 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMSVIT: Improving Spiking Vision Transformer Using Multi-scale Attention Fusion
May 19, 2025The combination of Spiking Neural Networks(SNNs) with Vision Transformer architectures has attracted significant attention due to the great potential for energy-efficient and high-performance computing paradigms. However, a substantial performance gap still exists between SNN-based and ANN-based transformer architectures. While existing methods propose spiking self-attention mechanisms that are successfully combined with SNNs, the overall architectures proposed by these methods suffer from a bottleneck in effectively extracting features from different image scales. In this paper, we address this issue and propose MSVIT, a novel spike-driven Transformer architecture, which firstly uses multi-scale spiking attention (MSSA) to enrich the capability of spiking attention blocks. We validate our approach across various main data sets. The experimental results show that MSVIT outperforms existing SNN-based models, positioning itself as a state-of-the-art solution among SNN-transformer architectures. The codes are available at https://github.com/Nanhu-AI-Lab/MSViT.
Decoding finger velocity from cortical spike trains with recurrent spiking neural networks
Sep 03, 2024



Invasive cortical brain-machine interfaces (BMIs) can significantly improve the life quality of motor-impaired patients. Nonetheless, externally mounted pedestals pose an infection risk, which calls for fully implanted systems. Such systems, however, must meet strict latency and energy constraints while providing reliable decoding performance. While recurrent spiking neural networks (RSNNs) are ideally suited for ultra-low-power, low-latency processing on neuromorphic hardware, it is unclear whether they meet the above requirements. To address this question, we trained RSNNs to decode finger velocity from cortical spike trains (CSTs) of two macaque monkeys. First, we found that a large RSNN model outperformed existing feedforward spiking neural networks (SNNs) and artificial neural networks (ANNs) in terms of their decoding accuracy. We next developed a tiny RSNN with a smaller memory footprint, low firing rates, and sparse connectivity. Despite its reduced computational requirements, the resulting model performed substantially better than existing SNN and ANN decoders. Our results thus demonstrate that RSNNs offer competitive CST decoding performance under tight resource constraints and are promising candidates for fully implanted ultra-low-power BMIs with the potential to revolutionize patient care.
Towards Open-World Mobile Manipulation in Homes: Lessons from the Neurips 2023 HomeRobot Open Vocabulary Mobile Manipulation Challenge
Jul 09, 2024



In order to develop robots that can effectively serve as versatile and capable home assistants, it is crucial for them to reliably perceive and interact with a wide variety of objects across diverse environments. To this end, we proposed Open Vocabulary Mobile Manipulation as a key benchmark task for robotics: finding any object in a novel environment and placing it on any receptacle surface within that environment. We organized a NeurIPS 2023 competition featuring both simulation and real-world components to evaluate solutions to this task. Our baselines on the most challenging version of this task, using real perception in simulation, achieved only an 0.8% success rate; by the end of the competition, the best participants achieved an 10.8\% success rate, a 13x improvement. We observed that the most successful teams employed a variety of methods, yet two common threads emerged among the best solutions: enhancing error detection and recovery, and improving the integration of perception with decision-making processes. In this paper, we detail the results and methodologies used, both in simulation and real-world settings. We discuss the lessons learned and their implications for future research. Additionally, we compare performance in real and simulated environments, emphasizing the necessity for robust generalization to novel settings.
Spiking Structured State Space Model for Monaural Speech Enhancement
Sep 07, 2023Speech enhancement seeks to extract clean speech from noisy signals. Traditional deep learning methods face two challenges: efficiently using information in long speech sequences and high computational costs. To address these, we introduce the Spiking Structured State Space Model (Spiking-S4). This approach merges the energy efficiency of Spiking Neural Networks (SNN) with the long-range sequence modeling capabilities of Structured State Space Models (S4), offering a compelling solution. Evaluation on the DNS Challenge and VoiceBank+Demand Datasets confirms that Spiking-S4 rivals existing Artificial Neural Network (ANN) methods but with fewer computational resources, as evidenced by reduced parameters and Floating Point Operations (FLOPs).
Emergent Bio-Functional Similarities in a Cortical-Spike-Train-Decoding Spiking Neural Network Facilitate Predictions of Neural Computation
Mar 14, 2023



Despite its better bio-plausibility, goal-driven spiking neural network (SNN) has not achieved applicable performance for classifying biological spike trains, and showed little bio-functional similarities compared to traditional artificial neural networks. In this study, we proposed the motorSRNN, a recurrent SNN topologically inspired by the neural motor circuit of primates. By employing the motorSRNN in decoding spike trains from the primary motor cortex of monkeys, we achieved a good balance between classification accuracy and energy consumption. The motorSRNN communicated with the input by capturing and cultivating more cosine-tuning, an essential property of neurons in the motor cortex, and maintained its stability during training. Such training-induced cultivation and persistency of cosine-tuning was also observed in our monkeys. Moreover, the motorSRNN produced additional bio-functional similarities at the single-neuron, population, and circuit levels, demonstrating biological authenticity. Thereby, ablation studies on motorSRNN have suggested long-term stable feedback synapses contribute to the training-induced cultivation in the motor cortex. Besides these novel findings and predictions, we offer a new framework for building authentic models of neural computation.
Adaptive Axonal Delays in feedforward spiking neural networks for accurate spoken word recognition
Feb 16, 2023



Spiking neural networks (SNN) are a promising research avenue for building accurate and efficient automatic speech recognition systems. Recent advances in audio-to-spike encoding and training algorithms enable SNN to be applied in practical tasks. Biologically-inspired SNN communicates using sparse asynchronous events. Therefore, spike-timing is critical to SNN performance. In this aspect, most works focus on training synaptic weights and few have considered delays in event transmission, namely axonal delay. In this work, we consider a learnable axonal delay capped at a maximum value, which can be adapted according to the axonal delay distribution in each network layer. We show that our proposed method achieves the best classification results reported on the SHD dataset (92.45%) and NTIDIGITS dataset (95.09%). Our work illustrates the potential of training axonal delays for tasks with complex temporal structures.
Training Spiking Neural Networks with Local Tandem Learning
Oct 10, 2022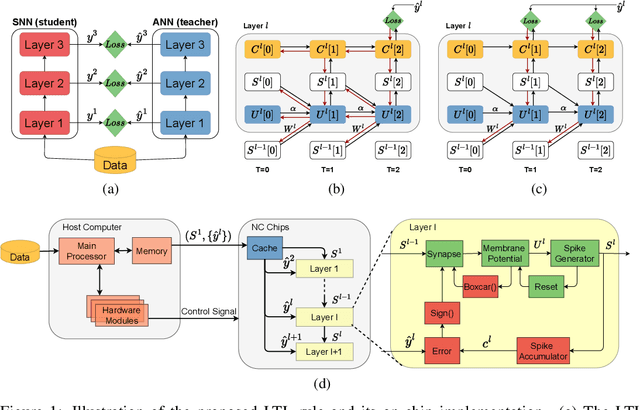
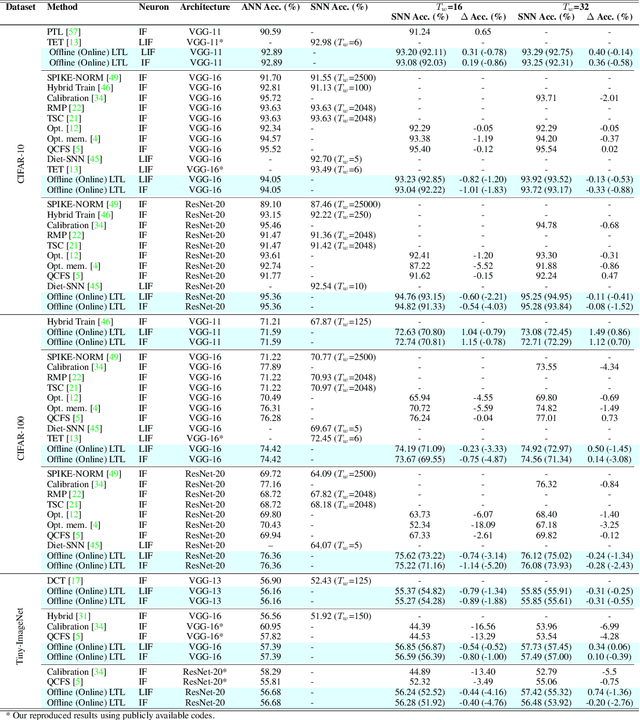
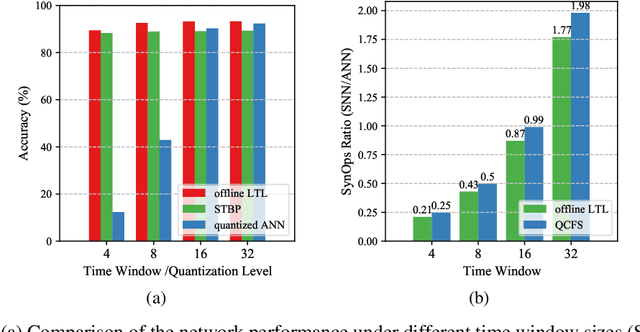
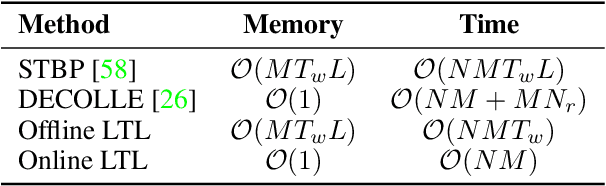
Spiking neural networks (SNNs) are shown to be more biologically plausible and energy efficient over their predecessors. However, there is a lack of an efficient and generalized training method for deep SNNs, especially for deployment on analog computing substrates. In this paper, we put forward a generalized learning rule, termed Local Tandem Learning (LTL). The LTL rule follows the teacher-student learning approach by mimicking the intermediate feature representations of a pre-trained ANN. By decoupling the learning of network layers and leveraging highly informative supervisor signals, we demonstrate rapid network convergence within five training epochs on the CIFAR-10 dataset while having low computational complexity. Our experimental results have also shown that the SNNs thus trained can achieve comparable accuracies to their teacher ANNs on CIFAR-10, CIFAR-100, and Tiny ImageNet datasets. Moreover, the proposed LTL rule is hardware friendly. It can be easily implemented on-chip to perform fast parameter calibration and provide robustness against the notorious device non-ideality issues. It, therefore, opens up a myriad of opportunities for training and deployment of SNN on ultra-low-power mixed-signal neuromorphic computing chips.10
Gradient Mask: Lateral Inhibition Mechanism Improves Performance in Artificial Neural Networks
Aug 14, 2022

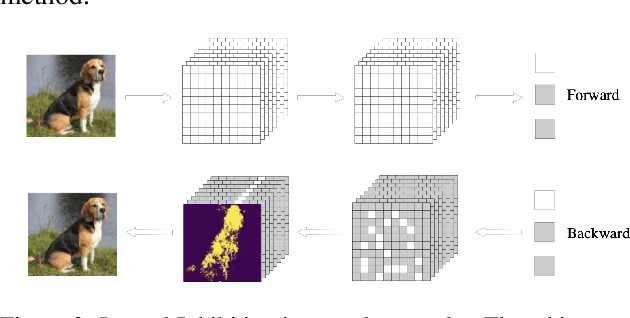

Lateral inhibitory connections have been observed in the cortex of the biological brain, and has been extensively studied in terms of its role in cognitive functions. However, in the vanilla version of backpropagation in deep learning, all gradients (which can be understood to comprise of both signal and noise gradients) flow through the network during weight updates. This may lead to overfitting. In this work, inspired by biological lateral inhibition, we propose Gradient Mask, which effectively filters out noise gradients in the process of backpropagation. This allows the learned feature information to be more intensively stored in the network while filtering out noisy or unimportant features. Furthermore, we demonstrate analytically how lateral inhibition in artificial neural networks improves the quality of propagated gradients. A new criterion for gradient quality is proposed which can be used as a measure during training of various convolutional neural networks (CNNs). Finally, we conduct several different experiments to study how Gradient Mask improves the performance of the network both quantitatively and qualitatively. Quantitatively, accuracy in the original CNN architecture, accuracy after pruning, and accuracy after adversarial attacks have shown improvements. Qualitatively, the CNN trained using Gradient Mask has developed saliency maps that focus primarily on the object of interest, which is useful for data augmentation and network interpretability.
SoftHebb: Bayesian inference in unsupervised Hebbian soft winner-take-all networks
Jul 12, 2021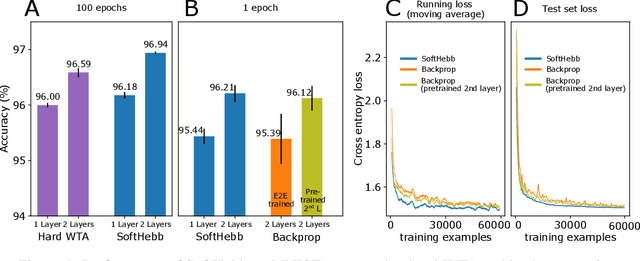
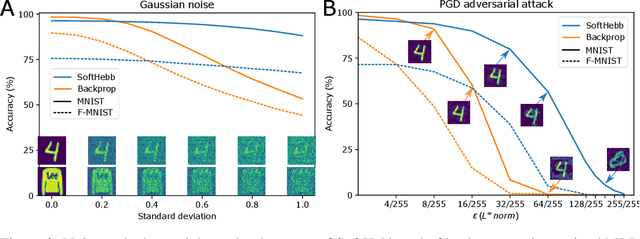
State-of-the-art artificial neural networks (ANNs) require labelled data or feedback between layers, are often biologically implausible, and are vulnerable to adversarial attacks that humans are not susceptible to. On the other hand, Hebbian learning in winner-take-all (WTA) networks, is unsupervised, feed-forward, and biologically plausible. However, an objective optimization theory for WTA networks has been missing, except under very limiting assumptions. Here we derive formally such a theory, based on biologically plausible but generic ANN elements. Through Hebbian learning, network parameters maintain a Bayesian generative model of the data. There is no supervisory loss function, but the network does minimize cross-entropy between its activations and the input distribution. The key is a "soft" WTA where there is no absolute "hard" winner neuron, and a specific type of Hebbian-like plasticity of weights and biases. We confirm our theory in practice, where, in handwritten digit (MNIST) recognition, our Hebbian algorithm, SoftHebb, minimizes cross-entropy without having access to it, and outperforms the more frequently used, hard-WTA-based method. Strikingly, it even outperforms supervised end-to-end backpropagation, under certain conditions. Specifically, in a two-layered network, SoftHebb outperforms backpropagation when the training dataset is only presented once, when the testing data is noisy, and under gradient-based adversarial attacks. Adversarial attacks that confuse SoftHebb are also confusing to the human eye. Finally, the model can generate interpolations of objects from its input distribution.
Spike-Timing-Dependent Back Propagation in Deep Spiking Neural Networks
Mar 26, 2020



The success of Deep Neural Networks (DNNs) can be attributed to its deep structure, that learns invariant feature representation at multiple levels of abstraction. Brain-inspired Spiking Neural Networks (SNNs) use spatiotemporal spike patterns to encode and transmit information, which is biologically realistic, and suitable for ultra-low-power event-driven neuromorphic implementation. Therefore, Deep Spiking Neural Networks (DSNNs) represent a promising direction in artificial intelligence, with the potential to benefit from the best of both worlds. However, the training of DSNNs is challenging because standard error back-propagation (BP) algorithms are not directly applicable. In this paper, we first establish an understanding of why error back-propagation does not work well in DSNNs. To address this problem, we propose a simple yet efficient Rectified Linear Postsynaptic Potential function (ReL-PSP) for spiking neurons and propose a Spike-Timing-Dependent Back-Propagation (STDBP) learning algorithm for DSNNs. In the proposed learning algorithm, the timing of individual spikes is used to carry information (temporal coding), and learning (back-propagation) is performed based on spike timing in an event-driven manner. Experimental results demonstrate that the proposed learning algorithm achieves state-of-the-art performance in spike time based learning algorithms of SNNs. This work investigates the contribution of dynamics in spike timing to information encoding, synaptic plasticity and decision making, providing a new perspective to design of future DSNNs.