 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniversal Fine-Grained Symmetry Inference and Enforcement for Rigorous Crystal Structure Prediction
Feb 19, 2026Crystal structure prediction (CSP), which aims to predict the three-dimensional atomic arrangement of a crystal from its composition, is central to materials discovery and mechanistic understanding. Existing deep learning models often treat crystallographic symmetry only as a soft heuristic or rely on space group and Wyckoff templates retrieved from known structures, which limits both physical fidelity and the ability to discover genuinely new material structures. In contrast to retrieval-based methods, our approach leverages large language models to encode chemical semantics and directly generate fine-grained Wyckoff patterns from composition, effectively circumventing the limitations inherent to database lookups. Crucially, we incorporate domain knowledge into the generative process through an efficient constrained-optimization search that rigorously enforces algebraic consistency between site multiplicities and atomic stoichiometry. By integrating this symmetry-consistent template into a diffusion backbone, our approach constrains the stochastic generative trajectory to a physically valid geometric manifold. This framework achieves state-of-the-art performance across stability, uniqueness, and novelty (SUN) benchmarks, alongside superior matching performance, thereby establishing a new paradigm for the rigorous exploration of targeted crystallographic space. This framework enables efficient expansion into previously uncharted materials space, eliminating reliance on existing databases or a priori structural knowledge.
HC$^3$L-Diff: Hybrid conditional latent diffusion with high frequency enhancement for CBCT-to-CT synthesis
Nov 03, 2024Background: Cone-beam computed tomography (CBCT) plays a crucial role in image-guided radiotherapy, but artifacts and noise make them unsuitable for accurate dose calculation. Artificial intelligence methods have shown promise in enhancing CBCT quality to produce synthetic CT (sCT) images. However, existing methods either produce images of suboptimal quality or incur excessive time costs, failing to satisfy clinical practice standards. Methods and materials: We propose a novel hybrid conditional latent diffusion model for efficient and accurate CBCT-to-CT synthesis, named HC$^3$L-Diff. We employ the Unified Feature Encoder (UFE) to compress images into a low-dimensional latent space, thereby optimizing computational efficiency. Beyond the use of CBCT images, we propose integrating its high-frequency knowledge as a hybrid condition to guide the diffusion model in generating sCT images with preserved structural details. This high-frequency information is captured using our designed High-Frequency Extractor (HFE). During inference, we utilize denoising diffusion implicit model to facilitate rapid sampling. We construct a new in-house prostate dataset with paired CBCT and CT to validate the effectiveness of our method. Result: Extensive experimental results demonstrate that our approach outperforms state-of-the-art methods in terms of sCT quality and generation efficiency. Moreover, our medical physicist conducts the dosimetric evaluations to validate the benefit of our method in practical dose calculation, achieving a remarkable 93.8% gamma passing rate with a 2%/2mm criterion, superior to other methods. Conclusion: The proposed HC$^3$L-Diff can efficiently achieve high-quality CBCT-to-CT synthesis in only over 2 mins per patient. Its promising performance in dose calculation shows great potential for enhancing real-world adaptive radiotherapy.
Serialized Output Training by Learned Dominance
Jul 04, 2024Serialized Output Training (SOT) has showcased state-of-the-art performance in multi-talker speech recognition by sequentially decoding the speech of individual speakers. To address the challenging label-permutation issue, prior methods have relied on either the Permutation Invariant Training (PIT) or the time-based First-In-First-Out (FIFO) rule. This study presents a model-based serialization strategy that incorporates an auxiliary module into the Attention Encoder-Decoder architecture, autonomously identifying the crucial factors to order the output sequence of the speech components in multi-talker speech. Experiments conducted on the LibriSpeech and LibriMix databases reveal that our approach significantly outperforms the PIT and FIFO baselines in both 2-mix and 3-mix scenarios. Further analysis shows that the serialization module identifies dominant speech components in a mixture by factors including loudness and gender, and orders speech components based on the dominance score.
A Comprehensive Investigation on Speaker Augmentation for Speaker Recognition
Jun 11, 2024



Data augmentation (DA) has played a pivotal role in the success of deep speaker recognition. Current DA techniques primarily focus on speaker-preserving augmentation, which does not change the speaker trait of the speech and does not create new speakers. Recent research has shed light on the potential of speaker augmentation, which generates new speakers to enrich the training dataset. In this study, we delve into two speaker augmentation approaches: speed perturbation (SP) and vocal tract length perturbation (VTLP). Despite the empirical utilization of both methods, a comprehensive investigation into their efficacy is lacking. Our study, conducted using two public datasets, VoxCeleb and CN-Celeb, revealed that both SP and VTLP are proficient at generating new speakers, leading to significant performance improvements in speaker recognition. Furthermore, they exhibit distinct properties in sensitivity to perturbation factors and data complexity, hinting at the potential benefits of their fusion. Our research underscores the substantial potential of speaker augmentation, highlighting the importance of in-depth exploration and analysis.
A Framework of SO-equivariant Non-linear Representation Learning and its Application to Electronic-Structure Hamiltonian Prediction
May 10, 2024We present both a theoretical and a methodological framework that addresses a critical challenge in applying deep learning to physical systems: the reconciliation of non-linear expressiveness with SO(3)-equivariance in predictions of SO(3)-equivariant quantities, such as the electronic-structure Hamiltonian. Inspired by covariant theory in physics, we address this problem by exploring the mathematical relationships between SO(3)-invariant and SO(3)-equivariant quantities and their representations. We first construct theoretical SO(3)-invariant quantities derived from the SO(3)-equivariant regression targets, and use these invariant quantities as supervisory labels to guide the learning of high-quality SO(3)-invariant features. Given that SO(3)-invariance is preserved under non-linear operations, the encoding process for invariant features can extensively utilize non-linear mappings, thereby fully capturing the non-linear patterns inherent in physical systems. Building on this foundation, we propose a gradient-based mechanism to induce SO(3)-equivariant encodings of various degrees from the learned SO(3)-invariant features. This mechanism can incorporate non-linear expressive capabilities into SO(3)-equivariant representations, while theoretically preserving their equivariant properties as we prove. Our approach offers a promising general solution to the critical dilemma between equivariance and non-linear expressiveness in deep learning methodologies. We apply our theory and method to the electronic-structure Hamiltonian prediction tasks, demonstrating state-of-the-art performance across six benchmark databases.
Harmonizing Covariance and Expressiveness for Deep Hamiltonian Regression in Crystalline Material Research: a Hybrid Cascaded Regression Framework
Jan 15, 2024



Deep learning for Hamiltonian regression of quantum systems in material research necessitates satisfying the covariance laws, among which achieving SO(3)-equivariance without sacrificing the expressiveness capability of networks remains an elusive challenge due to the restriction to non-linear mappings on guaranteeing theoretical equivariance. To alleviate the covariance-expressiveness dilemma, we propose a hybrid framework with two cascaded regression stages. The first stage, i.e., a theoretically-guaranteed covariant neural network modeling symmetry properties of 3D atom systems, predicts baseline Hamiltonians with theoretically covariant features extracted, assisting the second stage in learning covariance. Meanwhile, the second stage, powered by a non-linear 3D graph Transformer network we propose for structural modeling of atomic systems, refines the first stage's output as a fine-grained prediction of Hamiltonians with better expressiveness capability. The combination of a theoretically covariant yet inevitably less expressive model with a highly expressive non-linear network enables precise, generalizable predictions while maintaining robust covariance under coordinate transformations. Our method achieves state-of-the-art performance in Hamiltonian prediction for electronic structure calculations, confirmed through experiments on six crystalline material databases. The codes and configuration scripts are available in the supplementary material.
1DFormer: Learning 1D Landmark Representations via Transformer for Facial Landmark Tracking
Nov 01, 2023Recently, heatmap regression methods based on 1D landmark representations have shown prominent performance on locating facial landmarks. However, previous methods ignored to make deep explorations on the good potentials of 1D landmark representations for sequential and structural modeling of multiple landmarks to track facial landmarks. To address this limitation, we propose a Transformer architecture, namely 1DFormer, which learns informative 1D landmark representations by capturing the dynamic and the geometric patterns of landmarks via token communications in both temporal and spatial dimensions for facial landmark tracking. For temporal modeling, we propose a recurrent token mixing mechanism, an axis-landmark-positional embedding mechanism, as well as a confidence-enhanced multi-head attention mechanism to adaptively and robustly embed long-term landmark dynamics into their 1D representations; for structure modeling, we design intra-group and inter-group structure modeling mechanisms to encode the component-level as well as global-level facial structure patterns as a refinement for the 1D representations of landmarks through token communications in the spatial dimension via 1D convolutional layers. Experimental results on the 300VW and the TF databases show that 1DFormer successfully models the long-range sequential patterns as well as the inherent facial structures to learn informative 1D representations of landmark sequences, and achieves state-of-the-art performance on facial landmark tracking.
Spot keywords from very noisy and mixed speech
May 28, 2023Most existing keyword spotting research focuses on conditions with slight or moderate noise. In this paper, we try to tackle a more challenging task: detecting keywords buried under strong interfering speech (10 times higher than the keyword in amplitude), and even worse, mixed with other keywords. We propose a novel Mix Training (MT) strategy that encourages the model to discover low-energy keywords from noisy and mixed speech. Experiments were conducted with a vanilla CNN and two EfficientNet (B0/B2) architectures. The results evaluated with the Google Speech Command dataset demonstrated that the proposed mix training approach is highly effective and outperforms standard data augmentation and mixup training.
Attentive One-Dimensional Heatmap Regression for Facial Landmark Detection and Tracking
Apr 11, 2020
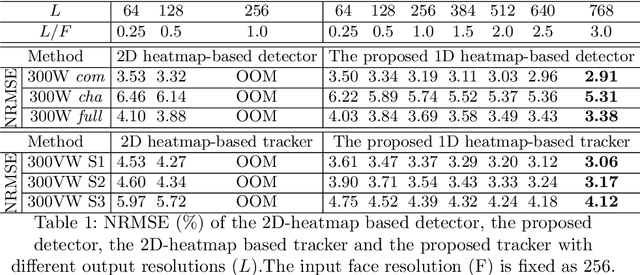
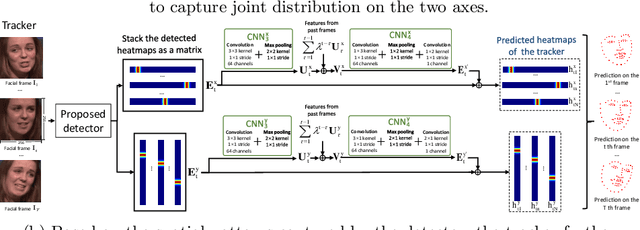

Although heatmap regression is considered a state-of-the-art method to locate facial landmarks, it suffers from huge spatial complexity and is prone to quantization error. To address this, we propose a novel attentive one-dimensional heatmap regression method for facial landmark localization. First, we predict two groups of 1D heatmaps to represent the marginal distributions of the x and y coordinates. These 1D heatmaps reduce spatial complexity significantly compared to current heatmap regression methods, which use 2D heatmaps to represent the joint distributions of x and y coordinates. With much lower spatial complexity, the proposed method can output high-resolution 1D heatmaps despite limited GPU memory, significantly alleviating the quantization error. Second, a co-attention mechanism is adopted to model the inherent spatial patterns existing in x and y coordinates, and therefore the joint distributions on the x and y axes are also captured. Third, based on the 1D heatmap structures, we propose a facial landmark detector capturing spatial patterns for landmark detection on an image; and a tracker further capturing temporal patterns with a temporal refinement mechanism for landmark tracking. Experimental results on four benchmark databases demonstrate the superiority of our method.
Multiple Face Analyses through Adversarial Learning
Nov 18, 2019
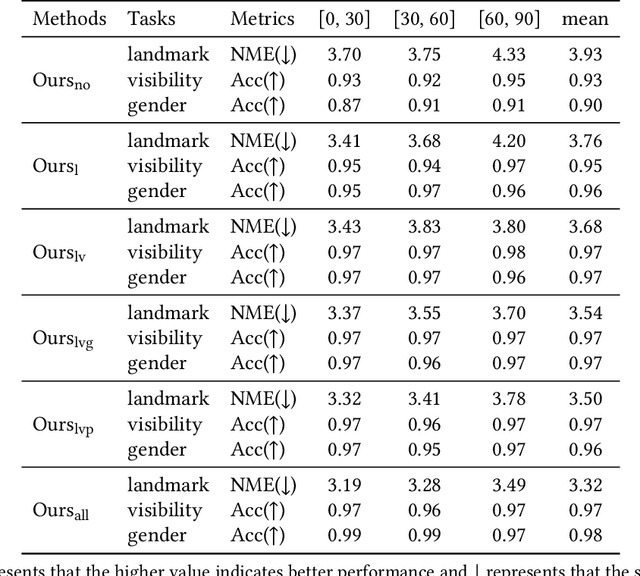
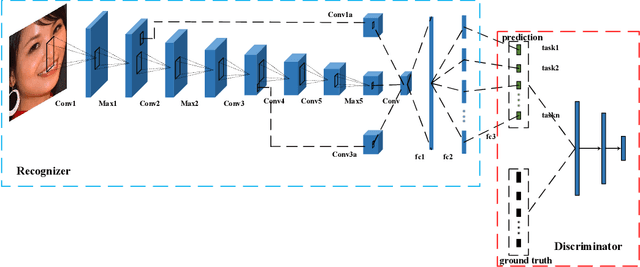
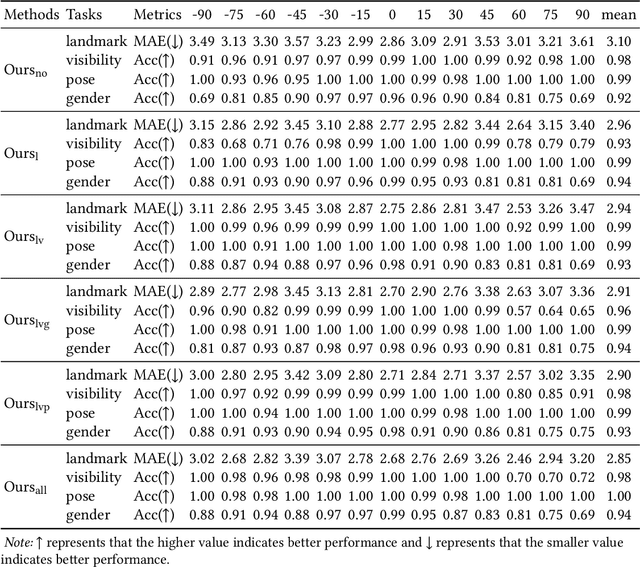
This inherent relations among multiple face analysis tasks, such as landmark detection, head pose estimation, gender recognition and face attribute estimation are crucial to boost the performance of each task, but have not been thoroughly explored since typically these multiple face analysis tasks are handled as separate tasks. In this paper, we propose a novel deep multi-task adversarial learning method to localize facial landmark, estimate head pose and recognize gender jointly or estimate multiple face attributes simultaneously through exploring their dependencies from both image representation-level and label-level. Specifically, the proposed method consists of a deep recognition network R and a discriminator D. The deep recognition network is used to learn the shared middle-level image representation and conducts multiple face analysis tasks simultaneously. Through multi-task learning mechanism, the recognition network explores the dependencies among multiple face analysis tasks, such as facial landmark localization, head pose estimation, gender recognition and face attribute estimation from image representation-level. The discriminator is introduced to enforce the distribution of the multiple face analysis tasks to converge to that inherent in the ground-truth labels. During training, the recognizer tries to confuse the discriminator, while the discriminator competes with the recognizer through distinguishing the predicted label combination from the ground-truth one. Though adversarial learning, we explore the dependencies among multiple face analysis tasks from label-level. Experimental results on four benchmark databases, i.e., the AFLW database, the Multi-PIE database, the CelebA database and the LFWA database, demonstrate the effectiveness of the proposed method for multiple face analyses.