 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoes YOLO Really Need to See Every Training Image in Every Epoch?
Mar 18, 2026YOLO detectors are known for their fast inference speed, yet training them remains unexpectedly time-consuming due to their exhaustive pipeline that processes every training image in every epoch, even when many images have already been sufficiently learned. This stands in clear contrast to the efficiency suggested by the ``You Only Look Once'' philosophy. This naturally raises an important question: \textit{Does YOLO really need to see every training image in every epoch?} To explore this, we propose an Anti-Forgetting Sampling Strategy (AFSS) that dynamically determines which images should be used and which can be skipped during each epoch, allowing the detector to learn more effectively and efficiently. Specifically, AFSS measures the learning sufficiency of each training image as the minimum of its detection recall and precision, and dynamically categorizes training images into easy, medium, or hard levels accordingly. Easy training images are sparsely resampled during training in a continuous review manner, with priority given to those that have not been used for a long time to reduce redundancy and prevent forgetting. Moderate training images are partially selected, prioritizing recently unused ones and randomly choosing the rest from unselected images to ensure coverage and prevent forgetting. Hard training images are fully sampled in every epoch to ensure sufficient learning. The learning sufficiency of each training image is periodically updated, enabling detectors to adaptively shift its focus toward the informative training images over time while progressively discarding redundant ones. On widely used natural image detection benchmarks (MS COCO 2017 and PASCAL VOC 2007) and remote sensing detection datasets (DOTA-v1.0 and DIOR-R), AFSS achieves more than $1.43\times$ training speedup for YOLO-series detectors while also improving accuracy.
Fewer is More: Efficient Object Detection in Large Aerial Images
Dec 26, 2022Current mainstream object detection methods for large aerial images usually divide large images into patches and then exhaustively detect the objects of interest on all patches, no matter whether there exist objects or not. This paradigm, although effective, is inefficient because the detectors have to go through all patches, severely hindering the inference speed. This paper presents an Objectness Activation Network (OAN) to help detectors focus on fewer patches but achieve more efficient inference and more accurate results, enabling a simple and effective solution to object detection in large images. In brief, OAN is a light fully-convolutional network for judging whether each patch contains objects or not, which can be easily integrated into many object detectors and jointly trained with them end-to-end. We extensively evaluate our OAN with five advanced detectors. Using OAN, all five detectors acquire more than 30.0% speed-up on three large-scale aerial image datasets, meanwhile with consistent accuracy improvements. On extremely large Gaofen-2 images (29200$\times$27620 pixels), our OAN improves the detection speed by 70.5%. Moreover, we extend our OAN to driving-scene object detection and 4K video object detection, boosting the detection speed by 112.1% and 75.0%, respectively, without sacrificing the accuracy. Code is available at https://github.com/Ranchosky/OAN.
Anchor-free Oriented Proposal Generator for Object Detection
Oct 05, 2021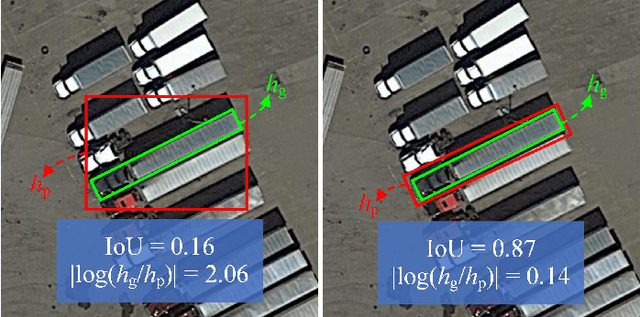

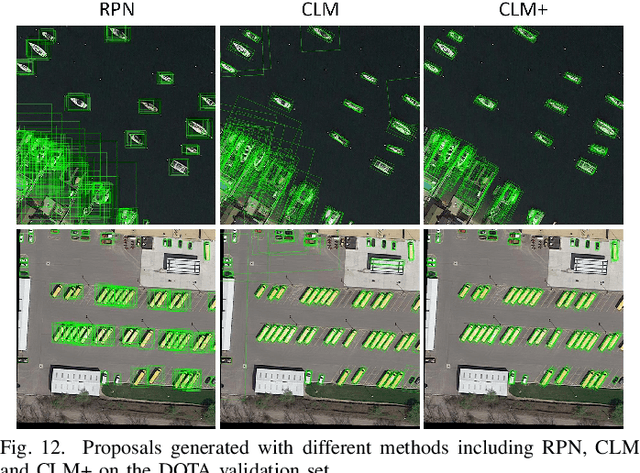
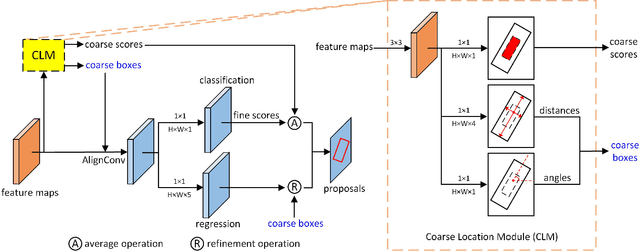
Oriented object detection is a practical and challenging task in remote sensing image interpretation. Nowadays, oriented detectors mostly use horizontal boxes as intermedium to derive oriented boxes from them. However, the horizontal boxes are inclined to get a small Intersection-over-Unions (IoUs) with ground truths, which may have some undesirable effects, such as introducing redundant noise, mismatching with ground truths, detracting from the robustness of detectors, etc. In this paper, we propose a novel Anchor-free Oriented Proposal Generator (AOPG) that abandons the horizontal boxes-related operations from the network architecture. AOPG first produces coarse oriented boxes by Coarse Location Module (CLM) in an anchor-free manner and then refines them into high-quality oriented proposals. After AOPG, we apply a Fast R-CNN head to produce the final detection results. Furthermore, the shortage of large-scale datasets is also a hindrance to the development of oriented object detection. To alleviate the data insufficiency, we release a new dataset on the basis of our DIOR dataset and name it DIOR-R. Massive experiments demonstrate the effectiveness of AOPG. Particularly, without bells and whistles, we achieve the highest accuracy of 64.41$\%$, 75.24$\%$ and 96.22$\%$ mAP on the DIOR-R, DOTA and HRSC2016 datasets respectively. Code and models are available at https://github.com/jbwang1997/AOPG.
Oriented R-CNN for Object Detection
Aug 12, 2021
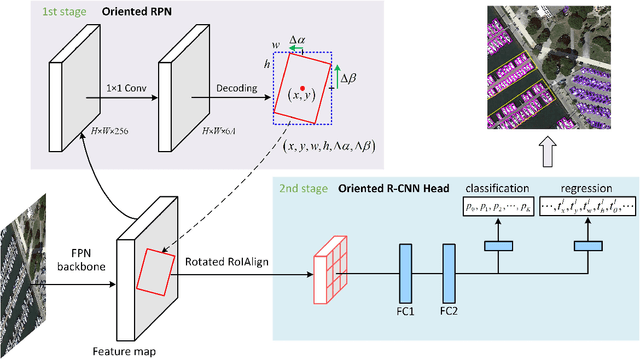
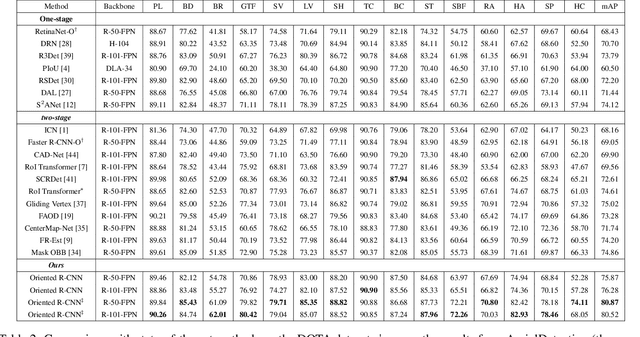
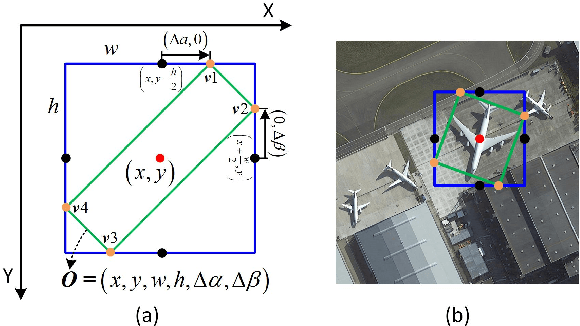
Current state-of-the-art two-stage detectors generate oriented proposals through time-consuming schemes. This diminishes the detectors' speed, thereby becoming the computational bottleneck in advanced oriented object detection systems. This work proposes an effective and simple oriented object detection framework, termed Oriented R-CNN, which is a general two-stage oriented detector with promising accuracy and efficiency. To be specific, in the first stage, we propose an oriented Region Proposal Network (oriented RPN) that directly generates high-quality oriented proposals in a nearly cost-free manner. The second stage is oriented R-CNN head for refining oriented Regions of Interest (oriented RoIs) and recognizing them. Without tricks, oriented R-CNN with ResNet50 achieves state-of-the-art detection accuracy on two commonly-used datasets for oriented object detection including DOTA (75.87% mAP) and HRSC2016 (96.50% mAP), while having a speed of 15.1 FPS with the image size of 1024$\times$1024 on a single RTX 2080Ti. We hope our work could inspire rethinking the design of oriented detectors and serve as a baseline for oriented object detection. Code is available at https://github.com/jbwang1997/OBBDetection.
Remote Sensing Image Scene Classification Meets Deep Learning: Challenges, Methods, Benchmarks, and Opportunities
May 03, 2020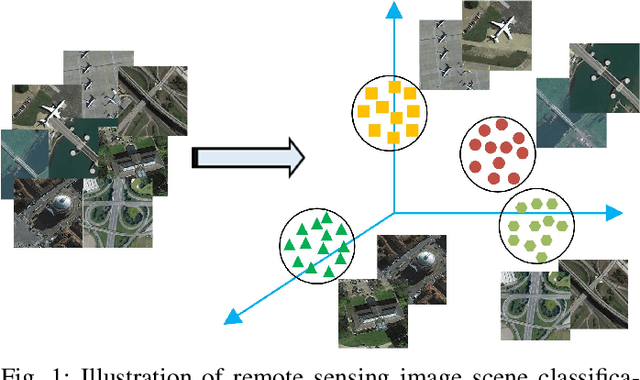
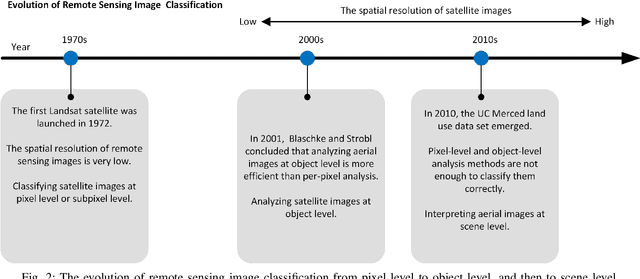
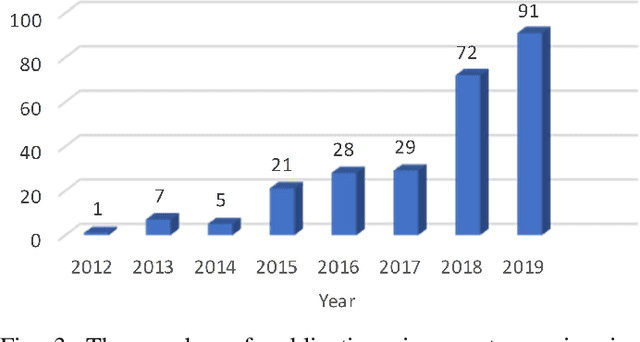
Remote sensing image scene classification, which aims at labeling remote sensing images with a set of semantic categories based on their contents, has broad applications in a range of fields. Propelled by the powerful feature learning capabilities of deep neural networks, remote sensing image scene classification driven by deep learning has drawn remarkable attention and achieved significant breakthroughs. However, to the best of our knowledge, a comprehensive review of recent achievements regarding deep learning for scene classification of remote sensing images is still lacking. Considering the rapid evolution of this field, this paper provides a systematic survey of deep learning methods for remote sensing image scene classification by covering more than 140 papers. To be specific, we discuss the main challenges of scene classification and survey (1) Autoencoder-based scene classification methods, (2) Convolutional Neural Network-based scene classification methods, and (3) Generative Adversarial Network-based scene classification methods. In addition, we introduce the benchmarks used for scene classification and summarize the performance of more than two dozens of representative algorithms on three commonly-used benchmark data sets. Finally, we discuss the promising opportunities for further research.