 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNearest-Better Network for Visualizing and Analyzing Combinatorial Optimization Problems: A Unified Tool
Jul 30, 2025The Nearest-Better Network (NBN) is a powerful method to visualize sampled data for continuous optimization problems while preserving multiple landscape features. However, the calculation of NBN is very time-consuming, and the extension of the method to combinatorial optimization problems is challenging but very important for analyzing the algorithm's behavior. This paper provides a straightforward theoretical derivation showing that the NBN network essentially functions as the maximum probability transition network for algorithms. This paper also presents an efficient NBN computation method with logarithmic linear time complexity to address the time-consuming issue. By applying this efficient NBN algorithm to the OneMax problem and the Traveling Salesman Problem (TSP), we have made several remarkable discoveries for the first time: The fitness landscape of OneMax exhibits neutrality, ruggedness, and modality features. The primary challenges of TSP problems are ruggedness, modality, and deception. Two state-of-the-art TSP algorithms (i.e., EAX and LKH) have limitations when addressing challenges related to modality and deception, respectively. LKH, based on local search operators, fails when there are deceptive solutions near global optima. EAX, which is based on a single population, can efficiently maintain diversity. However, when multiple attraction basins exist, EAX retains individuals within multiple basins simultaneously, reducing inter-basin interaction efficiency and leading to algorithm's stagnation.
Evolutionary Dynamic Optimization Laboratory: A MATLAB Optimization Platform for Education and Experimentation in Dynamic Environments
Aug 24, 2023



Many real-world optimization problems possess dynamic characteristics. Evolutionary dynamic optimization algorithms (EDOAs) aim to tackle the challenges associated with dynamic optimization problems. Looking at the existing works, the results reported for a given EDOA can sometimes be considerably different. This issue occurs because the source codes of many EDOAs, which are usually very complex algorithms, have not been made publicly available. Indeed, the complexity of components and mechanisms used in many EDOAs makes their re-implementation error-prone. In this paper, to assist researchers in performing experiments and comparing their algorithms against several EDOAs, we develop an open-source MATLAB platform for EDOAs, called Evolutionary Dynamic Optimization LABoratory (EDOLAB). This platform also contains an education module that can be used for educational purposes. In the education module, the user can observe a) a 2-dimensional problem space and how its morphology changes after each environmental change, b) the behaviors of individuals over time, and c) how the EDOA reacts to environmental changes and tries to track the moving optimum. In addition to being useful for research and education purposes, EDOLAB can also be used by practitioners to solve their real-world problems. The current version of EDOLAB includes 25 EDOAs and three fully-parametric benchmark generators. The MATLAB source code for EDOLAB is publicly available and can be accessed from [https://github.com/EDOLAB-platform/EDOLAB-MATLAB].
Eye-gaze-guided Vision Transformer for Rectifying Shortcut Learning
May 25, 2022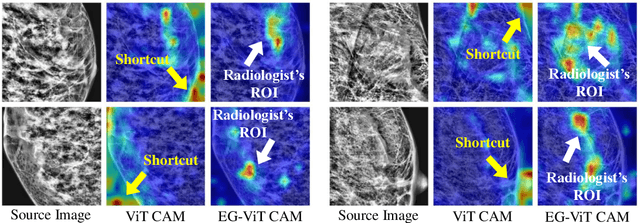
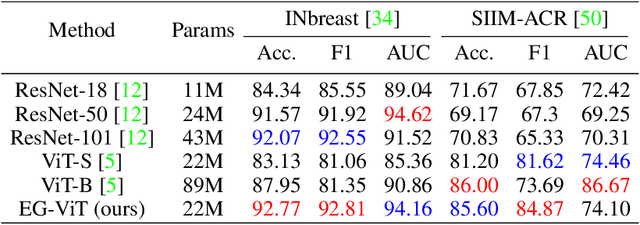
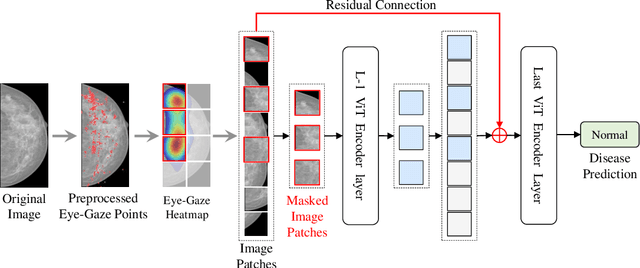
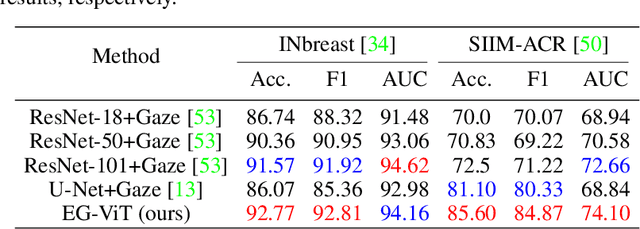
Learning harmful shortcuts such as spurious correlations and biases prevents deep neural networks from learning the meaningful and useful representations, thus jeopardizing the generalizability and interpretability of the learned representation. The situation becomes even more serious in medical imaging, where the clinical data (e.g., MR images with pathology) are limited and scarce while the reliability, generalizability and transparency of the learned model are highly required. To address this problem, we propose to infuse human experts' intelligence and domain knowledge into the training of deep neural networks. The core idea is that we infuse the visual attention information from expert radiologists to proactively guide the deep model to focus on regions with potential pathology and avoid being trapped in learning harmful shortcuts. To do so, we propose a novel eye-gaze-guided vision transformer (EG-ViT) for diagnosis with limited medical image data. We mask the input image patches that are out of the radiologists' interest and add an additional residual connection in the last encoder layer of EG-ViT to maintain the correlations of all patches. The experiments on two public datasets of INbreast and SIIM-ACR demonstrate our EG-ViT model can effectively learn/transfer experts' domain knowledge and achieve much better performance than baselines. Meanwhile, it successfully rectifies the harmful shortcut learning and significantly improves the EG-ViT model's interpretability. In general, EG-ViT takes the advantages of both human expert's prior knowledge and the power of deep neural networks. This work opens new avenues for advancing current artificial intelligence paradigms by infusing human intelligence.
Brain Cortical Functional Gradients Predict Cortical Folding Patterns via Attention Mesh Convolution
May 21, 2022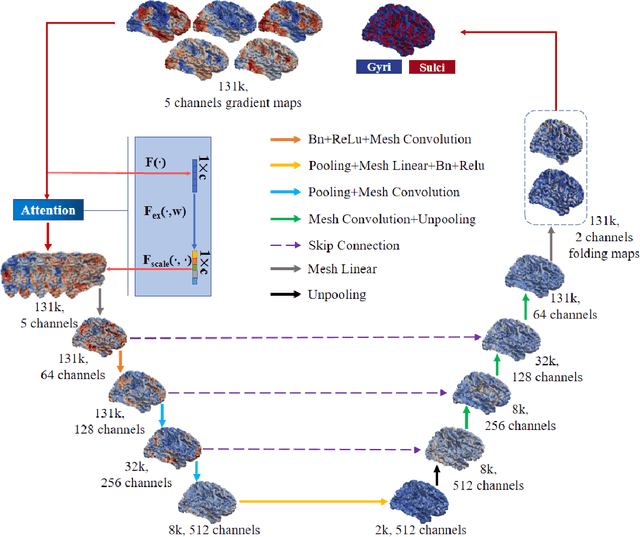
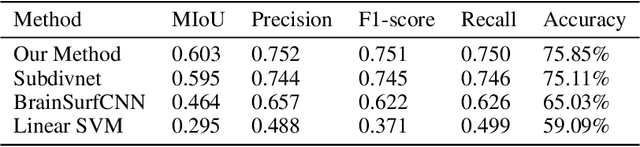

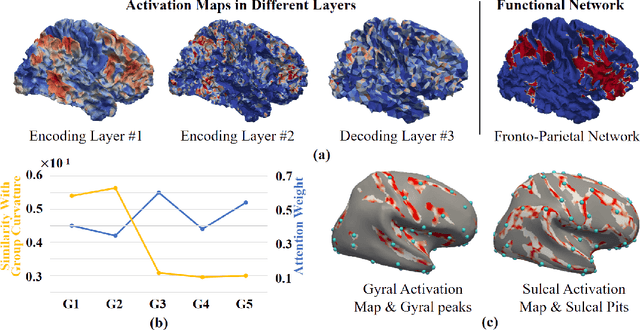
Since gyri and sulci, two basic anatomical building blocks of cortical folding patterns, were suggested to bear different functional roles, a precise mapping from brain function to gyro-sulcal patterns can provide profound insights into both biological and artificial neural networks. However, there lacks a generic theory and effective computational model so far, due to the highly nonlinear relation between them, huge inter-individual variabilities and a sophisticated description of brain function regions/networks distribution as mosaics, such that spatial patterning of them has not been considered. we adopted brain functional gradients derived from resting-state fMRI to embed the "gradual" change of functional connectivity patterns, and developed a novel attention mesh convolution model to predict cortical gyro-sulcal segmentation maps on individual brains. The convolution on mesh considers the spatial organization of functional gradients and folding patterns on a cortical sheet and the newly designed channel attention block enhances the interpretability of the contribution of different functional gradients to cortical folding prediction. Experiments show that the prediction performance via our model outperforms other state-of-the-art models. In addition, we found that the dominant functional gradients contribute less to folding prediction. On the activation maps of the last layer, some well-studied cortical landmarks are found on the borders of, rather than within, the highly activated regions. These results and findings suggest that a specifically designed artificial neural network can improve the precision of the mapping between brain functions and cortical folding patterns, and can provide valuable insight of brain anatomy-function relation for neuroscience.
Mask-guided Vision Transformer for Few-Shot Learning
May 20, 2022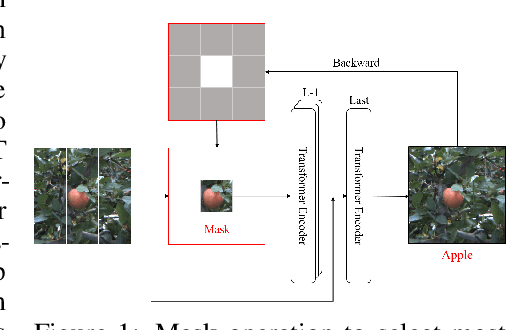
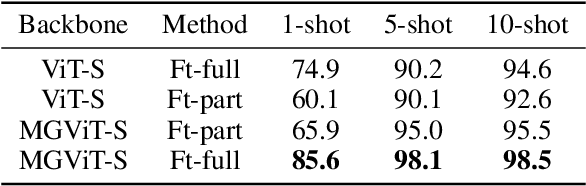
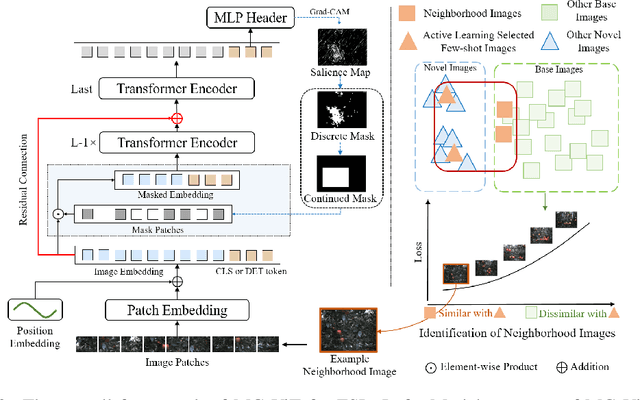
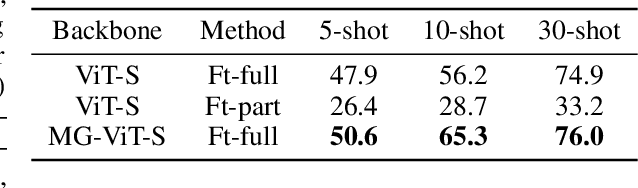
Learning with little data is challenging but often inevitable in various application scenarios where the labeled data is limited and costly. Recently, few-shot learning (FSL) gained increasing attention because of its generalizability of prior knowledge to new tasks that contain only a few samples. However, for data-intensive models such as vision transformer (ViT), current fine-tuning based FSL approaches are inefficient in knowledge generalization and thus degenerate the downstream task performances. In this paper, we propose a novel mask-guided vision transformer (MG-ViT) to achieve an effective and efficient FSL on ViT model. The key idea is to apply a mask on image patches to screen out the task-irrelevant ones and to guide the ViT to focus on task-relevant and discriminative patches during FSL. Particularly, MG-ViT only introduces an additional mask operation and a residual connection, enabling the inheritance of parameters from pre-trained ViT without any other cost. To optimally select representative few-shot samples, we also include an active learning based sample selection method to further improve the generalizability of MG-ViT based FSL. We evaluate the proposed MG-ViT on both Agri-ImageNet classification task and ACFR apple detection task with gradient-weighted class activation mapping (Grad-CAM) as the mask. The experimental results show that the MG-ViT model significantly improves the performance when compared with general fine-tuning based ViT models, providing novel insights and a concrete approach towards generalizing data-intensive and large-scale deep learning models for FSL.
Benchmark Functions for CEC 2022 Competition on Seeking Multiple Optima in Dynamic Environments
Jan 06, 2022



Dynamic and multimodal features are two important properties and widely existed in many real-world optimization problems. The former illustrates that the objectives and/or constraints of the problems change over time, while the latter means there is more than one optimal solution (sometimes including the accepted local solutions) in each environment. The dynamic multimodal optimization problems (DMMOPs) have both of these characteristics, which have been studied in the field of evolutionary computation and swarm intelligence for years, and attract more and more attention. Solving such problems requires optimization algorithms to simultaneously track multiple optima in the changing environments. So that the decision makers can pick out one optimal solution in each environment according to their experiences and preferences, or quickly turn to other solutions when the current one cannot work well. This is very helpful for the decision makers, especially when facing changing environments. In this competition, a test suit about DMMOPs is given, which models the real-world applications. Specifically, this test suit adopts 8 multimodal functions and 8 change modes to construct 24 typical dynamic multimodal optimization problems. Meanwhile, the metric is also given to measure the algorithm performance, which considers the average number of optimal solutions found in all environments. This competition will be very helpful to promote the development of dynamic multimodal optimization algorithms.
Generalized Moving Peaks Benchmark
Jun 11, 2021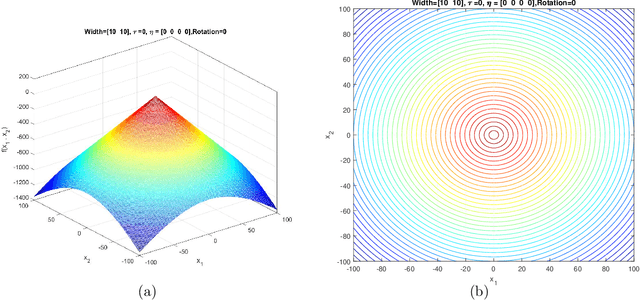
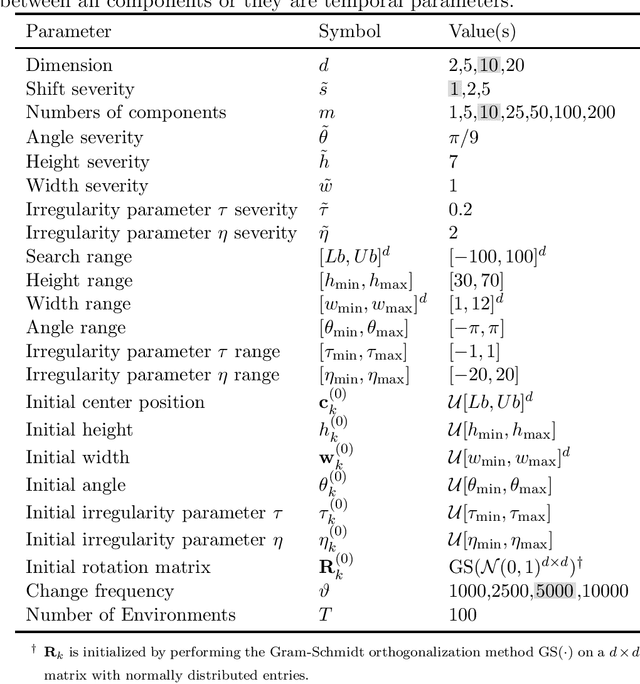
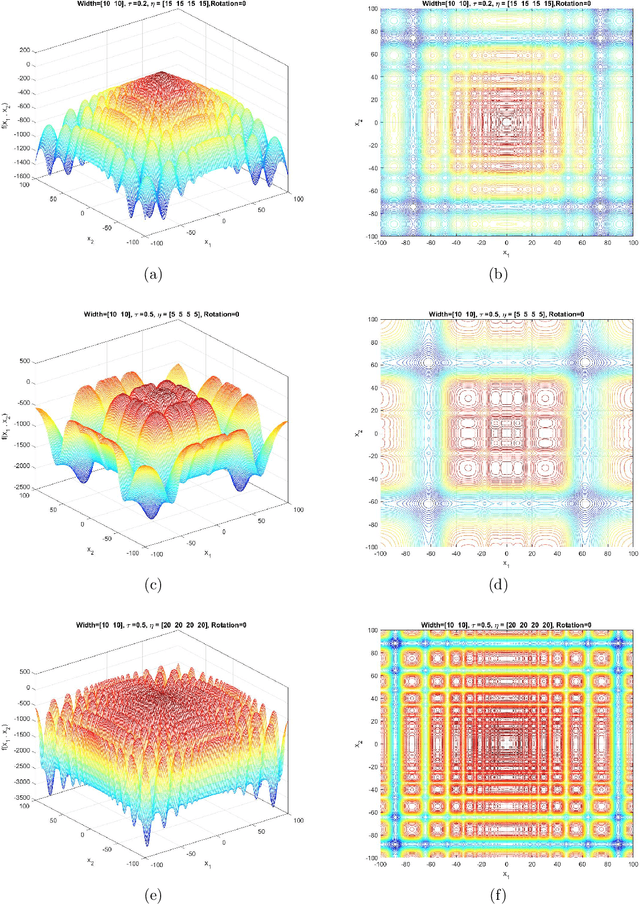
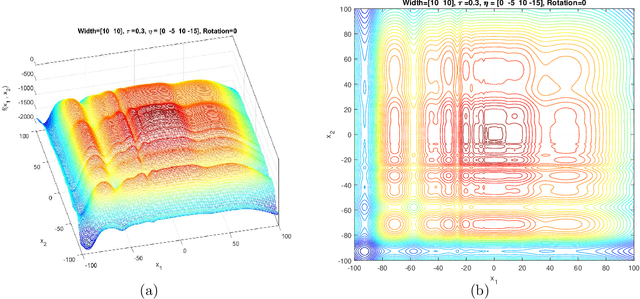
This document describes the Generalized Moving Peaks Benchmark (GMPB) that generates continuous dynamic optimization problem instances. The landscapes generated by GMPB are constructed by assembling several components with a variety of controllable characteristics ranging from unimodal to highly multimodal, symmetric to highly asymmetric, smooth to highly irregular, and various degrees of variable interaction and ill-conditioning. In this document, we explain how these characteristics can be generated by different parameter settings of GMPB. The MATLAB source code of GMPB is also explained. This document forms the basis for a range of competitions on Evolutionary Continuous Dynamic Optimization in the upcoming well-known conferences.