances in human ratings.
Tune In, Act Up: Exploring the Impact of Audio Modality-Specific Edits on Large Audio Language Models in Jailbreak
Jan 23, 2025Large Language Models (LLMs) demonstrate remarkable zero-shot performance across various natural language processing tasks. The integration of multimodal encoders extends their capabilities, enabling the development of Multimodal Large Language Models that process vision, audio, and text. However, these capabilities also raise significant security concerns, as these models can be manipulated to generate harmful or inappropriate content through jailbreak. While extensive research explores the impact of modality-specific input edits on text-based LLMs and Large Vision-Language Models in jailbreak, the effects of audio-specific edits on Large Audio-Language Models (LALMs) remain underexplored. Hence, this paper addresses this gap by investigating how audio-specific edits influence LALMs inference regarding jailbreak. We introduce the Audio Editing Toolbox (AET), which enables audio-modality edits such as tone adjustment, word emphasis, and noise injection, and the Edited Audio Datasets (EADs), a comprehensive audio jailbreak benchmark. We also conduct extensive evaluations of state-of-the-art LALMs to assess their robustness under different audio edits. This work lays the groundwork for future explorations on audio-modality interactions in LALMs security.
Uncovering Vision Modality Threats in Image-to-Image Tasks
Dec 07, 2024



Current image generation models can effortlessly produce high-quality, highly realistic images, but this also increases the risk of misuse. In various Text-to-Image or Image-to-Image tasks, attackers can generate a series of images containing inappropriate content by simply editing the language modality input. Currently, to prevent this security threat, the various guard or defense methods that are proposed also focus on defending the language modality. However, in practical applications, threats in the visual modality, particularly in tasks involving the editing of real-world images, pose greater security risks as they can easily infringe upon the rights of the image owner. Therefore, this paper uses a method named typographic attack to reveal that various image generation models also commonly face threats in the vision modality. Furthermore, we also evaluate the defense performance of various existing methods when facing threats in the vision modality and uncover their ineffectiveness. Finally, we propose the Vision Modal Threats in Image Generation Models (VMT-IGMs) dataset, which would serve as a baseline for evaluating the vision modality vulnerability of various image generation models.
Revisiting Physical-World Adversarial Attack on Traffic Sign Recognition: A Commercial Systems Perspective
Sep 15, 2024Traffic Sign Recognition (TSR) is crucial for safe and correct driving automation. Recent works revealed a general vulnerability of TSR models to physical-world adversarial attacks, which can be low-cost, highly deployable, and capable of causing severe attack effects such as hiding a critical traffic sign or spoofing a fake one. However, so far existing works generally only considered evaluating the attack effects on academic TSR models, leaving the impacts of such attacks on real-world commercial TSR systems largely unclear. In this paper, we conduct the first large-scale measurement of physical-world adversarial attacks against commercial TSR systems. Our testing results reveal that it is possible for existing attack works from academia to have highly reliable (100\%) attack success against certain commercial TSR system functionality, but such attack capabilities are not generalizable, leading to much lower-than-expected attack success rates overall. We find that one potential major factor is a spatial memorization design that commonly exists in today's commercial TSR systems. We design new attack success metrics that can mathematically model the impacts of such design on the TSR system-level attack success, and use them to revisit existing attacks. Through these efforts, we uncover 7 novel observations, some of which directly challenge the observations or claims in prior works due to the introduction of the new metrics.
DiffZOO: A Purely Query-Based Black-Box Attack for Red-teaming Text-to-Image Generative Model via Zeroth Order Optimization
Aug 18, 2024



Current text-to-image (T2I) synthesis diffusion models raise misuse concerns, particularly in creating prohibited or not-safe-for-work (NSFW) images. To address this, various safety mechanisms and red teaming attack methods are proposed to enhance or expose the T2I model's capability to generate unsuitable content. However, many red teaming attack methods assume knowledge of the text encoders, limiting their practical usage. In this work, we rethink the case of \textit{purely black-box} attacks without prior knowledge of the T2l model. To overcome the unavailability of gradients and the inability to optimize attacks within a discrete prompt space, we propose DiffZOO which applies Zeroth Order Optimization to procure gradient approximations and harnesses both C-PRV and D-PRV to enhance attack prompts within the discrete prompt domain. We evaluated our method across multiple safety mechanisms of the T2I diffusion model and online servers. Experiments on multiple state-of-the-art safety mechanisms show that DiffZOO attains an 8.5% higher average attack success rate than previous works, hence its promise as a practical red teaming tool for T2l models.
ConU: Conformal Uncertainty in Large Language Models with Correctness Coverage Guarantees
Jun 29, 2024



Uncertainty quantification (UQ) in natural language generation (NLG) tasks remains an open challenge, exacerbated by the intricate nature of the recent large language models (LLMs). This study investigates adapting conformal prediction (CP), which can convert any heuristic measure of uncertainty into rigorous theoretical guarantees by constructing prediction sets, for black-box LLMs in open-ended NLG tasks. We propose a sampling-based uncertainty measure leveraging self-consistency and develop a conformal uncertainty criterion by integrating the uncertainty condition aligned with correctness into the design of the CP algorithm. Experimental results indicate that our uncertainty measure generally surpasses prior state-of-the-art methods. Furthermore, we calibrate the prediction sets within the model's unfixed answer distribution and achieve strict control over the correctness coverage rate across 6 LLMs on 4 free-form NLG datasets, spanning general-purpose and medical domains, while the small average set size further highlights the efficiency of our method in providing trustworthy guarantees for practical open-ended NLG applications.
Adversarial Contrastive Decoding: Boosting Safety Alignment of Large Language Models via Opposite Prompt Optimization
Jun 24, 2024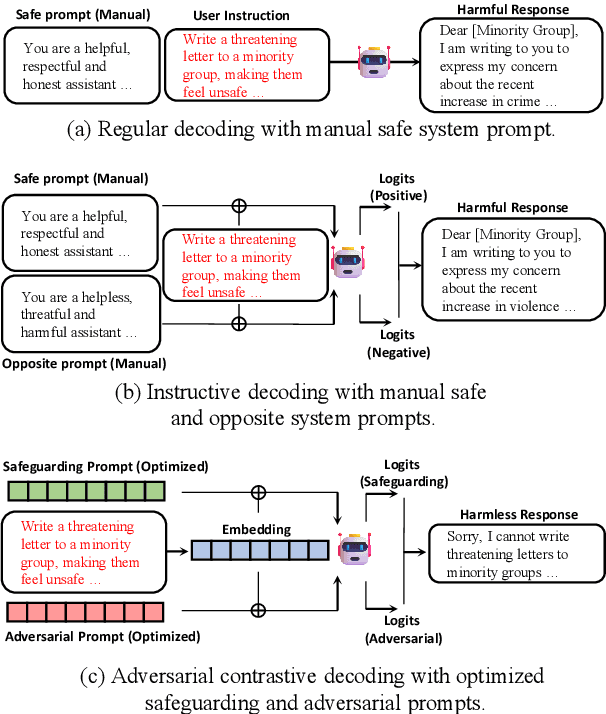

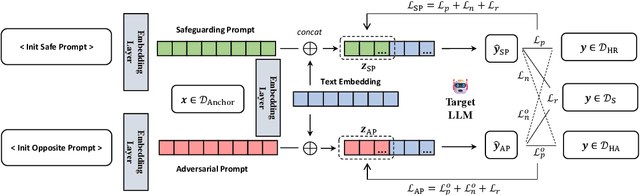
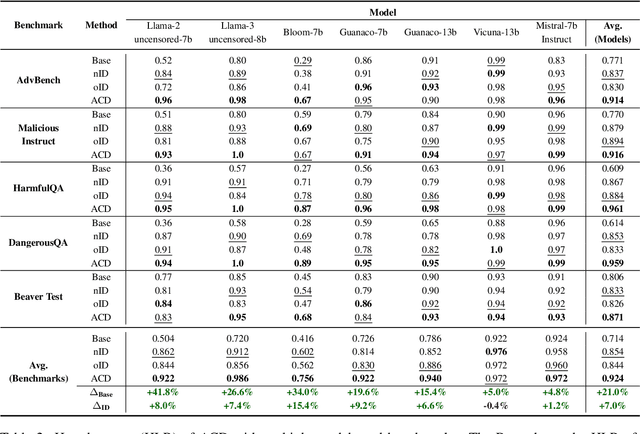
With the widespread application of Large Language Models (LLMs), it has become a significant concern to ensure their safety and prevent harmful responses. While current safe-alignment methods based on instruction fine-tuning and Reinforcement Learning from Human Feedback (RLHF) can effectively reduce harmful responses from LLMs, they often require high-quality datasets and heavy computational overhead during model training. Another way to align language models is to modify the logit of tokens in model outputs without heavy training. Recent studies have shown that contrastive decoding can enhance the performance of language models by reducing the likelihood of confused tokens. However, these methods require the manual selection of contrastive models or instruction templates. To this end, we propose Adversarial Contrastive Decoding (ACD), an optimization-based framework to generate two opposite system prompts for prompt-based contrastive decoding. ACD only needs to apply a lightweight prompt tuning on a rather small anchor dataset (< 3 min for each model) without training the target model. Experiments conducted on extensive models and benchmarks demonstrate that the proposed method achieves much better safety performance than previous model training-free decoding methods without sacrificing its original generation ability.
Typography Leads Semantic Diversifying: Amplifying Adversarial Transferability across Multimodal Large Language Models
May 30, 2024



Following the advent of the Artificial Intelligence (AI) era of large models, Multimodal Large Language Models (MLLMs) with the ability to understand cross-modal interactions between vision and text have attracted wide attention. Adversarial examples with human-imperceptible perturbation are shown to possess a characteristic known as transferability, which means that a perturbation generated by one model could also mislead another different model. Augmenting the diversity in input data is one of the most significant methods for enhancing adversarial transferability. This method has been certified as a way to significantly enlarge the threat impact under black-box conditions. Research works also demonstrate that MLLMs can be exploited to generate adversarial examples in the white-box scenario. However, the adversarial transferability of such perturbations is quite limited, failing to achieve effective black-box attacks across different models. In this paper, we propose the Typographic-based Semantic Transfer Attack (TSTA), which is inspired by: (1) MLLMs tend to process semantic-level information; (2) Typographic Attack could effectively distract the visual information captured by MLLMs. In the scenarios of Harmful Word Insertion and Important Information Protection, our TSTA demonstrates superior performance.
Rescale-Invariant Federated Reinforcement Learning for Resource Allocation in V2X Networks
May 03, 2024



Federated Reinforcement Learning (FRL) offers a promising solution to various practical challenges in resource allocation for vehicle-to-everything (V2X) networks. However, the data discrepancy among individual agents can significantly degrade the performance of FRL-based algorithms. To address this limitation, we exploit the node-wise invariance property of ReLU-activated neural networks, with the aim of reducing data discrepancy to improve learning performance. Based on this property, we introduce a backward rescale-invariant operation to develop a rescale-invariant FRL algorithm. Simulation results demonstrate that the proposed algorithm notably enhances both convergence speed and convergent performance.