 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Native Multimodal Modeling: A Roadmap
May 25, 2026Multimodal modeling represents a vital step from modality-agnostic reasoning toward world modeling. While early approaches predominantly rely on late-fusion that assembles encoders and frozen language backbones with output heads, recent efforts have shifted the paradigm toward native multimodal modeling (NMM) with the intrinsic integration of modalities for superior multimodal performance. Despite its potential, the design space of native architectures remains insufficiently defined. In this paper, we present the community with a formalized roadmap for this transition. Specifically, we formally define the architectural nativity, distinguishing mid-fusion and early-fusion from non-native paradigms. We further organize the existing native models through the lens of input-output duality into three categories: (i) Multi-to-Text for cross-modal comprehension with text-only output; (ii) Multi-to-Target for scenario-oriented generation, e.g., image, audio and video generation, and (iii) Multi-to-Multi for unified modeling with symmetric input-output. We deliver a comprehensive and industrial-grade investigation into the transition toward the definitive NMM framework, where understanding and generation seamlessly coexist within a unified transformer paradigm. We systematically unpack the end-to-end pipeline from industrial perspectives from architectural coordination, massive data curation, to full-stack training recipes, inference & deployment, and the comprehensive evaluation for truly native modeling.
Relative Score Policy Optimization for Diffusion Language Models
May 11, 2026Diffusion large language models (dLLMs) offer a promising route to parallel and efficient text generation, but improving their reasoning ability requires effective post-training. Reinforcement learning with verifiable rewards (RLVR) is a natural choice for this purpose, yet its application to dLLMs is hindered by the absence of tractable sequence-level log-ratios, which are central to standard policy optimization. The lack of tractable sequence-level log-ratios forces existing methods to rely on high-variance ELBO-based approximations, where high verifier rewards can amplify inaccurate score estimates and destabilize RL training. To overcome this issue, we propose \textbf{R}elative \textbf{S}core \textbf{P}olicy \textbf{O}ptimization (RSPO), a simple RLVR method that uses verifiable rewards to calibrate noisy likelihood estimates in dLLMs. The core of our algorithm relies on a key observation: a reward advantage can be interpreted not only as an update direction, but also as a target for the relative log-ratio between the current and reference policies. Accordingly, RSPO calibrates this noisy relative log-ratio estimate by comparing its reward advantage with the reward-implied target relative log-ratio, updating the policy according to the gap between the current estimate and the target rather than the raw advantage alone. Experiments on mathematical reasoning and planning benchmarks show that RSPO yields especially strong gains on planning tasks and competitive mathematical-reasoning performance.
ProFlow: Zero-Shot Physics-Consistent Sampling via Proximal Flow Guidance
Jan 28, 2026Inferring physical fields from sparse observations while strictly satisfying partial differential equations (PDEs) is a fundamental challenge in computational physics. Recently, deep generative models offer powerful data-driven priors for such inverse problems, yet existing methods struggle to enforce hard physical constraints without costly retraining or disrupting the learned generative prior. Consequently, there is a critical need for a sampling mechanism that can reconcile strict physical consistency and observational fidelity with the statistical structure of the pre-trained prior. To this end, we present ProFlow, a proximal guidance framework for zero-shot physics-consistent sampling, defined as inferring solutions from sparse observations using a fixed generative prior without task-specific retraining. The algorithm employs a rigorous two-step scheme that alternates between: (\romannumeral1) a terminal optimization step, which projects the flow prediction onto the intersection of the physically and observationally consistent sets via proximal minimization; and (\romannumeral2) an interpolation step, which maps the refined state back to the generative trajectory to maintain consistency with the learned flow probability path. This procedure admits a Bayesian interpretation as a sequence of local maximum a posteriori (MAP) updates. Comprehensive benchmarks on Poisson, Helmholtz, Darcy, and viscous Burgers' equations demonstrate that ProFlow achieves superior physical and observational consistency, as well as more accurate distributional statistics, compared to state-of-the-art diffusion- and flow-based baselines.
Fast-ARDiff: An Entropy-informed Acceleration Framework for Continuous Space Autoregressive Generation
Dec 09, 2025



Autoregressive(AR)-diffusion hybrid paradigms combine AR's structured modeling with diffusion's photorealistic synthesis, yet suffer from high latency due to sequential AR generation and iterative denoising. In this work, we tackle this bottleneck and propose a unified AR-diffusion framework Fast-ARDiff that jointly optimizes both components, accelerating AR speculative decoding while simultaneously facilitating faster diffusion decoding. Specifically: (1) The entropy-informed speculative strategy encourages draft model to produce higher-entropy representations aligned with target model's entropy characteristics, mitigating entropy mismatch and high rejection rates caused by draft overconfidence. (2) For diffusion decoding, rather than treating it as an independent module, we integrate it into the same end-to-end framework using a dynamic scheduler that prioritizes AR optimization to guide the diffusion part in further steps. The diffusion part is optimized through a joint distillation framework combining trajectory and distribution matching, ensuring stable training and high-quality synthesis with extremely few steps. During inference, shallow feature entropy from AR module is used to pre-filter low-entropy drafts, avoiding redundant computation and improving latency. Fast-ARDiff achieves state-of-the-art acceleration across diverse models: on ImageNet 256$\times$256, TransDiff attains 4.3$\times$ lossless speedup, and NextStep-1 achieves 3$\times$ acceleration on text-conditioned generation. Code will be available at https://github.com/aSleepyTree/Fast-ARDiff.
AB-Cache: Training-Free Acceleration of Diffusion Models via Adams-Bashforth Cached Feature Reuse
Apr 13, 2025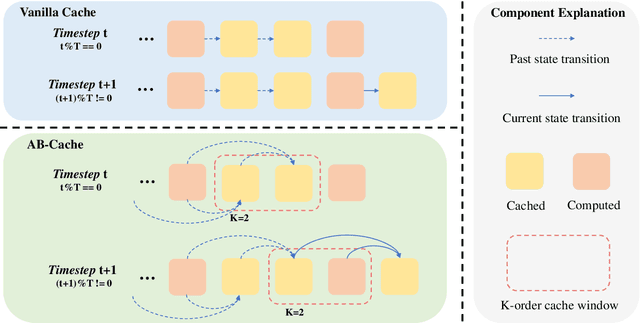
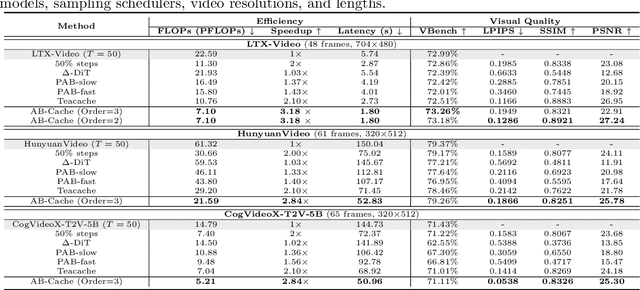
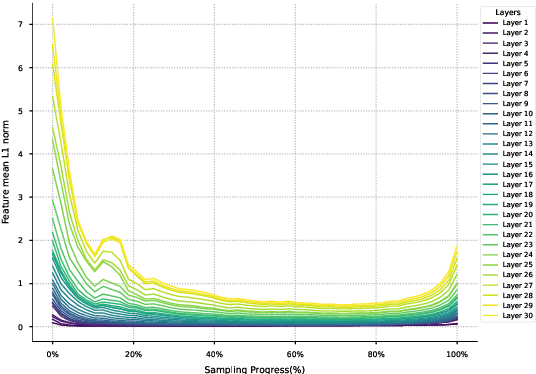
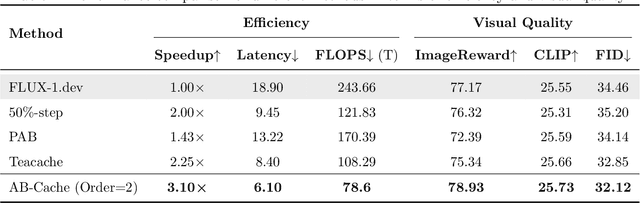
Diffusion models have demonstrated remarkable success in generative tasks, yet their iterative denoising process results in slow inference, limiting their practicality. While existing acceleration methods exploit the well-known U-shaped similarity pattern between adjacent steps through caching mechanisms, they lack theoretical foundation and rely on simplistic computation reuse, often leading to performance degradation. In this work, we provide a theoretical understanding by analyzing the denoising process through the second-order Adams-Bashforth method, revealing a linear relationship between the outputs of consecutive steps. This analysis explains why the outputs of adjacent steps exhibit a U-shaped pattern. Furthermore, extending Adams-Bashforth method to higher order, we propose a novel caching-based acceleration approach for diffusion models, instead of directly reusing cached results, with a truncation error bound of only \(O(h^k)\) where $h$ is the step size. Extensive validation across diverse image and video diffusion models (including HunyuanVideo and FLUX.1-dev) with various schedulers demonstrates our method's effectiveness in achieving nearly $3\times$ speedup while maintaining original performance levels, offering a practical real-time solution without compromising generation quality.
Infinite Mobility: Scalable High-Fidelity Synthesis of Articulated Objects via Procedural Generation
Mar 17, 2025Large-scale articulated objects with high quality are desperately needed for multiple tasks related to embodied AI. Most existing methods for creating articulated objects are either data-driven or simulation based, which are limited by the scale and quality of the training data or the fidelity and heavy labour of the simulation. In this paper, we propose Infinite Mobility, a novel method for synthesizing high-fidelity articulated objects through procedural generation. User study and quantitative evaluation demonstrate that our method can produce results that excel current state-of-the-art methods and are comparable to human-annotated datasets in both physics property and mesh quality. Furthermore, we show that our synthetic data can be used as training data for generative models, enabling next-step scaling up. Code is available at https://github.com/Intern-Nexus/Infinite-Mobility