 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEMA-Nesterov: Stabilizing Nesterov's Lookahead for Accelerated Deep Learning Optimization
May 25, 2026Lookahead-based acceleration methods, such as Nesterov's momentum, are widely used in optimization, but they often become unreliable in deep learning training mainly due to stochastic gradient noise and non-convex loss landscapes. In particular, standard lookahead relies on short-horizon update signals (e.g., differences between consecutive iterates), which are inherently noisy and can lead to unstable extrapolation directions. This work revisits Nesterov's acceleration from a trajectory perspective and argues that effective acceleration in deep learning should harness the low-frequency trends of optimization trajectories rather than extrapolating noisy one-step updates. Leveraging this insight, we propose EMA-Nesterov, a simple modification that replaces the standard Nesterov's lookahead direction with an exponential moving average (EMA) of parameter updates. This yields a stabilized lookahead direction that captures and harnesses the evolving trend of the training trajectory through a low-pass filter, while remaining adaptive to progressive changes via the geometric weighting structure of EMA. We show that EMA-Nesterov retains a theoretical accelerated convergence rate in convex problems that is analogous to Nesterov's accelerated gradient method. Furthermore, we provide empirical evidence on language model pre-training to verify that EMA-Nesterov is broadly applicable across a range of fine-tuned base optimizers, including Adam, SOAP, Muon, as well as complex optimizers that achieve state-of-the-art performance on optimization benchmarks (NanoGPT). Compared to prior lookahead methods, EMA-Nesterov achieves better performance by avoiding the instability of short-horizon lookahead and the non-adaptivity of long-horizon lookahead.
Scalable Parameter and Memory Efficient Pretraining for LLM: Recent Algorithmic Advances and Benchmarking
May 28, 2025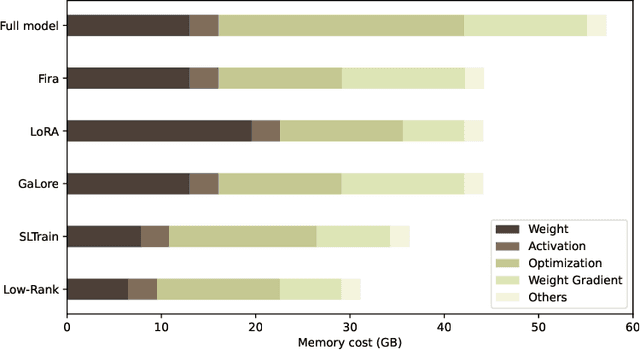



Fueled by their remarkable ability to tackle diverse tasks across multiple domains, large language models (LLMs) have grown at an unprecedented rate, with some recent models containing trillions of parameters. This growth is accompanied by substantial computational challenges, particularly regarding the memory and compute resources required for training and fine-tuning. Numerous approaches have been explored to address these issues, such as LoRA. While these methods are effective for fine-tuning, their application to pre-training is significantly more challenging due to the need to learn vast datasets. Motivated by this issue, we aim to address the following questions: Can parameter- or memory-efficient methods enhance pre-training efficiency while achieving performance comparable to full-model training? How can the performance gap be narrowed? To this end, the contributions of this work are the following. (1) We begin by conducting a comprehensive survey that summarizes state-of-the-art methods for efficient pre-training. (2) We perform a benchmark evaluation of several representative memory efficient pre-training approaches to comprehensively evaluate their performance across model sizes. We observe that with a proper choice of optimizer and hyperparameters, full-rank training delivers the best performance, as expected. We also notice that incorporating high-rank updates in low-rank approaches is the key to improving their performance. (3) Finally, we propose two practical techniques, namely weight refactorization and momentum reset, to enhance the performance of efficient pre-training methods. We observe that applying these techniques to the low-rank method (on a 1B model) can achieve a lower perplexity than popular memory efficient algorithms such as GaLore and Fira, while simultaneously using about 25% less memory.