 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeACR: Attention Collaboration-based Regressor for Arbitrary Two-Hand Reconstruction
Mar 10, 2023



Reconstructing two hands from monocular RGB images is challenging due to frequent occlusion and mutual confusion. Existing methods mainly learn an entangled representation to encode two interacting hands, which are incredibly fragile to impaired interaction, such as truncated hands, separate hands, or external occlusion. This paper presents ACR (Attention Collaboration-based Regressor), which makes the first attempt to reconstruct hands in arbitrary scenarios. To achieve this, ACR explicitly mitigates interdependencies between hands and between parts by leveraging center and part-based attention for feature extraction. However, reducing interdependence helps release the input constraint while weakening the mutual reasoning about reconstructing the interacting hands. Thus, based on center attention, ACR also learns cross-hand prior that handle the interacting hands better. We evaluate our method on various types of hand reconstruction datasets. Our method significantly outperforms the best interacting-hand approaches on the InterHand2.6M dataset while yielding comparable performance with the state-of-the-art single-hand methods on the FreiHand dataset. More qualitative results on in-the-wild and hand-object interaction datasets and web images/videos further demonstrate the effectiveness of our approach for arbitrary hand reconstruction. Our code is available at https://github.com/ZhengdiYu/Arbitrary-Hands-3D-Reconstruction.
Passively Addressed Morphing Surface (PARMS) Based on Machine Learning
Jan 30, 2023Reconfigurable morphing surfaces provide new opportunities for advanced human-machine interfaces and bio-inspired robotics. Morphing into arbitrary surfaces on demand requires a device with a sufficiently large number of actuators and an inverse control strategy that can calculate the actuator stimulation necessary to achieve a target surface. The programmability of a morphing surface can be improved by increasing the number of independent actuators, but this increases the complexity of the control system. Thus, developing compact and efficient control interfaces and control algorithms is a crucial knowledge gap for the adoption of morphing surfaces in broad applications. In this work, we describe a passively addressed robotic morphing surface (PARMS) composed of matrix-arranged ionic actuators. To reduce the complexity of the physical control interface, we introduce passive matrix addressing. Matrix addressing allows the control of independent actuators using only 2N control inputs, which is significantly lower than control inputs required for traditional direct addressing. Our control algorithm is based on machine learning using finite element simulations as the training data. This machine learning approach allows both forward and inverse control with high precision in real time. Inverse control demonstrations show that the PARMS can dynamically morph into arbitrary pre-defined surfaces on demand. These innovations in actuator matrix control may enable future implementation of PARMS in wearables, haptics, and augmented reality/virtual reality (AR/VR).
CodeTalker: Speech-Driven 3D Facial Animation with Discrete Motion Prior
Jan 06, 2023Speech-driven 3D facial animation has been widely studied, yet there is still a gap to achieving realism and vividness due to the highly ill-posed nature and scarcity of audio-visual data. Existing works typically formulate the cross-modal mapping into a regression task, which suffers from the regression-to-mean problem leading to over-smoothed facial motions. In this paper, we propose to cast speech-driven facial animation as a code query task in a finite proxy space of the learned codebook, which effectively promotes the vividness of the generated motions by reducing the cross-modal mapping uncertainty. The codebook is learned by self-reconstruction over real facial motions and thus embedded with realistic facial motion priors. Over the discrete motion space, a temporal autoregressive model is employed to sequentially synthesize facial motions from the input speech signal, which guarantees lip-sync as well as plausible facial expressions. We demonstrate that our approach outperforms current state-of-the-art methods both qualitatively and quantitatively. Also, a user study further justifies our superiority in perceptual quality.
High-Quality Supersampling via Mask-reinforced Deep Learning for Real-time Rendering
Jan 03, 2023To generate high quality rendering images for real time applications, it is often to trace only a few samples-per-pixel (spp) at a lower resolution and then supersample to the high resolution. Based on the observation that the rendered pixels at a low resolution are typically highly aliased, we present a novel method for neural supersampling based on ray tracing 1/4-spp samples at the high resolution. Our key insight is that the ray-traced samples at the target resolution are accurate and reliable, which makes the supersampling an interpolation problem. We present a mask-reinforced neural network to reconstruct and interpolate high-quality image sequences. First, a novel temporal accumulation network is introduced to compute the correlation between current and previous features to significantly improve their temporal stability. Then a reconstruct network based on a multi-scale U-Net with skip connections is adopted for reconstruction and generation of the desired high-resolution image. Experimental results and comparisons have shown that our proposed method can generate higher quality results of supersampling, without increasing the total number of ray-tracing samples, over current state-of-the-art methods.
Truncate-Split-Contrast: A Framework for Learning from Mislabeled Videos
Dec 29, 2022



Learning with noisy label (LNL) is a classic problem that has been extensively studied for image tasks, but much less for video in the literature. A straightforward migration from images to videos without considering the properties of videos, such as computational cost and redundant information, is not a sound choice. In this paper, we propose two new strategies for video analysis with noisy labels: 1) A lightweight channel selection method dubbed as Channel Truncation for feature-based label noise detection. This method selects the most discriminative channels to split clean and noisy instances in each category; 2) A novel contrastive strategy dubbed as Noise Contrastive Learning, which constructs the relationship between clean and noisy instances to regularize model training. Experiments on three well-known benchmark datasets for video classification show that our proposed tru{\bf N}cat{\bf E}-split-contr{\bf A}s{\bf T} (NEAT) significantly outperforms the existing baselines. By reducing the dimension to 10\% of it, our method achieves over 0.4 noise detection F1-score and 5\% classification accuracy improvement on Mini-Kinetics dataset under severe noise (symmetric-80\%). Thanks to Noise Contrastive Learning, the average classification accuracy improvement on Mini-Kinetics and Sth-Sth-V1 is over 1.6\%.
Rate-Splitting Multiple Access for Uplink Massive MIMO With Electromagnetic Exposure Constraints
Dec 14, 2022



Over the past few years, the prevalence of wireless devices has become one of the essential sources of electromagnetic (EM) radiation to the public. Facing with the swift development of wireless communications, people are skeptical about the risks of long-term exposure to EM radiation. As EM exposure is required to be restricted at user terminals, it is inefficient to blindly decrease the transmit power, which leads to limited spectral efficiency and energy efficiency (EE). Recently, rate-splitting multiple access (RSMA) has been proposed as an effective way to provide higher wireless transmission performance, which is a promising technology for future wireless communications. To this end, we propose using RSMA to increase the EE of massive MIMO uplink while limiting the EM exposure of users. In particularly, we investigate the optimization of the transmit covariance matrices and decoding order using statistical channel state information (CSI). The problem is formulated as non-convex mixed integer program, which is in general difficult to handle. We first propose a modified water-filling scheme to obtain the transmit covariance matrices with fixed decoding order. Then, a greedy approach is proposed to obtain the decoding permutation. Numerical results verify the effectiveness of the proposed EM exposure-aware EE maximization scheme for uplink RSMA.
VideoReTalking: Audio-based Lip Synchronization for Talking Head Video Editing In the Wild
Nov 27, 2022We present VideoReTalking, a new system to edit the faces of a real-world talking head video according to input audio, producing a high-quality and lip-syncing output video even with a different emotion. Our system disentangles this objective into three sequential tasks: (1) face video generation with a canonical expression; (2) audio-driven lip-sync; and (3) face enhancement for improving photo-realism. Given a talking-head video, we first modify the expression of each frame according to the same expression template using the expression editing network, resulting in a video with the canonical expression. This video, together with the given audio, is then fed into the lip-sync network to generate a lip-syncing video. Finally, we improve the photo-realism of the synthesized faces through an identity-aware face enhancement network and post-processing. We use learning-based approaches for all three steps and all our modules can be tackled in a sequential pipeline without any user intervention. Furthermore, our system is a generic approach that does not need to be retrained to a specific person. Evaluations on two widely-used datasets and in-the-wild examples demonstrate the superiority of our framework over other state-of-the-art methods in terms of lip-sync accuracy and visual quality.
Fine-Grained Face Swapping via Regional GAN Inversion
Nov 25, 2022



We present a novel paradigm for high-fidelity face swapping that faithfully preserves the desired subtle geometry and texture details. We rethink face swapping from the perspective of fine-grained face editing, \textit{i.e., ``editing for swapping'' (E4S)}, and propose a framework that is based on the explicit disentanglement of the shape and texture of facial components. Following the E4S principle, our framework enables both global and local swapping of facial features, as well as controlling the amount of partial swapping specified by the user. Furthermore, the E4S paradigm is inherently capable of handling facial occlusions by means of facial masks. At the core of our system lies a novel Regional GAN Inversion (RGI) method, which allows the explicit disentanglement of shape and texture. It also allows face swapping to be performed in the latent space of StyleGAN. Specifically, we design a multi-scale mask-guided encoder to project the texture of each facial component into regional style codes. We also design a mask-guided injection module to manipulate the feature maps with the style codes. Based on the disentanglement, face swapping is reformulated as a simplified problem of style and mask swapping. Extensive experiments and comparisons with current state-of-the-art methods demonstrate the superiority of our approach in preserving texture and shape details, as well as working with high resolution images at 1024$\times$1024.
Holistic Evaluation of Language Models
Nov 16, 2022



Language models (LMs) are becoming the foundation for almost all major language technologies, but their capabilities, limitations, and risks are not well understood. We present Holistic Evaluation of Language Models (HELM) to improve the transparency of language models. First, we taxonomize the vast space of potential scenarios (i.e. use cases) and metrics (i.e. desiderata) that are of interest for LMs. Then we select a broad subset based on coverage and feasibility, noting what's missing or underrepresented (e.g. question answering for neglected English dialects, metrics for trustworthiness). Second, we adopt a multi-metric approach: We measure 7 metrics (accuracy, calibration, robustness, fairness, bias, toxicity, and efficiency) for each of 16 core scenarios when possible (87.5% of the time). This ensures metrics beyond accuracy don't fall to the wayside, and that trade-offs are clearly exposed. We also perform 7 targeted evaluations, based on 26 targeted scenarios, to analyze specific aspects (e.g. reasoning, disinformation). Third, we conduct a large-scale evaluation of 30 prominent language models (spanning open, limited-access, and closed models) on all 42 scenarios, 21 of which were not previously used in mainstream LM evaluation. Prior to HELM, models on average were evaluated on just 17.9% of the core HELM scenarios, with some prominent models not sharing a single scenario in common. We improve this to 96.0%: now all 30 models have been densely benchmarked on the same core scenarios and metrics under standardized conditions. Our evaluation surfaces 25 top-level findings. For full transparency, we release all raw model prompts and completions publicly for further analysis, as well as a general modular toolkit. We intend for HELM to be a living benchmark for the community, continuously updated with new scenarios, metrics, and models.
One Model to Edit Them All: Free-Form Text-Driven Image Manipulation with Semantic Modulations
Oct 17, 2022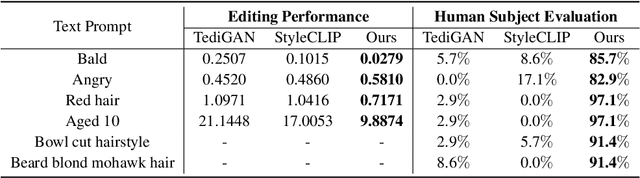
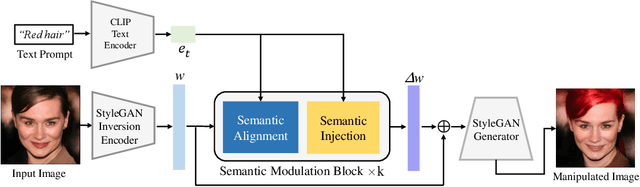
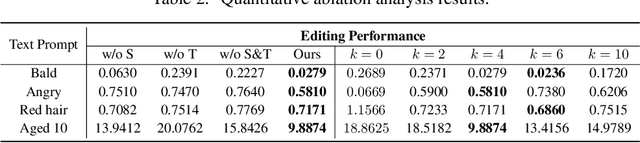
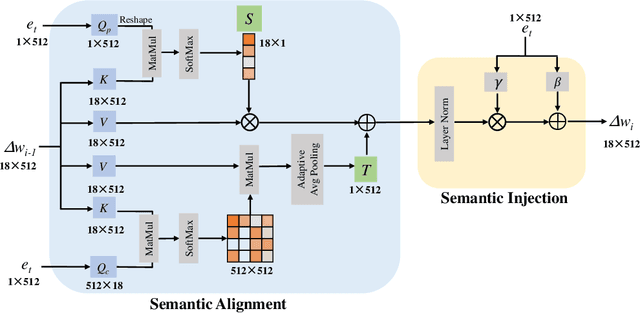
Free-form text prompts allow users to describe their intentions during image manipulation conveniently. Based on the visual latent space of StyleGAN[21] and text embedding space of CLIP[34], studies focus on how to map these two latent spaces for text-driven attribute manipulations. Currently, the latent mapping between these two spaces is empirically designed and confines that each manipulation model can only handle one fixed text prompt. In this paper, we propose a method named Free-Form CLIP (FFCLIP), aiming to establish an automatic latent mapping so that one manipulation model handles free-form text prompts. Our FFCLIP has a cross-modality semantic modulation module containing semantic alignment and injection. The semantic alignment performs the automatic latent mapping via linear transformations with a cross attention mechanism. After alignment, we inject semantics from text prompt embeddings to the StyleGAN latent space. For one type of image (e.g., `human portrait'), one FFCLIP model can be learned to handle free-form text prompts. Meanwhile, we observe that although each training text prompt only contains a single semantic meaning, FFCLIP can leverage text prompts with multiple semantic meanings for image manipulation. In the experiments, we evaluate FFCLIP on three types of images (i.e., `human portraits', `cars', and `churches'). Both visual and numerical results show that FFCLIP effectively produces semantically accurate and visually realistic images. Project page: https://github.com/KumapowerLIU/FFCLIP.