 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiagnosing Ensemble Few-Shot Classifiers
Jun 09, 2022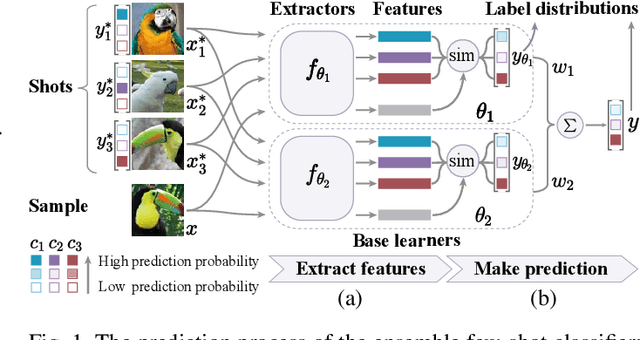
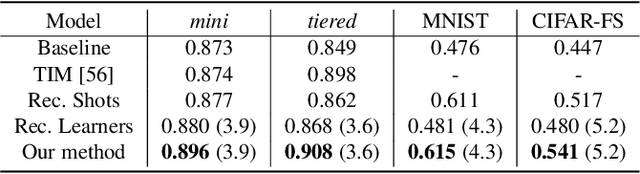
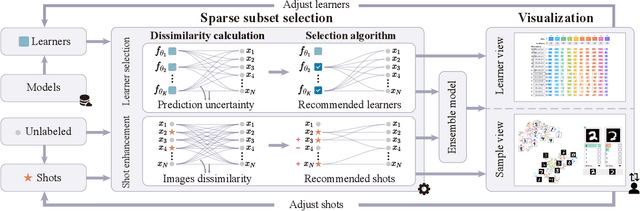

The base learners and labeled samples (shots) in an ensemble few-shot classifier greatly affect the model performance. When the performance is not satisfactory, it is usually difficult to understand the underlying causes and make improvements. To tackle this issue, we propose a visual analysis method, FSLDiagnotor. Given a set of base learners and a collection of samples with a few shots, we consider two problems: 1) finding a subset of base learners that well predict the sample collections; and 2) replacing the low-quality shots with more representative ones to adequately represent the sample collections. We formulate both problems as sparse subset selection and develop two selection algorithms to recommend appropriate learners and shots, respectively. A matrix visualization and a scatterplot are combined to explain the recommended learners and shots in context and facilitate users in adjusting them. Based on the adjustment, the algorithm updates the recommendation results for another round of improvement. Two case studies are conducted to demonstrate that FSLDiagnotor helps build a few-shot classifier efficiently and increases the accuracy by 12% and 21%, respectively.
GSmooth: Certified Robustness against Semantic Transformations via Generalized Randomized Smoothing
Jun 09, 2022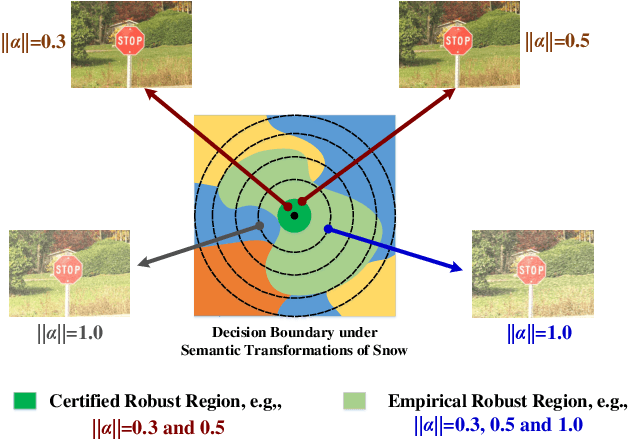
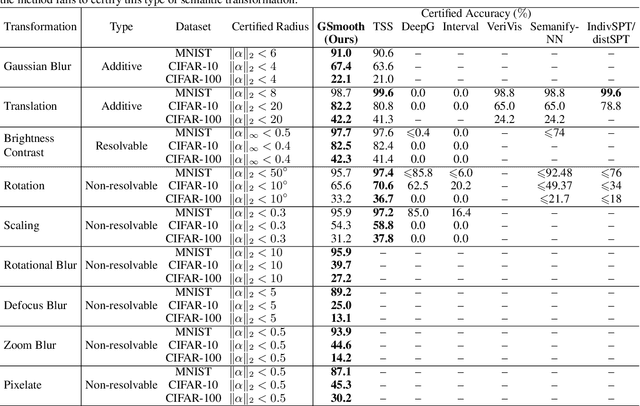
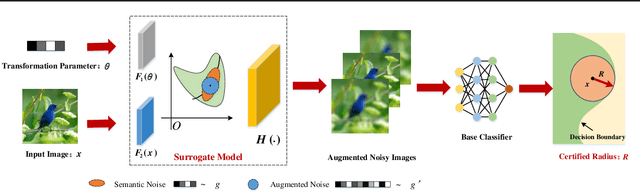
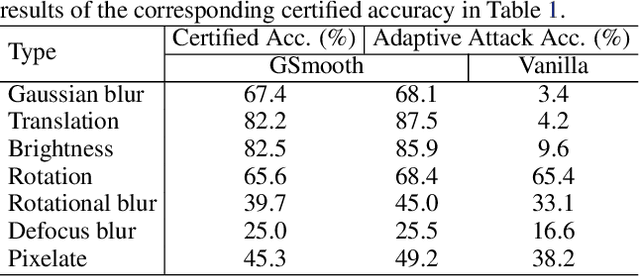
Certified defenses such as randomized smoothing have shown promise towards building reliable machine learning systems against $\ell_p$-norm bounded attacks. However, existing methods are insufficient or unable to provably defend against semantic transformations, especially those without closed-form expressions (such as defocus blur and pixelate), which are more common in practice and often unrestricted. To fill up this gap, we propose generalized randomized smoothing (GSmooth), a unified theoretical framework for certifying robustness against general semantic transformations via a novel dimension augmentation strategy. Under the GSmooth framework, we present a scalable algorithm that uses a surrogate image-to-image network to approximate the complex transformation. The surrogate model provides a powerful tool for studying the properties of semantic transformations and certifying robustness. Experimental results on several datasets demonstrate the effectiveness of our approach for robustness certification against multiple kinds of semantic transformations and corruptions, which is not achievable by the alternative baselines.
DPM-Solver: A Fast ODE Solver for Diffusion Probabilistic Model Sampling in Around 10 Steps
Jun 02, 2022
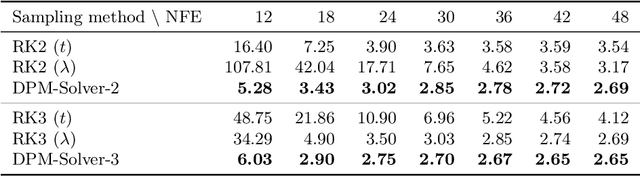
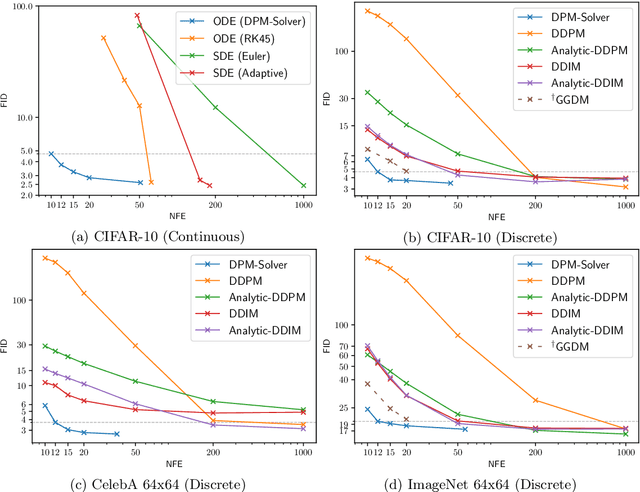
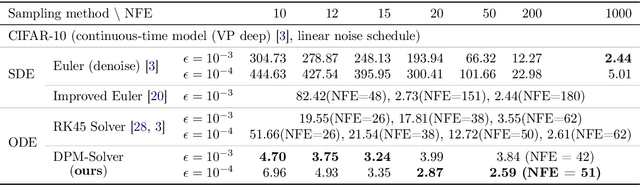
Diffusion probabilistic models (DPMs) are emerging powerful generative models. Despite their high-quality generation performance, DPMs still suffer from their slow sampling as they generally need hundreds or thousands of sequential function evaluations (steps) of large neural networks to draw a sample. Sampling from DPMs can be viewed alternatively as solving the corresponding diffusion ordinary differential equations (ODEs). In this work, we propose an exact formulation of the solution of diffusion ODEs. The formulation analytically computes the linear part of the solution, rather than leaving all terms to black-box ODE solvers as adopted in previous works. By applying change-of-variable, the solution can be equivalently simplified to an exponentially weighted integral of the neural network. Based on our formulation, we propose DPM-Solver, a fast dedicated high-order solver for diffusion ODEs with the convergence order guarantee. DPM-Solver is suitable for both discrete-time and continuous-time DPMs without any further training. Experimental results show that DPM-Solver can generate high-quality samples in only 10 to 20 function evaluations on various datasets. We achieve 4.70 FID in 10 function evaluations and 2.87 FID in 20 function evaluations on the CIFAR10 dataset, and a $4\sim 16\times$ speedup compared with previous state-of-the-art training-free samplers on various datasets.
BadDet: Backdoor Attacks on Object Detection
May 28, 2022
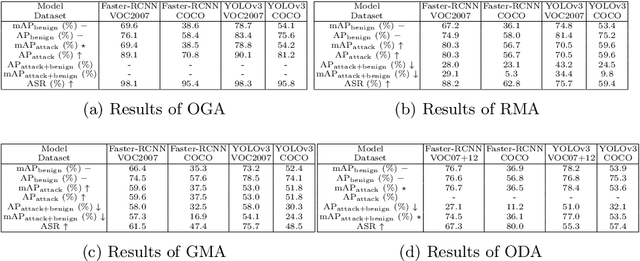


Deep learning models have been deployed in numerous real-world applications such as autonomous driving and surveillance. However, these models are vulnerable in adversarial environments. Backdoor attack is emerging as a severe security threat which injects a backdoor trigger into a small portion of training data such that the trained model behaves normally on benign inputs but gives incorrect predictions when the specific trigger appears. While most research in backdoor attacks focuses on image classification, backdoor attacks on object detection have not been explored but are of equal importance. Object detection has been adopted as an important module in various security-sensitive applications such as autonomous driving. Therefore, backdoor attacks on object detection could pose severe threats to human lives and properties. We propose four kinds of backdoor attacks for object detection task: 1) Object Generation Attack: a trigger can falsely generate an object of the target class; 2) Regional Misclassification Attack: a trigger can change the prediction of a surrounding object to the target class; 3) Global Misclassification Attack: a single trigger can change the predictions of all objects in an image to the target class; and 4) Object Disappearance Attack: a trigger can make the detector fail to detect the object of the target class. We develop appropriate metrics to evaluate the four backdoor attacks on object detection. We perform experiments using two typical object detection models -- Faster-RCNN and YOLOv3 on different datasets. More crucially, we demonstrate that even fine-tuning on another benign dataset cannot remove the backdoor hidden in the object detection model. To defend against these backdoor attacks, we propose Detector Cleanse, an entropy-based run-time detection framework to identify poisoned testing samples for any deployed object detector.
Censored Quantile Regression Neural Networks
May 26, 2022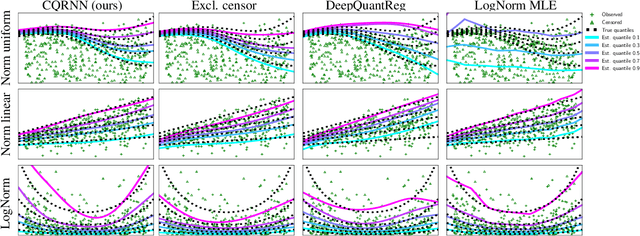
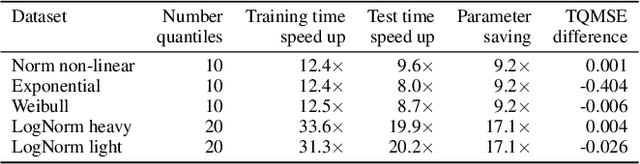
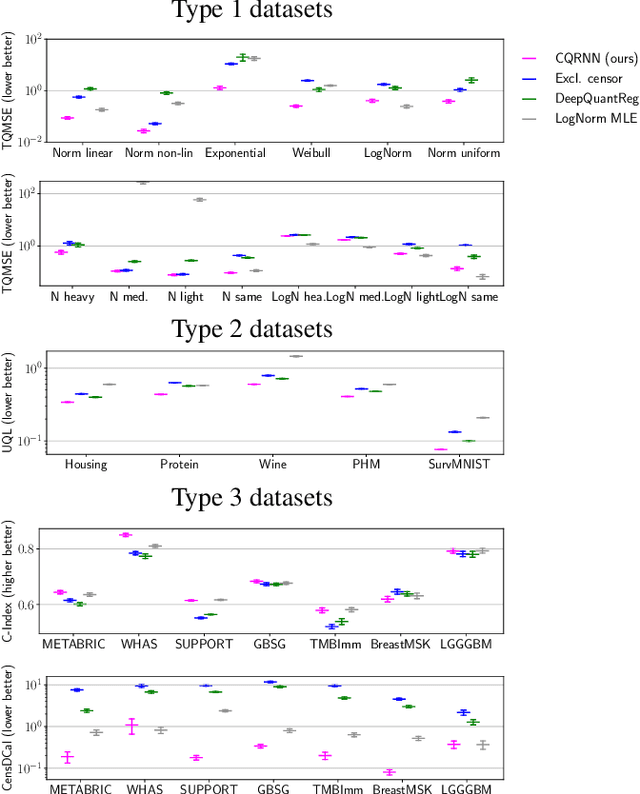
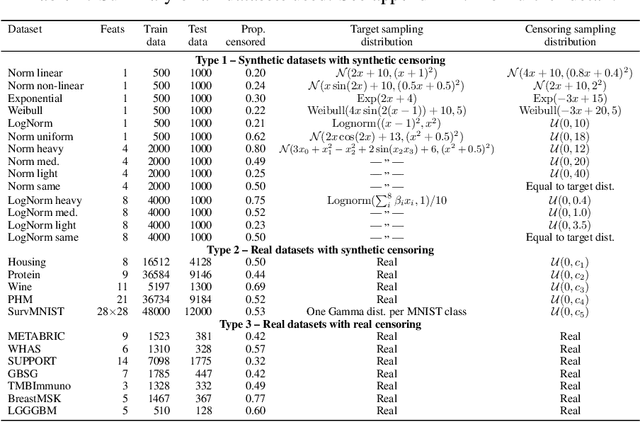
This paper considers doing quantile regression on censored data using neural networks (NNs). This adds to the survival analysis toolkit by allowing direct prediction of the target variable, along with a distribution-free characterisation of uncertainty, using a flexible function approximator. We begin by showing how an algorithm popular in linear models can be applied to NNs. However, the resulting procedure is inefficient, requiring sequential optimisation of an individual NN at each desired quantile. Our major contribution is a novel algorithm that simultaneously optimises a grid of quantiles output by a single NN. To offer theoretical insight into our algorithm, we show firstly that it can be interpreted as a form of expectation-maximisation, and secondly that it exhibits a desirable `self-correcting' property. Experimentally, the algorithm produces quantiles that are better calibrated than existing methods on 10 out of 12 real datasets.
Fast Instrument Learning with Faster Rates
May 22, 2022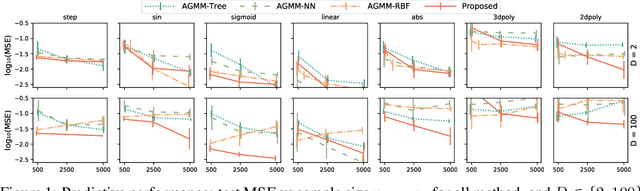
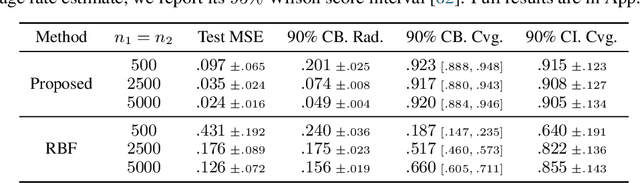


We investigate nonlinear instrumental variable (IV) regression given high-dimensional instruments. We propose a simple algorithm which combines kernelized IV methods and an arbitrary, adaptive regression algorithm, accessed as a black box. Our algorithm enjoys faster-rate convergence and adapts to the dimensionality of informative latent features, while avoiding an expensive minimax optimization procedure, which has been necessary to establish similar guarantees. It further brings the benefit of flexible machine learning models to quasi-Bayesian uncertainty quantification, likelihood-based model selection, and model averaging. Simulation studies demonstrate the competitive performance of our method.
NeuralEF: Deconstructing Kernels by Deep Neural Networks
Apr 30, 2022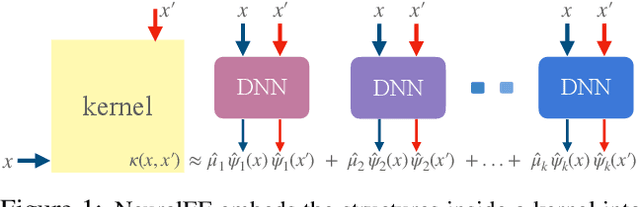

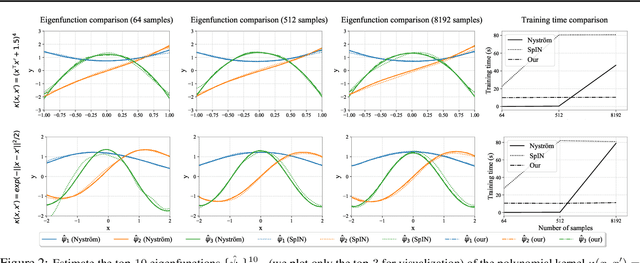
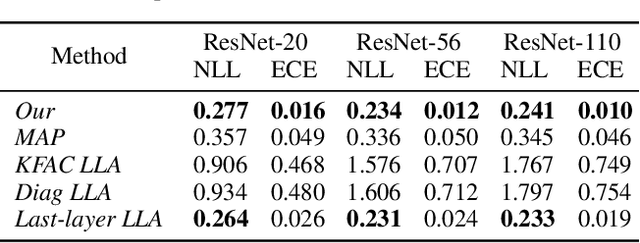
Learning the principal eigenfunctions of an integral operator defined by a kernel and a data distribution is at the core of many machine learning problems. Traditional nonparametric solutions based on the Nystr{\"o}m formula suffer from scalability issues. Recent work has resorted to a parametric approach, i.e., training neural networks to approximate the eigenfunctions. However, the existing method relies on an expensive orthogonalization step and is difficult to implement. We show that these problems can be fixed by using a new series of objective functions that generalizes the EigenGame~\citep{gemp2020eigengame} to function space. We test our method on a variety of supervised and unsupervised learning problems and show it provides accurate approximations to the eigenfunctions of polynomial, radial basis, neural network Gaussian process, and neural tangent kernels. Finally, we demonstrate our method can scale up linearised Laplace approximation of deep neural networks to modern image classification datasets through approximating the Gauss-Newton matrix.
Deep Ensemble as a Gaussian Process Approximate Posterior
Apr 30, 2022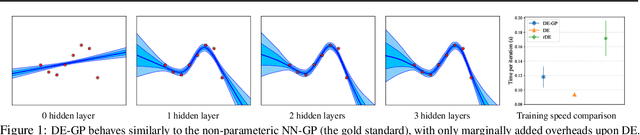
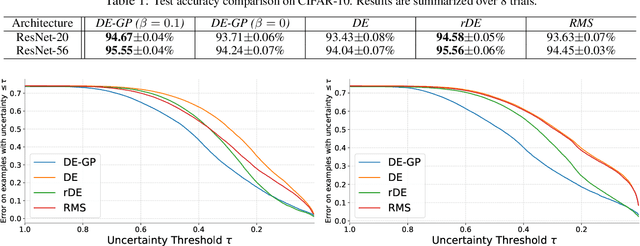
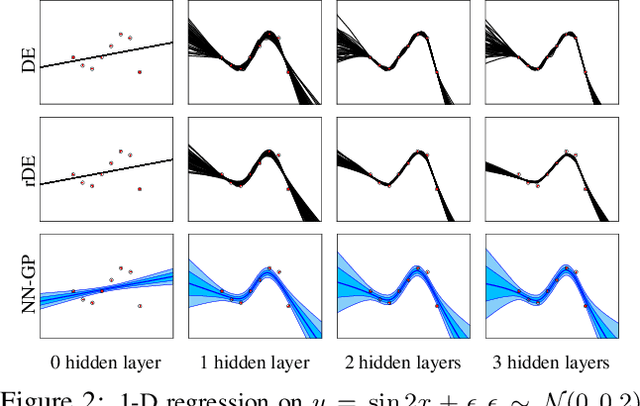

Deep Ensemble (DE) is an effective alternative to Bayesian neural networks for uncertainty quantification in deep learning. The uncertainty of DE is usually conveyed by the functional inconsistency among the ensemble members, say, the disagreement among their predictions. Yet, the functional inconsistency stems from unmanageable randomness and may easily collapse in specific cases. To render the uncertainty of DE reliable, we propose a refinement of DE where the functional inconsistency is explicitly characterized, and further tuned w.r.t. the training data and certain priori beliefs. Specifically, we describe the functional inconsistency with the empirical covariance of the functions dictated by ensemble members, which, along with the mean, define a Gaussian process (GP). Then, with specific priori uncertainty imposed, we maximize functional evidence lower bound to make the GP specified by DE approximate the Bayesian posterior. In this way, we relate DE to Bayesian inference to enjoy reliable Bayesian uncertainty. Moreover, we provide strategies to make the training efficient. Our approach consumes only marginally added training cost than the standard DE, but achieves better uncertainty quantification than DE and its variants across diverse scenarios.
DINO: DETR with Improved DeNoising Anchor Boxes for End-to-End Object Detection
Apr 07, 2022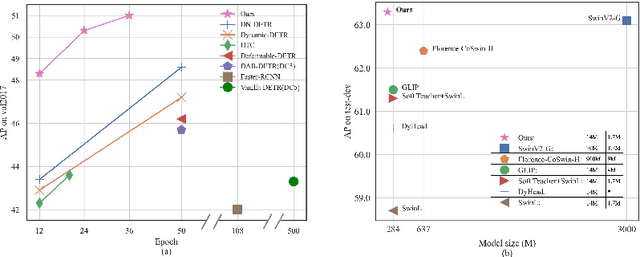
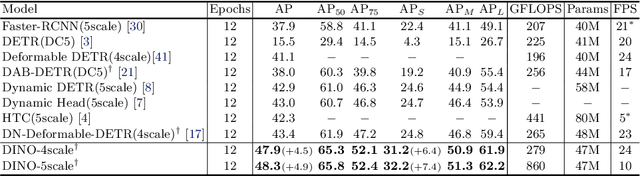
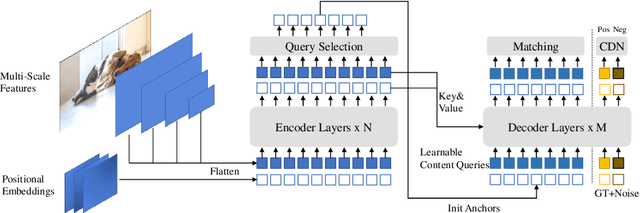
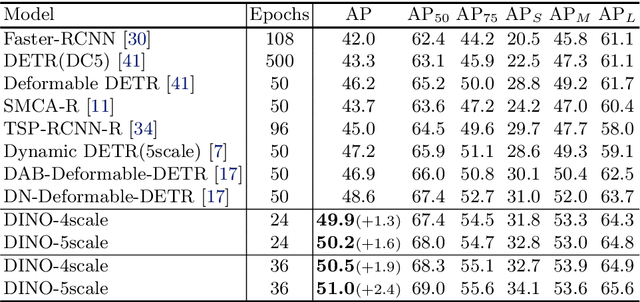
We present DINO (\textbf{D}ETR with \textbf{I}mproved de\textbf{N}oising anch\textbf{O}r boxes), a state-of-the-art end-to-end object detector. % in this paper. DINO improves over previous DETR-like models in performance and efficiency by using a contrastive way for denoising training, a mixed query selection method for anchor initialization, and a look forward twice scheme for box prediction. DINO achieves $48.3$AP in $12$ epochs and $51.0$AP in $36$ epochs on COCO with a ResNet-50 backbone and multi-scale features, yielding a significant improvement of $\textbf{+4.9}$\textbf{AP} and $\textbf{+2.4}$\textbf{AP}, respectively, compared to DN-DETR, the previous best DETR-like model. DINO scales well in both model size and data size. Without bells and whistles, after pre-training on the Objects365 dataset with a SwinL backbone, DINO obtains the best results on both COCO \texttt{val2017} ($\textbf{63.2}$\textbf{AP}) and \texttt{test-dev} (\textbf{$\textbf{63.3}$AP}). Compared to other models on the leaderboard, DINO significantly reduces its model size and pre-training data size while achieving better results. Our code will be available at \url{https://github.com/IDEACVR/DINO}.
A Roadmap for Big Model
Apr 02, 2022



With the rapid development of deep learning, training Big Models (BMs) for multiple downstream tasks becomes a popular paradigm. Researchers have achieved various outcomes in the construction of BMs and the BM application in many fields. At present, there is a lack of research work that sorts out the overall progress of BMs and guides the follow-up research. In this paper, we cover not only the BM technologies themselves but also the prerequisites for BM training and applications with BMs, dividing the BM review into four parts: Resource, Models, Key Technologies and Application. We introduce 16 specific BM-related topics in those four parts, they are Data, Knowledge, Computing System, Parallel Training System, Language Model, Vision Model, Multi-modal Model, Theory&Interpretability, Commonsense Reasoning, Reliability&Security, Governance, Evaluation, Machine Translation, Text Generation, Dialogue and Protein Research. In each topic, we summarize clearly the current studies and propose some future research directions. At the end of this paper, we conclude the further development of BMs in a more general view.