 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSSCL-BW: Sample-Specific Clean-Label Backdoor Watermarking for Dataset Ownership Verification
Oct 30, 2025The rapid advancement of deep neural networks (DNNs) heavily relies on large-scale, high-quality datasets. However, unauthorized commercial use of these datasets severely violates the intellectual property rights of dataset owners. Existing backdoor-based dataset ownership verification methods suffer from inherent limitations: poison-label watermarks are easily detectable due to label inconsistencies, while clean-label watermarks face high technical complexity and failure on high-resolution images. Moreover, both approaches employ static watermark patterns that are vulnerable to detection and removal. To address these issues, this paper proposes a sample-specific clean-label backdoor watermarking (i.e., SSCL-BW). By training a U-Net-based watermarked sample generator, this method generates unique watermarks for each sample, fundamentally overcoming the vulnerability of static watermark patterns. The core innovation lies in designing a composite loss function with three components: target sample loss ensures watermark effectiveness, non-target sample loss guarantees trigger reliability, and perceptual similarity loss maintains visual imperceptibility. During ownership verification, black-box testing is employed to check whether suspicious models exhibit predefined backdoor behaviors. Extensive experiments on benchmark datasets demonstrate the effectiveness of the proposed method and its robustness against potential watermark removal attacks.
Cert-SSB: Toward Certified Sample-Specific Backdoor Defense
Apr 30, 2025Deep neural networks (DNNs) are vulnerable to backdoor attacks, where an attacker manipulates a small portion of the training data to implant hidden backdoors into the model. The compromised model behaves normally on clean samples but misclassifies backdoored samples into the attacker-specified target class, posing a significant threat to real-world DNN applications. Currently, several empirical defense methods have been proposed to mitigate backdoor attacks, but they are often bypassed by more advanced backdoor techniques. In contrast, certified defenses based on randomized smoothing have shown promise by adding random noise to training and testing samples to counteract backdoor attacks. In this paper, we reveal that existing randomized smoothing defenses implicitly assume that all samples are equidistant from the decision boundary. However, it may not hold in practice, leading to suboptimal certification performance. To address this issue, we propose a sample-specific certified backdoor defense method, termed Cert-SSB. Cert-SSB first employs stochastic gradient ascent to optimize the noise magnitude for each sample, ensuring a sample-specific noise level that is then applied to multiple poisoned training sets to retrain several smoothed models. After that, Cert-SSB aggregates the predictions of multiple smoothed models to generate the final robust prediction. In particular, in this case, existing certification methods become inapplicable since the optimized noise varies across different samples. To conquer this challenge, we introduce a storage-update-based certification method, which dynamically adjusts each sample's certification region to improve certification performance. We conduct extensive experiments on multiple benchmark datasets, demonstrating the effectiveness of our proposed method. Our code is available at https://github.com/NcepuQiaoTing/Cert-SSB.
STBA: Towards Evaluating the Robustness of DNNs for Query-Limited Black-box Scenario
Mar 30, 2024



Many attack techniques have been proposed to explore the vulnerability of DNNs and further help to improve their robustness. Despite the significant progress made recently, existing black-box attack methods still suffer from unsatisfactory performance due to the vast number of queries needed to optimize desired perturbations. Besides, the other critical challenge is that adversarial examples built in a noise-adding manner are abnormal and struggle to successfully attack robust models, whose robustness is enhanced by adversarial training against small perturbations. There is no doubt that these two issues mentioned above will significantly increase the risk of exposure and result in a failure to dig deeply into the vulnerability of DNNs. Hence, it is necessary to evaluate DNNs' fragility sufficiently under query-limited settings in a non-additional way. In this paper, we propose the Spatial Transform Black-box Attack (STBA), a novel framework to craft formidable adversarial examples in the query-limited scenario. Specifically, STBA introduces a flow field to the high-frequency part of clean images to generate adversarial examples and adopts the following two processes to enhance their naturalness and significantly improve the query efficiency: a) we apply an estimated flow field to the high-frequency part of clean images to generate adversarial examples instead of introducing external noise to the benign image, and b) we leverage an efficient gradient estimation method based on a batch of samples to optimize such an ideal flow field under query-limited settings. Compared to existing score-based black-box baselines, extensive experiments indicated that STBA could effectively improve the imperceptibility of the adversarial examples and remarkably boost the attack success rate under query-limited settings.
Cross-lingual Entity Alignment with Adversarial Kernel Embedding and Adversarial Knowledge Translation
Apr 16, 2021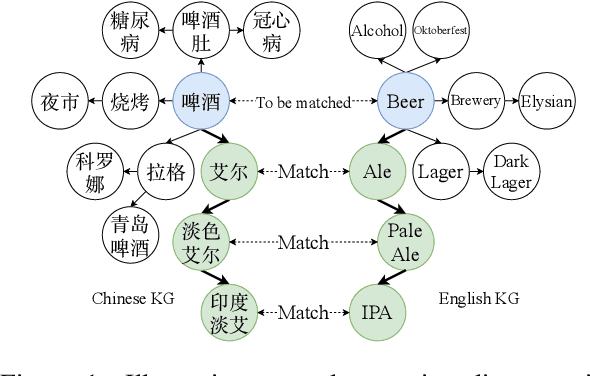
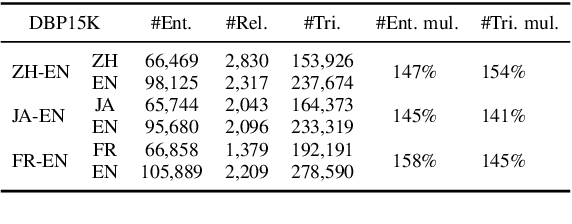
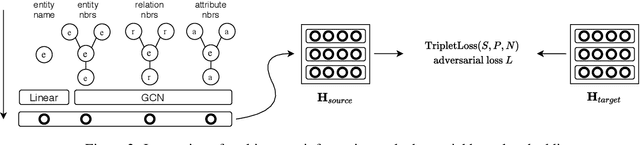
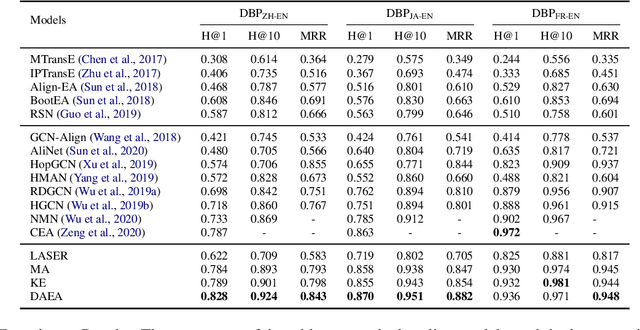
Cross-lingual entity alignment, which aims to precisely connect the same entities in different monolingual knowledge bases (KBs) together, often suffers challenges from feature inconsistency to sequence context unawareness. This paper presents a dual adversarial learning framework for cross-lingual entity alignment, DAEA, with two original contributions. First, in order to address the structural and attribute feature inconsistency between entities in two knowledge graphs (KGs), an adversarial kernel embedding technique is proposed to extract graph-invariant information in an unsupervised manner, and project two KGs into the common embedding space. Second, in order to further improve successful rate of entity alignment, we propose to produce multiple random walks through each entity to be aligned and mask these entities in random walks. With the guidance of known aligned entities in the context of multiple random walks, an adversarial knowledge translation model is developed to fill and translate masked entities in pairwise random walks from two KGs. Extensive experiments performed on real-world datasets show that DAEA can well solve the feature inconsistency and sequence context unawareness issues and significantly outperforms thirteen state-of-the-art entity alignment methods.