 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMLHarness: A Scalable Benchmarking System for MLCommons
Nov 09, 2021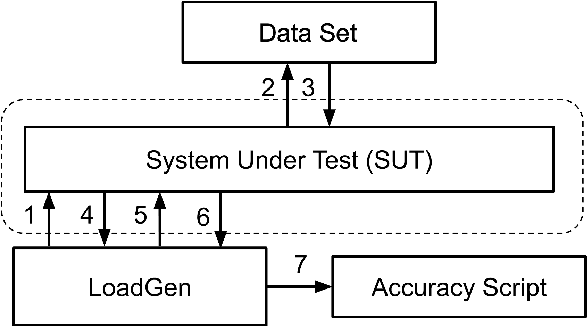
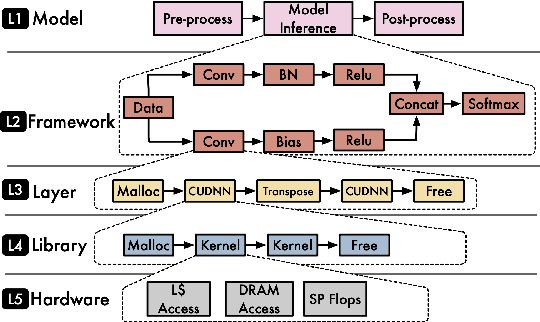

With the society's growing adoption of machine learning (ML) and deep learning (DL) for various intelligent solutions, it becomes increasingly imperative to standardize a common set of measures for ML/DL models with large scale open datasets under common development practices and resources so that people can benchmark and compare models quality and performance on a common ground. MLCommons has emerged recently as a driving force from both industry and academia to orchestrate such an effort. Despite its wide adoption as standardized benchmarks, MLCommons Inference has only included a limited number of ML/DL models (in fact seven models in total). This significantly limits the generality of MLCommons Inference's benchmarking results because there are many more novel ML/DL models from the research community, solving a wide range of problems with different inputs and outputs modalities. To address such a limitation, we propose MLHarness, a scalable benchmarking harness system for MLCommons Inference with three distinctive features: (1) it codifies the standard benchmark process as defined by MLCommons Inference including the models, datasets, DL frameworks, and software and hardware systems; (2) it provides an easy and declarative approach for model developers to contribute their models and datasets to MLCommons Inference; and (3) it includes the support of a wide range of models with varying inputs/outputs modalities so that we can scalably benchmark these models across different datasets, frameworks, and hardware systems. This harness system is developed on top of the MLModelScope system, and will be open sourced to the community. Our experimental results demonstrate the superior flexibility and scalability of this harness system for MLCommons Inference benchmarking.
Why Lottery Ticket Wins? A Theoretical Perspective of Sample Complexity on Pruned Neural Networks
Oct 12, 2021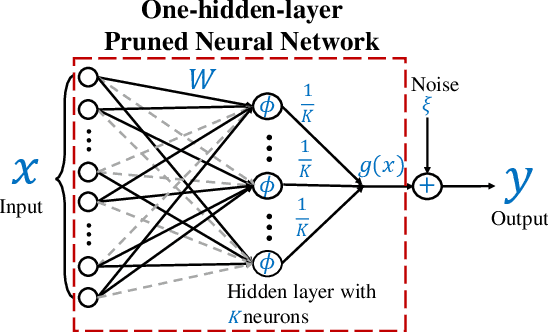
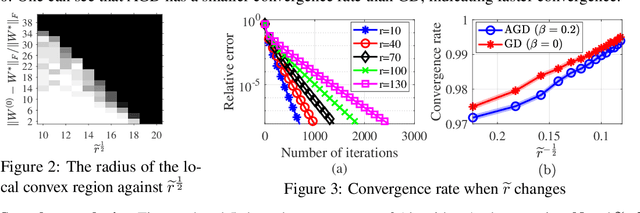
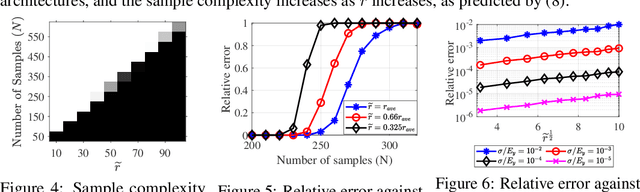
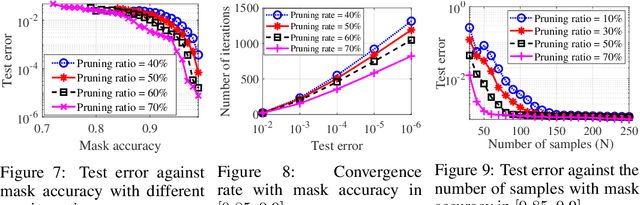
The \textit{lottery ticket hypothesis} (LTH) states that learning on a properly pruned network (the \textit{winning ticket}) improves test accuracy over the original unpruned network. Although LTH has been justified empirically in a broad range of deep neural network (DNN) involved applications like computer vision and natural language processing, the theoretical validation of the improved generalization of a winning ticket remains elusive. To the best of our knowledge, our work, for the first time, characterizes the performance of training a pruned neural network by analyzing the geometric structure of the objective function and the sample complexity to achieve zero generalization error. We show that the convex region near a desirable model with guaranteed generalization enlarges as the neural network model is pruned, indicating the structural importance of a winning ticket. Moreover, when the algorithm for training a pruned neural network is specified as an (accelerated) stochastic gradient descent algorithm, we theoretically show that the number of samples required for achieving zero generalization error is proportional to the number of the non-pruned weights in the hidden layer. With a fixed number of samples, training a pruned neural network enjoys a faster convergence rate to the desired model than training the original unpruned one, providing a formal justification of the improved generalization of the winning ticket. Our theoretical results are acquired from learning a pruned neural network of one hidden layer, while experimental results are further provided to justify the implications in pruning multi-layer neural networks.
Exploration of Quantum Neural Architecture by Mixing Quantum Neuron Designs
Sep 08, 2021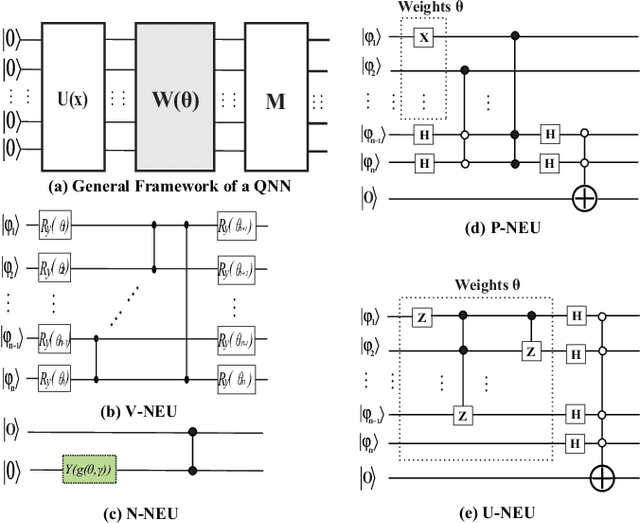

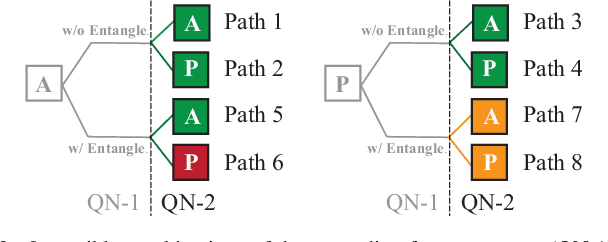
With the constant increase of the number of quantum bits (qubits) in the actual quantum computers, implementing and accelerating the prevalent deep learning on quantum computers are becoming possible. Along with this trend, there emerge quantum neural architectures based on different designs of quantum neurons. A fundamental question in quantum deep learning arises: what is the best quantum neural architecture? Inspired by the design of neural architectures for classical computing which typically employs multiple types of neurons, this paper makes the very first attempt to mix quantum neuron designs to build quantum neural architectures. We observe that the existing quantum neuron designs may be quite different but complementary, such as neurons from variation quantum circuits (VQC) and Quantumflow. More specifically, VQC can apply real-valued weights but suffer from being extended to multiple layers, while QuantumFlow can build a multi-layer network efficiently, but is limited to use binary weights. To take their respective advantages, we propose to mix them together and figure out a way to connect them seamlessly without additional costly measurement. We further investigate the design principles to mix quantum neurons, which can provide guidance for quantum neural architecture exploration in the future. Experimental results demonstrate that the identified quantum neural architectures with mixed quantum neurons can achieve 90.62% of accuracy on the MNIST dataset, compared with 52.77% and 69.92% on the VQC and QuantumFlow, respectively.
Can Noise on Qubits Be Learned in Quantum Neural Network? A Case Study on QuantumFlow
Sep 08, 2021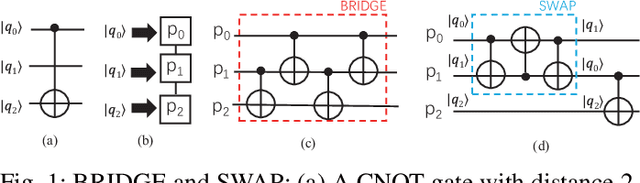
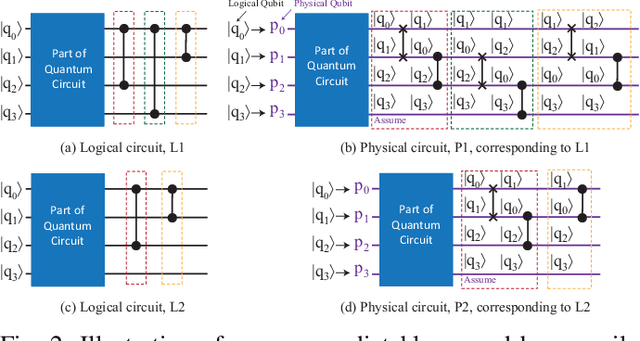
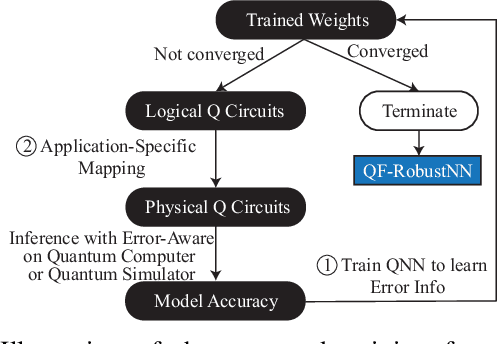
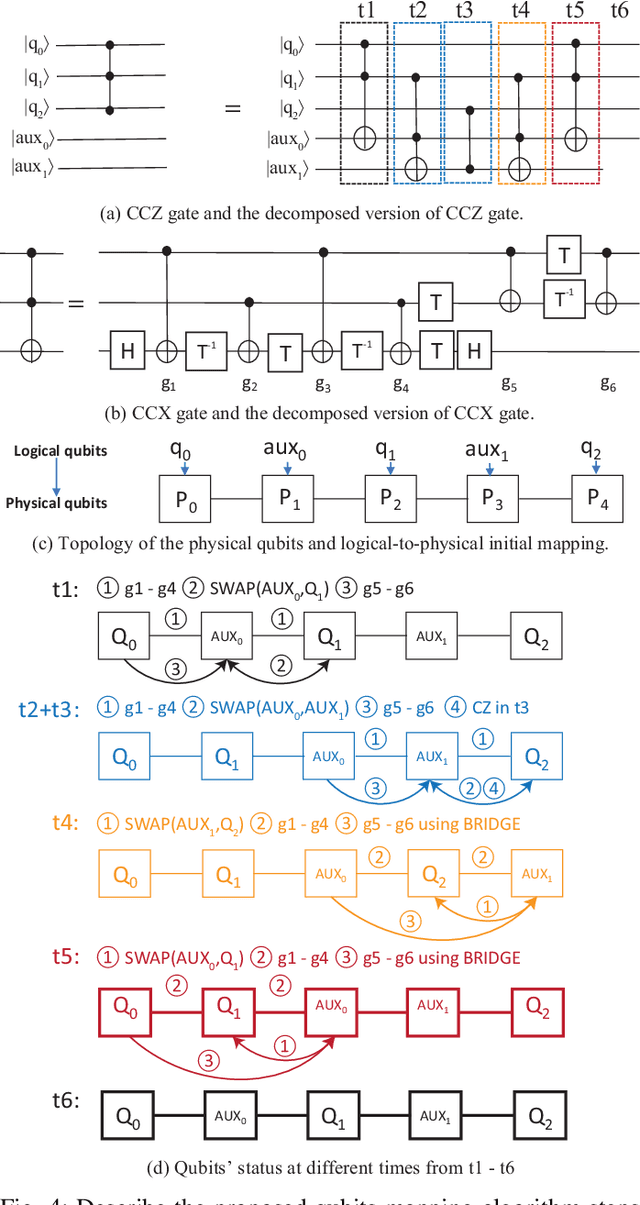
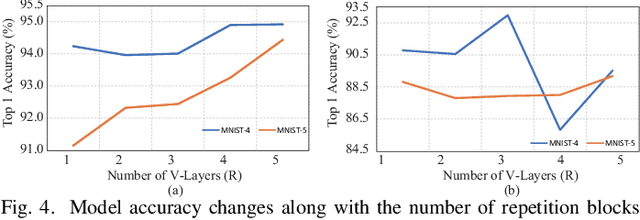
In the noisy intermediate-scale quantum (NISQ) era, one of the key questions is how to deal with the high noise level existing in physical quantum bits (qubits). Quantum error correction is promising but requires an extensive number (e.g., over 1,000) of physical qubits to create one "perfect" qubit, exceeding the capacity of the existing quantum computers. This paper aims to tackle the noise issue from another angle: instead of creating perfect qubits for general quantum algorithms, we investigate the potential to mitigate the noise issue for dedicate algorithms. Specifically, this paper targets quantum neural network (QNN), and proposes to learn the errors in the training phase, so that the identified QNN model can be resilient to noise. As a result, the implementation of QNN needs no or a small number of additional physical qubits, which is more realistic for the near-term quantum computers. To achieve this goal, an application-specific compiler is essential: on the one hand, the error cannot be learned if the mapping from logical qubits to physical qubits exists randomness; on the other hand, the compiler needs to be efficient so that the lengthy training procedure can be completed in a reasonable time. In this paper, we utilize the recent QNN framework, QuantumFlow, as a case study. Experimental results show that the proposed approach can optimize QNN models for different errors in qubits, achieving up to 28% accuracy improvement compared with the model obtained by the error-agnostic training.
Open Relation Modeling: Learning to Define Relations between Entities
Aug 20, 2021
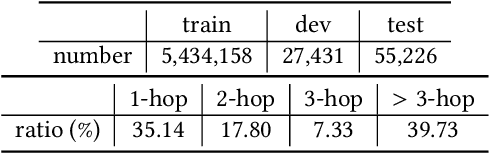

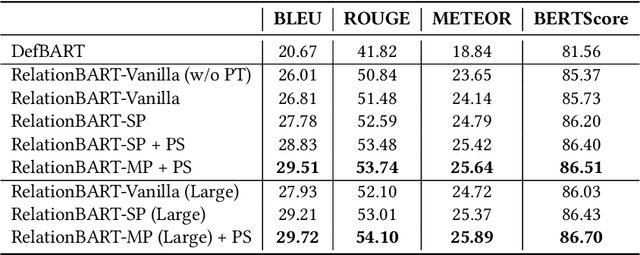
Relations between entities can be represented by different instances, e.g., a sentence containing both entities or a fact in a Knowledge Graph (KG). However, these instances may not well capture the general relations between entities, may be difficult to understand by humans, even may not be found due to the incompleteness of the knowledge source. In this paper, we introduce the Open Relation Modeling task - given two entities, generate a coherent sentence describing the relation between them. To solve this task, we propose to teach machines to generate definition-like relation descriptions by letting them learn from definitions of entities. Specifically, we fine-tune Pre-trained Language Models (PLMs) to produce definitions conditioned on extracted entity pairs. To help PLMs reason between entities and provide additional relational knowledge to PLMs for open relation modeling, we incorporate reasoning paths in KGs and include a reasoning path selection mechanism. We show that PLMs can select interpretable and informative reasoning paths by confidence estimation, and the selected path can guide PLMs to generate better relation descriptions. Experimental results show that our model can generate concise but informative relation descriptions that capture the representative characteristics of entities and relations.
Generic Neural Architecture Search via Regression
Aug 04, 2021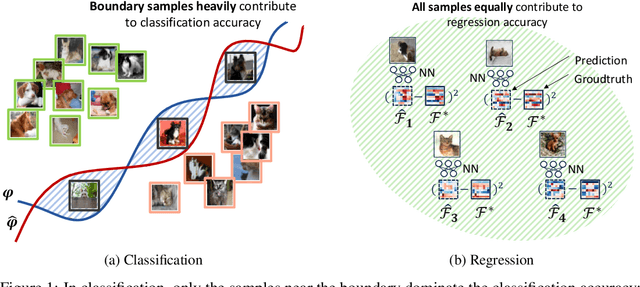
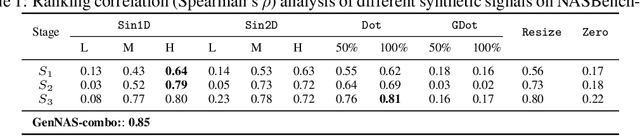
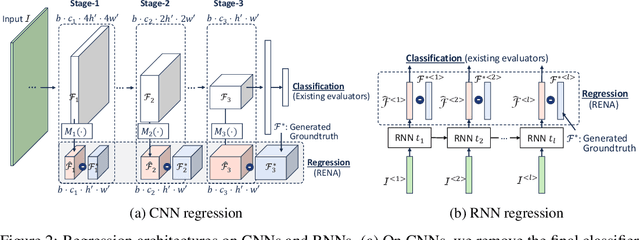
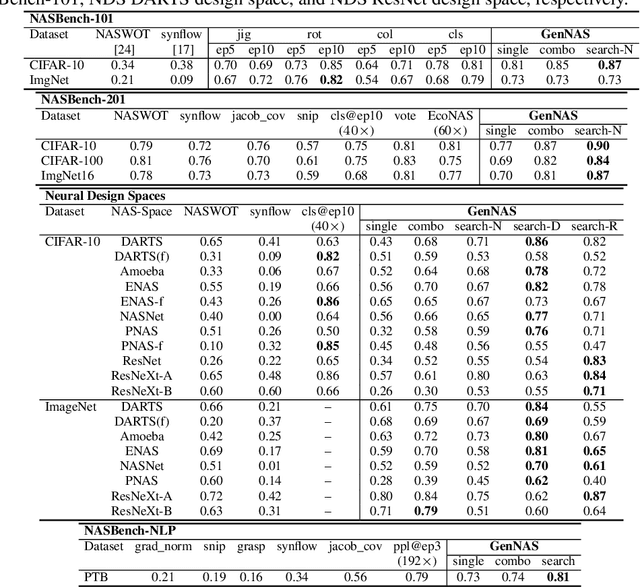
Most existing neural architecture search (NAS) algorithms are dedicated to the downstream tasks, e.g., image classification in computer vision. However, extensive experiments have shown that, prominent neural architectures, such as ResNet in computer vision and LSTM in natural language processing, are generally good at extracting patterns from the input data and perform well on different downstream tasks. These observations inspire us to ask: Is it necessary to use the performance of specific downstream tasks to evaluate and search for good neural architectures? Can we perform NAS effectively and efficiently while being agnostic to the downstream task? In this work, we attempt to affirmatively answer the above two questions and improve the state-of-the-art NAS solution by proposing a novel and generic NAS framework, termed Generic NAS (GenNAS). GenNAS does not use task-specific labels but instead adopts \textit{regression} on a set of manually designed synthetic signal bases for architecture evaluation. Such a self-supervised regression task can effectively evaluate the intrinsic power of an architecture to capture and transform the input signal patterns, and allow more sufficient usage of training samples. We then propose an automatic task search to optimize the combination of synthetic signals using limited downstream-task-specific labels, further improving the performance of GenNAS. We also thoroughly evaluate GenNAS's generality and end-to-end NAS performance on all search spaces, which outperforms almost all existing works with significant speedup.
Global Rhythm Style Transfer Without Text Transcriptions
Jun 16, 2021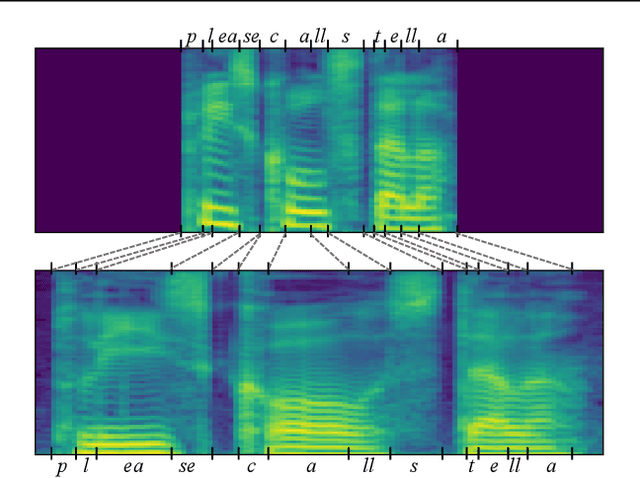
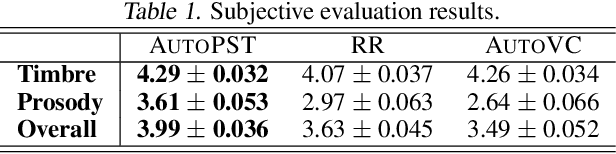
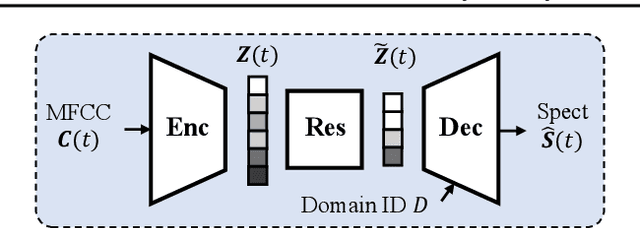

Prosody plays an important role in characterizing the style of a speaker or an emotion, but most non-parallel voice or emotion style transfer algorithms do not convert any prosody information. Two major components of prosody are pitch and rhythm. Disentangling the prosody information, particularly the rhythm component, from the speech is challenging because it involves breaking the synchrony between the input speech and the disentangled speech representation. As a result, most existing prosody style transfer algorithms would need to rely on some form of text transcriptions to identify the content information, which confines their application to high-resource languages only. Recently, SpeechSplit has made sizeable progress towards unsupervised prosody style transfer, but it is unable to extract high-level global prosody style in an unsupervised manner. In this paper, we propose AutoPST, which can disentangle global prosody style from speech without relying on any text transcriptions. AutoPST is an Autoencoder-based Prosody Style Transfer framework with a thorough rhythm removal module guided by the self-expressive representation learning. Experiments on different style transfer tasks show that AutoPST can effectively convert prosody that correctly reflects the styles of the target domains.
Measuring Fine-Grained Domain Relevance of Terms: A Hierarchical Core-Fringe Approach
May 27, 2021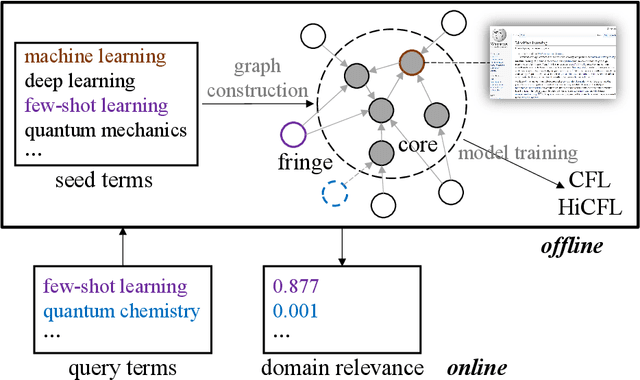
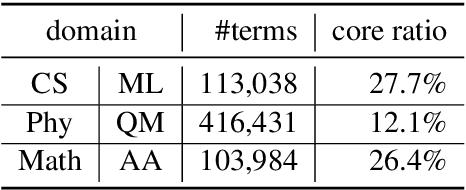
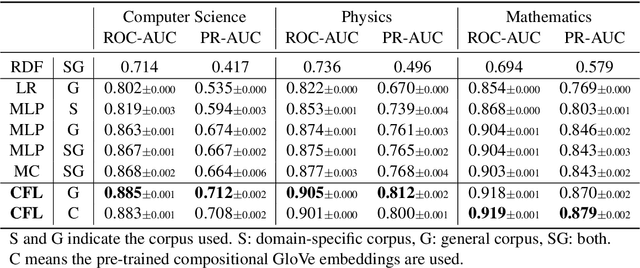
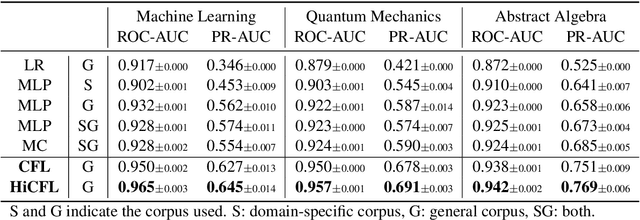
We propose to measure fine-grained domain relevance - the degree that a term is relevant to a broad (e.g., computer science) or narrow (e.g., deep learning) domain. Such measurement is crucial for many downstream tasks in natural language processing. To handle long-tail terms, we build a core-anchored semantic graph, which uses core terms with rich description information to bridge the vast remaining fringe terms semantically. To support a fine-grained domain without relying on a matching corpus for supervision, we develop hierarchical core-fringe learning, which learns core and fringe terms jointly in a semi-supervised manner contextualized in the hierarchy of the domain. To reduce expensive human efforts, we employ automatic annotation and hierarchical positive-unlabeled learning. Our approach applies to big or small domains, covers head or tail terms, and requires little human effort. Extensive experiments demonstrate that our methods outperform strong baselines and even surpass professional human performance.
Heterogeneous Contrastive Learning
May 19, 2021
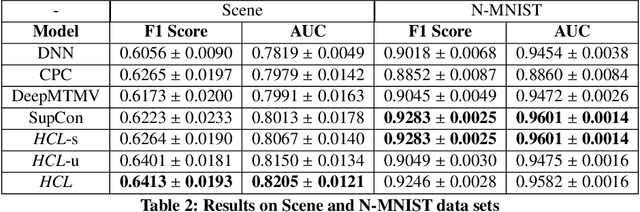
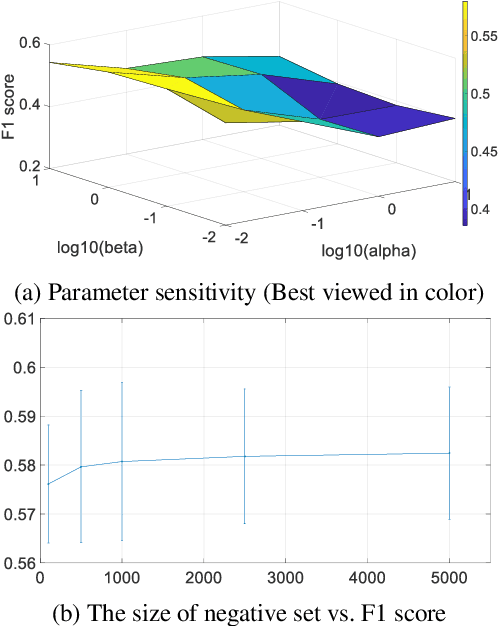
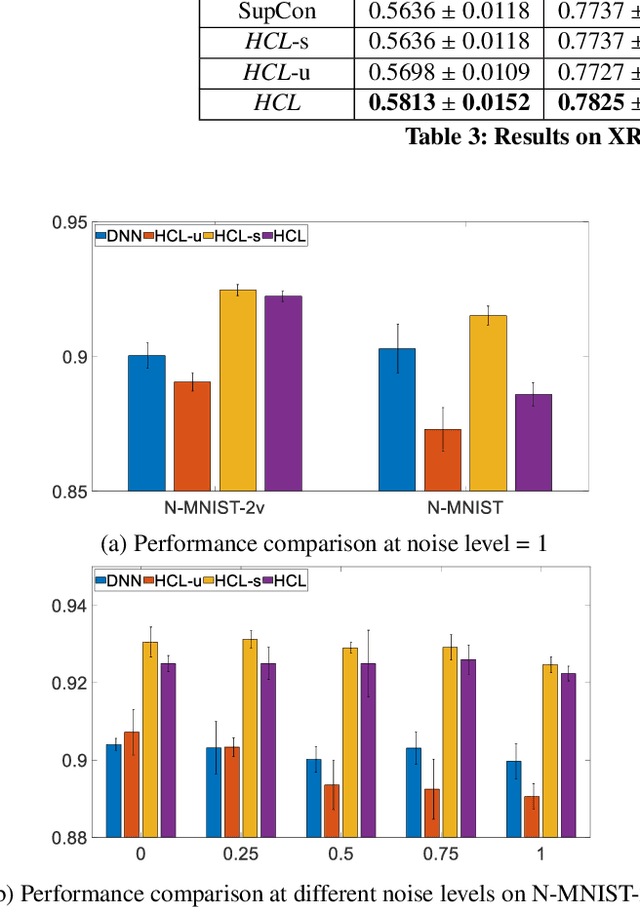
With the advent of big data across multiple high-impact applications, we are often facing the challenge of complex heterogeneity. The newly collected data usually consist of multiple modalities and characterized with multiple labels, thus exhibiting the co-existence of multiple types of heterogeneity. Although state-of-the-art techniques are good at modeling the complex heterogeneity with sufficient label information, such label information can be quite expensive to obtain in real applications, leading to sub-optimal performance using these techniques. Inspired by the capability of contrastive learning to utilize rich unlabeled data for improving performance, in this paper, we propose a unified heterogeneous learning framework, which combines both weighted unsupervised contrastive loss and weighted supervised contrastive loss to model multiple types of heterogeneity. We also provide theoretical analyses showing that the proposed weighted supervised contrastive loss is the lower bound of the mutual information of two samples from the same class and the weighted unsupervised contrastive loss is the lower bound of the mutual information between the hidden representation of two views of the same sample. Experimental results on real-world data sets demonstrate the effectiveness and the efficiency of the proposed method modeling multiple types of heterogeneity.
Pseudo-IoU: Improving Label Assignment in Anchor-Free Object Detection
Apr 29, 2021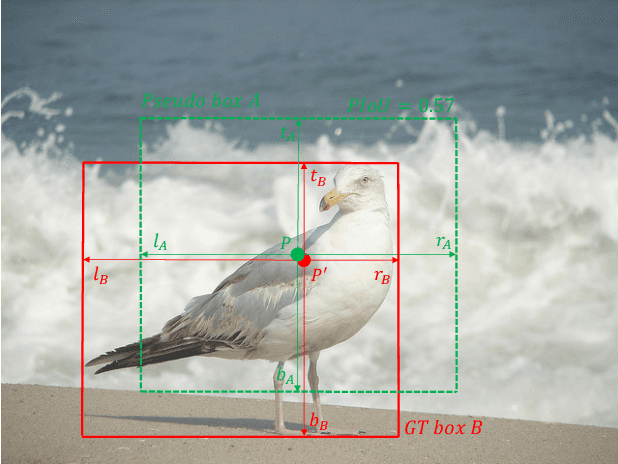
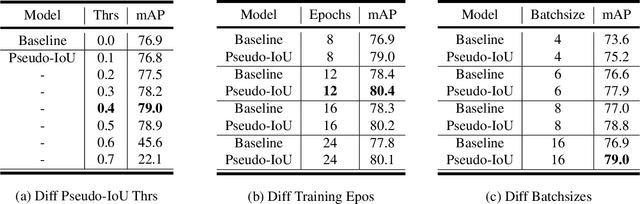
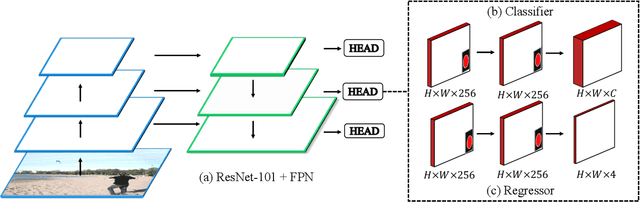
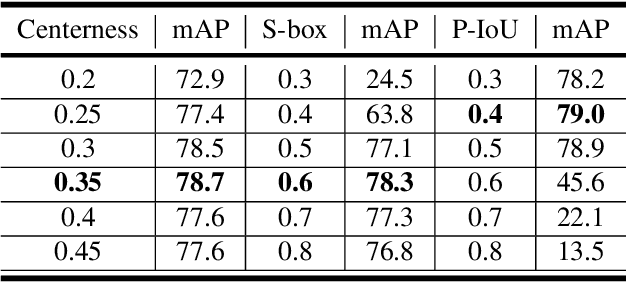
Current anchor-free object detectors are quite simple and effective yet lack accurate label assignment methods, which limits their potential in competing with classic anchor-based models that are supported by well-designed assignment methods based on the Intersection-over-Union~(IoU) metric. In this paper, we present \textbf{Pseudo-Intersection-over-Union~(Pseudo-IoU)}: a simple metric that brings more standardized and accurate assignment rule into anchor-free object detection frameworks without any additional computational cost or extra parameters for training and testing, making it possible to further improve anchor-free object detection by utilizing training samples of good quality under effective assignment rules that have been previously applied in anchor-based methods. By incorporating Pseudo-IoU metric into an end-to-end single-stage anchor-free object detection framework, we observe consistent improvements in their performance on general object detection benchmarks such as PASCAL VOC and MSCOCO. Our method (single-model and single-scale) also achieves comparable performance to other recent state-of-the-art anchor-free methods without bells and whistles. Our code is based on mmdetection toolbox and will be made publicly available at https://github.com/SHI-Labs/Pseudo-IoU-for-Anchor-Free-Object-Detection.