 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Question Answering via only 2D Vision-Language Models
May 28, 2025Large vision-language models (LVLMs) have significantly advanced numerous fields. In this work, we explore how to harness their potential to address 3D scene understanding tasks, using 3D question answering (3D-QA) as a representative example. Due to the limited training data in 3D, we do not train LVLMs but infer in a zero-shot manner. Specifically, we sample 2D views from a 3D point cloud and feed them into 2D models to answer a given question. When the 2D model is chosen, e.g., LLAVA-OV, the quality of sampled views matters the most. We propose cdViews, a novel approach to automatically selecting critical and diverse Views for 3D-QA. cdViews consists of two key components: viewSelector prioritizing critical views based on their potential to provide answer-specific information, and viewNMS enhancing diversity by removing redundant views based on spatial overlap. We evaluate cdViews on the widely-used ScanQA and SQA benchmarks, demonstrating that it achieves state-of-the-art performance in 3D-QA while relying solely on 2D models without fine-tuning. These findings support our belief that 2D LVLMs are currently the most effective alternative (of the resource-intensive 3D LVLMs) for addressing 3D tasks.
Plenodium: UnderWater 3D Scene Reconstruction with Plenoptic Medium Representation
May 27, 2025



We present Plenodium (plenoptic medium), an effective and efficient 3D representation framework capable of jointly modeling both objects and participating media. In contrast to existing medium representations that rely solely on view-dependent modeling, our novel plenoptic medium representation incorporates both directional and positional information through spherical harmonics encoding, enabling highly accurate underwater scene reconstruction. To address the initialization challenge in degraded underwater environments, we propose the pseudo-depth Gaussian complementation to augment COLMAP-derived point clouds with robust depth priors. In addition, a depth ranking regularized loss is developed to optimize the geometry of the scene and improve the ordinal consistency of the depth maps. Extensive experiments on real-world underwater datasets demonstrate that our method achieves significant improvements in 3D reconstruction. Furthermore, we conduct a simulated dataset with ground truth and the controllable scattering medium to demonstrate the restoration capability of our method in underwater scenarios. Our code and dataset are available at https://plenodium.github.io/.
R-Genie: Reasoning-Guided Generative Image Editing
May 23, 2025While recent advances in image editing have enabled impressive visual synthesis capabilities, current methods remain constrained by explicit textual instructions and limited editing operations, lacking deep comprehension of implicit user intentions and contextual reasoning. In this work, we introduce a new image editing paradigm: reasoning-guided generative editing, which synthesizes images based on complex, multi-faceted textual queries accepting world knowledge and intention inference. To facilitate this task, we first construct a comprehensive dataset featuring over 1,000 image-instruction-edit triples that incorporate rich reasoning contexts and real-world knowledge. We then propose R-Genie: a reasoning-guided generative image editor, which synergizes the generation power of diffusion models with advanced reasoning capabilities of multimodal large language models. R-Genie incorporates a reasoning-attention mechanism to bridge linguistic understanding with visual synthesis, enabling it to handle intricate editing requests involving abstract user intentions and contextual reasoning relations. Extensive experimental results validate that R-Genie can equip diffusion models with advanced reasoning-based editing capabilities, unlocking new potentials for intelligent image synthesis.
Diff-MM: Exploring Pre-trained Text-to-Image Generation Model for Unified Multi-modal Object Tracking
May 19, 2025Multi-modal object tracking integrates auxiliary modalities such as depth, thermal infrared, event flow, and language to provide additional information beyond RGB images, showing great potential in improving tracking stabilization in complex scenarios. Existing methods typically start from an RGB-based tracker and learn to understand auxiliary modalities only from training data. Constrained by the limited multi-modal training data, the performance of these methods is unsatisfactory. To alleviate this limitation, this work proposes a unified multi-modal tracker Diff-MM by exploiting the multi-modal understanding capability of the pre-trained text-to-image generation model. Diff-MM leverages the UNet of pre-trained Stable Diffusion as a tracking feature extractor through the proposed parallel feature extraction pipeline, which enables pairwise image inputs for object tracking. We further introduce a multi-modal sub-module tuning method that learns to gain complementary information between different modalities. By harnessing the extensive prior knowledge in the generation model, we achieve a unified tracker with uniform parameters for RGB-N/D/T/E tracking. Experimental results demonstrate the promising performance of our method compared with recently proposed trackers, e.g., its AUC outperforms OneTracker by 8.3% on TNL2K.
Equal is Not Always Fair: A New Perspective on Hyperspectral Representation Non-Uniformity
May 16, 2025Hyperspectral image (HSI) representation is fundamentally challenged by pervasive non-uniformity, where spectral dependencies, spatial continuity, and feature efficiency exhibit complex and often conflicting behaviors. Most existing models rely on a unified processing paradigm that assumes homogeneity across dimensions, leading to suboptimal performance and biased representations. To address this, we propose FairHyp, a fairness-directed framework that explicitly disentangles and resolves the threefold non-uniformity through cooperative yet specialized modules. We introduce a Runge-Kutta-inspired spatial variability adapter to restore spatial coherence under resolution discrepancies, a multi-receptive field convolution module with sparse-aware refinement to enhance discriminative features while respecting inherent sparsity, and a spectral-context state space model that captures stable and long-range spectral dependencies via bidirectional Mamba scanning and statistical aggregation. Unlike one-size-fits-all solutions, FairHyp achieves dimension-specific adaptation while preserving global consistency and mutual reinforcement. This design is grounded in the view that non-uniformity arises from the intrinsic structure of HSI representations, rather than any particular task setting. To validate this, we apply FairHyp across four representative tasks including classification, denoising, super-resolution, and inpaintin, demonstrating its effectiveness in modeling a shared structural flaw. Extensive experiments show that FairHyp consistently outperforms state-of-the-art methods under varied imaging conditions. Our findings redefine fairness as a structural necessity in HSI modeling and offer a new paradigm for balancing adaptability, efficiency, and fidelity in high-dimensional vision tasks.
Diverse Semantics-Guided Feature Alignment and Decoupling for Visible-Infrared Person Re-Identification
May 01, 2025



Visible-Infrared Person Re-Identification (VI-ReID) is a challenging task due to the large modality discrepancy between visible and infrared images, which complicates the alignment of their features into a suitable common space. Moreover, style noise, such as illumination and color contrast, reduces the identity discriminability and modality invariance of features. To address these challenges, we propose a novel Diverse Semantics-guided Feature Alignment and Decoupling (DSFAD) network to align identity-relevant features from different modalities into a textual embedding space and disentangle identity-irrelevant features within each modality. Specifically, we develop a Diverse Semantics-guided Feature Alignment (DSFA) module, which generates pedestrian descriptions with diverse sentence structures to guide the cross-modality alignment of visual features. Furthermore, to filter out style information, we propose a Semantic Margin-guided Feature Decoupling (SMFD) module, which decomposes visual features into pedestrian-related and style-related components, and then constrains the similarity between the former and the textual embeddings to be at least a margin higher than that between the latter and the textual embeddings. Additionally, to prevent the loss of pedestrian semantics during feature decoupling, we design a Semantic Consistency-guided Feature Restitution (SCFR) module, which further excavates useful information for identification from the style-related features and restores it back into the pedestrian-related features, and then constrains the similarity between the features after restitution and the textual embeddings to be consistent with that between the features before decoupling and the textual embeddings. Extensive experiments on three VI-ReID datasets demonstrate the superiority of our DSFAD.
IMAGGarment-1: Fine-Grained Garment Generation for Controllable Fashion Design
Apr 17, 2025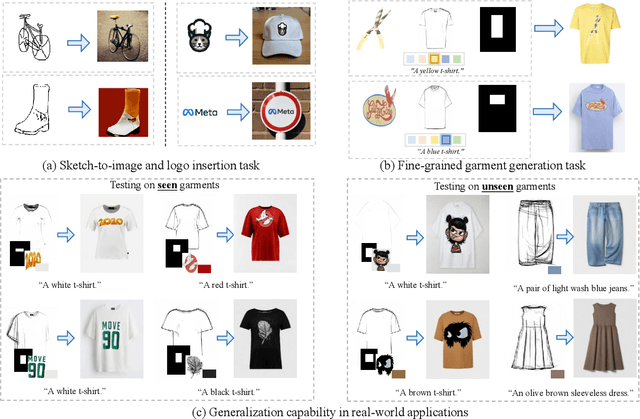
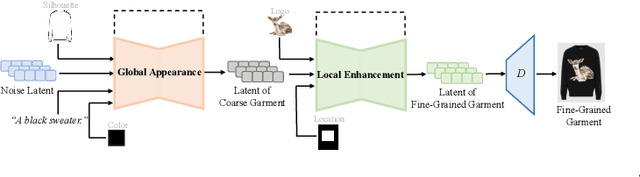
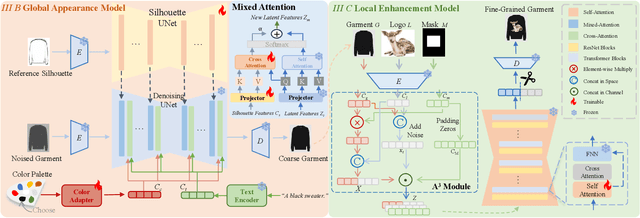

This paper presents IMAGGarment-1, a fine-grained garment generation (FGG) framework that enables high-fidelity garment synthesis with precise control over silhouette, color, and logo placement. Unlike existing methods that are limited to single-condition inputs, IMAGGarment-1 addresses the challenges of multi-conditional controllability in personalized fashion design and digital apparel applications. Specifically, IMAGGarment-1 employs a two-stage training strategy to separately model global appearance and local details, while enabling unified and controllable generation through end-to-end inference. In the first stage, we propose a global appearance model that jointly encodes silhouette and color using a mixed attention module and a color adapter. In the second stage, we present a local enhancement model with an adaptive appearance-aware module to inject user-defined logos and spatial constraints, enabling accurate placement and visual consistency. To support this task, we release GarmentBench, a large-scale dataset comprising over 180K garment samples paired with multi-level design conditions, including sketches, color references, logo placements, and textual prompts. Extensive experiments demonstrate that our method outperforms existing baselines, achieving superior structural stability, color fidelity, and local controllability performance. The code and model are available at https://github.com/muzishen/IMAGGarment-1.
The Tenth NTIRE 2025 Efficient Super-Resolution Challenge Report
Apr 14, 2025This paper presents a comprehensive review of the NTIRE 2025 Challenge on Single-Image Efficient Super-Resolution (ESR). The challenge aimed to advance the development of deep models that optimize key computational metrics, i.e., runtime, parameters, and FLOPs, while achieving a PSNR of at least 26.90 dB on the $\operatorname{DIV2K\_LSDIR\_valid}$ dataset and 26.99 dB on the $\operatorname{DIV2K\_LSDIR\_test}$ dataset. A robust participation saw \textbf{244} registered entrants, with \textbf{43} teams submitting valid entries. This report meticulously analyzes these methods and results, emphasizing groundbreaking advancements in state-of-the-art single-image ESR techniques. The analysis highlights innovative approaches and establishes benchmarks for future research in the field.
Multi-scale Activation, Refinement, and Aggregation: Exploring Diverse Cues for Fine-Grained Bird Recognition
Apr 12, 2025



Given the critical role of birds in ecosystems, Fine-Grained Bird Recognition (FGBR) has gained increasing attention, particularly in distinguishing birds within similar subcategories. Although Vision Transformer (ViT)-based methods often outperform Convolutional Neural Network (CNN)-based methods in FGBR, recent studies reveal that the limited receptive field of plain ViT model hinders representational richness and makes them vulnerable to scale variance. Thus, enhancing the multi-scale capabilities of existing ViT-based models to overcome this bottleneck in FGBR is a worthwhile pursuit. In this paper, we propose a novel framework for FGBR, namely Multi-scale Diverse Cues Modeling (MDCM), which explores diverse cues at different scales across various stages of a multi-scale Vision Transformer (MS-ViT) in an "Activation-Selection-Aggregation" paradigm. Specifically, we first propose a multi-scale cue activation module to ensure the discriminative cues learned at different stage are mutually different. Subsequently, a multi-scale token selection mechanism is proposed to remove redundant noise and highlight discriminative, scale-specific cues at each stage. Finally, the selected tokens from each stage are independently utilized for bird recognition, and the recognition results from multiple stages are adaptively fused through a multi-scale dynamic aggregation mechanism for final model decisions. Both qualitative and quantitative results demonstrate the effectiveness of our proposed MDCM, which outperforms CNN- and ViT-based models on several widely-used FGBR benchmarks.
ReCoM: Realistic Co-Speech Motion Generation with Recurrent Embedded Transformer
Mar 27, 2025We present ReCoM, an efficient framework for generating high-fidelity and generalizable human body motions synchronized with speech. The core innovation lies in the Recurrent Embedded Transformer (RET), which integrates Dynamic Embedding Regularization (DER) into a Vision Transformer (ViT) core architecture to explicitly model co-speech motion dynamics. This architecture enables joint spatial-temporal dependency modeling, thereby enhancing gesture naturalness and fidelity through coherent motion synthesis. To enhance model robustness, we incorporate the proposed DER strategy, which equips the model with dual capabilities of noise resistance and cross-domain generalization, thereby improving the naturalness and fluency of zero-shot motion generation for unseen speech inputs. To mitigate inherent limitations of autoregressive inference, including error accumulation and limited self-correction, we propose an iterative reconstruction inference (IRI) strategy. IRI refines motion sequences via cyclic pose reconstruction, driven by two key components: (1) classifier-free guidance improves distribution alignment between generated and real gestures without auxiliary supervision, and (2) a temporal smoothing process eliminates abrupt inter-frame transitions while ensuring kinematic continuity. Extensive experiments on benchmark datasets validate ReCoM's effectiveness, achieving state-of-the-art performance across metrics. Notably, it reduces the Fr\'echet Gesture Distance (FGD) from 18.70 to 2.48, demonstrating an 86.7% improvement in motion realism. Our project page is https://yong-xie-xy.github.io/ReCoM/.