 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBakedSDF: Meshing Neural SDFs for Real-Time View Synthesis
Feb 28, 2023



We present a method for reconstructing high-quality meshes of large unbounded real-world scenes suitable for photorealistic novel view synthesis. We first optimize a hybrid neural volume-surface scene representation designed to have well-behaved level sets that correspond to surfaces in the scene. We then bake this representation into a high-quality triangle mesh, which we equip with a simple and fast view-dependent appearance model based on spherical Gaussians. Finally, we optimize this baked representation to best reproduce the captured viewpoints, resulting in a model that can leverage accelerated polygon rasterization pipelines for real-time view synthesis on commodity hardware. Our approach outperforms previous scene representations for real-time rendering in terms of accuracy, speed, and power consumption, and produces high quality meshes that enable applications such as appearance editing and physical simulation.
MERF: Memory-Efficient Radiance Fields for Real-time View Synthesis in Unbounded Scenes
Feb 23, 2023



Neural radiance fields enable state-of-the-art photorealistic view synthesis. However, existing radiance field representations are either too compute-intensive for real-time rendering or require too much memory to scale to large scenes. We present a Memory-Efficient Radiance Field (MERF) representation that achieves real-time rendering of large-scale scenes in a browser. MERF reduces the memory consumption of prior sparse volumetric radiance fields using a combination of a sparse feature grid and high-resolution 2D feature planes. To support large-scale unbounded scenes, we introduce a novel contraction function that maps scene coordinates into a bounded volume while still allowing for efficient ray-box intersection. We design a lossless procedure for baking the parameterization used during training into a model that achieves real-time rendering while still preserving the photorealistic view synthesis quality of a volumetric radiance field.
Polynomial Neural Fields for Subband Decomposition and Manipulation
Feb 09, 2023



Neural fields have emerged as a new paradigm for representing signals, thanks to their ability to do it compactly while being easy to optimize. In most applications, however, neural fields are treated like black boxes, which precludes many signal manipulation tasks. In this paper, we propose a new class of neural fields called polynomial neural fields (PNFs). The key advantage of a PNF is that it can represent a signal as a composition of a number of manipulable and interpretable components without losing the merits of neural fields representation. We develop a general theoretical framework to analyze and design PNFs. We use this framework to design Fourier PNFs, which match state-of-the-art performance in signal representation tasks that use neural fields. In addition, we empirically demonstrate that Fourier PNFs enable signal manipulation applications such as texture transfer and scale-space interpolation. Code is available at https://github.com/stevenygd/PNF.
MIRA: Mental Imagery for Robotic Affordances
Dec 12, 2022Humans form mental images of 3D scenes to support counterfactual imagination, planning, and motor control. Our abilities to predict the appearance and affordance of the scene from previously unobserved viewpoints aid us in performing manipulation tasks (e.g., 6-DoF kitting) with a level of ease that is currently out of reach for existing robot learning frameworks. In this work, we aim to build artificial systems that can analogously plan actions on top of imagined images. To this end, we introduce Mental Imagery for Robotic Affordances (MIRA), an action reasoning framework that optimizes actions with novel-view synthesis and affordance prediction in the loop. Given a set of 2D RGB images, MIRA builds a consistent 3D scene representation, through which we synthesize novel orthographic views amenable to pixel-wise affordances prediction for action optimization. We illustrate how this optimization process enables us to generalize to unseen out-of-plane rotations for 6-DoF robotic manipulation tasks given a limited number of demonstrations, paving the way toward machines that autonomously learn to understand the world around them for planning actions.
AligNeRF: High-Fidelity Neural Radiance Fields via Alignment-Aware Training
Nov 17, 2022Neural Radiance Fields (NeRFs) are a powerful representation for modeling a 3D scene as a continuous function. Though NeRF is able to render complex 3D scenes with view-dependent effects, few efforts have been devoted to exploring its limits in a high-resolution setting. Specifically, existing NeRF-based methods face several limitations when reconstructing high-resolution real scenes, including a very large number of parameters, misaligned input data, and overly smooth details. In this work, we conduct the first pilot study on training NeRF with high-resolution data and propose the corresponding solutions: 1) marrying the multilayer perceptron (MLP) with convolutional layers which can encode more neighborhood information while reducing the total number of parameters; 2) a novel training strategy to address misalignment caused by moving objects or small camera calibration errors; and 3) a high-frequency aware loss. Our approach is nearly free without introducing obvious training/testing costs, while experiments on different datasets demonstrate that it can recover more high-frequency details compared with the current state-of-the-art NeRF models. Project page: \url{https://yifanjiang.net/alignerf.}
DreamFusion: Text-to-3D using 2D Diffusion
Sep 29, 2022


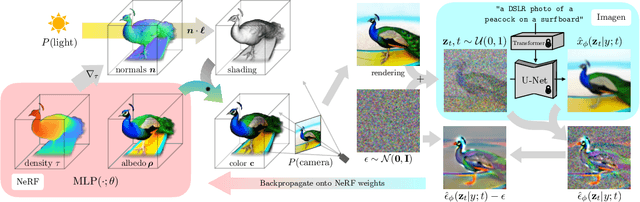
Recent breakthroughs in text-to-image synthesis have been driven by diffusion models trained on billions of image-text pairs. Adapting this approach to 3D synthesis would require large-scale datasets of labeled 3D data and efficient architectures for denoising 3D data, neither of which currently exist. In this work, we circumvent these limitations by using a pretrained 2D text-to-image diffusion model to perform text-to-3D synthesis. We introduce a loss based on probability density distillation that enables the use of a 2D diffusion model as a prior for optimization of a parametric image generator. Using this loss in a DeepDream-like procedure, we optimize a randomly-initialized 3D model (a Neural Radiance Field, or NeRF) via gradient descent such that its 2D renderings from random angles achieve a low loss. The resulting 3D model of the given text can be viewed from any angle, relit by arbitrary illumination, or composited into any 3D environment. Our approach requires no 3D training data and no modifications to the image diffusion model, demonstrating the effectiveness of pretrained image diffusion models as priors.
SAMURAI: Shape And Material from Unconstrained Real-world Arbitrary Image collections
May 31, 2022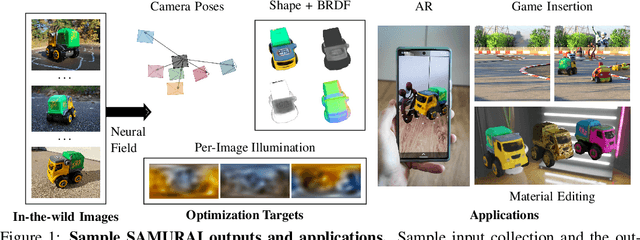

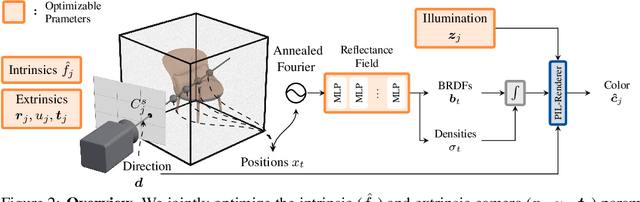

Inverse rendering of an object under entirely unknown capture conditions is a fundamental challenge in computer vision and graphics. Neural approaches such as NeRF have achieved photorealistic results on novel view synthesis, but they require known camera poses. Solving this problem with unknown camera poses is highly challenging as it requires joint optimization over shape, radiance, and pose. This problem is exacerbated when the input images are captured in the wild with varying backgrounds and illuminations. Standard pose estimation techniques fail in such image collections in the wild due to very few estimated correspondences across images. Furthermore, NeRF cannot relight a scene under any illumination, as it operates on radiance (the product of reflectance and illumination). We propose a joint optimization framework to estimate the shape, BRDF, and per-image camera pose and illumination. Our method works on in-the-wild online image collections of an object and produces relightable 3D assets for several use-cases such as AR/VR. To our knowledge, our method is the first to tackle this severely unconstrained task with minimal user interaction. Project page: https://markboss.me/publication/2022-samurai/ Video: https://youtu.be/LlYuGDjXp-8
NeRF-Supervision: Learning Dense Object Descriptors from Neural Radiance Fields
Mar 03, 2022



Thin, reflective objects such as forks and whisks are common in our daily lives, but they are particularly challenging for robot perception because it is hard to reconstruct them using commodity RGB-D cameras or multi-view stereo techniques. While traditional pipelines struggle with objects like these, Neural Radiance Fields (NeRFs) have recently been shown to be remarkably effective for performing view synthesis on objects with thin structures or reflective materials. In this paper we explore the use of NeRF as a new source of supervision for robust robot vision systems. In particular, we demonstrate that a NeRF representation of a scene can be used to train dense object descriptors. We use an optimized NeRF to extract dense correspondences between multiple views of an object, and then use these correspondences as training data for learning a view-invariant representation of the object. NeRF's usage of a density field allows us to reformulate the correspondence problem with a novel distribution-of-depths formulation, as opposed to the conventional approach of using a depth map. Dense correspondence models supervised with our method significantly outperform off-the-shelf learned descriptors by 106% (PCK@3px metric, more than doubling performance) and outperform our baseline supervised with multi-view stereo by 29%. Furthermore, we demonstrate the learned dense descriptors enable robots to perform accurate 6-degree of freedom (6-DoF) pick and place of thin and reflective objects.
Block-NeRF: Scalable Large Scene Neural View Synthesis
Feb 10, 2022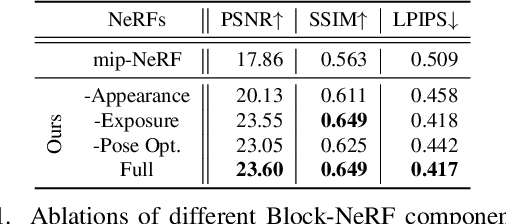
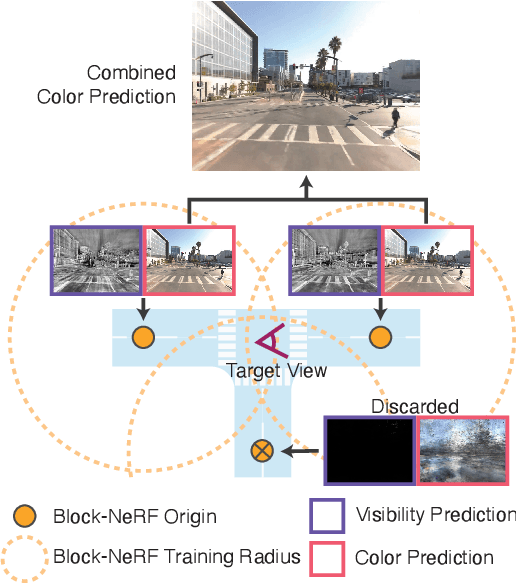
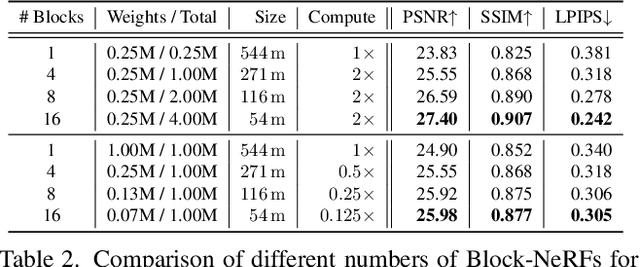
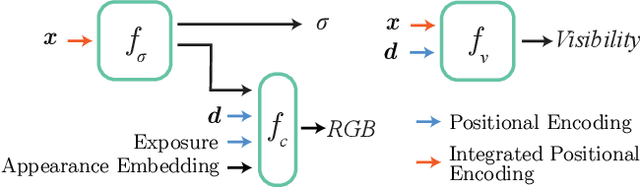
We present Block-NeRF, a variant of Neural Radiance Fields that can represent large-scale environments. Specifically, we demonstrate that when scaling NeRF to render city-scale scenes spanning multiple blocks, it is vital to decompose the scene into individually trained NeRFs. This decomposition decouples rendering time from scene size, enables rendering to scale to arbitrarily large environments, and allows per-block updates of the environment. We adopt several architectural changes to make NeRF robust to data captured over months under different environmental conditions. We add appearance embeddings, learned pose refinement, and controllable exposure to each individual NeRF, and introduce a procedure for aligning appearance between adjacent NeRFs so that they can be seamlessly combined. We build a grid of Block-NeRFs from 2.8 million images to create the largest neural scene representation to date, capable of rendering an entire neighborhood of San Francisco.
HumanNeRF: Free-viewpoint Rendering of Moving People from Monocular Video
Jan 11, 2022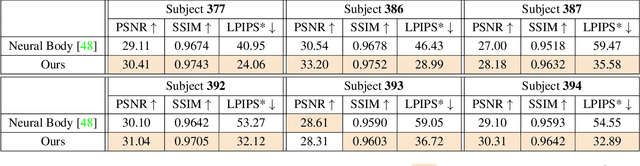

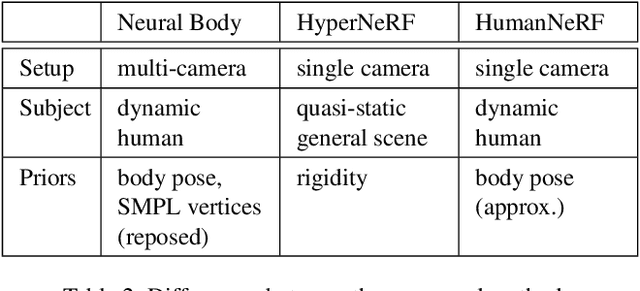

We introduce a free-viewpoint rendering method -- HumanNeRF -- that works on a given monocular video of a human performing complex body motions, e.g. a video from YouTube. Our method enables pausing the video at any frame and rendering the subject from arbitrary new camera viewpoints or even a full 360-degree camera path for that particular frame and body pose. This task is particularly challenging, as it requires synthesizing photorealistic details of the body, as seen from various camera angles that may not exist in the input video, as well as synthesizing fine details such as cloth folds and facial appearance. Our method optimizes for a volumetric representation of the person in a canonical T-pose, in concert with a motion field that maps the estimated canonical representation to every frame of the video via backward warps. The motion field is decomposed into skeletal rigid and non-rigid motions, produced by deep networks. We show significant performance improvements over prior work, and compelling examples of free-viewpoint renderings from monocular video of moving humans in challenging uncontrolled capture scenarios.