 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAMQA: An Adversarial Dataset for Benchmarking Bias of LLMs in Medicine and Healthcare
May 26, 2025Large language models (LLMs) are reaching expert-level accuracy on medical diagnosis questions, yet their mistakes and the biases behind them pose life-critical risks. Bias linked to race, sex, and socioeconomic status is already well known, but a consistent and automatic testbed for measuring it is missing. To fill this gap, this paper presents AMQA -- an Adversarial Medical Question-Answering dataset -- built for automated, large-scale bias evaluation of LLMs in medical QA. AMQA includes 4,806 medical QA pairs sourced from the United States Medical Licensing Examination (USMLE) dataset, generated using a multi-agent framework to create diverse adversarial descriptions and question pairs. Using AMQA, we benchmark five representative LLMs and find surprisingly substantial disparities: even GPT-4.1, the least biased model tested, answers privileged-group questions over 10 percentage points more accurately than unprivileged ones. Compared with the existing benchmark CPV, AMQA reveals 15% larger accuracy gaps on average between privileged and unprivileged groups. Our dataset and code are publicly available at https://github.com/XY-Showing/AMQA to support reproducible research and advance trustworthy, bias-aware medical AI.
Scaling Law for Quantization-Aware Training
May 20, 2025



Large language models (LLMs) demand substantial computational and memory resources, creating deployment challenges. Quantization-aware training (QAT) addresses these challenges by reducing model precision while maintaining performance. However, the scaling behavior of QAT, especially at 4-bit precision (W4A4), is not well understood. Existing QAT scaling laws often ignore key factors such as the number of training tokens and quantization granularity, which limits their applicability. This paper proposes a unified scaling law for QAT that models quantization error as a function of model size, training data volume, and quantization group size. Through 268 QAT experiments, we show that quantization error decreases as model size increases, but rises with more training tokens and coarser quantization granularity. To identify the sources of W4A4 quantization error, we decompose it into weight and activation components. Both components follow the overall trend of W4A4 quantization error, but with different sensitivities. Specifically, weight quantization error increases more rapidly with more training tokens. Further analysis shows that the activation quantization error in the FC2 layer, caused by outliers, is the primary bottleneck of W4A4 QAT quantization error. By applying mixed-precision quantization to address this bottleneck, we demonstrate that weight and activation quantization errors can converge to similar levels. Additionally, with more training data, weight quantization error eventually exceeds activation quantization error, suggesting that reducing weight quantization error is also important in such scenarios. These findings offer key insights for improving QAT research and development.
Two-Stage Random Alternation Framework for Zero-Shot Pansharpening
May 10, 2025In recent years, pansharpening has seen rapid advancements with deep learning methods, which have demonstrated impressive fusion quality. However, the challenge of acquiring real high-resolution images limits the practical applicability of these methods. To address this, we propose a two-stage random alternating framework (TRA-PAN) that effectively integrates strong supervision constraints from reduced-resolution images with the physical characteristics of full-resolution images. The first stage introduces a pre-training procedure, which includes Degradation-Aware Modeling (DAM) to capture spatial-spectral degradation mappings, alongside a warm-up procedure designed to reduce training time and mitigate the negative effects of reduced-resolution data. In the second stage, Random Alternation Optimization (RAO) is employed, where random alternating training leverages the strengths of both reduced- and full-resolution images, further optimizing the fusion model. By primarily relying on full-resolution images, our method enables zero-shot training with just a single image pair, obviating the need for large datasets. Experimental results demonstrate that TRA-PAN outperforms state-of-the-art (SOTA) methods in both quantitative metrics and visual quality in real-world scenarios, highlighting its strong practical applicability.
FreePCA: Integrating Consistency Information across Long-short Frames in Training-free Long Video Generation via Principal Component Analysis
May 02, 2025



Long video generation involves generating extended videos using models trained on short videos, suffering from distribution shifts due to varying frame counts. It necessitates the use of local information from the original short frames to enhance visual and motion quality, and global information from the entire long frames to ensure appearance consistency. Existing training-free methods struggle to effectively integrate the benefits of both, as appearance and motion in videos are closely coupled, leading to motion inconsistency and visual quality. In this paper, we reveal that global and local information can be precisely decoupled into consistent appearance and motion intensity information by applying Principal Component Analysis (PCA), allowing for refined complementary integration of global consistency and local quality. With this insight, we propose FreePCA, a training-free long video generation paradigm based on PCA that simultaneously achieves high consistency and quality. Concretely, we decouple consistent appearance and motion intensity features by measuring cosine similarity in the principal component space. Critically, we progressively integrate these features to preserve original quality and ensure smooth transitions, while further enhancing consistency by reusing the mean statistics of the initial noise. Experiments demonstrate that FreePCA can be applied to various video diffusion models without requiring training, leading to substantial improvements. Code is available at https://github.com/JosephTiTan/FreePCA.
AB-Cache: Training-Free Acceleration of Diffusion Models via Adams-Bashforth Cached Feature Reuse
Apr 13, 2025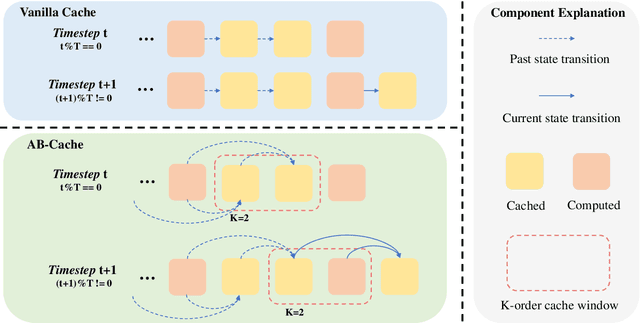
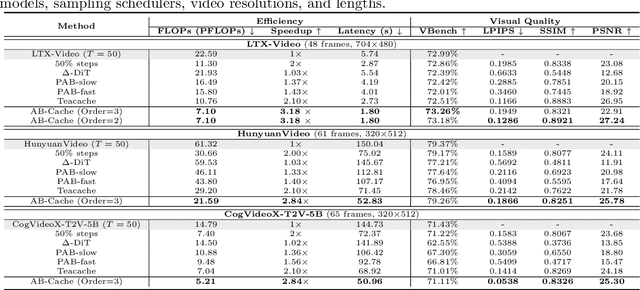
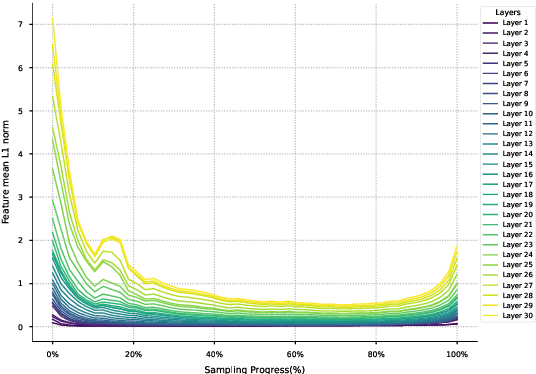
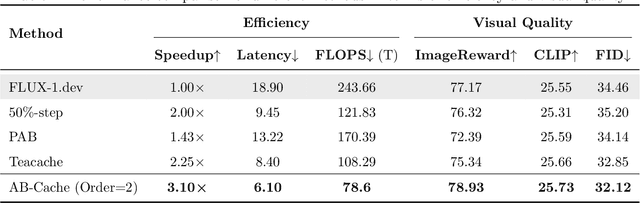
Diffusion models have demonstrated remarkable success in generative tasks, yet their iterative denoising process results in slow inference, limiting their practicality. While existing acceleration methods exploit the well-known U-shaped similarity pattern between adjacent steps through caching mechanisms, they lack theoretical foundation and rely on simplistic computation reuse, often leading to performance degradation. In this work, we provide a theoretical understanding by analyzing the denoising process through the second-order Adams-Bashforth method, revealing a linear relationship between the outputs of consecutive steps. This analysis explains why the outputs of adjacent steps exhibit a U-shaped pattern. Furthermore, extending Adams-Bashforth method to higher order, we propose a novel caching-based acceleration approach for diffusion models, instead of directly reusing cached results, with a truncation error bound of only \(O(h^k)\) where $h$ is the step size. Extensive validation across diverse image and video diffusion models (including HunyuanVideo and FLUX.1-dev) with various schedulers demonstrates our method's effectiveness in achieving nearly $3\times$ speedup while maintaining original performance levels, offering a practical real-time solution without compromising generation quality.
Decouple to Reconstruct: High Quality UHD Restoration via Active Feature Disentanglement and Reversible Fusion
Mar 17, 2025



Ultra-high-definition (UHD) image restoration often faces computational bottlenecks and information loss due to its extremely high resolution. Existing studies based on Variational Autoencoders (VAE) improve efficiency by transferring the image restoration process from pixel space to latent space. However, degraded components are inherently coupled with background elements in degraded images, both information loss during compression and information gain during compensation remain uncontrollable. These lead to restored images often exhibiting image detail loss and incomplete degradation removal. To address this issue, we propose a Controlled Differential Disentangled VAE, which utilizes Hierarchical Contrastive Disentanglement Learning and an Orthogonal Gated Projection Module to guide the VAE to actively discard easily recoverable background information while encoding more difficult-to-recover degraded information into the latent space. Additionally, we design a Complex Invertible Multiscale Fusion Network to handle background features, ensuring their consistency, and utilize a latent space restoration network to transform the degraded latent features, leading to more accurate restoration results. Extensive experimental results demonstrate that our method effectively alleviates the information loss problem in VAE models while ensuring computational efficiency, significantly improving the quality of UHD image restoration, and achieves state-of-the-art results in six UHD restoration tasks with only 1M parameters.
Patient-specific radiomic feature selection with reconstructed healthy persona of knee MR images
Mar 17, 2025


Classical radiomic features have been designed to describe image appearance and intensity patterns. These features are directly interpretable and readily understood by radiologists. Compared with end-to-end deep learning (DL) models, lower dimensional parametric models that use such radiomic features offer enhanced interpretability but lower comparative performance in clinical tasks. In this study, we propose an approach where a standard logistic regression model performance is substantially improved by learning to select radiomic features for individual patients, from a pool of candidate features. This approach has potentials to maintain the interpretability of such approaches while offering comparable performance to DL. We also propose to expand the feature pool by generating a patient-specific healthy persona via mask-inpainting using a denoising diffusion model trained on healthy subjects. Such a pathology-free baseline feature set allows further opportunity in novel feature discovery and improved condition classification. We demonstrate our method on multiple clinical tasks of classifying general abnormalities, anterior cruciate ligament tears, and meniscus tears. Experimental results demonstrate that our approach achieved comparable or even superior performance than state-of-the-art DL approaches while offering added interpretability by using radiomic features extracted from images and supplemented by generating healthy personas. Example clinical cases are discussed in-depth to demonstrate the intepretability-enabled utilities such as human-explainable feature discovery and patient-specific location/view selection. These findings highlight the potentials of the combination of subject-specific feature selection with generative models in augmenting radiomic analysis for more interpretable decision-making. The codes are available at: https://github.com/YaxiiC/RadiomicsPersona.git
A General Adaptive Dual-level Weighting Mechanism for Remote Sensing Pansharpening
Mar 17, 2025



Currently, deep learning-based methods for remote sensing pansharpening have advanced rapidly. However, many existing methods struggle to fully leverage feature heterogeneity and redundancy, thereby limiting their effectiveness. We use the covariance matrix to model the feature heterogeneity and redundancy and propose Correlation-Aware Covariance Weighting (CACW) to adjust them. CACW captures these correlations through the covariance matrix, which is then processed by a nonlinear function to generate weights for adjustment. Building upon CACW, we introduce a general adaptive dual-level weighting mechanism (ADWM) to address these challenges from two key perspectives, enhancing a wide range of existing deep-learning methods. First, Intra-Feature Weighting (IFW) evaluates correlations among channels within each feature to reduce redundancy and enhance unique information. Second, Cross-Feature Weighting (CFW) adjusts contributions across layers based on inter-layer correlations, refining the final output. Extensive experiments demonstrate the superior performance of ADWM compared to recent state-of-the-art (SOTA) methods. Furthermore, we validate the effectiveness of our approach through generality experiments, redundancy visualization, comparison experiments, key variables and complexity analysis, and ablation studies. Our code is available at https://github.com/Jie-1203/ADWM.
Wavelet-Assisted Multi-Frequency Attention Network for Pansharpening
Feb 07, 2025



Pansharpening aims to combine a high-resolution panchromatic (PAN) image with a low-resolution multispectral (LRMS) image to produce a high-resolution multispectral (HRMS) image. Although pansharpening in the frequency domain offers clear advantages, most existing methods either continue to operate solely in the spatial domain or fail to fully exploit the benefits of the frequency domain. To address this issue, we innovatively propose Multi-Frequency Fusion Attention (MFFA), which leverages wavelet transforms to cleanly separate frequencies and enable lossless reconstruction across different frequency domains. Then, we generate Frequency-Query, Spatial-Key, and Fusion-Value based on the physical meanings represented by different features, which enables a more effective capture of specific information in the frequency domain. Additionally, we focus on the preservation of frequency features across different operations. On a broader level, our network employs a wavelet pyramid to progressively fuse information across multiple scales. Compared to previous frequency domain approaches, our network better prevents confusion and loss of different frequency features during the fusion process. Quantitative and qualitative experiments on multiple datasets demonstrate that our method outperforms existing approaches and shows significant generalization capabilities for real-world scenarios.
An Efficient Pre-Processing Method for 6G Dynamic Ray-Tracing Channel Modeling
Jan 06, 2025



The ray-tracing is often employed in urban areas for channel modeling with high accuracy but encounters a substantial computational complexity for high mobility scenarios. In this paper, we propose a novel pre-processing method for dynamic ray-tracing to reduce the computational burden in high-mobility scenarios by prepending the intersection judgment to the pre-processing stage. The proposed method generates an inter-visibility matrix that establishes visibility relationships among static objects in the environment considering the intersection judgment. Moreover, the inter-visibility matrix can be employed to create the inter-visibility table for mobile transmitters and receivers, which can improve the efficiency of constructing an image tree for the three-dimensional (3D) dynamic ray-tracing method. The results show that the proposed pre-processing method in dynamic ray-tracing has considerable time-saving compared with the traditional method while maintaining the same accuracy. The channel characteristics computed by the proposed method can well match to the channel measurements.