 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCaSP: Class-agnostic Semi-Supervised Pretraining for Detection and Segmentation
Dec 09, 2021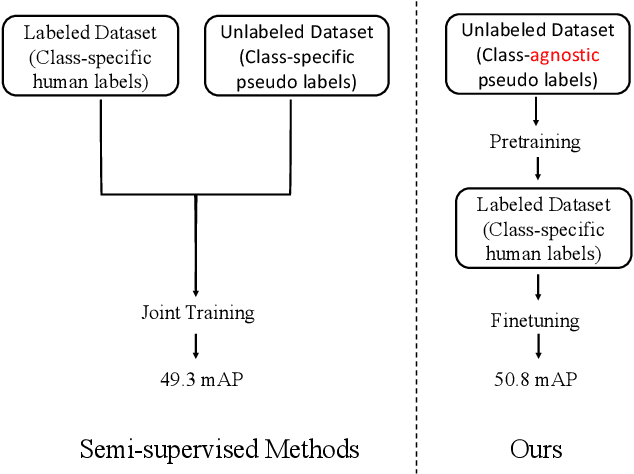
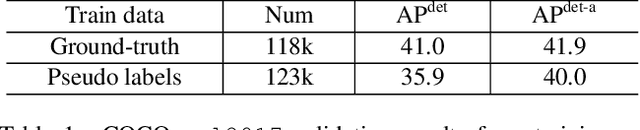
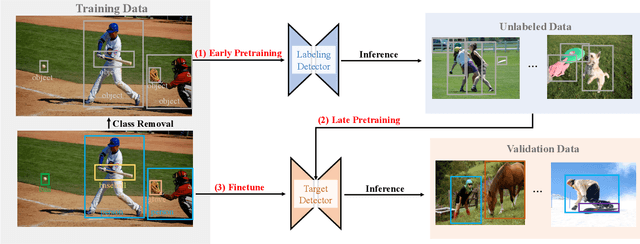
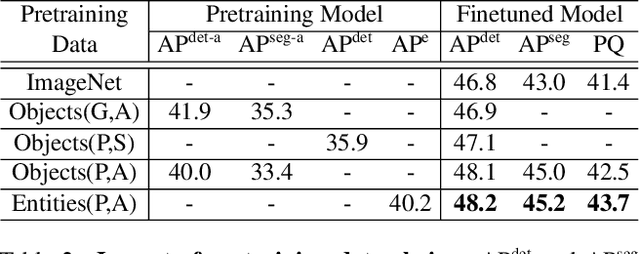
To improve instance-level detection/segmentation performance, existing self-supervised and semi-supervised methods extract either very task-unrelated or very task-specific training signals from unlabeled data. We argue that these two approaches, at the two extreme ends of the task-specificity spectrum, are suboptimal for the task performance. Utilizing too little task-specific training signals causes underfitting to the ground-truth labels of downstream tasks, while the opposite causes overfitting to the ground-truth labels. To this end, we propose a novel Class-agnostic Semi-supervised Pretraining (CaSP) framework to achieve a more favorable task-specificity balance in extracting training signals from unlabeled data. Compared to semi-supervised learning, CaSP reduces the task specificity in training signals by ignoring class information in the pseudo labels and having a separate pretraining stage that uses only task-unrelated unlabeled data. On the other hand, CaSP preserves the right amount of task specificity by leveraging box/mask-level pseudo labels. As a result, our pretrained model can better avoid underfitting/overfitting to ground-truth labels when finetuned on the downstream task. Using 3.6M unlabeled data, we achieve a remarkable performance gain of 4.7% over ImageNet-pretrained baseline on object detection. Our pretrained model also demonstrates excellent transferability to other detection and segmentation tasks/frameworks.
Blending Anti-Aliasing into Vision Transformer
Oct 28, 2021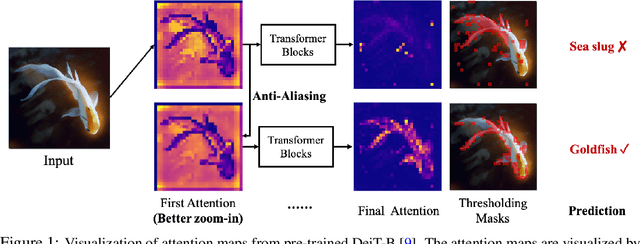
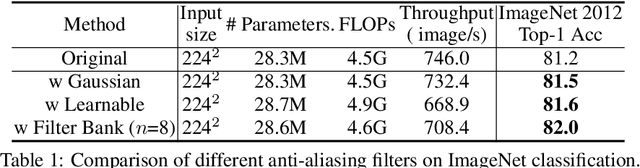

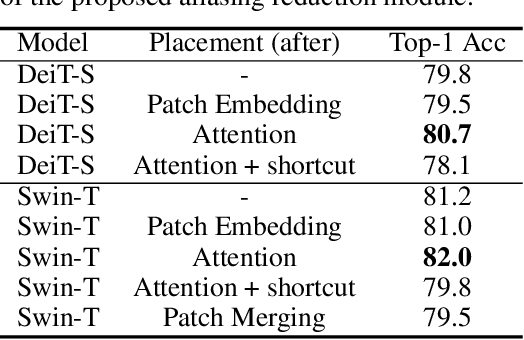
The transformer architectures, based on self-attention mechanism and convolution-free design, recently found superior performance and booming applications in computer vision. However, the discontinuous patch-wise tokenization process implicitly introduces jagged artifacts into attention maps, arising the traditional problem of aliasing for vision transformers. Aliasing effect occurs when discrete patterns are used to produce high frequency or continuous information, resulting in the indistinguishable distortions. Recent researches have found that modern convolution networks still suffer from this phenomenon. In this work, we analyze the uncharted problem of aliasing in vision transformer and explore to incorporate anti-aliasing properties. Specifically, we propose a plug-and-play Aliasing-Reduction Module(ARM) to alleviate the aforementioned issue. We investigate the effectiveness and generalization of the proposed method across multiple tasks and various vision transformer families. This lightweight design consistently attains a clear boost over several famous structures. Furthermore, our module also improves data efficiency and robustness of vision transformers.
Guided Point Contrastive Learning for Semi-supervised Point Cloud Semantic Segmentation
Oct 15, 2021
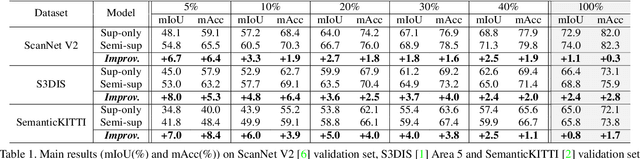
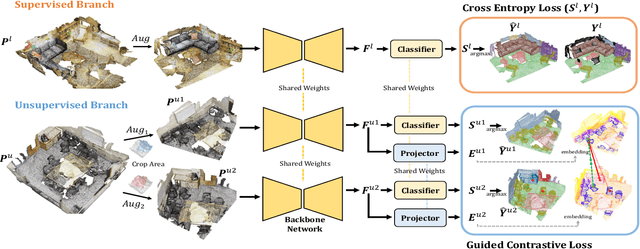
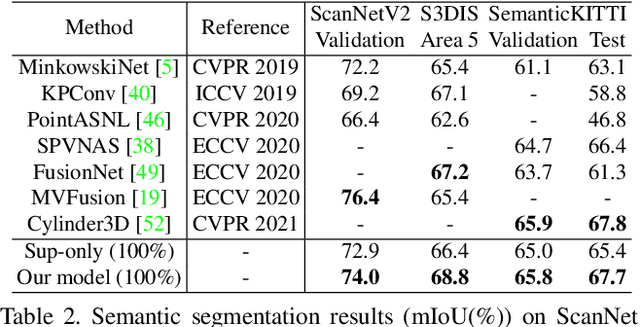
Rapid progress in 3D semantic segmentation is inseparable from the advances of deep network models, which highly rely on large-scale annotated data for training. To address the high cost and challenges of 3D point-level labeling, we present a method for semi-supervised point cloud semantic segmentation to adopt unlabeled point clouds in training to boost the model performance. Inspired by the recent contrastive loss in self-supervised tasks, we propose the guided point contrastive loss to enhance the feature representation and model generalization ability in semi-supervised setting. Semantic predictions on unlabeled point clouds serve as pseudo-label guidance in our loss to avoid negative pairs in the same category. Also, we design the confidence guidance to ensure high-quality feature learning. Besides, a category-balanced sampling strategy is proposed to collect positive and negative samples to mitigate the class imbalance problem. Extensive experiments on three datasets (ScanNet V2, S3DIS, and SemanticKITTI) show the effectiveness of our semi-supervised method to improve the prediction quality with unlabeled data.
PFENet++: Boosting Few-shot Semantic Segmentation with the Noise-filtered Context-aware Prior Mask
Sep 28, 2021
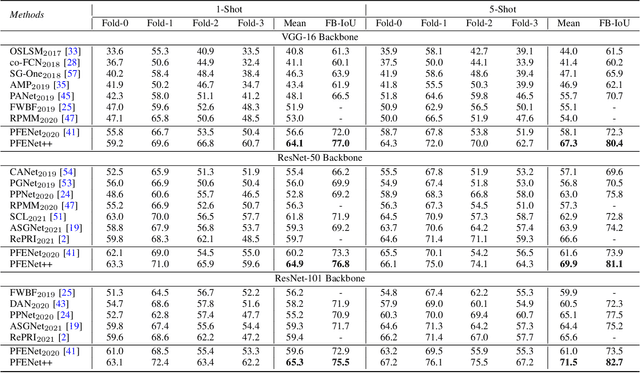
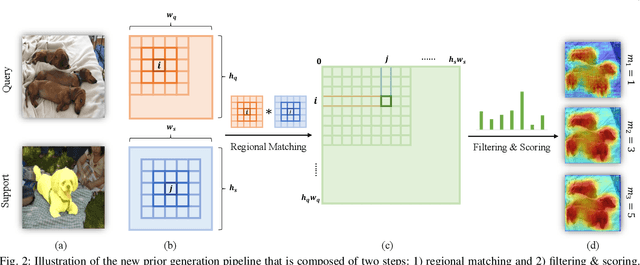
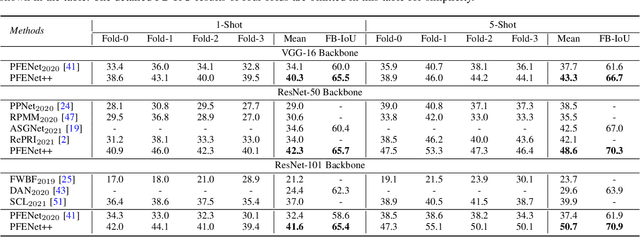
In this work, we revisit the prior mask guidance proposed in "Prior Guided Feature Enrichment Network for Few-Shot Segmentation". The prior mask serves as an indicator that highlights the region of interests of unseen categories, and it is effective in achieving better performance on different frameworks of recent studies. However, the current method directly takes the maximum element-to-element correspondence between the query and support features to indicate the probability of belonging to the target class, thus the broader contextual information is seldom exploited during the prior mask generation. To address this issue, first, we propose the Context-aware Prior Mask (CAPM) that leverages additional nearby semantic cues for better locating the objects in query images. Second, since the maximum correlation value is vulnerable to noisy features, we take one step further by incorporating a lightweight Noise Suppression Module (NSM) to screen out the unnecessary responses, yielding high-quality masks for providing the prior knowledge. Both two contributions are experimentally shown to have substantial practical merit, and the new model named PFENet++ significantly outperforms the baseline PFENet as well as all other competitors on three challenging benchmarks PASCAL-5$^i$, COCO-20$^i$ and FSS-1000. The new state-of-the-art performance is achieved without compromising the efficiency, manifesting the potential for being a new strong baseline in few-shot semantic segmentation. Our code will be available at https://github.com/dvlab-research/PFENet++.
Deep Structured Instance Graph for Distilling Object Detectors
Sep 27, 2021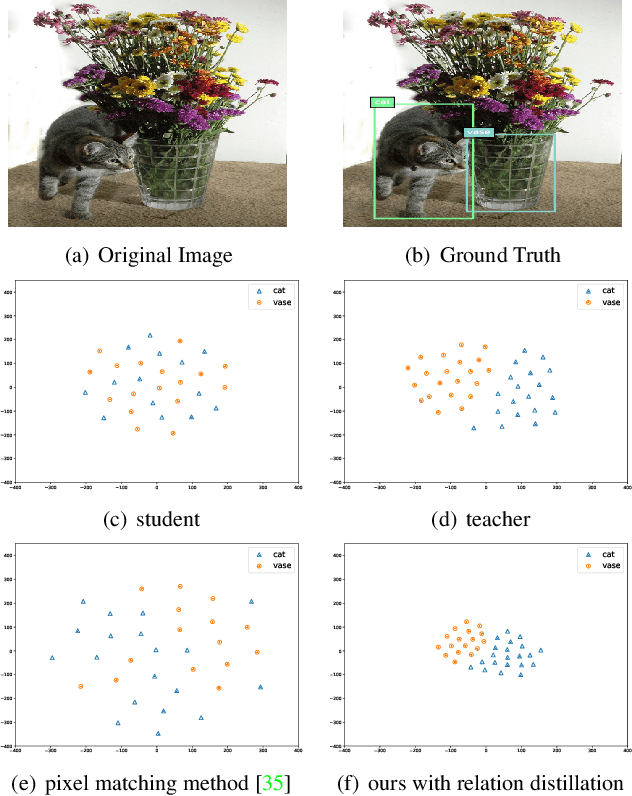
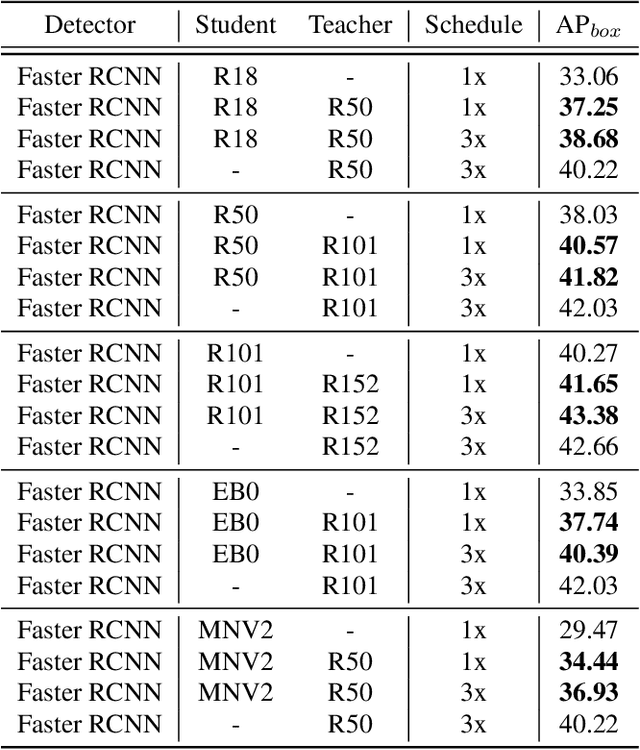

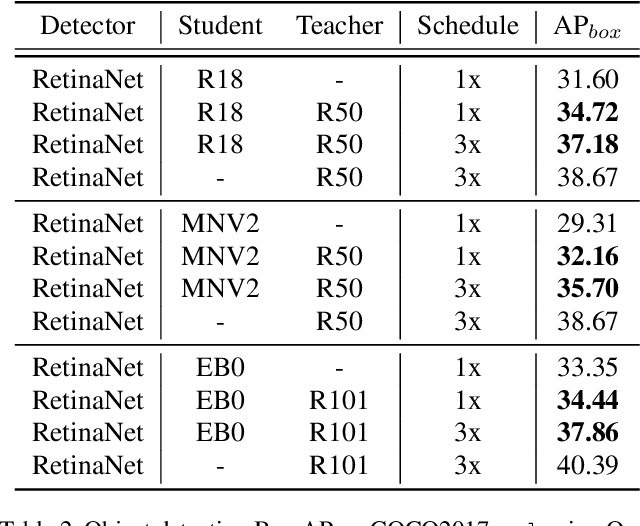
Effectively structuring deep knowledge plays a pivotal role in transfer from teacher to student, especially in semantic vision tasks. In this paper, we present a simple knowledge structure to exploit and encode information inside the detection system to facilitate detector knowledge distillation. Specifically, aiming at solving the feature imbalance problem while further excavating the missing relation inside semantic instances, we design a graph whose nodes correspond to instance proposal-level features and edges represent the relation between nodes. To further refine this graph, we design an adaptive background loss weight to reduce node noise and background samples mining to prune trivial edges. We transfer the entire graph as encoded knowledge representation from teacher to student, capturing local and global information simultaneously. We achieve new state-of-the-art results on the challenging COCO object detection task with diverse student-teacher pairs on both one- and two-stage detectors. We also experiment with instance segmentation to demonstrate robustness of our method. It is notable that distilled Faster R-CNN with ResNet18-FPN and ResNet50-FPN yields 38.68 and 41.82 Box AP respectively on the COCO benchmark, Faster R-CNN with ResNet101-FPN significantly achieves 43.38 AP, which outperforms ResNet152-FPN teacher about 0.7 AP. Code: https://github.com/dvlab-research/Dsig.
Image Synthesis via Semantic Composition
Sep 15, 2021
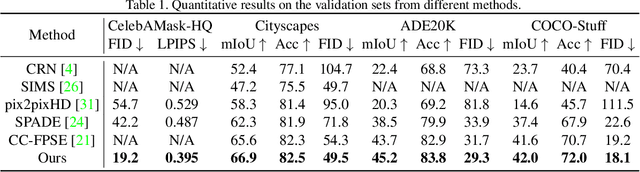
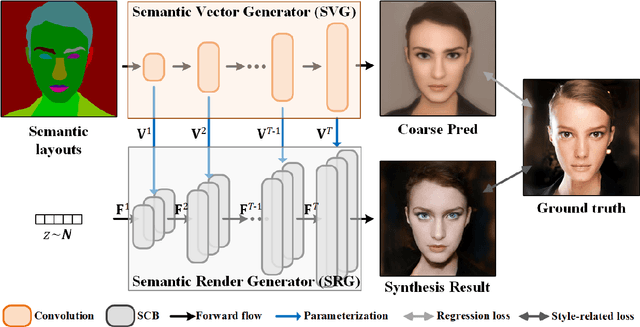
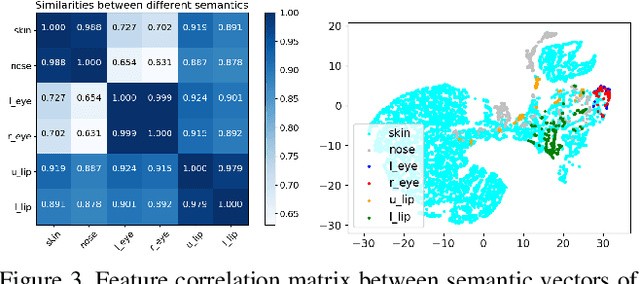
In this paper, we present a novel approach to synthesize realistic images based on their semantic layouts. It hypothesizes that for objects with similar appearance, they share similar representation. Our method establishes dependencies between regions according to their appearance correlation, yielding both spatially variant and associated representations. Conditioning on these features, we propose a dynamic weighted network constructed by spatially conditional computation (with both convolution and normalization). More than preserving semantic distinctions, the given dynamic network strengthens semantic relevance, benefiting global structure and detail synthesis. We demonstrate that our method gives the compelling generation performance qualitatively and quantitatively with extensive experiments on benchmarks.
Multi-Scale Aligned Distillation for Low-Resolution Detection
Sep 14, 2021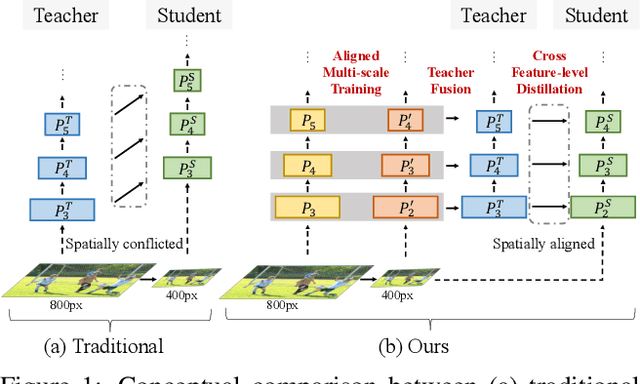
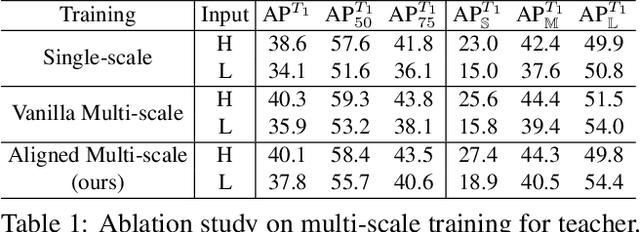
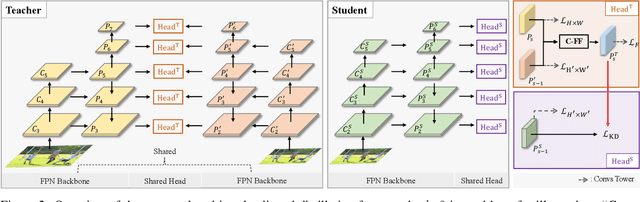

In instance-level detection tasks (e.g., object detection), reducing input resolution is an easy option to improve runtime efficiency. However, this option traditionally hurts the detection performance much. This paper focuses on boosting the performance of low-resolution models by distilling knowledge from a high- or multi-resolution model. We first identify the challenge of applying knowledge distillation (KD) to teacher and student networks that act on different input resolutions. To tackle it, we explore the idea of spatially aligning feature maps between models of varying input resolutions by shifting feature pyramid positions and introduce aligned multi-scale training to train a multi-scale teacher that can distill its knowledge to a low-resolution student. Further, we propose crossing feature-level fusion to dynamically fuse teacher's multi-resolution features to guide the student better. On several instance-level detection tasks and datasets, the low-resolution models trained via our approach perform competitively with high-resolution models trained via conventional multi-scale training, while outperforming the latter's low-resolution models by 2.1% to 3.6% in terms of mAP. Our code is made publicly available at https://github.com/dvlab-research/MSAD.
Exploring and Improving Mobile Level Vision Transformers
Aug 30, 2021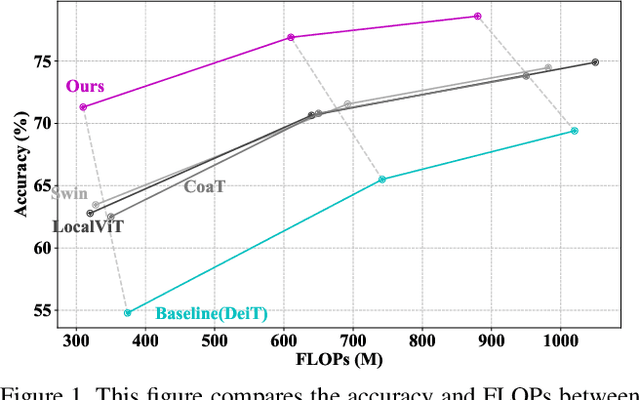
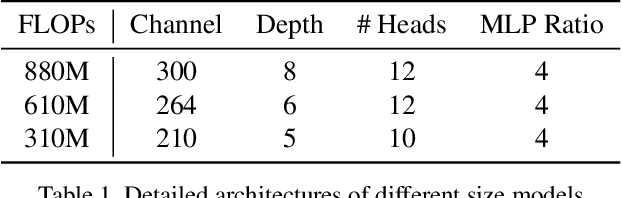
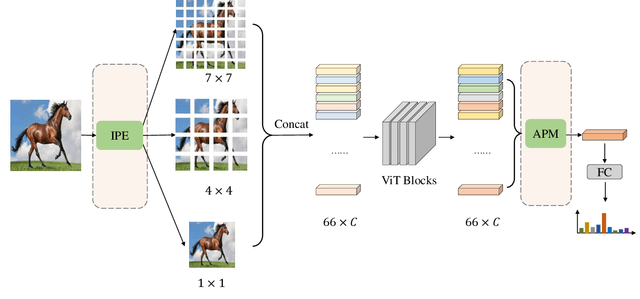
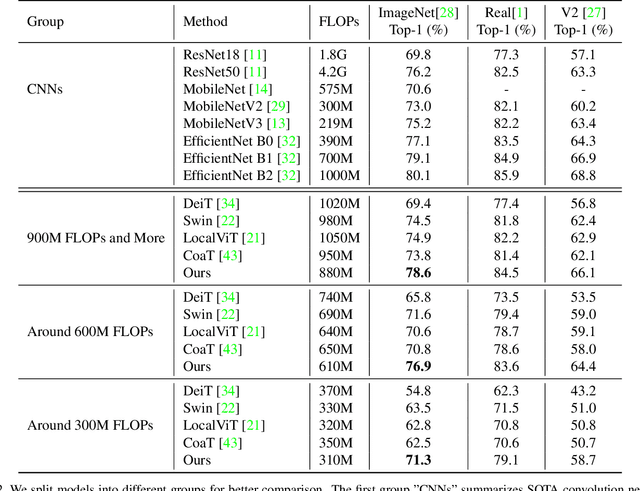
We study the vision transformer structure in the mobile level in this paper, and find a dramatic performance drop. We analyze the reason behind this phenomenon, and propose a novel irregular patch embedding module and adaptive patch fusion module to improve the performance. We conjecture that the vision transformer blocks (which consist of multi-head attention and feed-forward network) are more suitable to handle high-level information than low-level features. The irregular patch embedding module extracts patches that contain rich high-level information with different receptive fields. The transformer blocks can obtain the most useful information from these irregular patches. Then the processed patches pass the adaptive patch merging module to get the final features for the classifier. With our proposed improvements, the traditional uniform vision transformer structure can achieve state-of-the-art results in mobile level. We improve the DeiT baseline by more than 9\% under the mobile-level settings and surpass other transformer architectures like Swin and CoaT by a large margin.
Fully Convolutional Networks for Panoptic Segmentation with Point-based Supervision
Aug 18, 2021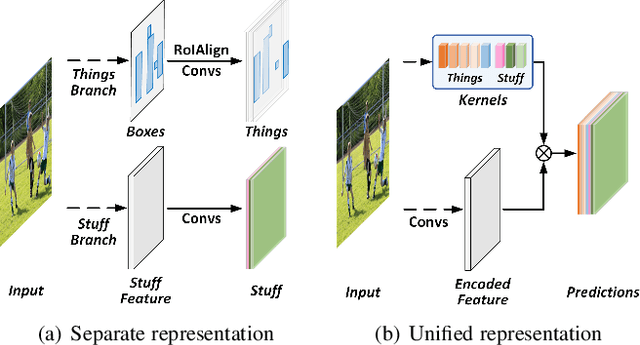
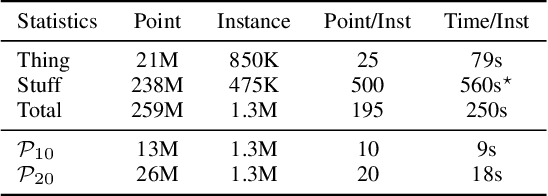
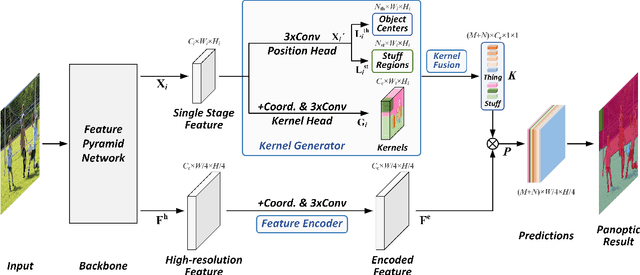
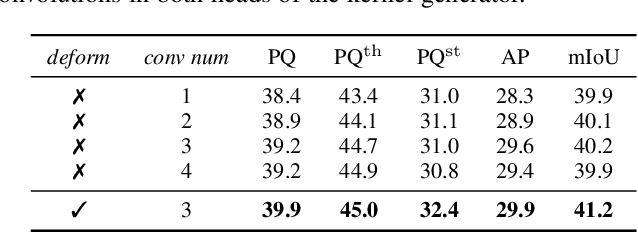
In this paper, we present a conceptually simple, strong, and efficient framework for fully- and weakly-supervised panoptic segmentation, called Panoptic FCN. Our approach aims to represent and predict foreground things and background stuff in a unified fully convolutional pipeline, which can be optimized with point-based fully or weak supervision. In particular, Panoptic FCN encodes each object instance or stuff category with the proposed kernel generator and produces the prediction by convolving the high-resolution feature directly. With this approach, instance-aware and semantically consistent properties for things and stuff can be respectively satisfied in a simple generate-kernel-then-segment workflow. Without extra boxes for localization or instance separation, the proposed approach outperforms the previous box-based and -free models with high efficiency. Furthermore, we propose a new form of point-based annotation for weakly-supervised panoptic segmentation. It only needs several random points for both things and stuff, which dramatically reduces the annotation cost of human. The proposed Panoptic FCN is also proved to have much superior performance in this weakly-supervised setting, which achieves 82% of the fully-supervised performance with only 20 randomly annotated points per instance. Extensive experiments demonstrate the effectiveness and efficiency of Panoptic FCN on COCO, VOC 2012, Cityscapes, and Mapillary Vistas datasets. And it sets up a new leading benchmark for both fully- and weakly-supervised panoptic segmentation. Our code and models are made publicly available at https://github.com/dvlab-research/PanopticFCN
Parametric Contrastive Learning
Aug 17, 2021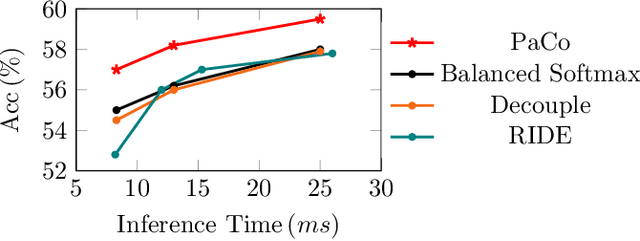
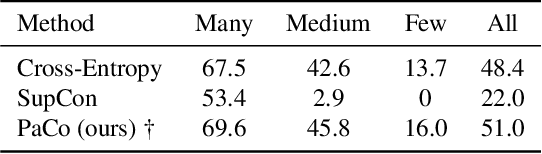
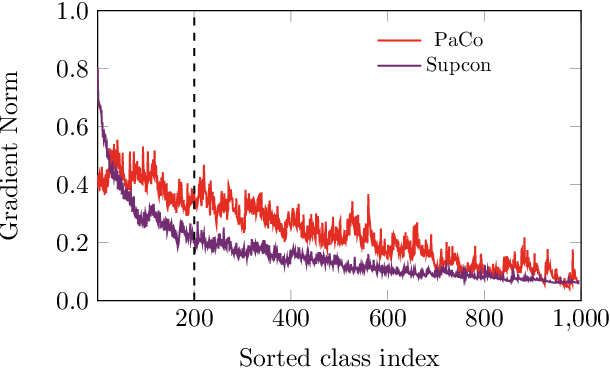

In this paper, we propose Parametric Contrastive Learning (PaCo) to tackle long-tailed recognition. Based on theoretical analysis, we observe supervised contrastive loss tends to bias on high-frequency classes and thus increases the difficulty of imbalanced learning. We introduce a set of parametric class-wise learnable centers to rebalance from an optimization perspective. Further, we analyze our PaCo loss under a balanced setting. Our analysis demonstrates that PaCo can adaptively enhance the intensity of pushing samples of the same class close as more samples are pulled together with their corresponding centers and benefit hard example learning. Experiments on long-tailed CIFAR, ImageNet, Places, and iNaturalist 2018 manifest the new state-of-the-art for long-tailed recognition. On full ImageNet, models trained with PaCo loss surpass supervised contrastive learning across various ResNet backbones, e.g., our ResNet-200 achieves 81.8% top-1 accuracy. Our code is available at https://github.com/dvlab-research/Parametric-Contrastive-Learning.