 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReasoning Efficiently Through Adaptive Chain-of-Thought Compression: A Self-Optimizing Framework
Sep 17, 2025



Chain-of-Thought (CoT) reasoning enhances Large Language Models (LLMs) by prompting intermediate steps, improving accuracy and robustness in arithmetic, logic, and commonsense tasks. However, this benefit comes with high computational costs: longer outputs increase latency, memory usage, and KV-cache demands. These issues are especially critical in software engineering tasks where concise and deterministic outputs are required. To investigate these trade-offs, we conduct an empirical study based on code generation benchmarks. The results reveal that longer CoT does not always help. Excessive reasoning often causes truncation, accuracy drops, and latency up to five times higher, with failed outputs consistently longer than successful ones. These findings challenge the assumption that longer reasoning is inherently better and highlight the need for adaptive CoT control. Motivated by this, we propose SEER (Self-Enhancing Efficient Reasoning), an adaptive framework that compresses CoT while preserving accuracy. SEER combines Best-of-N sampling with task-aware adaptive filtering, dynamically adjusting thresholds based on pre-inference outputs to reduce verbosity and computational overhead. We then evaluate SEER on three software engineering tasks and one math task. On average, SEER shortens CoT by 42.1%, improves accuracy by reducing truncation, and eliminates most infinite loops. These results demonstrate SEER as a practical method to make CoT-enhanced LLMs more efficient and robust, even under resource constraints.
Code Smells in Machine Learning Systems
Mar 02, 2022
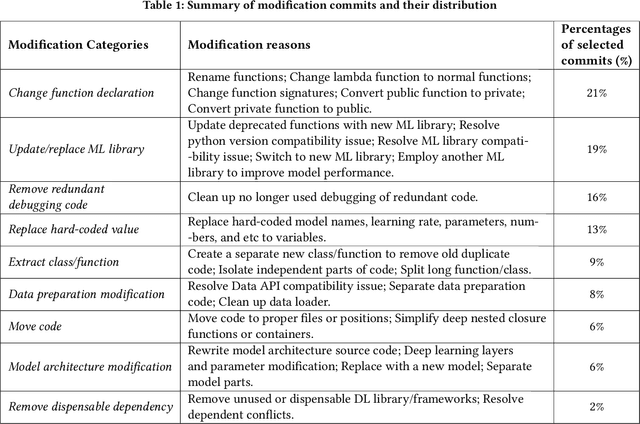
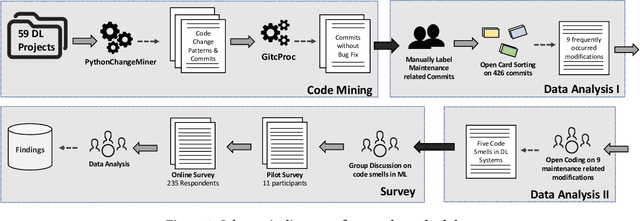

As Deep learning (DL) systems continuously evolve and grow, assuring their quality becomes an important yet challenging task. Compared to non-DL systems, DL systems have more complex team compositions and heavier data dependency. These inherent characteristics would potentially cause DL systems to be more vulnerable to bugs and, in the long run, to maintenance issues. Code smells are empirically tested as efficient indicators of non-DL systems. Therefore, we took a step forward into identifying code smells, and understanding their impact on maintenance in this comprehensive study. This is the first study on investigating code smells in the context of DL software systems, which helps researchers and practitioners to get a first look at what kind of maintenance modification made and what code smells developers have been dealing with. Our paper has three major contributions. First, we comprehensively investigated the maintenance modifications that have been made by DL developers via studying the evolution of DL systems, and we identified nine frequently occurred maintenance-related modification categories in DL systems. Second, we summarized five code smells in DL systems. Third, we validated the prevalence, and the impact of our newly identified code smells through a mixture of qualitative and quantitative analysis. We found that our newly identified code smells are prevalent and impactful on the maintenance of DL systems from the developer's perspective.