 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWideSeek: Advancing Wide Research via Multi-Agent Scaling
Feb 02, 2026Search intelligence is evolving from Deep Research to Wide Research, a paradigm essential for retrieving and synthesizing comprehensive information under complex constraints in parallel. However, progress in this field is impeded by the lack of dedicated benchmarks and optimization methodologies for search breadth. To address these challenges, we take a deep dive into Wide Research from two perspectives: Data Pipeline and Agent Optimization. First, we produce WideSeekBench, a General Broad Information Seeking (GBIS) benchmark constructed via a rigorous multi-phase data pipeline to ensure diversity across the target information volume, logical constraints, and domains. Second, we introduce WideSeek, a dynamic hierarchical multi-agent architecture that can autonomously fork parallel sub-agents based on task requirements. Furthermore, we design a unified training framework that linearizes multi-agent trajectories and optimizes the system using end-to-end RL. Experimental results demonstrate the effectiveness of WideSeek and multi-agent RL, highlighting that scaling the number of agents is a promising direction for advancing the Wide Research paradigm.
S$^2$GR: Stepwise Semantic-Guided Reasoning in Latent Space for Generative Recommendation
Jan 26, 2026Generative Recommendation (GR) has emerged as a transformative paradigm with its end-to-end generation advantages. However, existing GR methods primarily focus on direct Semantic ID (SID) generation from interaction sequences, failing to activate deeper reasoning capabilities analogous to those in large language models and thus limiting performance potential. We identify two critical limitations in current reasoning-enhanced GR approaches: (1) Strict sequential separation between reasoning and generation steps creates imbalanced computational focus across hierarchical SID codes, degrading quality for SID codes; (2) Generated reasoning vectors lack interpretable semantics, while reasoning paths suffer from unverifiable supervision. In this paper, we propose stepwise semantic-guided reasoning in latent space (S$^2$GR), a novel reasoning enhanced GR framework. First, we establish a robust semantic foundation via codebook optimization, integrating item co-occurrence relationship to capture behavioral patterns, and load balancing and uniformity objectives that maximize codebook utilization while reinforcing coarse-to-fine semantic hierarchies. Our core innovation introduces the stepwise reasoning mechanism inserting thinking tokens before each SID generation step, where each token explicitly represents coarse-grained semantics supervised via contrastive learning against ground-truth codebook cluster distributions ensuring physically grounded reasoning paths and balanced computational focus across all SID codes. Extensive experiments demonstrate the superiority of S$^2$GR, and online A/B test confirms efficacy on large-scale industrial short video platform.
Which Reasoning Trajectories Teach Students to Reason Better? A Simple Metric of Informative Alignment
Jan 20, 2026Long chain-of-thought (CoT) trajectories provide rich supervision signals for distilling reasoning from teacher to student LLMs. However, both prior work and our experiments show that trajectories from stronger teachers do not necessarily yield better students, highlighting the importance of data-student suitability in distillation. Existing methods assess suitability primarily through student likelihood, favoring trajectories that closely align with the model's current behavior but overlooking more informative ones. Addressing this, we propose Rank-Surprisal Ratio (RSR), a simple metric that captures both alignment and informativeness to assess the suitability of a reasoning trajectory. RSR is motivated by the observation that effective trajectories typically combine low absolute probability with relatively high-ranked tokens under the student model, balancing learning signal strength and behavioral alignment. Concretely, RSR is defined as the ratio of a trajectory's average token-wise rank to its average negative log-likelihood, and is straightforward to compute and interpret. Across five student models and reasoning trajectories from 11 diverse teachers, RSR strongly correlates with post-training performance (average Spearman 0.86), outperforming existing metrics. We further demonstrate its practical utility in both trajectory selection and teacher selection.
Enhancing Image Quality Assessment Ability of LMMs via Retrieval-Augmented Generation
Jan 13, 2026Large Multimodal Models (LMMs) have recently shown remarkable promise in low-level visual perception tasks, particularly in Image Quality Assessment (IQA), demonstrating strong zero-shot capability. However, achieving state-of-the-art performance often requires computationally expensive fine-tuning methods, which aim to align the distribution of quality-related token in output with image quality levels. Inspired by recent training-free works for LMM, we introduce IQARAG, a novel, training-free framework that enhances LMMs' IQA ability. IQARAG leverages Retrieval-Augmented Generation (RAG) to retrieve some semantically similar but quality-variant reference images with corresponding Mean Opinion Scores (MOSs) for input image. These retrieved images and input image are integrated into a specific prompt. Retrieved images provide the LMM with a visual perception anchor for IQA task. IQARAG contains three key phases: Retrieval Feature Extraction, Image Retrieval, and Integration & Quality Score Generation. Extensive experiments across multiple diverse IQA datasets, including KADID, KonIQ, LIVE Challenge, and SPAQ, demonstrate that the proposed IQARAG effectively boosts the IQA performance of LMMs, offering a resource-efficient alternative to fine-tuning for quality assessment.
Learning How to Remember: A Meta-Cognitive Management Method for Structured and Transferable Agent Memory
Jan 12, 2026Large language model (LLM) agents increasingly rely on accumulated memory to solve long-horizon decision-making tasks. However, most existing approaches store memory in fixed representations and reuse it at a single or implicit level of abstraction, which limits generalization and often leads to negative transfer when distribution shift. This paper proposes the Meta-Cognitive Memory Abstraction method (MCMA), which treats memory abstraction as a learnable cognitive skill rather than a fixed design choice. MCMA decouples task execution from memory management by combining a frozen task model with a learned memory copilot. The memory copilot is trained using direct preference optimization, it determines how memories should be structured, abstracted, and reused. Memories are further organized into a hierarchy of abstraction levels, enabling selective reuse based on task similarity. When no memory is transferable, MCMA transfers the ability to abstract and manage memory by transferring the memory copilot. Experiments on ALFWorld, ScienceWorld, and BabyAI demonstrate substantial improvements in performance, out-of-distribution generalization, and cross-task transfer over several baselines.
Bottom-up Policy Optimization: Your Language Model Policy Secretly Contains Internal Policies
Dec 22, 2025



Existing reinforcement learning (RL) approaches treat large language models (LLMs) as a single unified policy, overlooking their internal mechanisms. Understanding how policy evolves across layers and modules is therefore crucial for enabling more targeted optimization and raveling out complex reasoning mechanisms. In this paper, we decompose the language model policy by leveraging the intrinsic split of the Transformer residual stream and the equivalence between the composition of hidden states with the unembedding matrix and the resulting samplable policy. This decomposition reveals Internal Layer Policies, corresponding to contributions from individual layers, and Internal Modular Policies, which align with the self-attention and feed-forward network (FFN) components within each layer. By analyzing the entropy of internal policy, we find that: (a) Early layers keep high entropy for exploration, top layers converge to near-zero entropy for refinement, with convergence patterns varying across model series. (b) LLama's prediction space rapidly converges in the final layer, whereas Qwen-series models, especially Qwen3, exhibit a more human-like, progressively structured reasoning pattern. Motivated by these findings, we propose Bottom-up Policy Optimization (BuPO), a novel RL paradigm that directly optimizes the internal layer policy during early training. By aligning training objective at lower layer, BuPO reconstructs foundational reasoning capabilities and achieves superior performance. Extensive experiments on complex reasoning benchmarks demonstrates the effectiveness of our method. Our code is available at https://github.com/Trae1ounG/BuPO.
Bias-Restrained Prefix Representation Finetuning for Mathematical Reasoning
Nov 13, 2025



Parameter-Efficient finetuning (PEFT) enhances model performance on downstream tasks by updating a minimal subset of parameters. Representation finetuning (ReFT) methods further improve efficiency by freezing model weights and optimizing internal representations with fewer parameters than PEFT, outperforming PEFT on several tasks. However, ReFT exhibits a significant performance decline on mathematical reasoning tasks. To address this problem, the paper demonstrates that ReFT's poor performance on mathematical tasks primarily stems from its struggle to generate effective reasoning prefixes during the early inference phase. Moreover, ReFT disturbs the numerical encoding and the error accumulats during the CoT stage. Based on these observations, this paper proposes Bias-REstrained Prefix Representation FineTuning (BREP ReFT), which enhances ReFT's mathematical reasoning capability by truncating training data to optimize the generation of initial reasoning prefixes, intervening on the early inference stage to prevent error accumulation, and constraining the intervention vectors' magnitude to avoid disturbing numerical encoding. Extensive experiments across diverse model architectures demonstrate BREP's superior effectiveness, efficiency, and robust generalization capability, outperforming both standard ReFT and weight-based PEFT methods on the task of mathematical reasoning. The source code is available at https://github.com/LiangThree/BREP.
Thinking with Video: Video Generation as a Promising Multimodal Reasoning Paradigm
Nov 06, 2025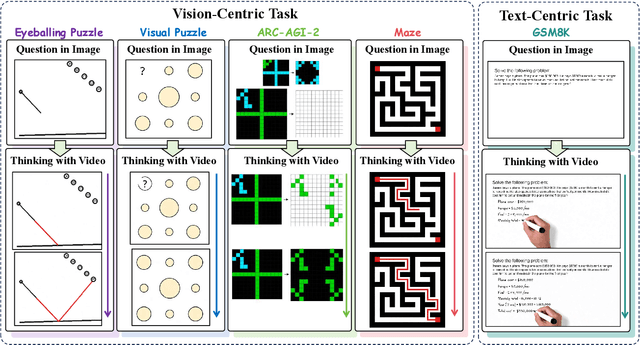
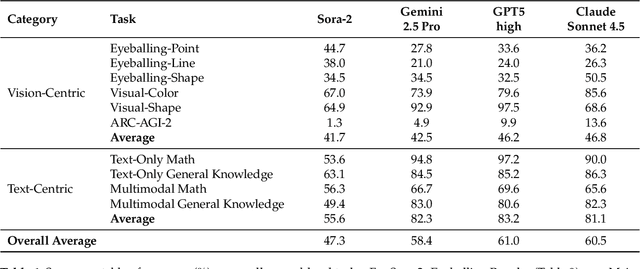
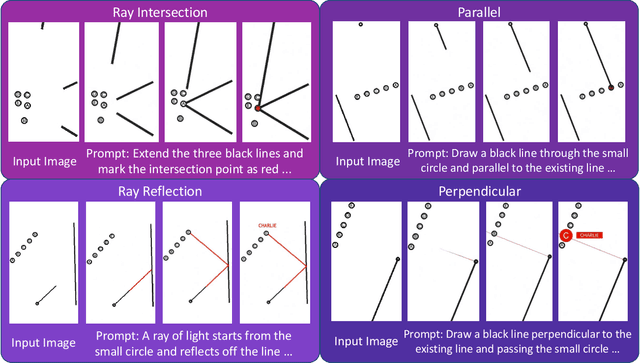

"Thinking with Text" and "Thinking with Images" paradigm significantly improve the reasoning ability of large language models (LLMs) and Vision Language Models (VLMs). However, these paradigms have inherent limitations. (1) Images capture only single moments and fail to represent dynamic processes or continuous changes, and (2) The separation of text and vision as distinct modalities, hindering unified multimodal understanding and generation. To overcome these limitations, we introduce "Thinking with Video", a new paradigm that leverages video generation models, such as Sora-2, to bridge visual and textual reasoning in a unified temporal framework. To support this exploration, we developed the Video Thinking Benchmark (VideoThinkBench). VideoThinkBench encompasses two task categories: (1) vision-centric tasks (e.g., Eyeballing Puzzles), and (2) text-centric tasks (e.g., subsets of GSM8K, MMMU). Our evaluation establishes Sora-2 as a capable reasoner. On vision-centric tasks, Sora-2 is generally comparable to state-of-the-art (SOTA) VLMs, and even surpasses VLMs on several tasks, such as Eyeballing Games. On text-centric tasks, Sora-2 achieves 92% accuracy on MATH, and 75.53% accuracy on MMMU. Furthermore, we systematically analyse the source of these abilities. We also find that self-consistency and in-context learning can improve Sora-2's performance. In summary, our findings demonstrate that the video generation model is the potential unified multimodal understanding and generation model, positions "thinking with video" as a unified multimodal reasoning paradigm.
InfoFlow: Reinforcing Search Agent Via Reward Density Optimization
Oct 30, 2025Reinforcement Learning with Verifiable Rewards (RLVR) is a promising approach for enhancing agentic deep search. However, its application is often hindered by low \textbf{Reward Density} in deep search scenarios, where agents expend significant exploratory costs for infrequent and often null final rewards. In this paper, we formalize this challenge as the \textbf{Reward Density Optimization} problem, which aims to improve the reward obtained per unit of exploration cost. This paper introduce \textbf{InfoFlow}, a systematic framework that tackles this problem from three aspects. 1) \textbf{Subproblem decomposition}: breaking down long-range tasks to assign process rewards, thereby providing denser learning signals. 2) \textbf{Failure-guided hints}: injecting corrective guidance into stalled trajectories to increase the probability of successful outcomes. 3) \textbf{Dual-agent refinement}: employing a dual-agent architecture to offload the cognitive burden of deep exploration. A refiner agent synthesizes the search history, which effectively compresses the researcher's perceived trajectory, thereby reducing exploration cost and increasing the overall reward density. We evaluate InfoFlow on multiple agentic search benchmarks, where it significantly outperforms strong baselines, enabling lightweight LLMs to achieve performance comparable to advanced proprietary LLMs.
The Zero-Step Thinking: An Empirical Study of Mode Selection as Harder Early Exit in Reasoning Models
Oct 22, 2025Reasoning models have demonstrated exceptional performance in tasks such as mathematics and logical reasoning, primarily due to their ability to engage in step-by-step thinking during the reasoning process. However, this often leads to overthinking, resulting in unnecessary computational overhead. To address this issue, Mode Selection aims to automatically decide between Long-CoT (Chain-of-Thought) or Short-CoT by utilizing either a Thinking or NoThinking mode. Simultaneously, Early Exit determines the optimal stopping point during the iterative reasoning process. Both methods seek to reduce the computational burden. In this paper, we first identify Mode Selection as a more challenging variant of the Early Exit problem, as they share similar objectives but differ in decision timing. While Early Exit focuses on determining the best stopping point for concise reasoning at inference time, Mode Selection must make this decision at the beginning of the reasoning process, relying on pre-defined fake thoughts without engaging in an explicit reasoning process, referred to as zero-step thinking. Through empirical studies on nine baselines, we observe that prompt-based approaches often fail due to their limited classification capabilities when provided with minimal hand-crafted information. In contrast, approaches that leverage internal information generally perform better across most scenarios but still exhibit issues with stability. Our findings indicate that existing methods relying solely on the information provided by models are insufficient for effectively addressing Mode Selection in scenarios with limited information, highlighting the ongoing challenges of this task. Our code is available at https://github.com/Trae1ounG/Zero_Step_Thinking.