 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReachability Analysis of Neural Feedback Loops
Aug 09, 2021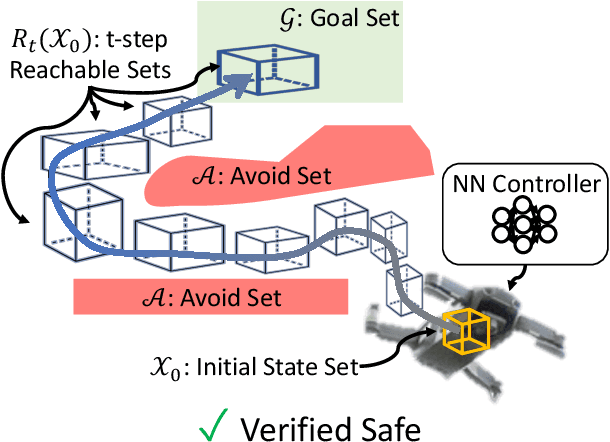
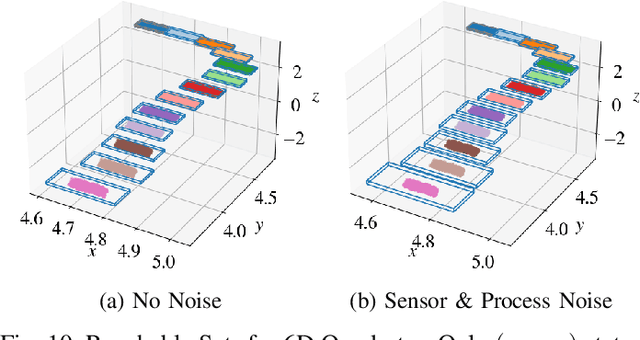
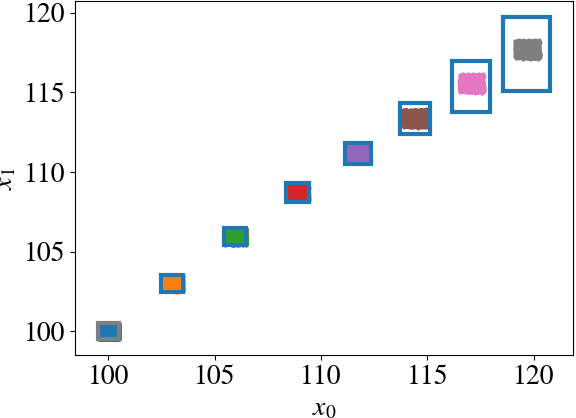
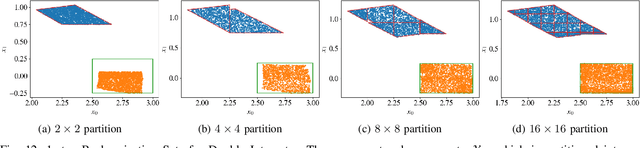
Neural Networks (NNs) can provide major empirical performance improvements for closed-loop systems, but they also introduce challenges in formally analyzing those systems' safety properties. In particular, this work focuses on estimating the forward reachable set of \textit{neural feedback loops} (closed-loop systems with NN controllers). Recent work provides bounds on these reachable sets, but the computationally tractable approaches yield overly conservative bounds (thus cannot be used to verify useful properties), and the methods that yield tighter bounds are too intensive for online computation. This work bridges the gap by formulating a convex optimization problem for the reachability analysis of closed-loop systems with NN controllers. While the solutions are less tight than previous (semidefinite program-based) methods, they are substantially faster to compute, and some of those computational time savings can be used to refine the bounds through new input set partitioning techniques, which is shown to dramatically reduce the tightness gap. The new framework is developed for systems with uncertainty (e.g., measurement and process noise) and nonlinearities (e.g., polynomial dynamics), and thus is shown to be applicable to real-world systems. To inform the design of an initial state set when only the target state set is known/specified, a novel algorithm for backward reachability analysis is also provided, which computes the set of states that are guaranteed to lead to the target set. The numerical experiments show that our approach (based on linear relaxations and partitioning) gives a $5\times$ reduction in conservatism in $150\times$ less computation time compared to the state-of-the-art. Furthermore, experiments on quadrotor, 270-state, and polynomial systems demonstrate the method's ability to handle uncertainty sources, high dimensionality, and nonlinear dynamics, respectively.
Kimera-Multi: Robust, Distributed, Dense Metric-Semantic SLAM for Multi-Robot Systems
Jun 28, 2021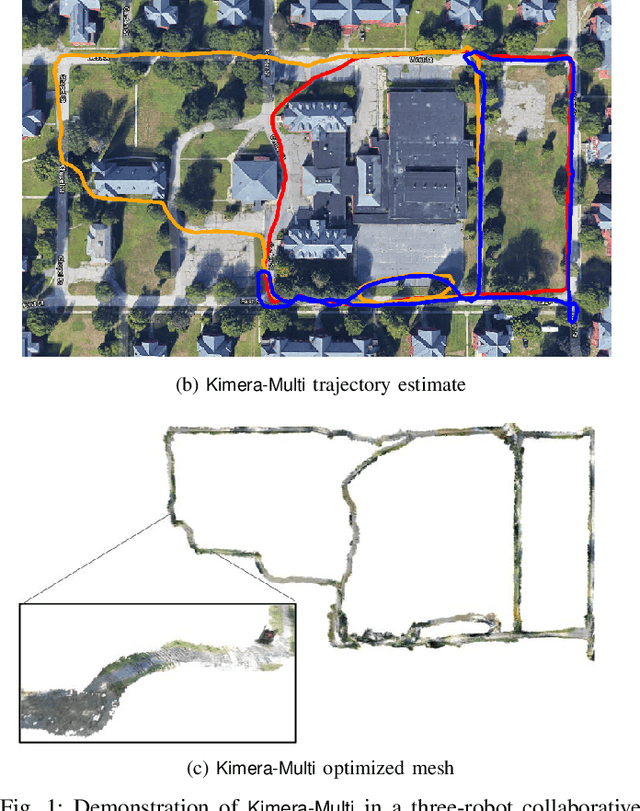
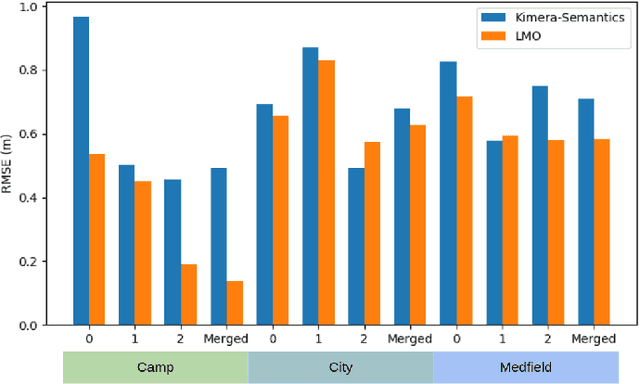
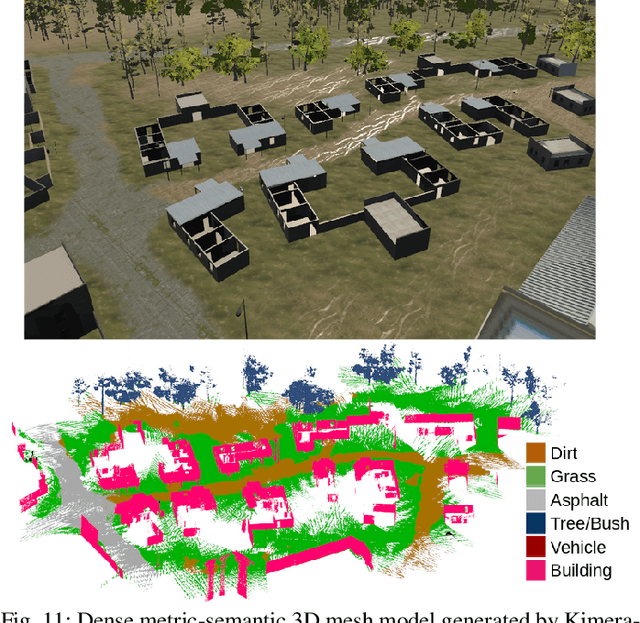

This paper presents Kimera-Multi, the first multi-robot system that (i) is robust and capable of identifying and rejecting incorrect inter and intra-robot loop closures resulting from perceptual aliasing, (ii) is fully distributed and only relies on local (peer-to-peer) communication to achieve distributed localization and mapping, and (iii) builds a globally consistent metric-semantic 3D mesh model of the environment in real-time, where faces of the mesh are annotated with semantic labels. Kimera-Multi is implemented by a team of robots equipped with visual-inertial sensors. Each robot builds a local trajectory estimate and a local mesh using Kimera. When communication is available, robots initiate a distributed place recognition and robust pose graph optimization protocol based on a novel distributed graduated non-convexity algorithm. The proposed protocol allows the robots to improve their local trajectory estimates by leveraging inter-robot loop closures while being robust to outliers. Finally, each robot uses its improved trajectory estimate to correct the local mesh using mesh deformation techniques. We demonstrate Kimera-Multi in photo-realistic simulations, SLAM benchmarking datasets, and challenging outdoor datasets collected using ground robots. Both real and simulated experiments involve long trajectories (e.g., up to 800 meters per robot). The experiments show that Kimera-Multi (i) outperforms the state of the art in terms of robustness and accuracy, (ii) achieves estimation errors comparable to a centralized SLAM system while being fully distributed, (iii) is parsimonious in terms of communication bandwidth, (iv) produces accurate metric-semantic 3D meshes, and (v) is modular and can be also used for standard 3D reconstruction (i.e., without semantic labels) or for trajectory estimation (i.e., without reconstructing a 3D mesh).
Airflow-Inertial Odometry for Resilient State Estimation on Multirotors
May 27, 2021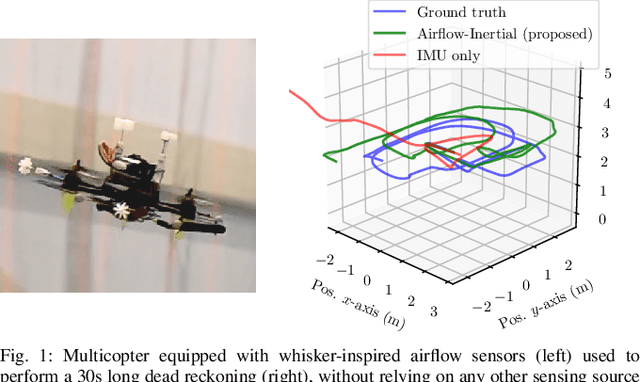
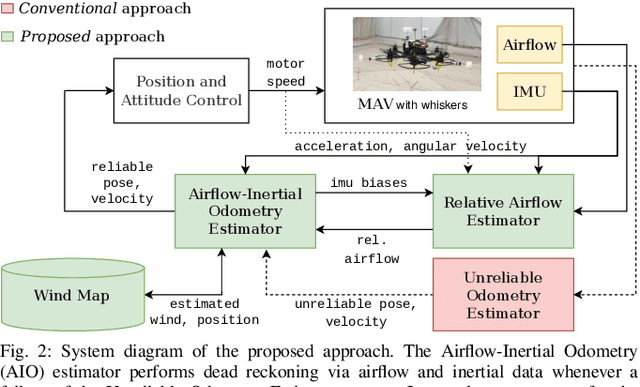
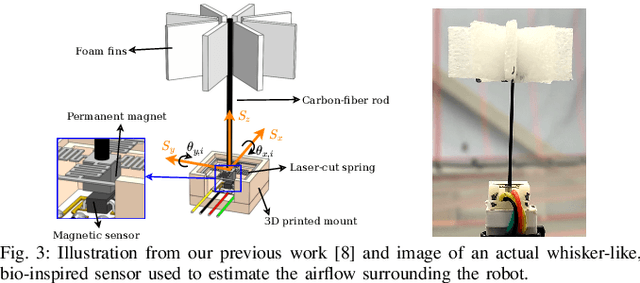
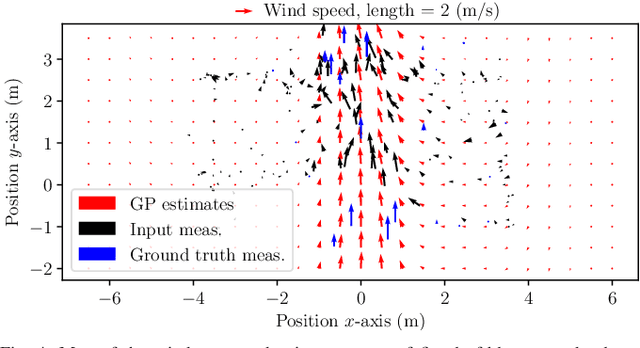
We present a dead reckoning strategy for increased resilience to position estimation failures on multirotors, using only data from a low-cost IMU and novel, bio-inspired airflow sensors. The goal is challenging, since low-cost IMUs are subject to large noise and drift, while 3D airflow sensing is made difficult by the interference caused by the propellers and by the wind. Our approach relies on a deep-learning strategy to interpret the measurements of the bio-inspired sensors, a map of the wind speed to compensate for position-dependent wind, and a filter to fuse the information and generate a pose and velocity estimate. Our results show that the approach reduces the drift with respect to IMU-only dead reckoning by up to an order of magnitude over 30 seconds after a position sensor failure in non-windy environments, and it can compensate for the challenging effects of turbulent, and spatially varying wind.
NF-iSAM: Incremental Smoothing and Mapping via Normalizing Flows
May 11, 2021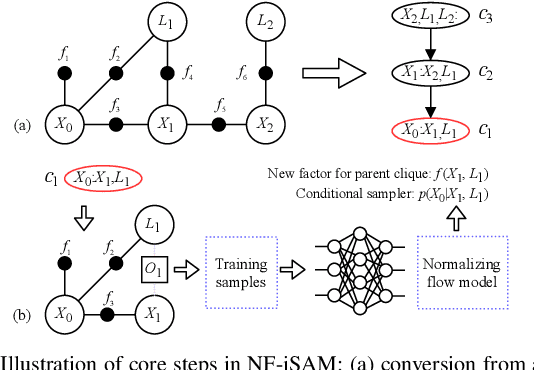
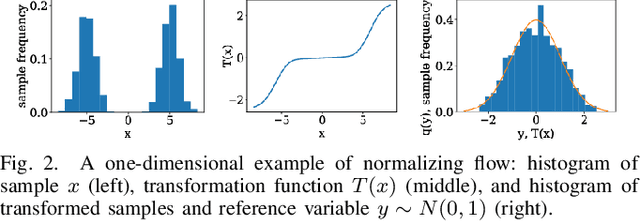
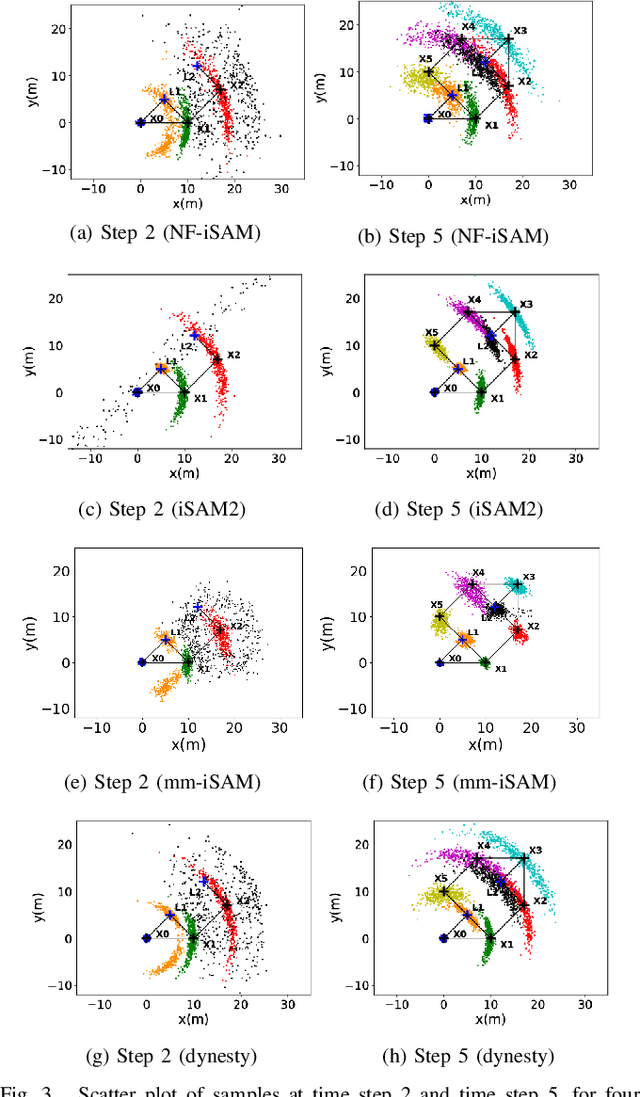
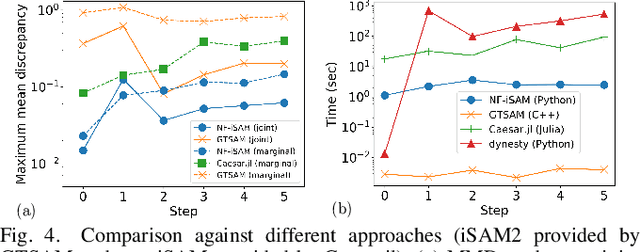
This paper presents a novel non-Gaussian inference algorithm, Normalizing Flow iSAM (NF-iSAM), for solving SLAM problems with non-Gaussian factors and/or non-linear measurement models. NF-iSAM exploits the expressive power of neural networks, and trains normalizing flows to draw samples from the joint posterior of non-Gaussian factor graphs. By leveraging the Bayes tree, NF-iSAM is able to exploit the sparsity structure of SLAM, thus enabling efficient incremental updates similar to iSAM2, albeit in the more challenging non-Gaussian setting. We demonstrate the performance of NF-iSAM and compare it against the state-of-the-art algorithms such as iSAM2 (Gaussian) and mm-iSAM (non-Gaussian) in synthetic and real range-only SLAM datasets.
Multi-Robot Distributed Semantic Mapping in Unfamiliar Environments through Online Matching of Learned Representations
Mar 27, 2021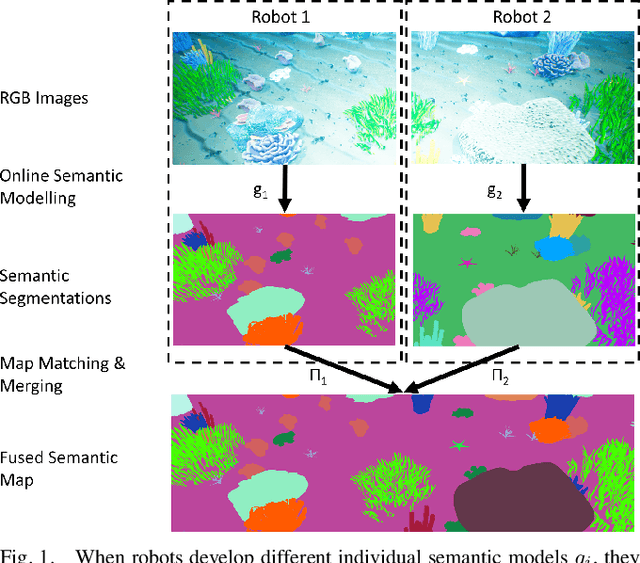
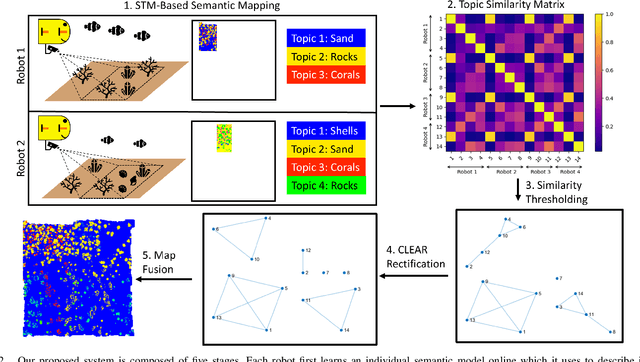
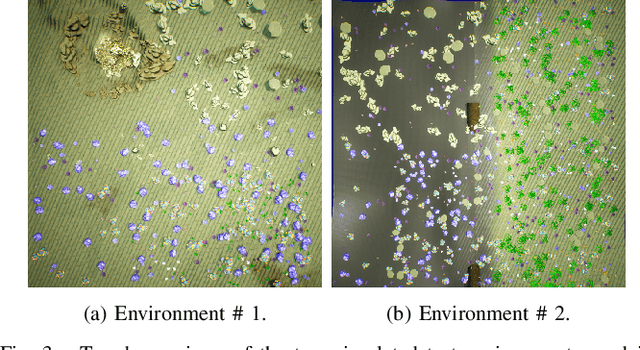
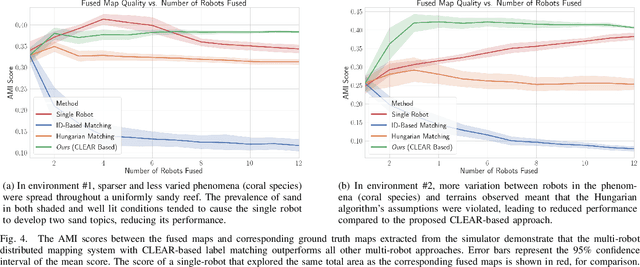
We present a solution to multi-robot distributed semantic mapping of novel and unfamiliar environments. Most state-of-the-art semantic mapping systems are based on supervised learning algorithms that cannot classify novel observations online. While unsupervised learning algorithms can invent labels for novel observations, approaches to detect when multiple robots have independently developed their own labels for the same new class are prone to erroneous or inconsistent matches. These issues worsen as the number of robots in the system increases and prevent fusing the local maps produced by each robot into a consistent global map, which is crucial for cooperative planning and joint mission summarization. Our proposed solution overcomes these obstacles by having each robot learn an unsupervised semantic scene model online and use a multiway matching algorithm to identify consistent sets of matches between learned semantic labels belonging to different robots. Compared to the state of the art, the proposed solution produces 20-60% higher quality global maps that do not degrade even as many more local maps are fused.
PANTHER: Perception-Aware Trajectory Planner in Dynamic Environments
Mar 10, 2021
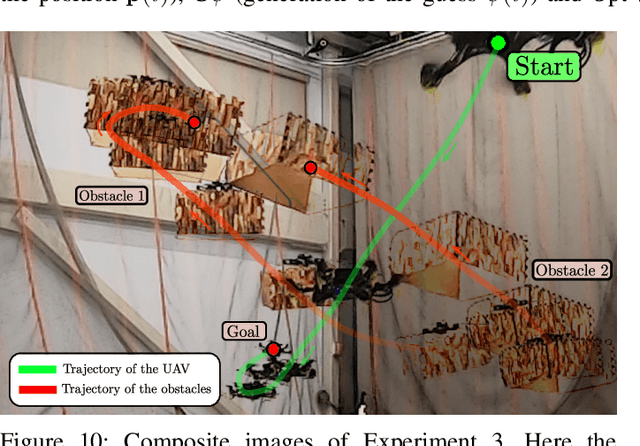
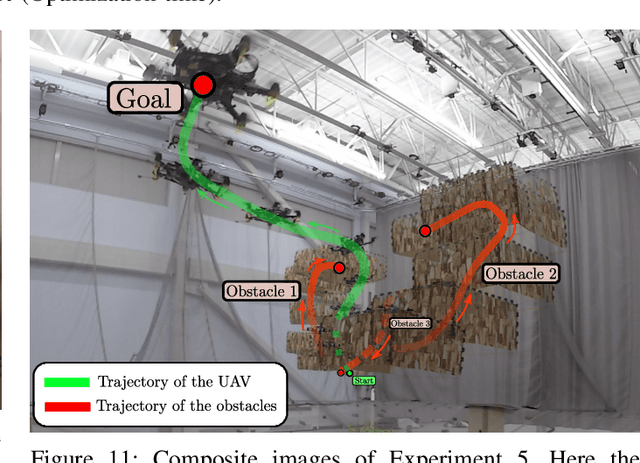
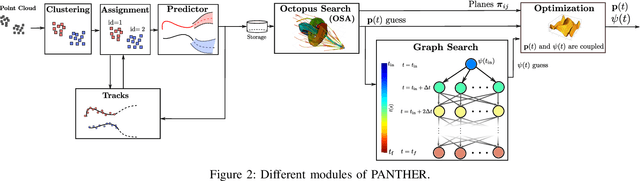
This paper presents PANTHER, a real-time perception-aware (PA) trajectory planner in dynamic environments. PANTHER plans trajectories that avoid dynamic obstacles while also keeping them in the sensor field of view (FOV) and minimizing the blur to aid in object tracking. The rotation and translation of the UAV are jointly optimized, which allows PANTHER to fully exploit the differential flatness of multirotors. Real-time performance is achieved by implicitly imposing this constraint through the Hopf fibration. PANTHER is able to keep the obstacles inside the FOV 7.4 and 1.5 times more than non-PA approaches and PA approaches that decouple translation and yaw, respectively. The projected velocity (and hence the blur) is reduced by 30%. Our recently-derived MINVO basis is used to impose low-conservative collision avoidance constraints in position and velocity space. Finally, extensive hardware experiments in unknown dynamic environments with all the computation running onboard are presented, with velocities of up to 5.8 m/s, and with relative velocities (with respect to the obstacles) of up to 6.3 m/s. The only sensors used are an IMU, a forward-facing depth camera, and a downward-facing monocular camera.
Where to go next: Learning a Subgoal Recommendation Policy for Navigation Among Pedestrians
Feb 26, 2021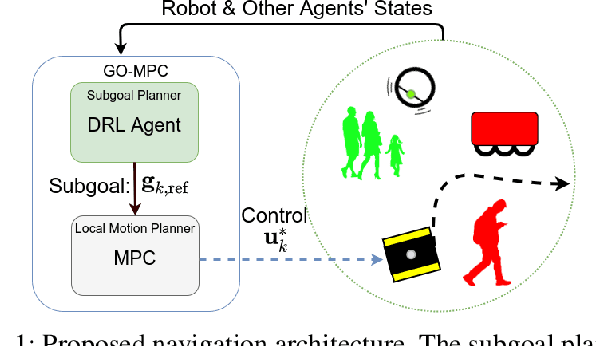
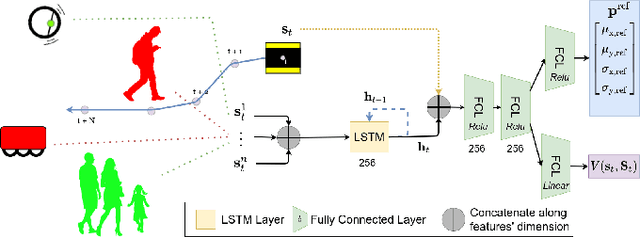
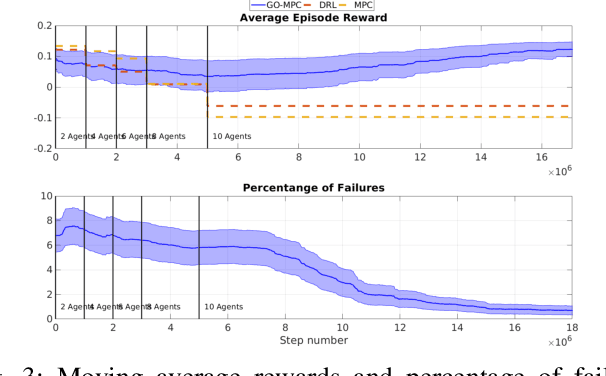
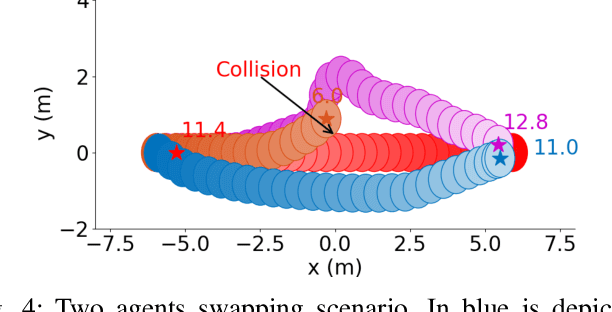
Robotic navigation in environments shared with other robots or humans remains challenging because the intentions of the surrounding agents are not directly observable and the environment conditions are continuously changing. Local trajectory optimization methods, such as model predictive control (MPC), can deal with those changes but require global guidance, which is not trivial to obtain in crowded scenarios. This paper proposes to learn, via deep Reinforcement Learning (RL), an interaction-aware policy that provides long-term guidance to the local planner. In particular, in simulations with cooperative and non-cooperative agents, we train a deep network to recommend a subgoal for the MPC planner. The recommended subgoal is expected to help the robot in making progress towards its goal and accounts for the expected interaction with other agents. Based on the recommended subgoal, the MPC planner then optimizes the inputs for the robot satisfying its kinodynamic and collision avoidance constraints. Our approach is shown to substantially improve the navigation performance in terms of number of collisions as compared to prior MPC frameworks, and in terms of both travel time and number of collisions compared to deep RL methods in cooperative, competitive and mixed multiagent scenarios.
LION: Lidar-Inertial Observability-Aware Navigator for Vision-Denied Environments
Feb 05, 2021
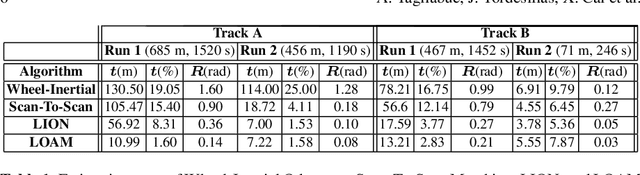
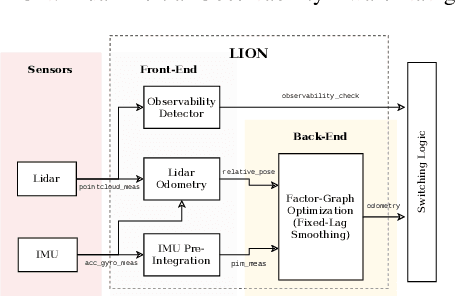
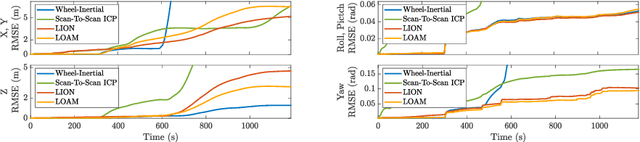
State estimation for robots navigating in GPS-denied and perceptually-degraded environments, such as underground tunnels, mines and planetary subsurface voids, remains challenging in robotics. Towards this goal, we present LION (Lidar-Inertial Observability-Aware Navigator), which is part of the state estimation framework developed by the team CoSTAR for the DARPA Subterranean Challenge, where the team achieved second and first places in the Tunnel and Urban circuits in August 2019 and February 2020, respectively. LION provides high-rate odometry estimates by fusing high-frequency inertial data from an IMU and low-rate relative pose estimates from a lidar via a fixed-lag sliding window smoother. LION does not require knowledge of relative positioning between lidar and IMU, as the extrinsic calibration is estimated online. In addition, LION is able to self-assess its performance using an observability metric that evaluates whether the pose estimate is geometrically ill-constrained. Odometry and confidence estimates are used by HeRO, a supervisory algorithm that provides robust estimates by switching between different odometry sources. In this paper we benchmark the performance of LION in perceptually-degraded subterranean environments, demonstrating its high technology readiness level for deployment in the field.
Non-Monotone Energy-Aware Information Gathering for Heterogeneous Robot Teams
Jan 26, 2021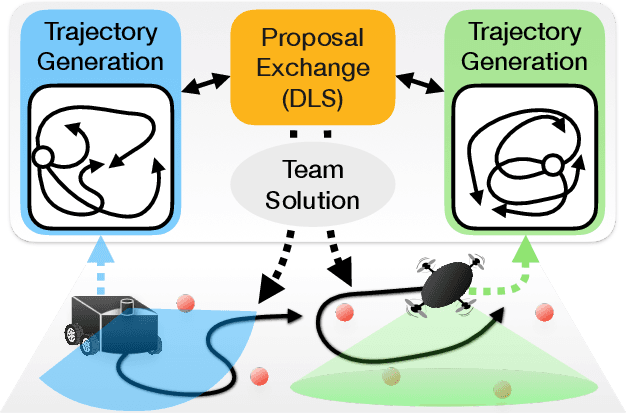
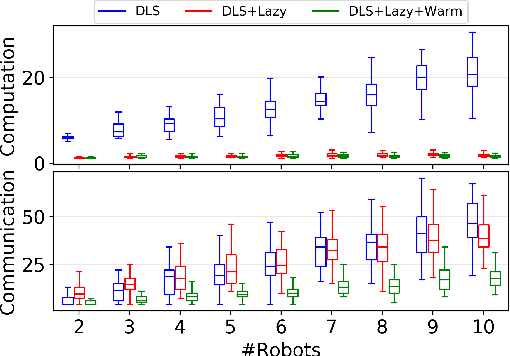
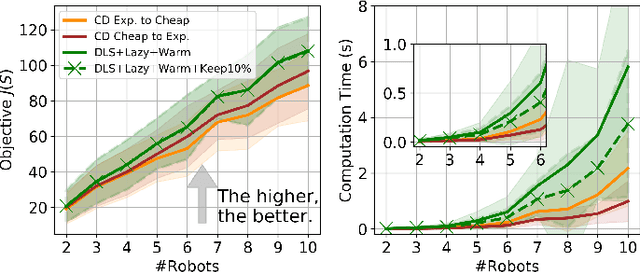
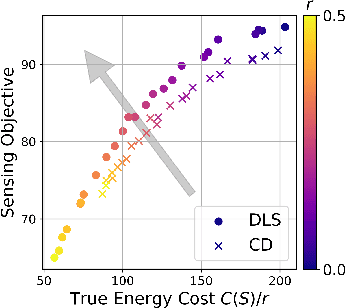
This paper considers the problem of planning trajectories for a team of sensor-equipped robots to reduce uncertainty about a dynamical process. Optimizing the trade-off between information gain and energy cost (e.g., control effort, energy expenditure, distance travelled) is desirable but leads to a non-monotone objective function in the set of robot trajectories. Therefore, common multi-robot planning algorithms based on techniques such as coordinate descent lose their performance guarantees. Methods based on local search provide performance guarantees for optimizing a non-monotone submodular function, but require access to all robots' trajectories, making it not suitable for distributed execution. This work proposes a distributed planning approach based on local search, and shows how to reduce its computation and communication requirements without sacrificing algorithm performance. We demonstrate the efficacy of our proposed method by coordinating robot teams composed of both ground and aerial vehicles with different sensing and control profiles, and evaluate the algorithm's performance in two target tracking scenarios. Our results show up to 60% communication reduction and 80-92% computation reduction on average when coordinating up to 10 robots, while outperforming the coordinate descent based algorithm in achieving a desirable trade-off between sensing and energy expenditure.
Efficient Reachability Analysis of Closed-Loop Systems with Neural Network Controllers
Jan 05, 2021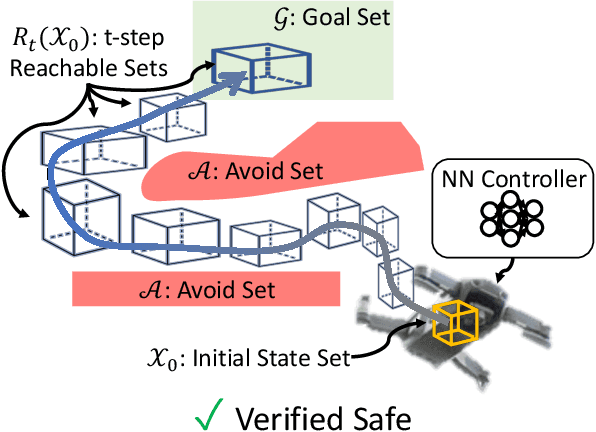
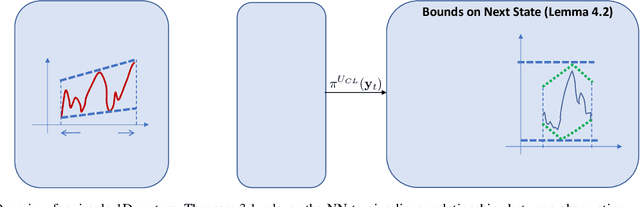
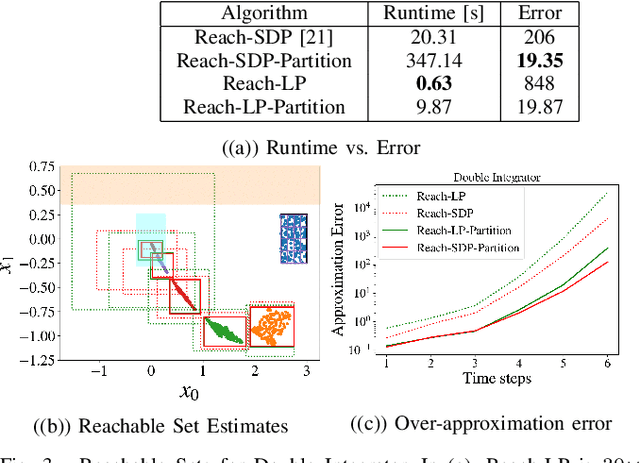
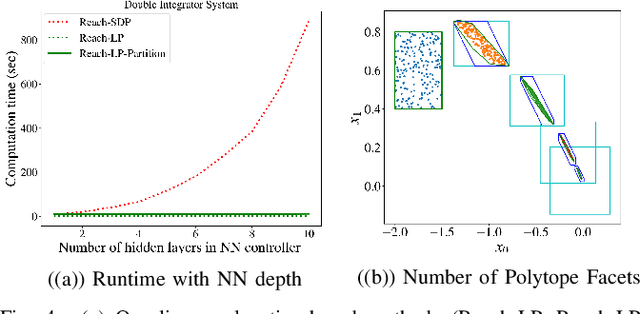
Neural Networks (NNs) can provide major empirical performance improvements for robotic systems, but they also introduce challenges in formally analyzing those systems' safety properties. In particular, this work focuses on estimating the forward reachable set of closed-loop systems with NN controllers. Recent work provides bounds on these reachable sets, yet the computationally efficient approaches provide overly conservative bounds (thus cannot be used to verify useful properties), whereas tighter methods are too intensive for online computation. This work bridges the gap by formulating a convex optimization problem for reachability analysis for closed-loop systems with NN controllers. While the solutions are less tight than prior semidefinite program-based methods, they are substantially faster to compute, and some of the available computation time can be used to refine the bounds through input set partitioning, which more than overcomes the tightness gap. The proposed framework further considers systems with measurement and process noise, thus being applicable to realistic systems with uncertainty. Finally, numerical comparisons show $10\times$ reduction in conservatism in $\frac{1}{2}$ of the computation time compared to the state-of-the-art, and the ability to handle various sources of uncertainty is highlighted on a quadrotor model.