 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre Top School Students More Critical of Their Professors? Mining Comments on RateMyProfessor.com
Jan 23, 2021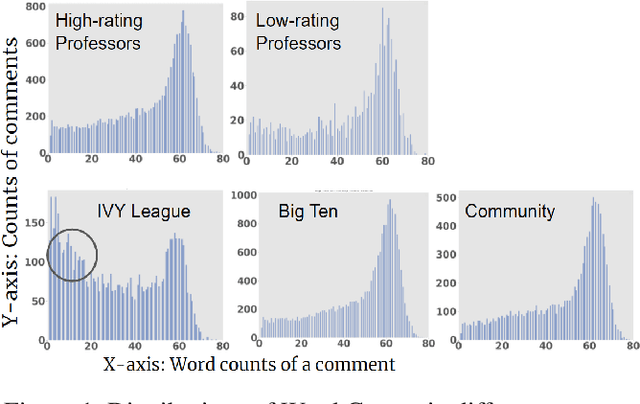
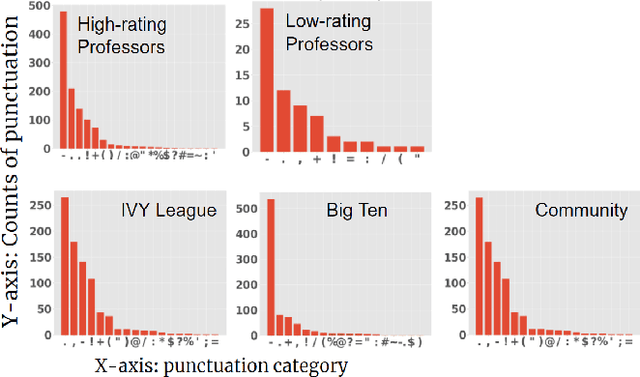
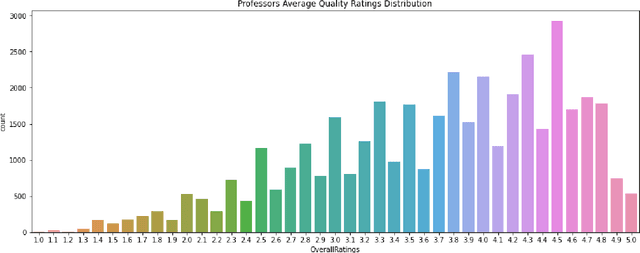
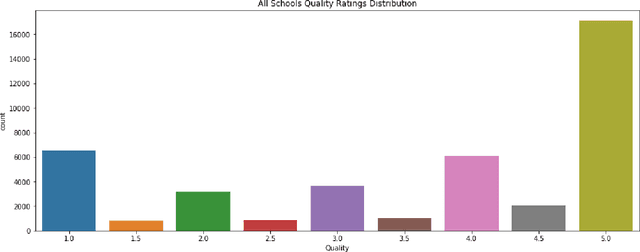
Student reviews and comments on RateMyProfessor.com reflect realistic learning experiences of students. Such information provides a large-scale data source to examine the teaching quality of the lecturers. In this paper, we propose an in-depth analysis of these comments. First, we partition our data into different comparison groups. Next, we perform exploratory data analysis to delve into the data. Furthermore, we employ Latent Dirichlet Allocation and sentiment analysis to extract topics and understand the sentiments associated with the comments. We uncover interesting insights about the characteristics of both college students and professors. Our study proves that student reviews and comments contain crucial information and can serve as essential references for enrollment in courses and universities.
DAIL: Dataset-Aware and Invariant Learning for Face Recognition
Jan 14, 2021
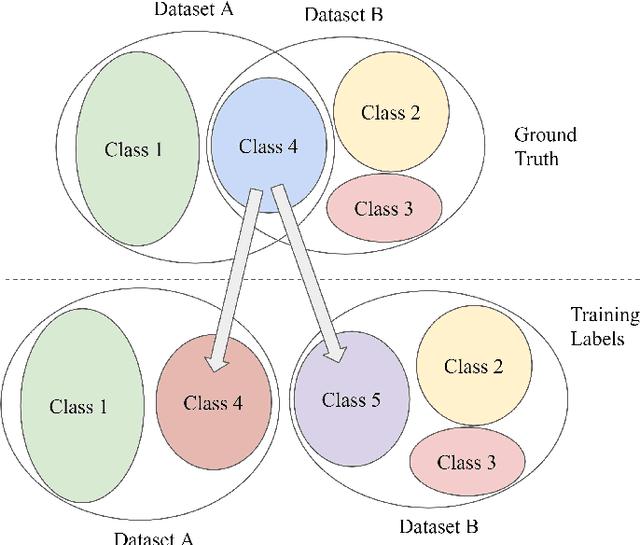
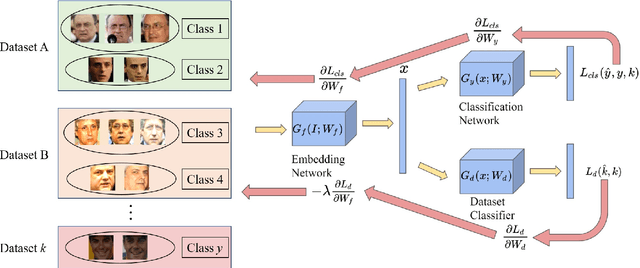
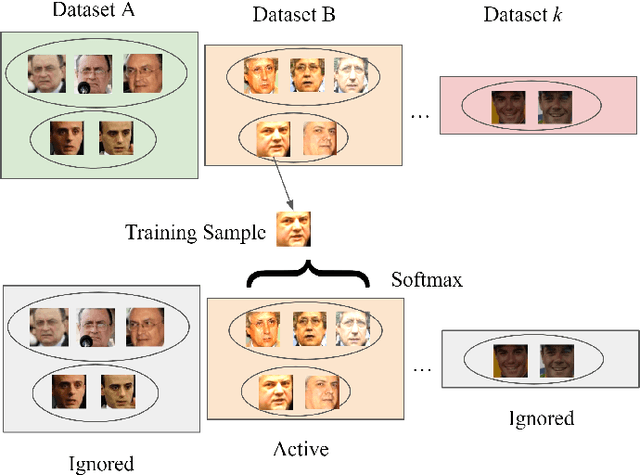
To achieve good performance in face recognition, a large scale training dataset is usually required. A simple yet effective way to improve recognition performance is to use a dataset as large as possible by combining multiple datasets in the training. However, it is problematic and troublesome to naively combine different datasets due to two major issues. First, the same person can possibly appear in different datasets, leading to an identity overlapping issue between different datasets. Naively treating the same person as different classes in different datasets during training will affect back-propagation and generate non-representative embeddings. On the other hand, manually cleaning labels may take formidable human efforts, especially when there are millions of images and thousands of identities. Second, different datasets are collected in different situations and thus will lead to different domain distributions. Naively combining datasets will make it difficult to learn domain invariant embeddings across different datasets. In this paper, we propose DAIL: Dataset-Aware and Invariant Learning to resolve the above-mentioned issues. To solve the first issue of identity overlapping, we propose a dataset-aware loss for multi-dataset training by reducing the penalty when the same person appears in multiple datasets. This can be readily achieved with a modified softmax loss with a dataset-aware term. To solve the second issue, domain adaptation with gradient reversal layers is employed for dataset invariant learning. The proposed approach not only achieves state-of-the-art results on several commonly used face recognition validation sets, including LFW, CFP-FP, and AgeDB-30, but also shows great benefit for practical use.
Semantic Layout Manipulation with High-Resolution Sparse Attention
Dec 14, 2020
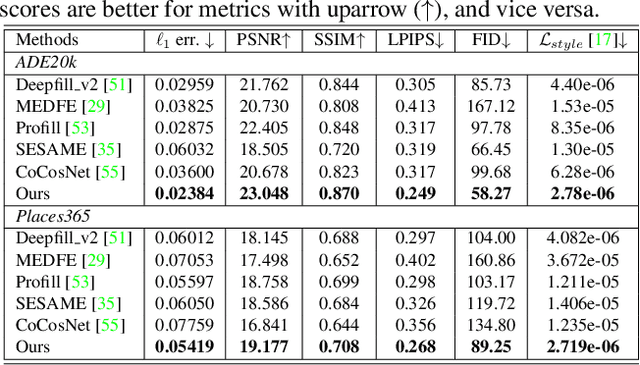
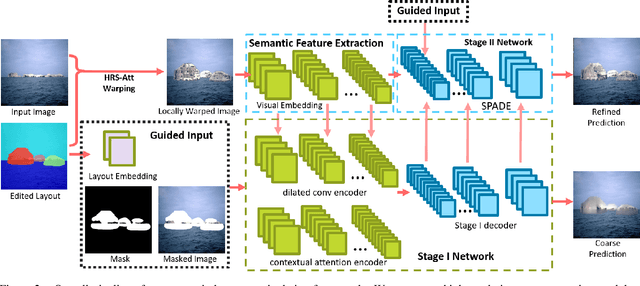
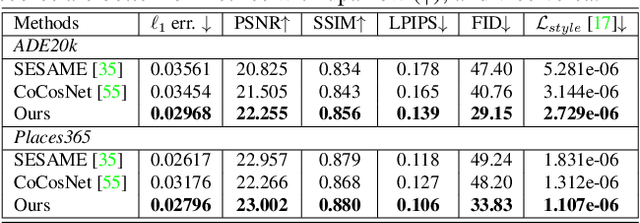
We tackle the problem of semantic image layout manipulation, which aims to manipulate an input image by editing its semantic label map. A core problem of this task is how to transfer visual details from the input images to the new semantic layout while making the resulting image visually realistic. Recent work on learning cross-domain correspondence has shown promising results for global layout transfer with dense attention-based warping. However, this method tends to lose texture details due to the lack of smoothness and resolution in the correspondence and warped images. To adapt this paradigm for the layout manipulation task, we propose a high-resolution sparse attention module that effectively transfers visual details to new layouts at a resolution up to 512x512. To further improve visual quality, we introduce a novel generator architecture consisting of a semantic encoder and a two-stage decoder for coarse-to-fine synthesis. Experiments on the ADE20k and Places365 datasets demonstrate that our proposed approach achieves substantial improvements over the existing inpainting and layout manipulation methods.
TAP: Text-Aware Pre-training for Text-VQA and Text-Caption
Dec 08, 2020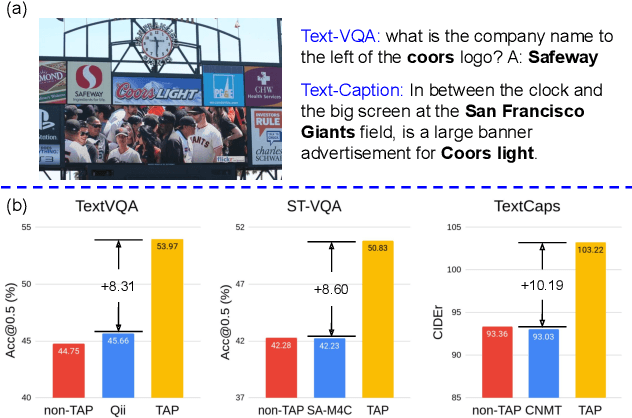
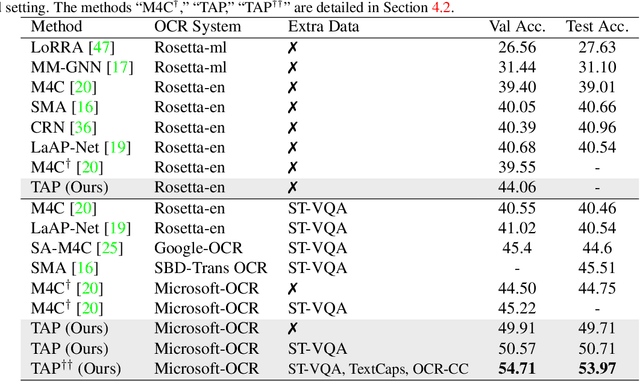
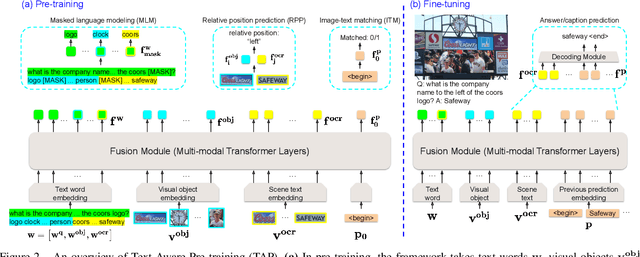
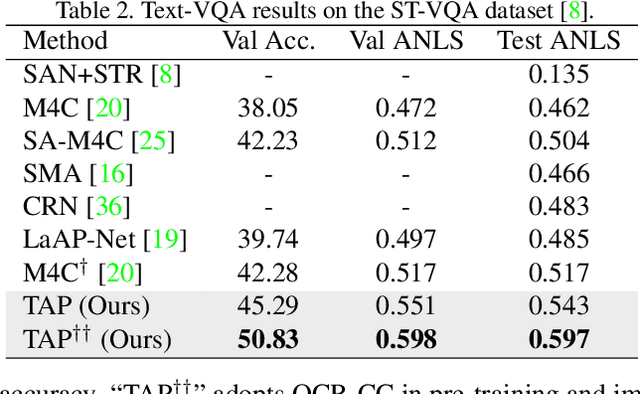
In this paper, we propose Text-Aware Pre-training (TAP) for Text-VQA and Text-Caption tasks. These two tasks aim at reading and understanding scene text in images for question answering and image caption generation, respectively. In contrast to the conventional vision-language pre-training that fails to capture scene text and its relationship with the visual and text modalities, TAP explicitly incorporates scene text (generated from OCR engines) in pre-training. With three pre-training tasks, including masked language modeling (MLM), image-text (contrastive) matching (ITM), and relative (spatial) position prediction (RPP), TAP effectively helps the model learn a better aligned representation among the three modalities: text word, visual object, and scene text. Due to this aligned representation learning, even pre-trained on the same downstream task dataset, TAP already boosts the absolute accuracy on the TextVQA dataset by +5.4%, compared with a non-TAP baseline. To further improve the performance, we build a large-scale dataset based on the Conceptual Caption dataset, named OCR-CC, which contains 1.4 million scene text-related image-text pairs. Pre-trained on this OCR-CC dataset, our approach outperforms the state of the art by large margins on multiple tasks, i.e., +8.3% accuracy on TextVQA, +8.6% accuracy on ST-VQA, and +10.2 CIDEr score on TextCaps.
Multi-Scale 2D Temporal Adjacent Networks for Moment Localization with Natural Language
Dec 04, 2020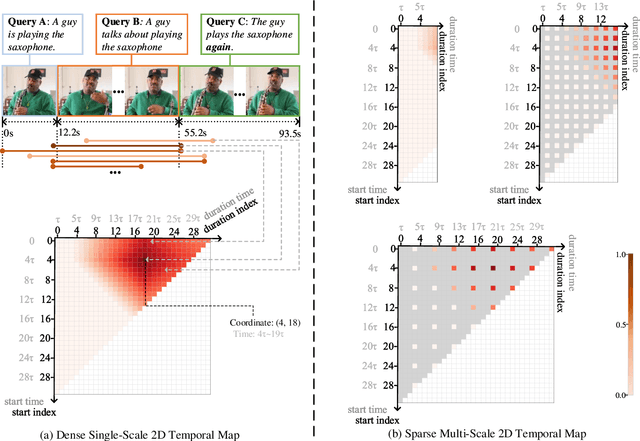
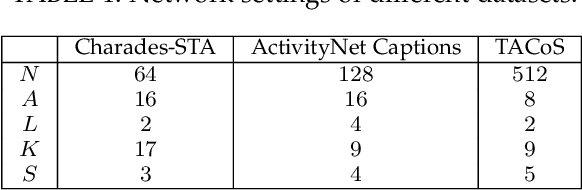
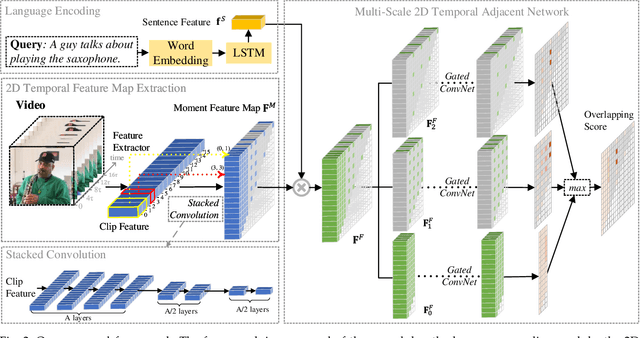
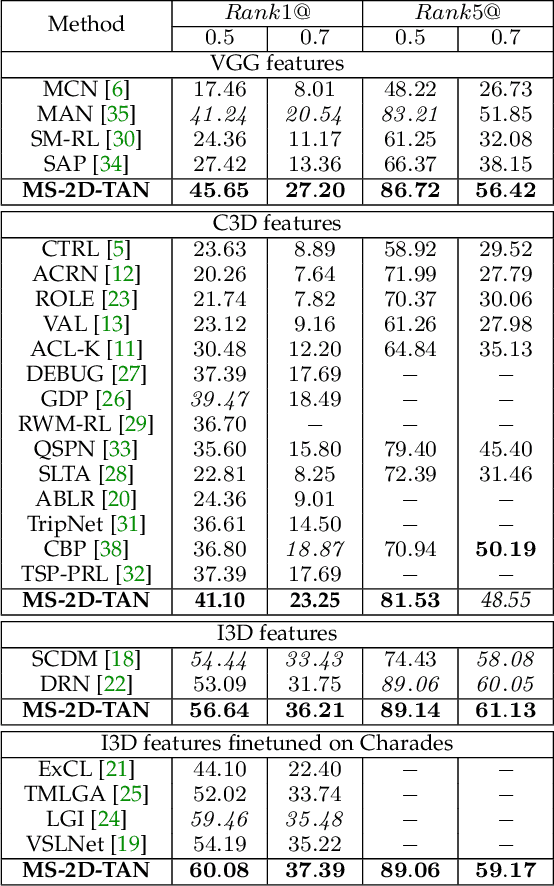
We address the problem of retrieving a specific moment from an untrimmed video by natural language. It is a challenging problem because a target moment may take place in the context of other temporal moments in the untrimmed video. Existing methods cannot tackle this challenge well since they do not fully consider the temporal contexts between temporal moments. In this paper, we model the temporal context between video moments by a set of predefined two-dimensional maps under different temporal scales. For each map, one dimension indicates the starting time of a moment and the other indicates the duration. These 2D temporal maps can cover diverse video moments with different lengths, while representing their adjacent contexts at different temporal scales. Based on the 2D temporal maps, we propose a Multi-Scale Temporal Adjacent Network (MS-2D-TAN), a single-shot framework for moment localization. It is capable of encoding the adjacent temporal contexts at each scale, while learning discriminative features for matching video moments with referring expressions. We evaluate the proposed MS-2D-TAN on three challenging benchmarks, i.e., Charades-STA, ActivityNet Captions, and TACoS, where our MS-2D-TAN outperforms the state of the art.
XraySyn: Realistic View Synthesis From a Single Radiograph Through CT Priors
Dec 04, 2020

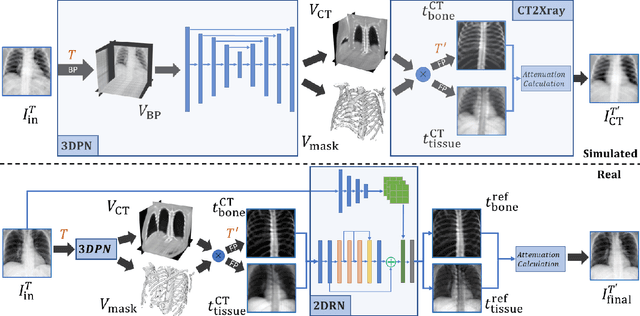

A radiograph visualizes the internal anatomy of a patient through the use of X-ray, which projects 3D information onto a 2D plane. Hence, radiograph analysis naturally requires physicians to relate the prior about 3D human anatomy to 2D radiographs. Synthesizing novel radiographic views in a small range can assist physicians in interpreting anatomy more reliably; however, radiograph view synthesis is heavily ill-posed, lacking in paired data, and lacking in differentiable operations to leverage learning-based approaches. To address these problems, we use Computed Tomography (CT) for radiograph simulation and design a differentiable projection algorithm, which enables us to achieve geometrically consistent transformations between the radiography and CT domains. Our method, XraySyn, can synthesize novel views on real radiographs through a combination of realistic simulation and finetuning on real radiographs. To the best of our knowledge, this is the first work on radiograph view synthesis. We show that by gaining an understanding of radiography in 3D space, our method can be applied to radiograph bone extraction and suppression without groundtruth bone labels.
Slender Object Detection: Diagnoses and Improvements
Nov 21, 2020


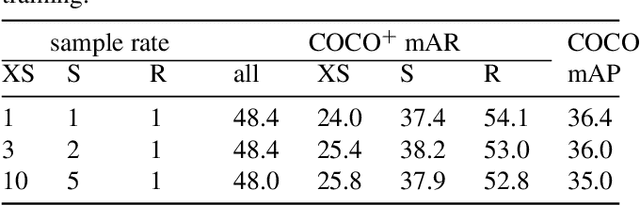
In this paper, we are concerned with the detection of a particular type of objects with extreme aspect ratios, namely slender objects. In real-world scenarios as well as widely-used datasets (such as COCO), slender objects are actually very common. However, this type of object has been largely overlooked by previous object detection algorithms. Upon our investigation, for a classical object detection method, a drastic drop of 18.9% mAP on COCO is observed, if solely evaluated on slender objects. Therefore, We systematically study the problem of slender object detection in this work. Accordingly, an analytical framework with carefully designed benchmark and evaluation protocols is established, in which different algorithms and modules can be inspected and compared. Our key findings include: 1) the essential role of anchors in label assignment; 2) the descriptive capability of the 2-point representation; 3) the crucial strategies for improving the detection of slender objects and regular objects. Our work identifies and extends the insights of existing methods that are previously underexploited. Furthermore, we propose a feature adaption strategy that achieves clear and consistent improvements over current representative object detection methods. In particular, a natural and effective extension of the center prior, which leads to a significant improvement on slender objects, is devised. We believe this work opens up new opportunities and calibrates ablation standards for future research in the field of object detection.
Content-based Analysis of the Cultural Differences between TikTok and Douyin
Nov 03, 2020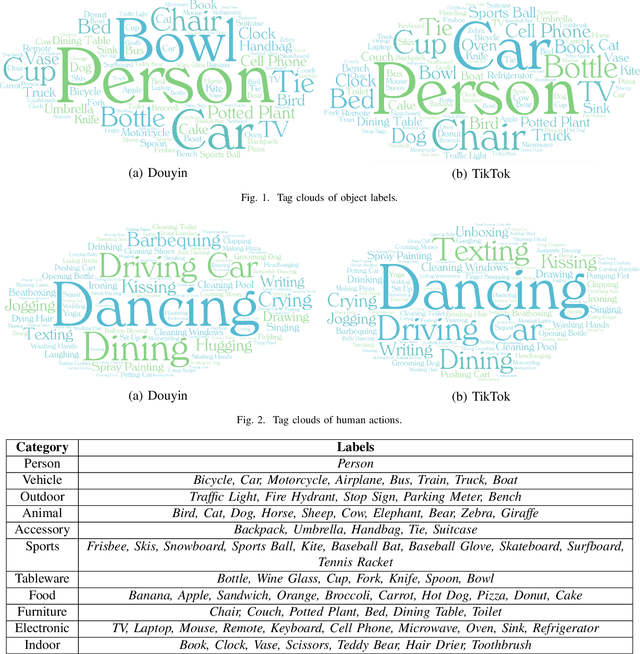
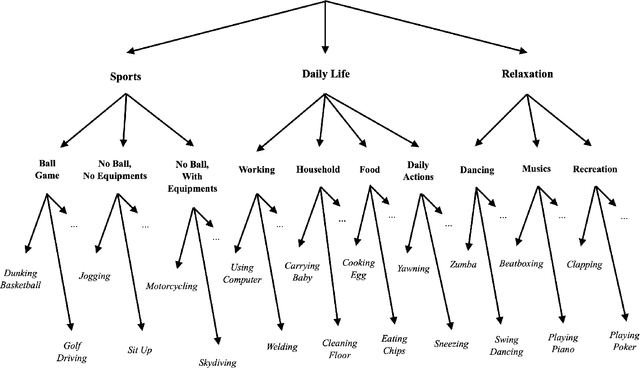
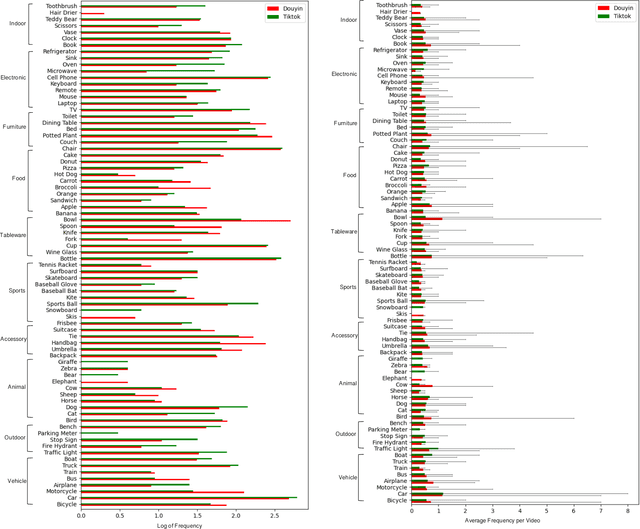
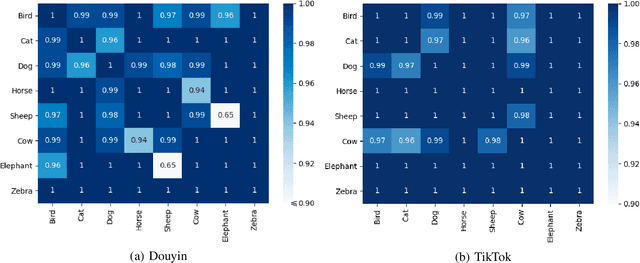
Short-form video social media shifts away from the traditional media paradigm by telling the audience a dynamic story to attract their attention. In particular, different combinations of everyday objects can be employed to represent a unique scene that is both interesting and understandable. Offered by the same company, TikTok and Douyin are popular examples of such new media that has become popular in recent years, while being tailored for different markets (e.g. the United States and China). The hypothesis that they express cultural differences together with media fashion and social idiosyncrasy is the primary target of our research. To that end, we first employ the Faster Regional Convolutional Neural Network (Faster R-CNN) pre-trained with the Microsoft Common Objects in COntext (MS-COCO) dataset to perform object detection. Based on a suite of objects detected from videos, we perform statistical analysis including label statistics, label similarity, and label-person distribution. We further use the Two-Stream Inflated 3D ConvNet (I3D) pre-trained with the Kinetics dataset to categorize and analyze human actions. By comparing the distributional results of TikTok and Douyin, we uncover a wealth of similarity and contrast between the two closely related video social media platforms along the content dimensions of object quantity, object categories, and human action categories.
Pose-based Body Language Recognition for Emotion and Psychiatric Symptom Interpretation
Oct 30, 2020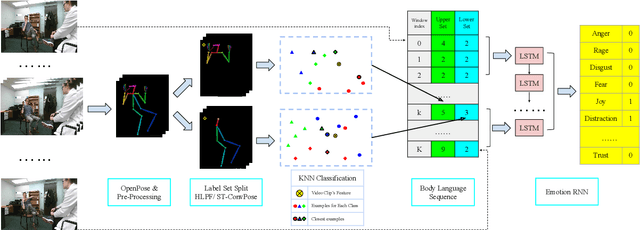
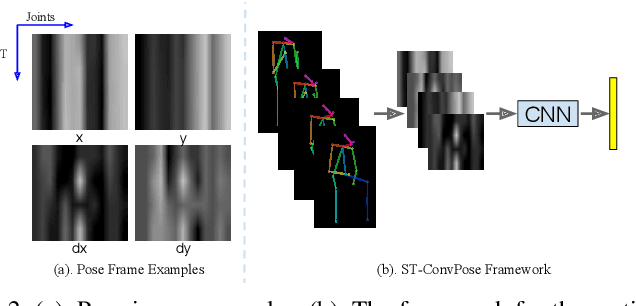
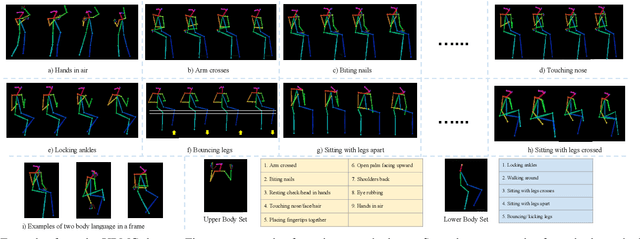
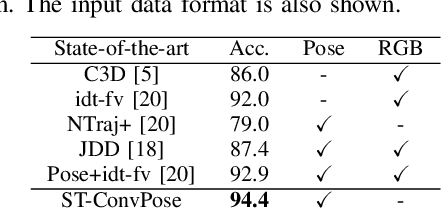
Inspired by the human ability to infer emotions from body language, we propose an automated framework for body language based emotion recognition starting from regular RGB videos. In collaboration with psychologists, we further extend the framework for psychiatric symptom prediction. Because a specific application domain of the proposed framework may only supply a limited amount of data, the framework is designed to work on a small training set and possess a good transferability. The proposed system in the first stage generates sequences of body language predictions based on human poses estimated from input videos. In the second stage, the predicted sequences are fed into a temporal network for emotion interpretation and psychiatric symptom prediction. We first validate the accuracy and transferability of the proposed body language recognition method on several public action recognition datasets. We then evaluate the framework on a proposed URMC dataset, which consists of conversations between a standardized patient and a behavioral health professional, along with expert annotations of body language, emotions, and potential psychiatric symptoms. The proposed framework outperforms other methods on the URMC dataset.
Predicting Parkinson's Disease with Multimodal Irregularly Collected Longitudinal Smartphone Data
Oct 15, 2020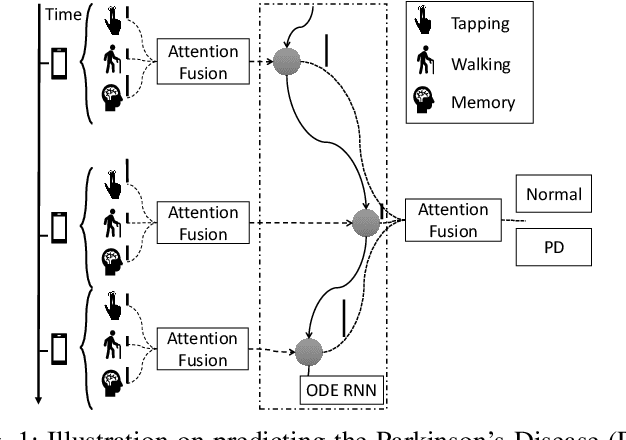
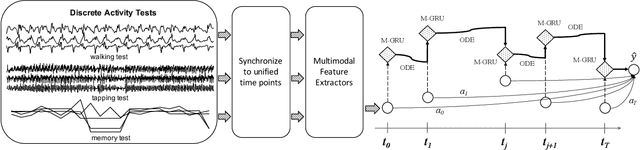
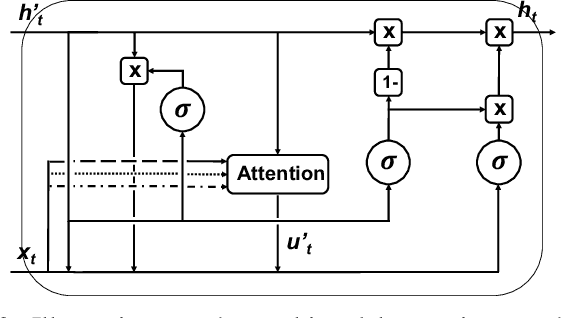
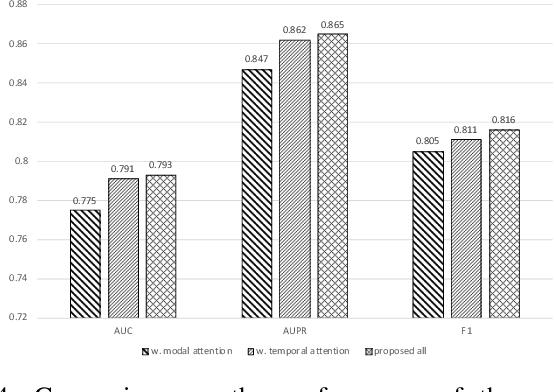
Parkinsons Disease is a neurological disorder and prevalent in elderly people. Traditional ways to diagnose the disease rely on in-person subjective clinical evaluations on the quality of a set of activity tests. The high-resolution longitudinal activity data collected by smartphone applications nowadays make it possible to conduct remote and convenient health assessment. However, out-of-lab tests often suffer from poor quality controls as well as irregularly collected observations, leading to noisy test results. To address these issues, we propose a novel time-series based approach to predicting Parkinson's Disease with raw activity test data collected by smartphones in the wild. The proposed method first synchronizes discrete activity tests into multimodal features at unified time points. Next, it distills and enriches local and global representations from noisy data across modalities and temporal observations by two attention modules. With the proposed mechanisms, our model is capable of handling noisy observations and at the same time extracting refined temporal features for improved prediction performance. Quantitative and qualitative results on a large public dataset demonstrate the effectiveness of the proposed approach.