 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting Low-Data Instance Segmentation by Unsupervised Pre-training with Saliency Prompt
Feb 02, 2023



Recently, inspired by DETR variants, query-based end-to-end instance segmentation (QEIS) methods have outperformed CNN-based models on large-scale datasets. Yet they would lose efficacy when only a small amount of training data is available since it's hard for the crucial queries/kernels to learn localization and shape priors. To this end, this work offers a novel unsupervised pre-training solution for low-data regimes. Inspired by the recent success of the Prompting technique, we introduce a new pre-training method that boosts QEIS models by giving Saliency Prompt for queries/kernels. Our method contains three parts: 1) Saliency Masks Proposal is responsible for generating pseudo masks from unlabeled images based on the saliency mechanism. 2) Prompt-Kernel Matching transfers pseudo masks into prompts and injects the corresponding localization and shape priors to the best-matched kernels. 3) Kernel Supervision is applied to supply supervision at the kernel level for robust learning. From a practical perspective, our pre-training method helps QEIS models achieve a similar convergence speed and comparable performance with CNN-based models in low-data regimes. Experimental results show that our method significantly boosts several QEIS models on three datasets. Code will be made available.
Fewer is More: Efficient Object Detection in Large Aerial Images
Dec 26, 2022Current mainstream object detection methods for large aerial images usually divide large images into patches and then exhaustively detect the objects of interest on all patches, no matter whether there exist objects or not. This paradigm, although effective, is inefficient because the detectors have to go through all patches, severely hindering the inference speed. This paper presents an Objectness Activation Network (OAN) to help detectors focus on fewer patches but achieve more efficient inference and more accurate results, enabling a simple and effective solution to object detection in large images. In brief, OAN is a light fully-convolutional network for judging whether each patch contains objects or not, which can be easily integrated into many object detectors and jointly trained with them end-to-end. We extensively evaluate our OAN with five advanced detectors. Using OAN, all five detectors acquire more than 30.0% speed-up on three large-scale aerial image datasets, meanwhile with consistent accuracy improvements. On extremely large Gaofen-2 images (29200$\times$27620 pixels), our OAN improves the detection speed by 70.5%. Moreover, we extend our OAN to driving-scene object detection and 4K video object detection, boosting the detection speed by 112.1% and 75.0%, respectively, without sacrificing the accuracy. Code is available at https://github.com/Ranchosky/OAN.
Progressively Dual Prior Guided Few-shot Semantic Segmentation
Nov 20, 2022



Few-shot semantic segmentation task aims at performing segmentation in query images with a few annotated support samples. Currently, few-shot segmentation methods mainly focus on leveraging foreground information without fully utilizing the rich background information, which could result in wrong activation of foreground-like background regions with the inadaptability to dramatic scene changes of support-query image pairs. Meanwhile, the lack of detail mining mechanism could cause coarse parsing results without some semantic components or edge areas since prototypes have limited ability to cope with large object appearance variance. To tackle these problems, we propose a progressively dual prior guided few-shot semantic segmentation network. Specifically, a dual prior mask generation (DPMG) module is firstly designed to suppress the wrong activation in foreground-background comparison manner by regarding background as assisted refinement information. With dual prior masks refining the location of foreground area, we further propose a progressive semantic detail enrichment (PSDE) module which forces the parsing model to capture the hidden semantic details by iteratively erasing the high-confidence foreground region and activating details in the rest region with a hierarchical structure. The collaboration of DPMG and PSDE formulates a novel few-shot segmentation network that can be learned in an end-to-end manner. Comprehensive experiments on PASCAL-5i and MS COCO powerfully demonstrate that our proposed algorithm achieves the great performance.
Intermediate Prototype Mining Transformer for Few-Shot Semantic Segmentation
Oct 13, 2022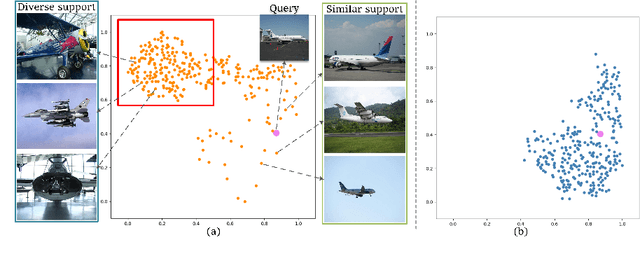
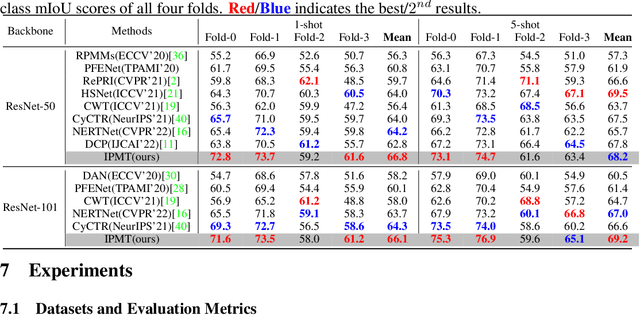
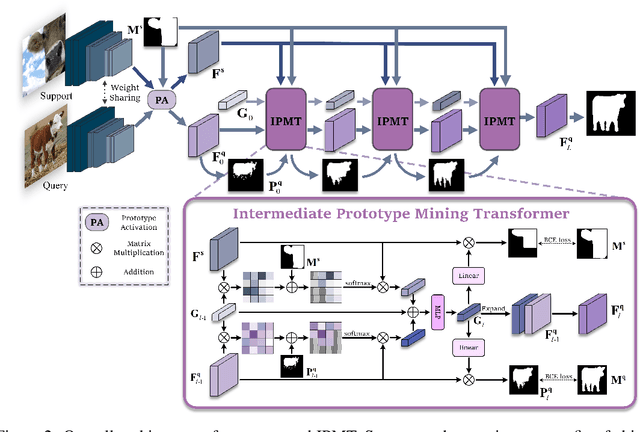
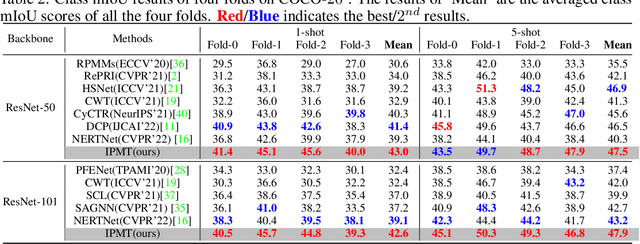
Few-shot semantic segmentation aims to segment the target objects in query under the condition of a few annotated support images. Most previous works strive to mine more effective category information from the support to match with the corresponding objects in query. However, they all ignored the category information gap between query and support images. If the objects in them show large intra-class diversity, forcibly migrating the category information from the support to the query is ineffective. To solve this problem, we are the first to introduce an intermediate prototype for mining both deterministic category information from the support and adaptive category knowledge from the query. Specifically, we design an Intermediate Prototype Mining Transformer (IPMT) to learn the prototype in an iterative way. In each IPMT layer, we propagate the object information in both support and query features to the prototype and then use it to activate the query feature map. By conducting this process iteratively, both the intermediate prototype and the query feature can be progressively improved. At last, the final query feature is used to yield precise segmentation prediction. Extensive experiments on both PASCAL-5i and COCO-20i datasets clearly verify the effectiveness of our IPMT and show that it outperforms previous state-of-the-art methods by a large margin. Code is available at https://github.com/LIUYUANWEI98/IPMT
Towards Large-Scale Small Object Detection: Survey and Benchmarks
Jul 31, 2022
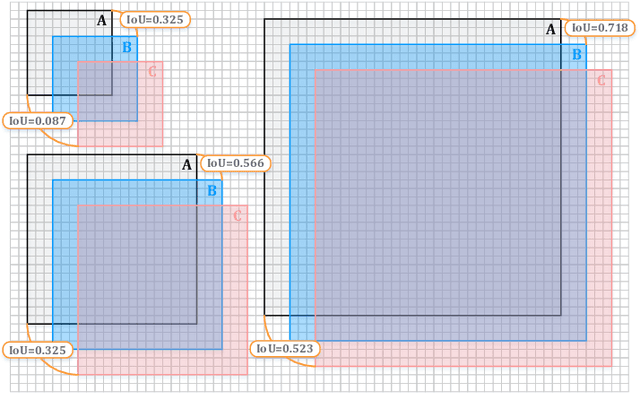
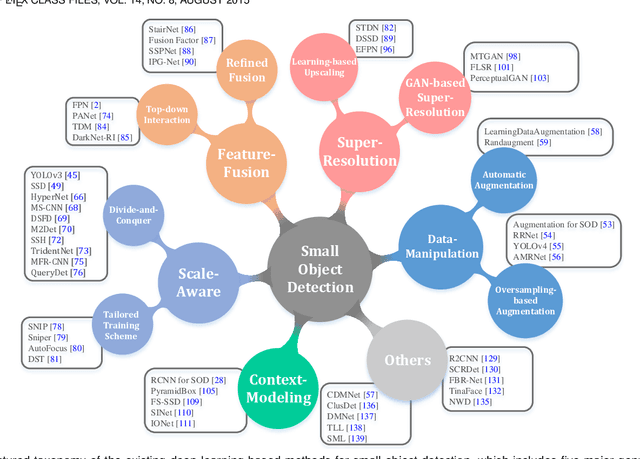
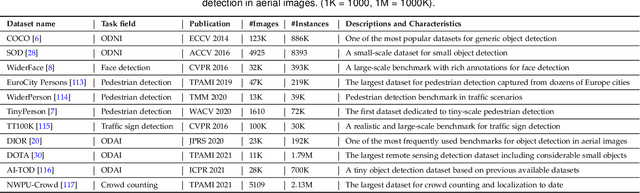
With the rise of deep convolutional neural networks, object detection has achieved prominent advances in past years. However, such prosperity could not camouflage the unsatisfactory situation of Small Object Detection (SOD), one of the notoriously challenging tasks in computer vision, owing to the poor visual appearance and noisy representation caused by the intrinsic structure of small targets. In addition, large-scale dataset for benchmarking small object detection methods remains a bottleneck. In this paper, we first conduct a thorough review of small object detection. Then, to catalyze the development of SOD, we construct two large-scale Small Object Detection dAtasets (SODA), SODA-D and SODA-A, which focus on the Driving and Aerial scenarios respectively. SODA-D includes 24704 high-quality traffic images and 277596 instances of 9 categories. For SODA-A, we harvest 2510 high-resolution aerial images and annotate 800203 instances over 9 classes. The proposed datasets, as we know, are the first-ever attempt to large-scale benchmarks with a vast collection of exhaustively annotated instances tailored for multi-category SOD. Finally, we evaluate the performance of mainstream methods on SODA. We expect the released benchmarks could facilitate the development of SOD and spawn more breakthroughs in this field. Datasets and codes will be available soon at: \url{https://shaunyuan22.github.io/SODA}.
Structured Attention Composition for Temporal Action Localization
May 27, 2022
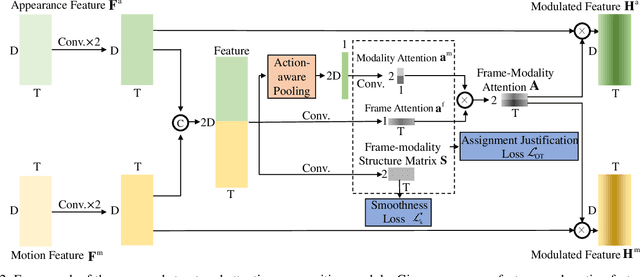
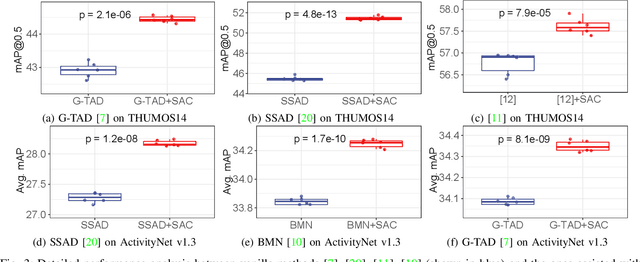

Temporal action localization aims at localizing action instances from untrimmed videos. Existing works have designed various effective modules to precisely localize action instances based on appearance and motion features. However, by treating these two kinds of features with equal importance, previous works cannot take full advantage of each modality feature, making the learned model still sub-optimal. To tackle this issue, we make an early effort to study temporal action localization from the perspective of multi-modality feature learning, based on the observation that different actions exhibit specific preferences to appearance or motion modality. Specifically, we build a novel structured attention composition module. Unlike conventional attention, the proposed module would not infer frame attention and modality attention independently. Instead, by casting the relationship between the modality attention and the frame attention as an attention assignment process, the structured attention composition module learns to encode the frame-modality structure and uses it to regularize the inferred frame attention and modality attention, respectively, upon the optimal transport theory. The final frame-modality attention is obtained by the composition of the two individual attentions. The proposed structured attention composition module can be deployed as a plug-and-play module into existing action localization frameworks. Extensive experiments on two widely used benchmarks show that the proposed structured attention composition consistently improves four state-of-the-art temporal action localization methods and builds new state-of-the-art performance on THUMOS14. Code is availabel at https://github.com/VividLe/Structured-Attention-Composition.
Brain Cortical Functional Gradients Predict Cortical Folding Patterns via Attention Mesh Convolution
May 21, 2022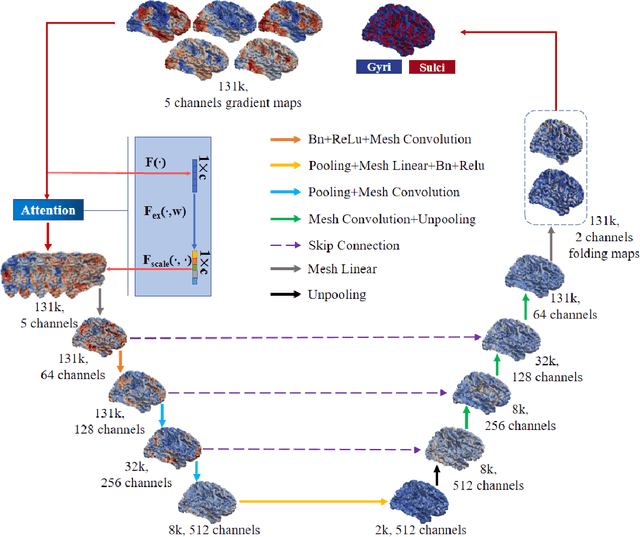
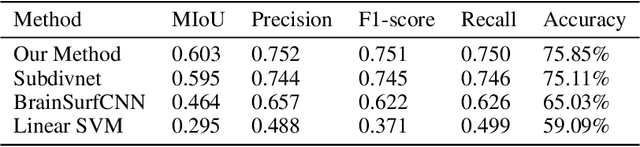

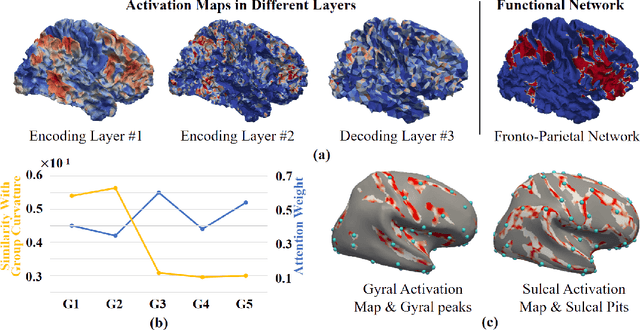
Since gyri and sulci, two basic anatomical building blocks of cortical folding patterns, were suggested to bear different functional roles, a precise mapping from brain function to gyro-sulcal patterns can provide profound insights into both biological and artificial neural networks. However, there lacks a generic theory and effective computational model so far, due to the highly nonlinear relation between them, huge inter-individual variabilities and a sophisticated description of brain function regions/networks distribution as mosaics, such that spatial patterning of them has not been considered. we adopted brain functional gradients derived from resting-state fMRI to embed the "gradual" change of functional connectivity patterns, and developed a novel attention mesh convolution model to predict cortical gyro-sulcal segmentation maps on individual brains. The convolution on mesh considers the spatial organization of functional gradients and folding patterns on a cortical sheet and the newly designed channel attention block enhances the interpretability of the contribution of different functional gradients to cortical folding prediction. Experiments show that the prediction performance via our model outperforms other state-of-the-art models. In addition, we found that the dominant functional gradients contribute less to folding prediction. On the activation maps of the last layer, some well-studied cortical landmarks are found on the borders of, rather than within, the highly activated regions. These results and findings suggest that a specifically designed artificial neural network can improve the precision of the mapping between brain functions and cortical folding patterns, and can provide valuable insight of brain anatomy-function relation for neuroscience.
Learning Non-target Knowledge for Few-shot Semantic Segmentation
May 10, 2022
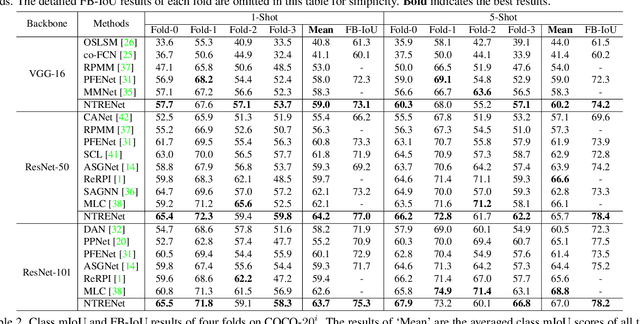
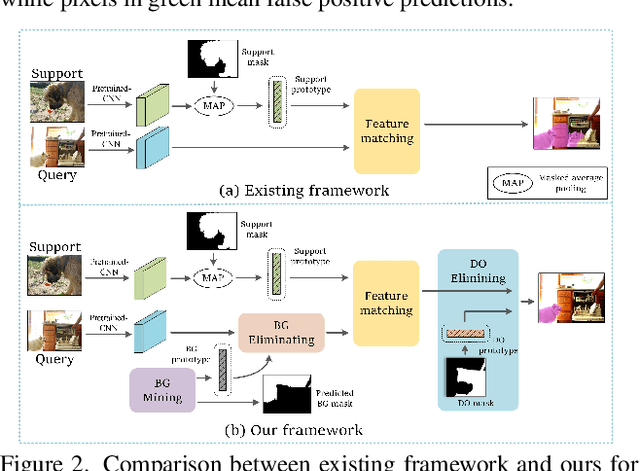
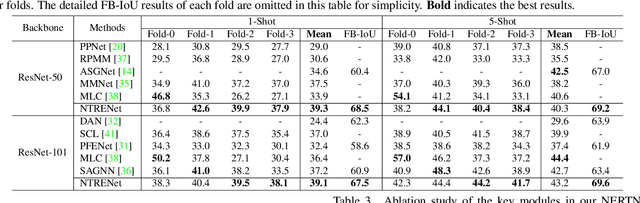
Existing studies in few-shot semantic segmentation only focus on mining the target object information, however, often are hard to tell ambiguous regions, especially in non-target regions, which include background (BG) and Distracting Objects (DOs). To alleviate this problem, we propose a novel framework, namely Non-Target Region Eliminating (NTRE) network, to explicitly mine and eliminate BG and DO regions in the query. First, a BG Mining Module (BGMM) is proposed to extract the BG region via learning a general BG prototype. To this end, we design a BG loss to supervise the learning of BGMM only using the known target object segmentation ground truth. Then, a BG Eliminating Module and a DO Eliminating Module are proposed to successively filter out the BG and DO information from the query feature, based on which we can obtain a BG and DO-free target object segmentation result. Furthermore, we propose a prototypical contrastive learning algorithm to improve the model ability of distinguishing the target object from DOs. Extensive experiments on both PASCAL-5i and COCO-20i datasets show that our approach is effective despite its simplicity.
Beyond the Prototype: Divide-and-conquer Proxies for Few-shot Segmentation
Apr 21, 2022
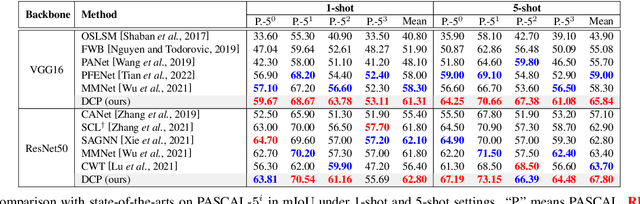
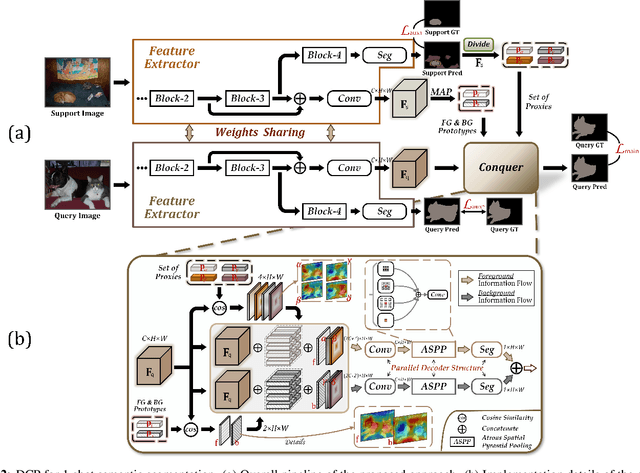

Few-shot segmentation, which aims to segment unseen-class objects given only a handful of densely labeled samples, has received widespread attention from the community. Existing approaches typically follow the prototype learning paradigm to perform meta-inference, which fails to fully exploit the underlying information from support image-mask pairs, resulting in various segmentation failures, e.g., incomplete objects, ambiguous boundaries, and distractor activation. To this end, we propose a simple yet versatile framework in the spirit of divide-and-conquer. Specifically, a novel self-reasoning scheme is first implemented on the annotated support image, and then the coarse segmentation mask is divided into multiple regions with different properties. Leveraging effective masked average pooling operations, a series of support-induced proxies are thus derived, each playing a specific role in conquering the above challenges. Moreover, we devise a unique parallel decoder structure that integrates proxies with similar attributes to boost the discrimination power. Our proposed approach, named divide-and-conquer proxies (DCP), allows for the development of appropriate and reliable information as a guide at the "episode" level, not just about the object cues themselves. Extensive experiments on PASCAL-5i and COCO-20i demonstrate the superiority of DCP over conventional prototype-based approaches (up to 5~10% on average), which also establishes a new state-of-the-art. Code is available at github.com/chunbolang/DCP.
Cross-Modality High-Frequency Transformer for MR Image Super-Resolution
Mar 29, 2022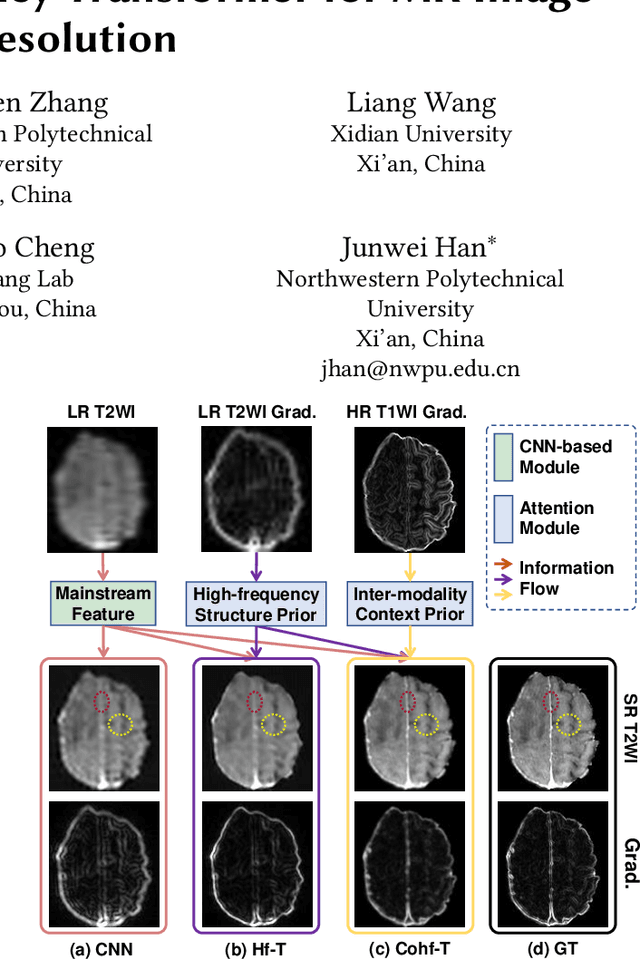
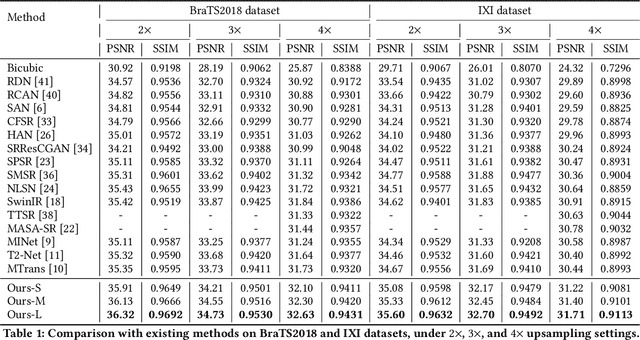
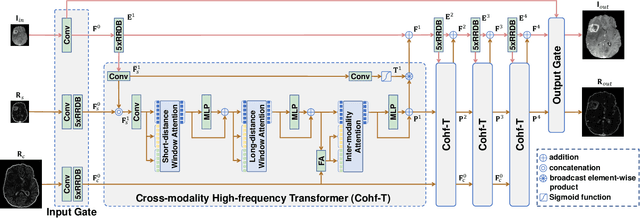
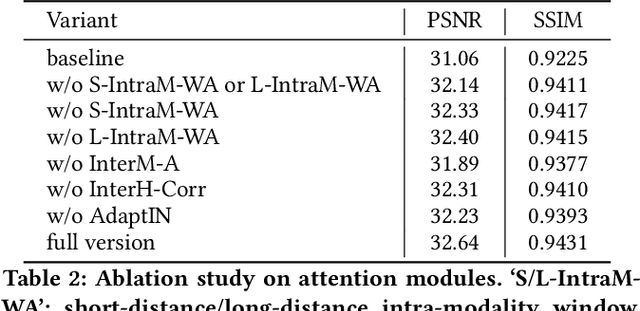
Improving the resolution of magnetic resonance (MR) image data is critical to computer-aided diagnosis and brain function analysis. Higher resolution helps to capture more detailed content, but typically induces to lower signal-to-noise ratio and longer scanning time. To this end, MR image super-resolution has become a widely-interested topic in recent times. Existing works establish extensive deep models with the conventional architectures based on convolutional neural networks (CNN). In this work, to further advance this research field, we make an early effort to build a Transformer-based MR image super-resolution framework, with careful designs on exploring valuable domain prior knowledge. Specifically, we consider two-fold domain priors including the high-frequency structure prior and the inter-modality context prior, and establish a novel Transformer architecture, called Cross-modality high-frequency Transformer (Cohf-T), to introduce such priors into super-resolving the low-resolution (LR) MR images. Comprehensive experiments on two datasets indicate that Cohf-T achieves new state-of-the-art performance.