 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Better Benchmark Datasets for Inductive Knowledge Graph Completion
Jun 14, 2024



Knowledge Graph Completion (KGC) attempts to predict missing facts in a Knowledge Graph (KG). Recently, there's been an increased focus on designing KGC methods that can excel in the {\it inductive setting}, where a portion or all of the entities and relations seen in inference are unobserved during training. Numerous benchmark datasets have been proposed for inductive KGC, all of which are subsets of existing KGs used for transductive KGC. However, we find that the current procedure for constructing inductive KGC datasets inadvertently creates a shortcut that can be exploited even while disregarding the relational information. Specifically, we observe that the Personalized PageRank (PPR) score can achieve strong or near SOTA performance on most inductive datasets. In this paper, we study the root cause of this problem. Using these insights, we propose an alternative strategy for constructing inductive KGC datasets that helps mitigate the PPR shortcut. We then benchmark multiple popular methods using the newly constructed datasets and analyze their performance. The new benchmark datasets help promote a better understanding of the capabilities and challenges of inductive KGC by removing any shortcuts that obfuscate performance.
Understanding the Generalizability of Link Predictors Under Distribution Shifts on Graphs
Jun 13, 2024



Recently, multiple models proposed for link prediction (LP) demonstrate impressive results on benchmark datasets. However, many popular benchmark datasets often assume that dataset samples are drawn from the same distribution (i.e., IID samples). In real-world situations, this assumption is often incorrect; since uncontrolled factors may lead train and test samples to come from separate distributions. To tackle the distribution shift problem, recent work focuses on creating datasets that feature distribution shifts and designing generalization methods that perform well on the new data. However, those studies only consider distribution shifts that affect {\it node-} and {\it graph-level} tasks, thus ignoring link-level tasks. Furthermore, relatively few LP generalization methods exist. To bridge this gap, we introduce a set of LP-specific data splits which utilizes structural properties to induce a controlled distribution shift. We verify the shift's effect empirically through evaluation of different SOTA LP methods and subsequently couple these methods with generalization techniques. Interestingly, LP-specific methods frequently generalize poorly relative to heuristics or basic GNN methods. Finally, this work provides analysis to uncover insights for enhancing LP generalization. Our code is available at: \href{https://github.com/revolins/LPStructGen}{https://github.com/revolins/LPStructGen}
Node-wise Filtering in Graph Neural Networks: A Mixture of Experts Approach
Jun 05, 2024



Graph Neural Networks (GNNs) have proven to be highly effective for node classification tasks across diverse graph structural patterns. Traditionally, GNNs employ a uniform global filter, typically a low-pass filter for homophilic graphs and a high-pass filter for heterophilic graphs. However, real-world graphs often exhibit a complex mix of homophilic and heterophilic patterns, rendering a single global filter approach suboptimal. In this work, we theoretically demonstrate that a global filter optimized for one pattern can adversely affect performance on nodes with differing patterns. To address this, we introduce a novel GNN framework Node-MoE that utilizes a mixture of experts to adaptively select the appropriate filters for different nodes. Extensive experiments demonstrate the effectiveness of Node-MoE on both homophilic and heterophilic graphs.
On the Intrinsic Self-Correction Capability of LLMs: Uncertainty and Latent Concept
Jun 04, 2024



Large Language Models (LLMs) can improve their responses when instructed to do so, a capability known as self-correction. When these instructions lack specific details about the issues in the response, this is referred to as leveraging the intrinsic self-correction capability. The empirical success of self-correction can be found in various applications, e.g., text detoxification and social bias mitigation. However, leveraging this self-correction capability may not always be effective, as it has the potential to revise an initially correct response into an incorrect one. In this paper, we endeavor to understand how and why leveraging the self-correction capability is effective. We identify that appropriate instructions can guide LLMs to a convergence state, wherein additional self-correction steps do not yield further performance improvements. We empirically demonstrate that model uncertainty and activated latent concepts jointly characterize the effectiveness of self-correction. Furthermore, we provide a mathematical formulation indicating that the activated latent concept drives the convergence of the model uncertainty and self-correction performance. Our analysis can also be generalized to the self-correction behaviors observed in Vision-Language Models (VLMs). Moreover, we highlight that task-agnostic debiasing can benefit from our principle in terms of selecting effective fine-tuning samples. Such initial success demonstrates the potential extensibility for better instruction tuning and safety alignment.
PDHG-Unrolled Learning-to-Optimize Method for Large-Scale Linear Programming
Jun 04, 2024



Solving large-scale linear programming (LP) problems is an important task in various areas such as communication networks, power systems, finance and logistics. Recently, two distinct approaches have emerged to expedite LP solving: (i) First-order methods (FOMs); (ii) Learning to optimize (L2O). In this work, we propose an FOM-unrolled neural network (NN) called PDHG-Net, and propose a two-stage L2O method to solve large-scale LP problems. The new architecture PDHG-Net is designed by unrolling the recently emerged PDHG method into a neural network, combined with channel-expansion techniques borrowed from graph neural networks. We prove that the proposed PDHG-Net can recover PDHG algorithm, thus can approximate optimal solutions of LP instances with a polynomial number of neurons. We propose a two-stage inference approach: first use PDHG-Net to generate an approximate solution, and then apply PDHG algorithm to further improve the solution. Experiments show that our approach can significantly accelerate LP solving, achieving up to a 3$\times$ speedup compared to FOMs for large-scale LP problems.
Cross-Domain Graph Data Scaling: A Showcase with Diffusion Models
Jun 04, 2024Models for natural language and images benefit from data scaling behavior: the more data fed into the model, the better they perform. This 'better with more' phenomenon enables the effectiveness of large-scale pre-training on vast amounts of data. However, current graph pre-training methods struggle to scale up data due to heterogeneity across graphs. To achieve effective data scaling, we aim to develop a general model that is able to capture diverse data patterns of graphs and can be utilized to adaptively help the downstream tasks. To this end, we propose UniAug, a universal graph structure augmentor built on a diffusion model. We first pre-train a discrete diffusion model on thousands of graphs across domains to learn the graph structural patterns. In the downstream phase, we provide adaptive enhancement by conducting graph structure augmentation with the help of the pre-trained diffusion model via guided generation. By leveraging the pre-trained diffusion model for structure augmentation, we consistently achieve performance improvements across various downstream tasks in a plug-and-play manner. To the best of our knowledge, this study represents the first demonstration of a data-scaling graph structure augmentor on graphs across domains.
Large Language Models for Education: A Survey and Outlook
Apr 01, 2024

The advent of Large Language Models (LLMs) has brought in a new era of possibilities in the realm of education. This survey paper summarizes the various technologies of LLMs in educational settings from multifaceted perspectives, encompassing student and teacher assistance, adaptive learning, and commercial tools. We systematically review the technological advancements in each perspective, organize related datasets and benchmarks, and identify the risks and challenges associated with deploying LLMs in education. Furthermore, we outline future research opportunities, highlighting the potential promising directions. Our survey aims to provide a comprehensive technological picture for educators, researchers, and policymakers to harness the power of LLMs to revolutionize educational practices and foster a more effective personalized learning environment.
Automate Knowledge Concept Tagging on Math Questions with LLMs
Mar 26, 2024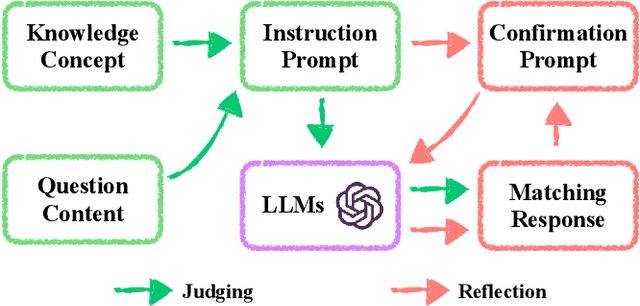
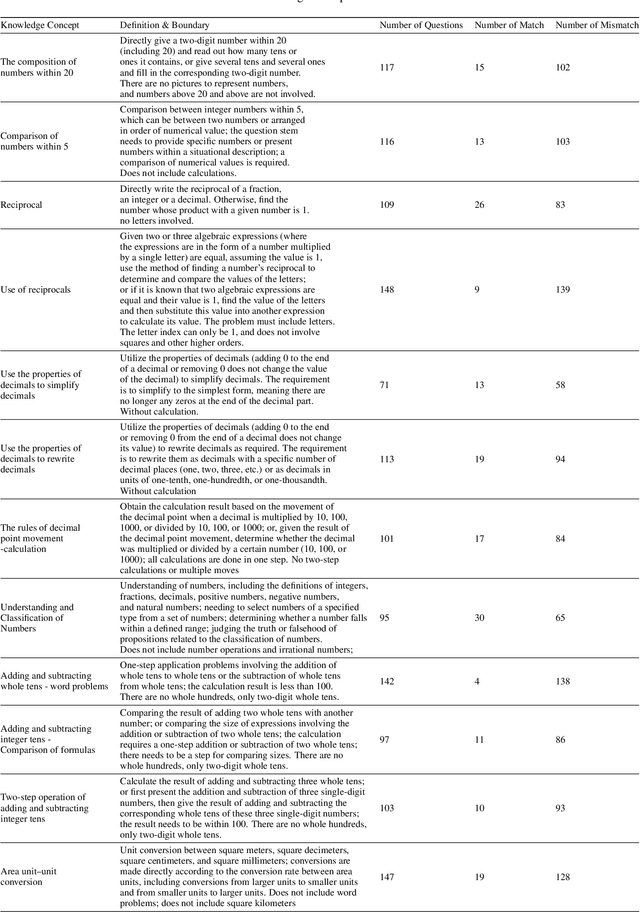
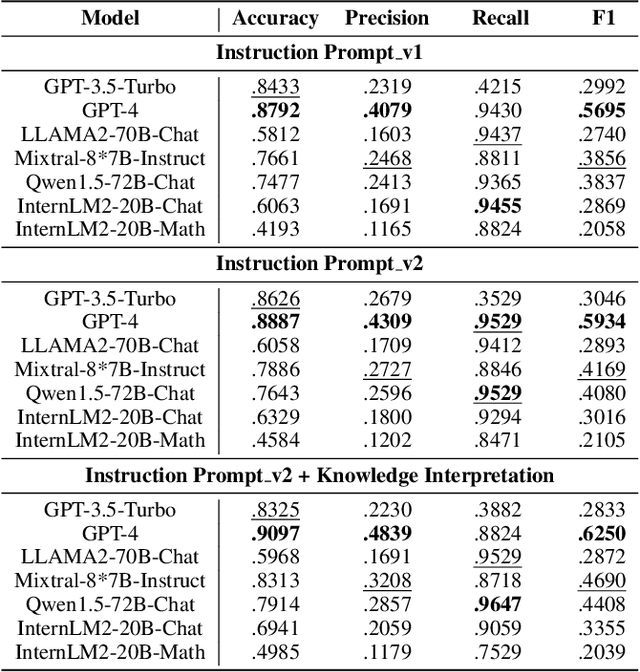
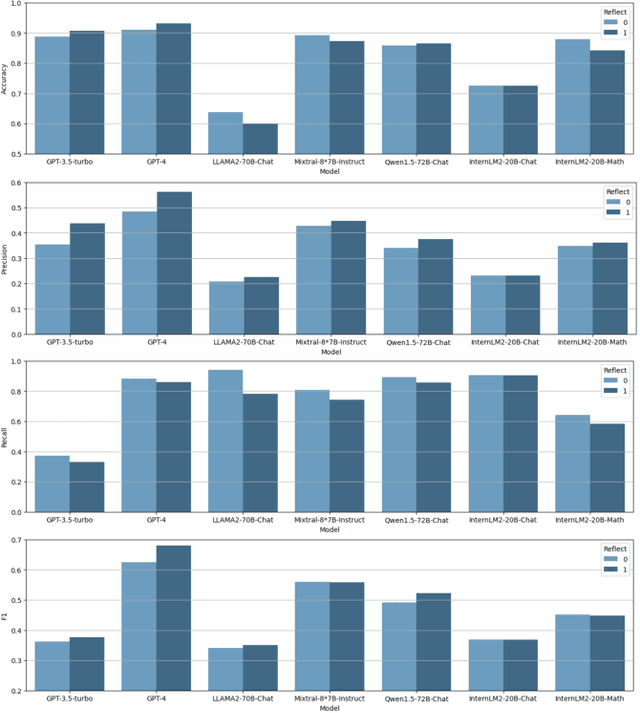
Knowledge concept tagging for questions plays a crucial role in contemporary intelligent educational applications, including learning progress diagnosis, practice question recommendations, and course content organization. Traditionally, these annotations have been conducted manually with help from pedagogical experts, as the task requires not only a strong semantic understanding of both question stems and knowledge definitions but also deep insights into connecting question-solving logic with corresponding knowledge concepts. In this paper, we explore automating the tagging task using Large Language Models (LLMs), in response to the inability of prior manual methods to meet the rapidly growing demand for concept tagging in questions posed by advanced educational applications. Moreover, the zero/few-shot learning capability of LLMs makes them well-suited for application in educational scenarios, which often face challenges in collecting large-scale, expertise-annotated datasets. By conducting extensive experiments with a variety of representative LLMs, we demonstrate that LLMs are a promising tool for concept tagging in math questions. Furthermore, through case studies examining the results from different LLMs, we draw some empirical conclusions about the key factors for success in applying LLMs to the automatic concept tagging task.
Unveiling and Mitigating Memorization in Text-to-image Diffusion Models through Cross Attention
Mar 17, 2024



Recent advancements in text-to-image diffusion models have demonstrated their remarkable capability to generate high-quality images from textual prompts. However, increasing research indicates that these models memorize and replicate images from their training data, raising tremendous concerns about potential copyright infringement and privacy risks. In our study, we provide a novel perspective to understand this memorization phenomenon by examining its relationship with cross-attention mechanisms. We reveal that during memorization, the cross-attention tends to focus disproportionately on the embeddings of specific tokens. The diffusion model is overfitted to these token embeddings, memorizing corresponding training images. To elucidate this phenomenon, we further identify and discuss various intrinsic findings of cross-attention that contribute to memorization. Building on these insights, we introduce an innovative approach to detect and mitigate memorization in diffusion models. The advantage of our proposed method is that it will not compromise the speed of either the training or the inference processes in these models while preserving the quality of generated images. Our code is available at https://github.com/renjie3/MemAttn .
The Good and The Bad: Exploring Privacy Issues in Retrieval-Augmented Generation
Feb 23, 2024



Retrieval-augmented generation (RAG) is a powerful technique to facilitate language model with proprietary and private data, where data privacy is a pivotal concern. Whereas extensive research has demonstrated the privacy risks of large language models (LLMs), the RAG technique could potentially reshape the inherent behaviors of LLM generation, posing new privacy issues that are currently under-explored. In this work, we conduct extensive empirical studies with novel attack methods, which demonstrate the vulnerability of RAG systems on leaking the private retrieval database. Despite the new risk brought by RAG on the retrieval data, we further reveal that RAG can mitigate the leakage of the LLMs' training data. Overall, we provide new insights in this paper for privacy protection of retrieval-augmented LLMs, which benefit both LLMs and RAG systems builders. Our code is available at https://github.com/phycholosogy/RAG-privacy.