 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVCNet: A Robust Approach to Blind Image Inpainting
Paper and Code
Mar 15, 2020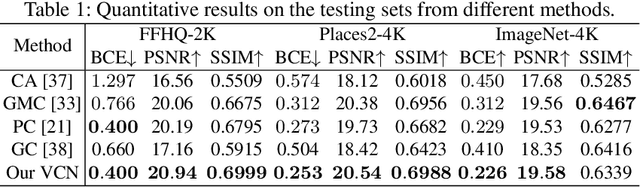
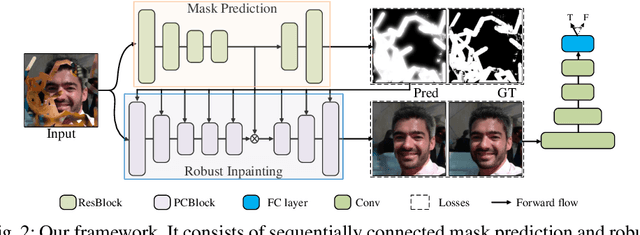
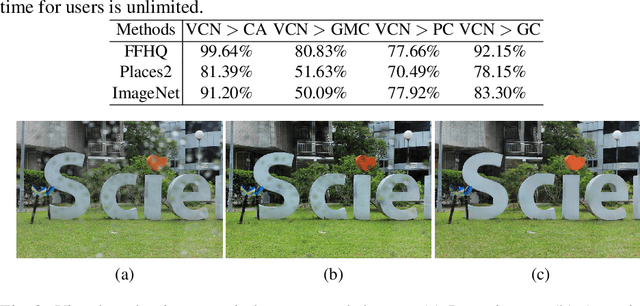

Blind inpainting is a task to automatically complete visual contents without specifying masks for missing areas in an image. Previous works assume missing region patterns are known, limiting its application scope. In this paper, we relax the assumption by defining a new blind inpainting setting, making training a blind inpainting neural system robust against various unknown missing region patterns. Specifically, we propose a two-stage visual consistency network (VCN), meant to estimate where to fill (via masks) and generate what to fill. In this procedure, the unavoidable potential mask prediction errors lead to severe artifacts in the subsequent repairing. To address it, our VCN predicts semantically inconsistent regions first, making mask prediction more tractable. Then it repairs these estimated missing regions using a new spatial normalization, enabling VCN to be robust to the mask prediction errors. In this way, semantically convincing and visually compelling content is thus generated. Extensive experiments are conducted, showing our method is effective and robust in blind image inpainting. And our VCN allows for a wide spectrum of applications.