 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUI-Evol: Automatic Knowledge Evolving for Computer Use Agents
May 28, 2025External knowledge has played a crucial role in the recent development of computer use agents. We identify a critical knowledge-execution gap: retrieved knowledge often fails to translate into effective real-world task execution. Our analysis shows even 90\% correct knowledge yields only 41\% execution success rate. To bridge this gap, we propose UI-Evol, a plug-and-play module for autonomous GUI knowledge evolution. UI-Evol consists of two stages: a Retrace Stage that extracts faithful objective action sequences from actual agent-environment interactions, and a Critique Stage that refines existing knowledge by comparing these sequences against external references. We conduct comprehensive experiments on the OSWorld benchmark with the state-of-the-art Agent S2. Our results demonstrate that UI-Evol not only significantly boosts task performance but also addresses a previously overlooked issue of high behavioral standard deviation in computer use agents, leading to superior performance on computer use tasks and substantially improved agent reliability.
Bridging the Gap: Self-Optimized Fine-Tuning for LLM-based Recommender Systems
May 27, 2025Recent years have witnessed extensive exploration of Large Language Models (LLMs) on the field of Recommender Systems (RS). There are currently two commonly used strategies to enable LLMs to have recommendation capabilities: 1) The "Guidance-Only" strategy uses in-context learning to exploit and amplify the inherent semantic understanding and item recommendation capabilities of LLMs; 2) The "Tuning-Only" strategy uses supervised fine-tuning (SFT) to fine-tune LLMs with the aim of fitting them to real recommendation data. However, neither of these strategies can effectively bridge the gap between the knowledge space of LLMs and recommendation, and their performance do not meet our expectations. To better enable LLMs to learn recommendation knowledge, we combine the advantages of the above two strategies and proposed a novel "Guidance+Tuning" method called Self-Optimized Fine-Tuning (SOFT), which adopts the idea of curriculum learning. It first employs self-distillation to construct an auxiliary easy-to-learn but meaningful dataset from a fine-tuned LLM. Then it further utilizes a self-adaptive curriculum scheduler to enable LLMs to gradually learn from simpler data (self-distilled data) to more challenging data (real RS data). Extensive experiments demonstrate that SOFT significantly enhances the recommendation accuracy (37.59\% on average) of LLM-based methods. The code is available via https://anonymous.4open.science/r/Self-Optimized-Fine-Tuning-264E
Learning Optimal Multimodal Information Bottleneck Representations
May 26, 2025Leveraging high-quality joint representations from multimodal data can greatly enhance model performance in various machine-learning based applications. Recent multimodal learning methods, based on the multimodal information bottleneck (MIB) principle, aim to generate optimal MIB with maximal task-relevant information and minimal superfluous information via regularization. However, these methods often set ad hoc regularization weights and overlook imbalanced task-relevant information across modalities, limiting their ability to achieve optimal MIB. To address this gap, we propose a novel multimodal learning framework, Optimal Multimodal Information Bottleneck (OMIB), whose optimization objective guarantees the achievability of optimal MIB by setting the regularization weight within a theoretically derived bound. OMIB further addresses imbalanced task-relevant information by dynamically adjusting regularization weights per modality, promoting the inclusion of all task-relevant information. Moreover, we establish a solid information-theoretical foundation for OMIB's optimization and implement it under the variational approximation framework for computational efficiency. Finally, we empirically validate the OMIB's theoretical properties on synthetic data and demonstrate its superiority over the state-of-the-art benchmark methods in various downstream tasks.
Accelerating Prefilling for Long-Context LLMs via Sparse Pattern Sharing
May 26, 2025Sparse attention methods exploit the inherent sparsity in attention to speed up the prefilling phase of long-context inference, mitigating the quadratic complexity of full attention computation. While existing sparse attention methods rely on predefined patterns or inaccurate estimations to approximate attention behavior, they often fail to fully capture the true dynamics of attention, resulting in reduced efficiency and compromised accuracy. Instead, we propose a highly accurate sparse attention mechanism that shares similar yet precise attention patterns across heads, enabling a more realistic capture of the dynamic behavior of attention. Our approach is grounded in two key observations: (1) attention patterns demonstrate strong inter-head similarity, and (2) this similarity remains remarkably consistent across diverse inputs. By strategically sharing computed accurate patterns across attention heads, our method effectively captures actual patterns while requiring full attention computation for only a small subset of heads. Comprehensive evaluations demonstrate that our approach achieves superior or comparable speedup relative to state-of-the-art methods while delivering the best overall accuracy.
GenPO: Generative Diffusion Models Meet On-Policy Reinforcement Learning
May 24, 2025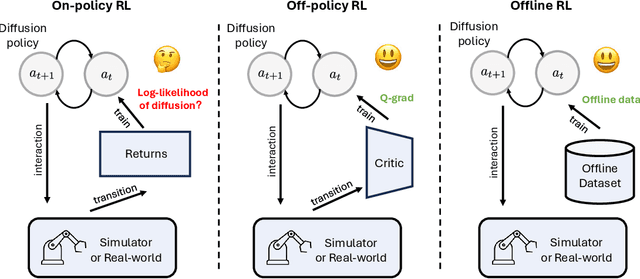

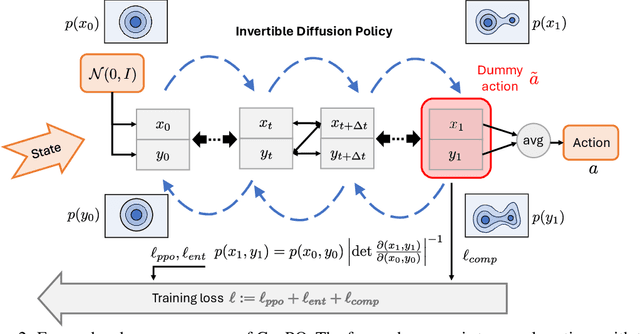
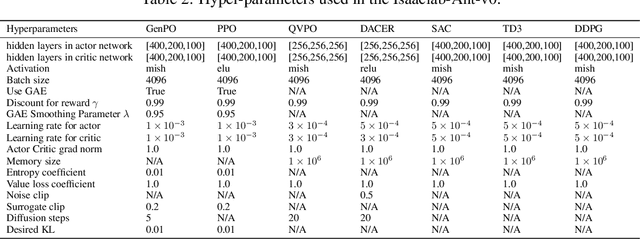
Recent advances in reinforcement learning (RL) have demonstrated the powerful exploration capabilities and multimodality of generative diffusion-based policies. While substantial progress has been made in offline RL and off-policy RL settings, integrating diffusion policies into on-policy frameworks like PPO remains underexplored. This gap is particularly significant given the widespread use of large-scale parallel GPU-accelerated simulators, such as IsaacLab, which are optimized for on-policy RL algorithms and enable rapid training of complex robotic tasks. A key challenge lies in computing state-action log-likelihoods under diffusion policies, which is straightforward for Gaussian policies but intractable for flow-based models due to irreversible forward-reverse processes and discretization errors (e.g., Euler-Maruyama approximations). To bridge this gap, we propose GenPO, a generative policy optimization framework that leverages exact diffusion inversion to construct invertible action mappings. GenPO introduces a novel doubled dummy action mechanism that enables invertibility via alternating updates, resolving log-likelihood computation barriers. Furthermore, we also use the action log-likelihood for unbiased entropy and KL divergence estimation, enabling KL-adaptive learning rates and entropy regularization in on-policy updates. Extensive experiments on eight IsaacLab benchmarks, including legged locomotion (Ant, Humanoid, Anymal-D, Unitree H1, Go2), dexterous manipulation (Shadow Hand), aerial control (Quadcopter), and robotic arm tasks (Franka), demonstrate GenPO's superiority over existing RL baselines. Notably, GenPO is the first method to successfully integrate diffusion policies into on-policy RL, unlocking their potential for large-scale parallelized training and real-world robotic deployment.
CIKT: A Collaborative and Iterative Knowledge Tracing Framework with Large Language Models
May 23, 2025Knowledge Tracing (KT) aims to model a student's learning state over time and predict their future performance. However, traditional KT methods often face challenges in explainability, scalability, and effective modeling of complex knowledge dependencies. While Large Language Models (LLMs) present new avenues for KT, their direct application often struggles with generating structured, explainable student representations and lacks mechanisms for continuous, task-specific refinement. To address these gaps, we propose Collaborative Iterative Knowledge Tracing (CIKT), a framework that harnesses LLMs to enhance both prediction accuracy and explainability. CIKT employs a dual-component architecture: an Analyst generates dynamic, explainable user profiles from student historical responses, and a Predictor utilizes these profiles to forecast future performance. The core of CIKT is a synergistic optimization loop. In this loop, the Analyst is iteratively refined based on the predictive accuracy of the Predictor, which conditions on the generated profiles, and the Predictor is subsequently retrained using these enhanced profiles. Evaluated on multiple educational datasets, CIKT demonstrates significant improvements in prediction accuracy, offers enhanced explainability through its dynamically updated user profiles, and exhibits improved scalability. Our work presents a robust and explainable solution for advancing knowledge tracing systems, effectively bridging the gap between predictive performance and model transparency.
Bottlenecked Transformers: Periodic KV Cache Abstraction for Generalised Reasoning
May 22, 2025Despite their impressive capabilities, Large Language Models struggle with generalisation beyond their training distribution, often exhibiting sophisticated pattern interpolation rather than true abstract reasoning (extrapolation). In this work, we approach this limitation through the lens of Information Bottleneck (IB) theory, which posits that model generalisation emerges from an optimal balance between input compression and retention of predictive information in latent representations. We prove using IB theory that decoder-only Transformers are inherently constrained in their ability to form task-optimal sequence representations. We then use this result to demonstrate that periodic global transformation of the internal sequence-level representations (KV cache) is a necessary computational step for improving Transformer generalisation in reasoning tasks. Based on these theoretical insights, we propose a modification to the Transformer architecture, in the form of an additional module that globally rewrites the KV cache at periodic intervals, shifting its capacity away from memorising input prefixes and toward encoding features most useful for predicting future tokens. Our model delivers substantial gains on mathematical reasoning benchmarks, outperforming both vanilla Transformers with up to 3.5x more parameters, as well as heuristic-driven pruning mechanisms for cache compression. Our approach can be seen as a principled generalisation of existing KV-cache compression methods; whereas such methods focus solely on compressing input representations, they often do so at the expense of retaining predictive information, and thus their capabilities are inherently bounded by those of an unconstrained model. This establishes a principled framework to manipulate Transformer memory using information theory, addressing fundamental reasoning limitations that scaling alone cannot overcome.
Few-Shot Test-Time Optimization Without Retraining for Semiconductor Recipe Generation and Beyond
May 21, 2025



We introduce Model Feedback Learning (MFL), a novel test-time optimization framework for optimizing inputs to pre-trained AI models or deployed hardware systems without requiring any retraining of the models or modifications to the hardware. In contrast to existing methods that rely on adjusting model parameters, MFL leverages a lightweight reverse model to iteratively search for optimal inputs, enabling efficient adaptation to new objectives under deployment constraints. This framework is particularly advantageous in real-world settings, such as semiconductor manufacturing recipe generation, where modifying deployed systems is often infeasible or cost-prohibitive. We validate MFL on semiconductor plasma etching tasks, where it achieves target recipe generation in just five iterations, significantly outperforming both Bayesian optimization and human experts. Beyond semiconductor applications, MFL also demonstrates strong performance in chemical processes (e.g., chemical vapor deposition) and electronic systems (e.g., wire bonding), highlighting its broad applicability. Additionally, MFL incorporates stability-aware optimization, enhancing robustness to process variations and surpassing conventional supervised learning and random search methods in high-dimensional control settings. By enabling few-shot adaptation, MFL provides a scalable and efficient paradigm for deploying intelligent control in real-world environments.
Field Matters: A lightweight LLM-enhanced Method for CTR Prediction
May 20, 2025



Click-through rate (CTR) prediction is a fundamental task in modern recommender systems. In recent years, the integration of large language models (LLMs) has been shown to effectively enhance the performance of traditional CTR methods. However, existing LLM-enhanced methods often require extensive processing of detailed textual descriptions for large-scale instances or user/item entities, leading to substantial computational overhead. To address this challenge, this work introduces LLaCTR, a novel and lightweight LLM-enhanced CTR method that employs a field-level enhancement paradigm. Specifically, LLaCTR first utilizes LLMs to distill crucial and lightweight semantic knowledge from small-scale feature fields through self-supervised field-feature fine-tuning. Subsequently, it leverages this field-level semantic knowledge to enhance both feature representation and feature interactions. In our experiments, we integrate LLaCTR with six representative CTR models across four datasets, demonstrating its superior performance in terms of both effectiveness and efficiency compared to existing LLM-enhanced methods. Our code is available at https://anonymous.4open.science/r/LLaCTR-EC46.
Developing and Integrating Trust Modeling into Multi-Objective Reinforcement Learning for Intelligent Agricultural Management
May 16, 2025



Precision agriculture, enhanced by artificial intelligence (AI), offers promising tools such as remote sensing, intelligent irrigation, fertilization management, and crop simulation to improve agricultural efficiency and sustainability. Reinforcement learning (RL), in particular, has outperformed traditional methods in optimizing yields and resource management. However, widespread AI adoption is limited by gaps between algorithmic recommendations and farmers' practical experience, local knowledge, and traditional practices. To address this, our study emphasizes Human-AI Interaction (HAII), focusing on transparency, usability, and trust in RL-based farm management. We employ a well-established trust framework - comprising ability, benevolence, and integrity - to develop a novel mathematical model quantifying farmers' confidence in AI-based fertilization strategies. Surveys conducted with farmers for this research reveal critical misalignments, which are integrated into our trust model and incorporated into a multi-objective RL framework. Unlike prior methods, our approach embeds trust directly into policy optimization, ensuring AI recommendations are technically robust, economically feasible, context-aware, and socially acceptable. By aligning technical performance with human-centered trust, this research supports broader AI adoption in agriculture.