 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBLOOM+1: Adding Language Support to BLOOM for Zero-Shot Prompting
Dec 19, 2022



The BLOOM model is a large open-source multilingual language model capable of zero-shot learning, but its pretraining was limited to 46 languages. To improve its zero-shot performance on unseen languages, it is desirable to adapt BLOOM, but previous works have only explored adapting small language models. In this work, we apply existing language adaptation strategies to BLOOM and benchmark its zero-shot prompting performance on eight new languages. We find language adaptation to be effective at improving zero-shot performance in new languages. Surprisingly, adapter-based finetuning is more effective than continued pretraining for large models. In addition, we discover that prompting performance is not significantly affected by language specifics, such as the writing system. It is primarily determined by the size of the language adaptation data. We also add new languages to BLOOMZ, which is a multitask finetuned version of BLOOM capable of following task instructions zero-shot. We find including a new language in the multitask fine-tuning mixture to be the most effective method to teach BLOOMZ a new language. We conclude that with sufficient training data language adaptation can generalize well to diverse languages. Our code is available at \url{https://github.com/bigscience-workshop/multilingual-modeling/}.
BLOOM: A 176B-Parameter Open-Access Multilingual Language Model
Nov 09, 2022Large language models (LLMs) have been shown to be able to perform new tasks based on a few demonstrations or natural language instructions. While these capabilities have led to widespread adoption, most LLMs are developed by resource-rich organizations and are frequently kept from the public. As a step towards democratizing this powerful technology, we present BLOOM, a 176B-parameter open-access language model designed and built thanks to a collaboration of hundreds of researchers. BLOOM is a decoder-only Transformer language model that was trained on the ROOTS corpus, a dataset comprising hundreds of sources in 46 natural and 13 programming languages (59 in total). We find that BLOOM achieves competitive performance on a wide variety of benchmarks, with stronger results after undergoing multitask prompted finetuning. To facilitate future research and applications using LLMs, we publicly release our models and code under the Responsible AI License.
How Much Does Attention Actually Attend? Questioning the Importance of Attention in Pretrained Transformers
Nov 07, 2022



The attention mechanism is considered the backbone of the widely-used Transformer architecture. It contextualizes the input by computing input-specific attention matrices. We find that this mechanism, while powerful and elegant, is not as important as typically thought for pretrained language models. We introduce PAPA, a new probing method that replaces the input-dependent attention matrices with constant ones -- the average attention weights over multiple inputs. We use PAPA to analyze several established pretrained Transformers on six downstream tasks. We find that without any input-dependent attention, all models achieve competitive performance -- an average relative drop of only 8% from the probing baseline. Further, little or no performance drop is observed when replacing half of the input-dependent attention matrices with constant (input-independent) ones. Interestingly, we show that better-performing models lose more from applying our method than weaker models, suggesting that the utilization of the input-dependent attention mechanism might be a factor in their success. Our results motivate research on simpler alternatives to input-dependent attention, as well as on methods for better utilization of this mechanism in the Transformer architecture.
Selective Annotation Makes Language Models Better Few-Shot Learners
Sep 05, 2022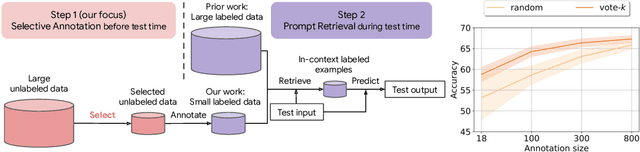
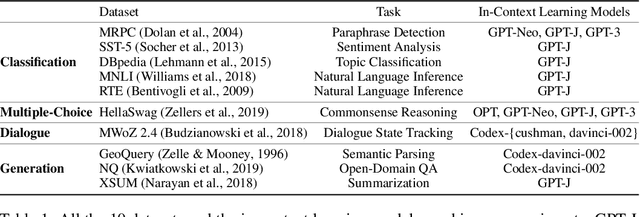
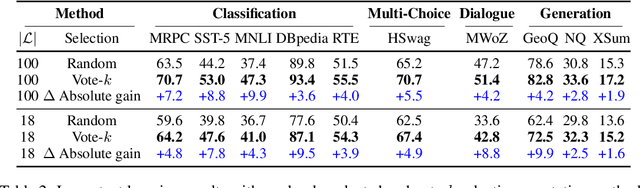
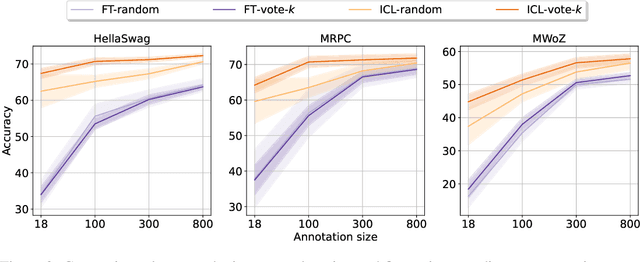
Many recent approaches to natural language tasks are built on the remarkable abilities of large language models. Large language models can perform in-context learning, where they learn a new task from a few task demonstrations, without any parameter updates. This work examines the implications of in-context learning for the creation of datasets for new natural language tasks. Departing from recent in-context learning methods, we formulate an annotation-efficient, two-step framework: selective annotation that chooses a pool of examples to annotate from unlabeled data in advance, followed by prompt retrieval that retrieves task examples from the annotated pool at test time. Based on this framework, we propose an unsupervised, graph-based selective annotation method, voke-k, to select diverse, representative examples to annotate. Extensive experiments on 10 datasets (covering classification, commonsense reasoning, dialogue, and text/code generation) demonstrate that our selective annotation method improves the task performance by a large margin. On average, vote-k achieves a 12.9%/11.4% relative gain under an annotation budget of 18/100, as compared to randomly selecting examples to annotate. Compared to state-of-the-art supervised finetuning approaches, it yields similar performance with 10-100x less annotation cost across 10 tasks. We further analyze the effectiveness of our framework in various scenarios: language models with varying sizes, alternative selective annotation methods, and cases where there is a test data domain shift. We hope that our studies will serve as a basis for data annotations as large language models are increasingly applied to new tasks. Our code is available at https://github.com/HKUNLP/icl-selective-annotation.
FOLIO: Natural Language Reasoning with First-Order Logic
Sep 02, 2022
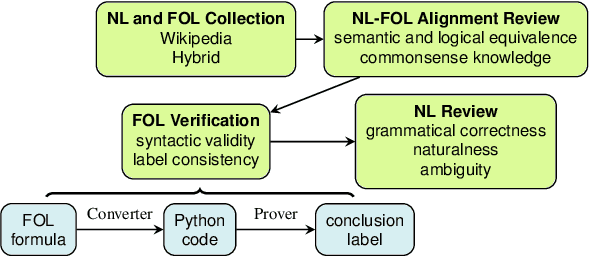
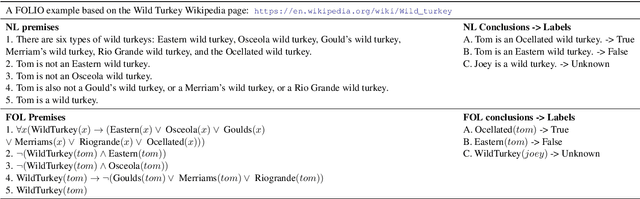
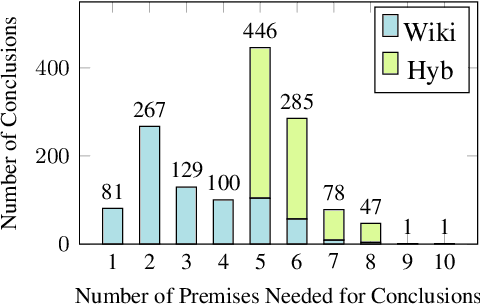
We present FOLIO, a human-annotated, open-domain, and logically complex and diverse dataset for reasoning in natural language (NL), equipped with first order logic (FOL) annotations. FOLIO consists of 1,435 examples (unique conclusions), each paired with one of 487 sets of premises which serve as rules to be used to deductively reason for the validity of each conclusion. The logical correctness of premises and conclusions is ensured by their parallel FOL annotations, which are automatically verified by our FOL inference engine. In addition to the main NL reasoning task, NL-FOL pairs in FOLIO automatically constitute a new NL-FOL translation dataset using FOL as the logical form. Our experiments on FOLIO systematically evaluate the FOL reasoning ability of supervised fine-tuning on medium-sized language models (BERT, RoBERTa) and few-shot prompting on large language models (GPT-NeoX, OPT, GPT-3, Codex). For NL-FOL translation, we experiment with GPT-3 and Codex. Our results show that one of the most capable Large Language Model (LLM) publicly available, GPT-3 davinci, achieves only slightly better than random results with few-shot prompting on a subset of FOLIO, and the model is especially bad at predicting the correct truth values for False and Unknown conclusions. Our dataset and code are available at https://github.com/Yale-LILY/FOLIO.
RealTime QA: What's the Answer Right Now?
Jul 27, 2022
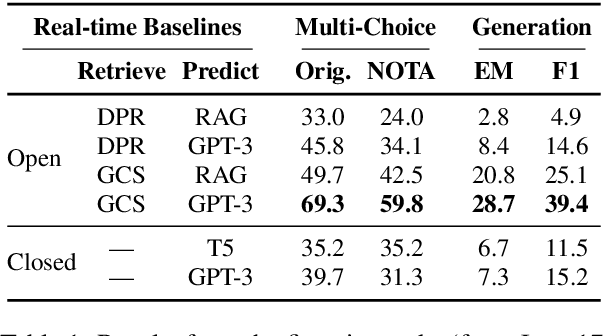
We introduce RealTime QA, a dynamic question answering (QA) platform that announces questions and evaluates systems on a regular basis (weekly in this version). RealTime QA inquires about the current world, and QA systems need to answer questions about novel events or information. It therefore challenges static, conventional assumptions in open domain QA datasets and pursues, instantaneous applications. We build strong baseline models upon large pretrained language models, including GPT-3 and T5. Our benchmark is an ongoing effort, and this preliminary report presents real-time evaluation results over the past month. Our experimental results show that GPT-3 can often properly update its generation results, based on newly-retrieved documents, highlighting the importance of up-to-date information retrieval. Nonetheless, we find that GPT-3 tends to return outdated answers when retrieved documents do not provide sufficient information to find an answer. This suggests an important avenue for future research: can an open domain QA system identify such unanswerable cases and communicate with the user or even the retrieval module to modify the retrieval results? We hope that RealTime QA will spur progress in instantaneous applications of question answering and beyond.
MIA 2022 Shared Task: Evaluating Cross-lingual Open-Retrieval Question Answering for 16 Diverse Languages
Jul 02, 2022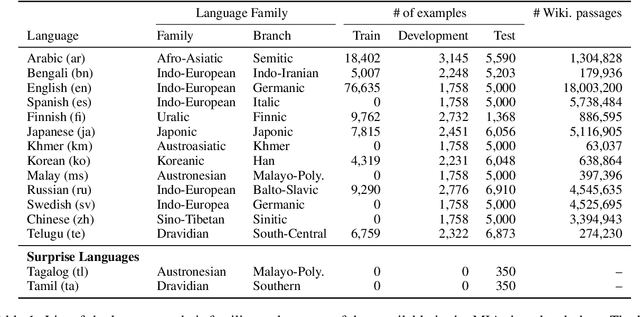
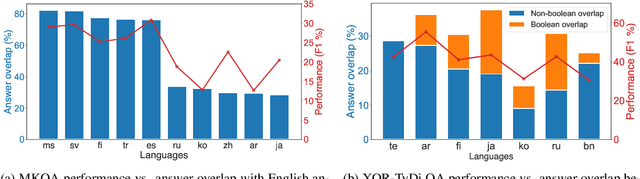
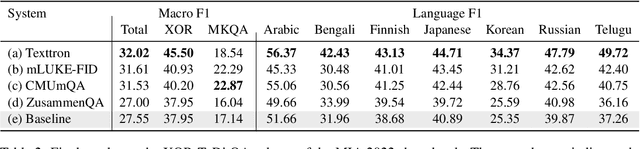
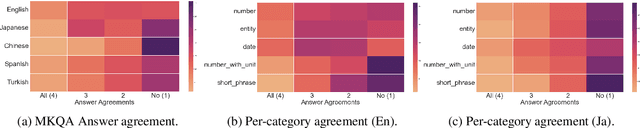
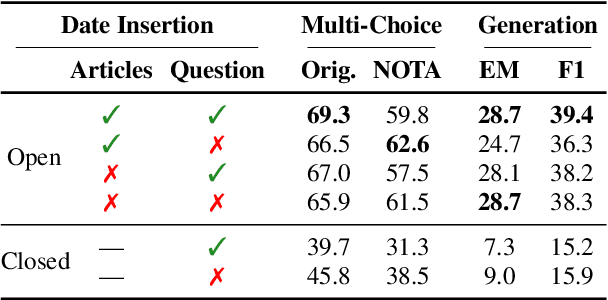
We present the results of the Workshop on Multilingual Information Access (MIA) 2022 Shared Task, evaluating cross-lingual open-retrieval question answering (QA) systems in 16 typologically diverse languages. In this task, we adapted two large-scale cross-lingual open-retrieval QA datasets in 14 typologically diverse languages, and newly annotated open-retrieval QA data in 2 underrepresented languages: Tagalog and Tamil. Four teams submitted their systems. The best system leveraging iteratively mined diverse negative examples and larger pretrained models achieves 32.2 F1, outperforming our baseline by 4.5 points. The second best system uses entity-aware contextualized representations for document retrieval, and achieves significant improvements in Tamil (20.8 F1), whereas most of the other systems yield nearly zero scores.
Twist Decoding: Diverse Generators Guide Each Other
May 19, 2022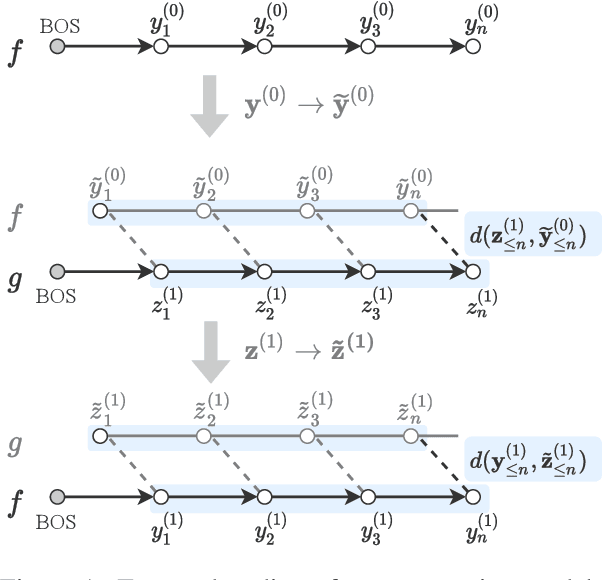
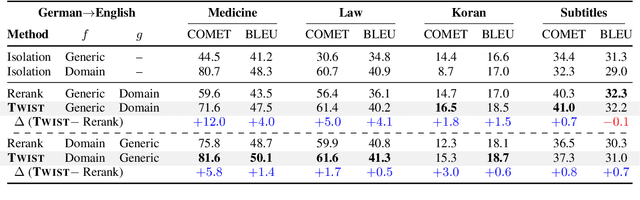

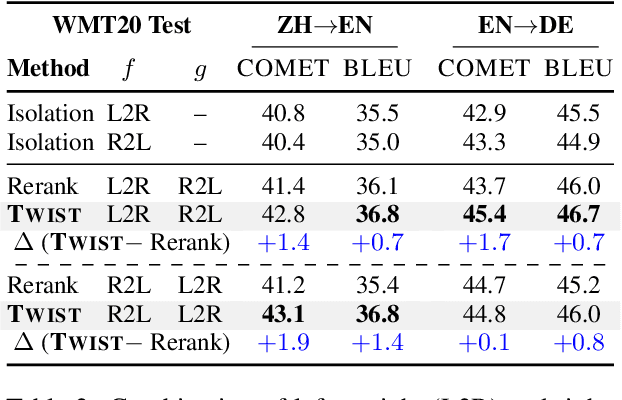
Natural language generation technology has recently seen remarkable progress with large-scale training, and many natural language applications are now built upon a wide range of generation models. Combining diverse models may lead to further progress, but conventional ensembling (e.g., shallow fusion) requires that they share vocabulary/tokenization schemes. We introduce Twist decoding, a simple and general inference algorithm that generates text while benefiting from diverse models. Our method does not assume the vocabulary, tokenization or even generation order is shared. Our extensive evaluations on machine translation and scientific paper summarization demonstrate that Twist decoding substantially outperforms each model decoded in isolation over various scenarios, including cases where domain-specific and general-purpose models are both available. Twist decoding also consistently outperforms the popular reranking heuristic where output candidates from one model is rescored by another. We hope that our work will encourage researchers and practitioners to examine generation models collectively, not just independently, and to seek out models with complementary strengths to the currently available models.
Beam Decoding with Controlled Patience
Apr 29, 2022
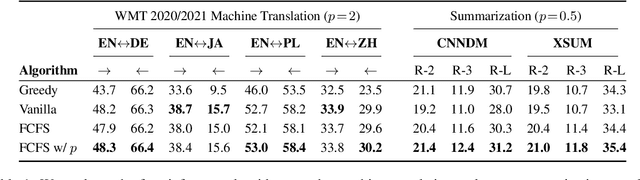


Text generation with beam search has proven successful in a wide range of applications. The commonly-used implementation of beam decoding follows a first come, first served heuristic: it keeps a set of already completed sequences over time steps and stops when the size of this set reaches the beam size. We introduce a patience factor, a simple modification to this decoding algorithm, that generalizes the stopping criterion and provides flexibility to the depth of search. Extensive empirical results demonstrate that the patience factor improves decoding performance of strong pretrained models on news text summarization and machine translation over diverse language pairs, with a negligible inference slowdown. Our approach only modifies one line of code and can be thus readily incorporated in any implementation.
NeuroLogic A*esque Decoding: Constrained Text Generation with Lookahead Heuristics
Dec 16, 2021

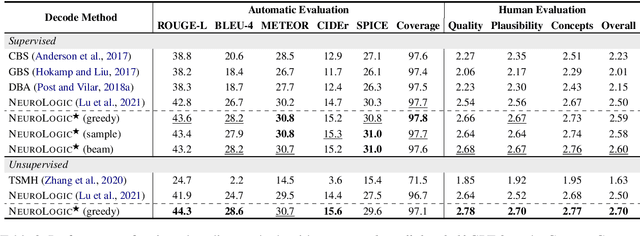
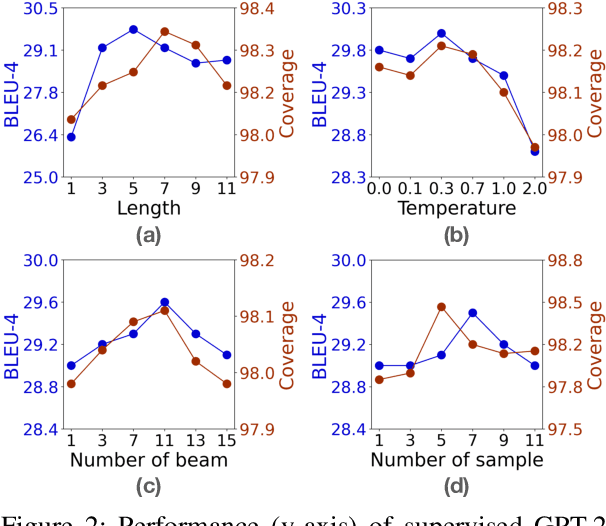
The dominant paradigm for neural text generation is left-to-right decoding from autoregressive language models. Constrained or controllable generation under complex lexical constraints, however, requires foresight to plan ahead feasible future paths. Drawing inspiration from the A* search algorithm, we propose NeuroLogic A*esque, a decoding algorithm that incorporates heuristic estimates of future cost. We develop efficient lookahead heuristics that are efficient for large-scale language models, making our method a drop-in replacement for common techniques such as beam search and top-k sampling. To enable constrained generation, we build on NeuroLogic decoding (Lu et al., 2021), combining its flexibility in incorporating logical constraints with A*esque estimates of future constraint satisfaction. Our approach outperforms competitive baselines on five generation tasks, and achieves new state-of-the-art performance on table-to-text generation, constrained machine translation, and keyword-constrained generation. The improvements are particularly notable on tasks that require complex constraint satisfaction or in few-shot or zero-shot settings. NeuroLogic A*esque illustrates the power of decoding for improving and enabling new capabilities of large-scale language models.