 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTaxoCom: Topic Taxonomy Completion with Hierarchical Discovery of Novel Topic Clusters
Jan 19, 2022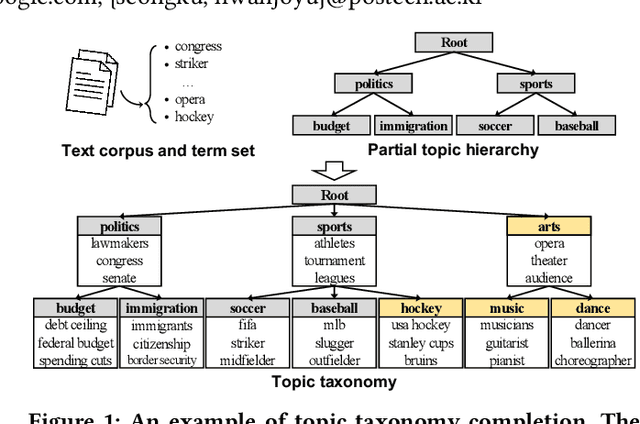
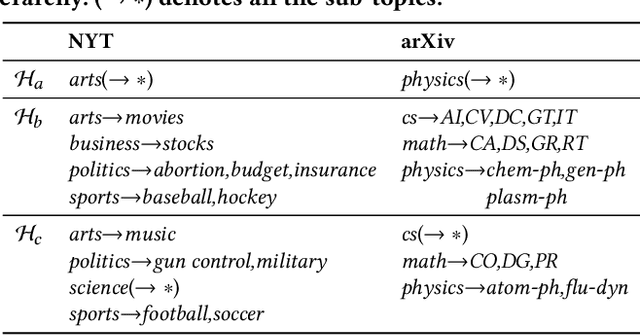
Topic taxonomies, which represent the latent topic (or category) structure of document collections, provide valuable knowledge of contents in many applications such as web search and information filtering. Recently, several unsupervised methods have been developed to automatically construct the topic taxonomy from a text corpus, but it is challenging to generate the desired taxonomy without any prior knowledge. In this paper, we study how to leverage the partial (or incomplete) information about the topic structure as guidance to find out the complete topic taxonomy. We propose a novel framework for topic taxonomy completion, named TaxoCom, which recursively expands the topic taxonomy by discovering novel sub-topic clusters of terms and documents. To effectively identify novel topics within a hierarchical topic structure, TaxoCom devises its embedding and clustering techniques to be closely-linked with each other: (i) locally discriminative embedding optimizes the text embedding space to be discriminative among known (i.e., given) sub-topics, and (ii) novelty adaptive clustering assigns terms into either one of the known sub-topics or novel sub-topics. Our comprehensive experiments on two real-world datasets demonstrate that TaxoCom not only generates the high-quality topic taxonomy in terms of term coherency and topic coverage but also outperforms all other baselines for a downstream task.
Out-of-Category Document Identification Using Target-Category Names as Weak Supervision
Nov 24, 2021
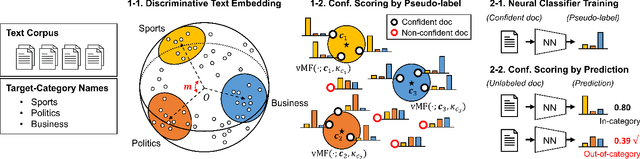

Identifying outlier documents, whose content is different from the majority of the documents in a corpus, has played an important role to manage a large text collection. However, due to the absence of explicit information about the inlier (or target) distribution, existing unsupervised outlier detectors are likely to make unreliable results depending on the density or diversity of the outliers in the corpus. To address this challenge, we introduce a new task referred to as out-of-category detection, which aims to distinguish the documents according to their semantic relevance to the inlier (or target) categories by using the category names as weak supervision. In practice, this task can be widely applicable in that it can flexibly designate the scope of target categories according to users' interests while requiring only the target-category names as minimum guidance. In this paper, we present an out-of-category detection framework, which effectively measures how confidently each document belongs to one of the target categories based on its category-specific relevance score. Our framework adopts a two-step approach; (i) it first generates the pseudo-category label of all unlabeled documents by exploiting the word-document similarity encoded in a text embedding space, then (ii) it trains a neural classifier by using the pseudo-labels in order to compute the confidence from its target-category prediction. The experiments on real-world datasets demonstrate that our framework achieves the best detection performance among all baseline methods in various scenarios specifying different target categories.
MotifClass: Weakly Supervised Text Classification with Higher-order Metadata Information
Nov 07, 2021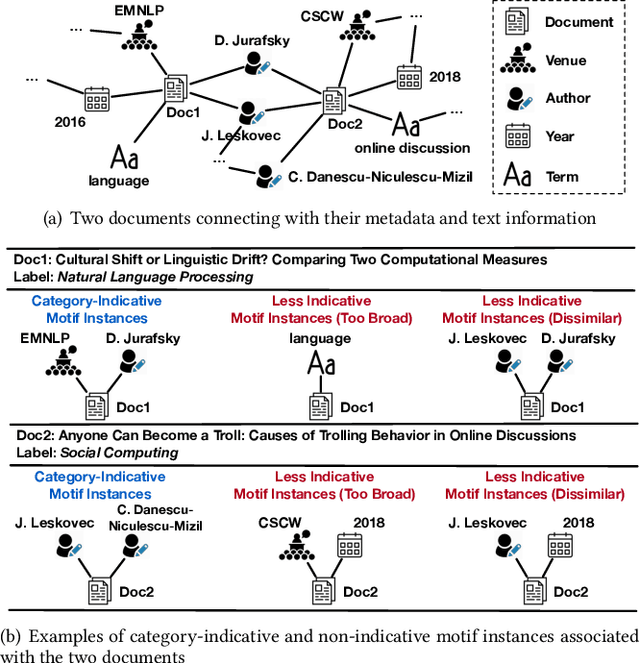
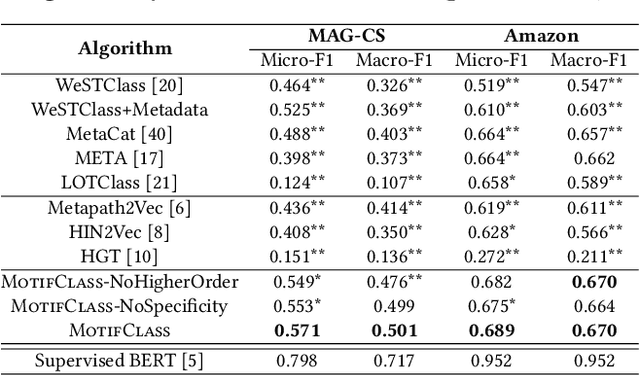
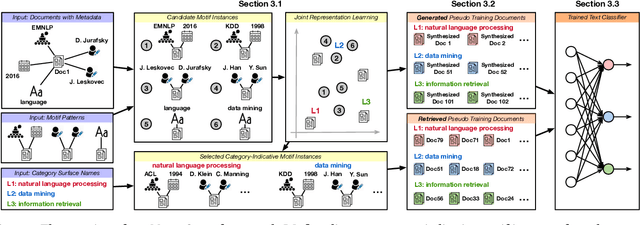
We study the problem of weakly supervised text classification, which aims to classify text documents into a set of pre-defined categories with category surface names only and without any annotated training document provided. Most existing approaches leverage textual information in each document. However, in many domains, documents are accompanied by various types of metadata (e.g., authors, venue, and year of a research paper). These metadata and their combinations may serve as strong category indicators in addition to textual contents. In this paper, we explore the potential of using metadata to help weakly supervised text classification. To be specific, we model the relationships between documents and metadata via a heterogeneous information network. To effectively capture higher-order structures in the network, we use motifs to describe metadata combinations. We propose a novel framework, named MotifClass, which (1) selects category-indicative motif instances, (2) retrieves and generates pseudo-labeled training samples based on category names and indicative motif instances, and (3) trains a text classifier using the pseudo training data. Extensive experiments on real-world datasets demonstrate the superior performance of MotifClass to existing weakly supervised text classification approaches. Further analysis shows the benefit of considering higher-order metadata information in our framework.
Fine-Grained Opinion Summarization with Minimal Supervision
Oct 17, 2021
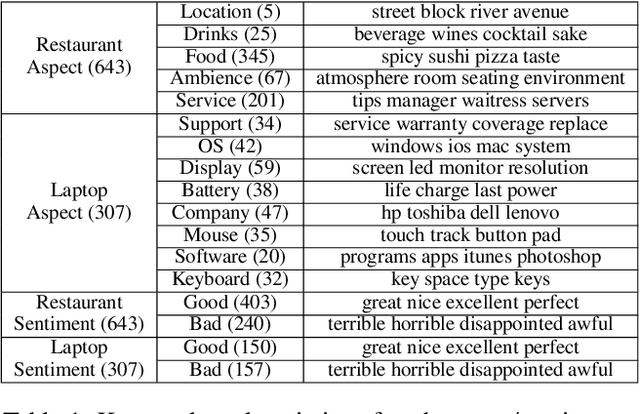
Opinion summarization aims to profile a target by extracting opinions from multiple documents. Most existing work approaches the task in a semi-supervised manner due to the difficulty of obtaining high-quality annotation from thousands of documents. Among them, some use aspect and sentiment analysis as a proxy for identifying opinions. In this work, we propose a new framework, FineSum, which advances this frontier in three aspects: (1) minimal supervision, where only aspect names and a few aspect/sentiment keywords are available; (2) fine-grained opinion analysis, where sentiment analysis drills down to the sub-aspect level; and (3) phrase-based summarization, where opinion is summarized in the form of phrases. FineSum automatically identifies opinion phrases from the raw corpus, classifies them into different aspects and sentiments, and constructs multiple fine-grained opinion clusters under each aspect/sentiment. Each cluster consists of semantically coherent phrases, expressing uniform opinions towards certain sub-aspect or characteristics (e.g., positive feelings for ``burgers'' in the ``food'' aspect). An opinion-oriented spherical word embedding space is trained to provide weak supervision for the phrase classifier, and phrase clustering is performed using the aspect-aware contextualized embedding generated from the phrase classifier. Both automatic evaluation on the benchmark and quantitative human evaluation validate the effectiveness of our approach.
UniPELT: A Unified Framework for Parameter-Efficient Language Model Tuning
Oct 14, 2021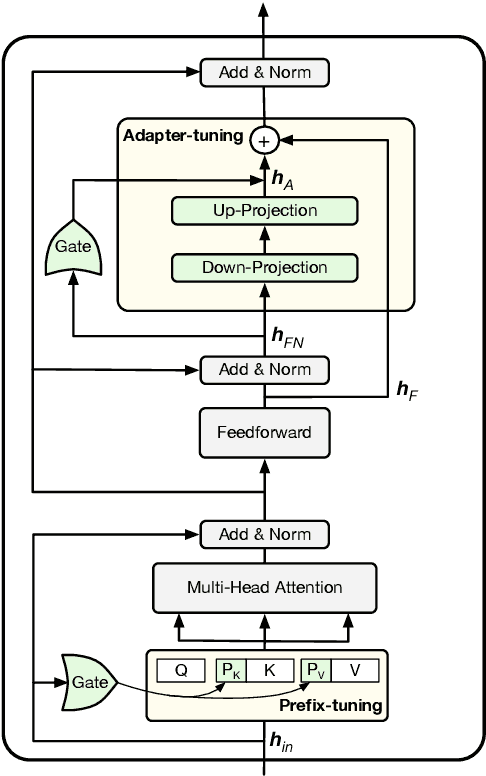
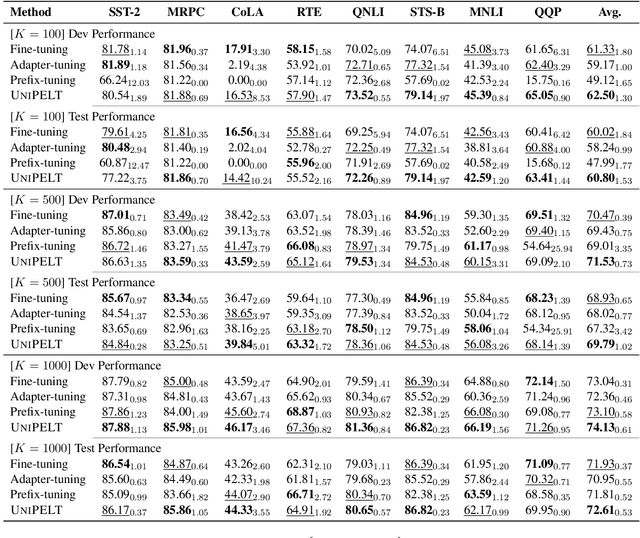
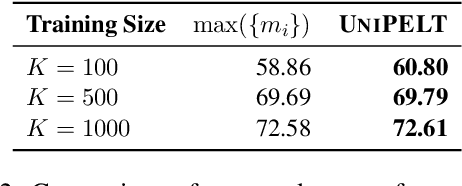
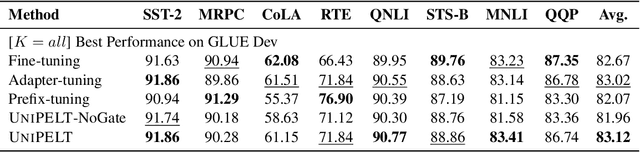
Conventional fine-tuning of pre-trained language models tunes all model parameters and stores a full model copy for each downstream task, which has become increasingly infeasible as the model size grows larger. Recent parameter-efficient language model tuning (PELT) methods manage to match the performance of fine-tuning with much fewer trainable parameters and perform especially well when the training data is limited. However, different PELT methods may perform rather differently on the same task, making it nontrivial to select the most appropriate method for a specific task, especially considering the fast-growing number of new PELT methods and downstream tasks. In light of model diversity and the difficulty of model selection, we propose a unified framework, UniPELT, which incorporates different PELT methods as submodules and learns to activate the ones that best suit the current data or task setup. Remarkably, on the GLUE benchmark, UniPELT consistently achieves 1~3pt gains compared to the best individual PELT method that it incorporates and even outperforms fine-tuning under different setups. Moreover, UniPELT often surpasses the upper bound when taking the best performance of all its submodules used individually on each task, indicating that a mixture of multiple PELT methods may be inherently more effective than single methods.
Entity Linking Meets Deep Learning: Techniques and Solutions
Sep 26, 2021
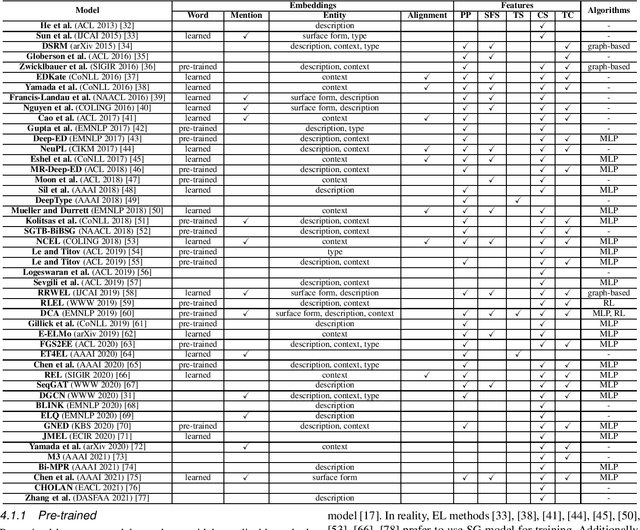
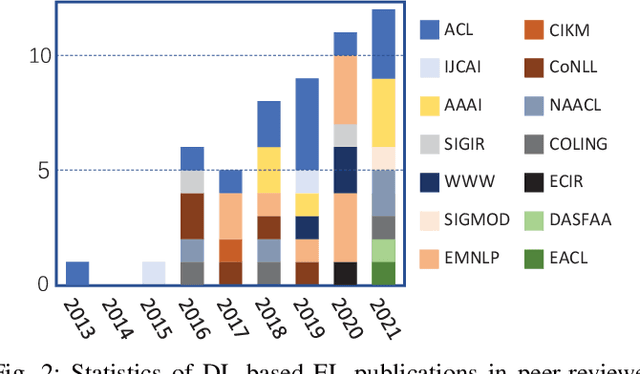
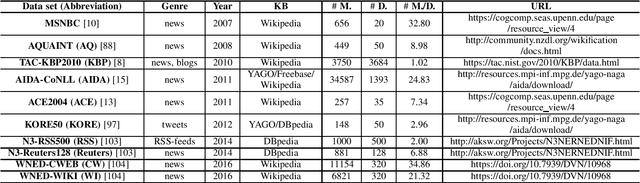
Entity linking (EL) is the process of linking entity mentions appearing in web text with their corresponding entities in a knowledge base. EL plays an important role in the fields of knowledge engineering and data mining, underlying a variety of downstream applications such as knowledge base population, content analysis, relation extraction, and question answering. In recent years, deep learning (DL), which has achieved tremendous success in various domains, has also been leveraged in EL methods to surpass traditional machine learning based methods and yield the state-of-the-art performance. In this survey, we present a comprehensive review and analysis of existing DL based EL methods. First of all, we propose a new taxonomy, which organizes existing DL based EL methods using three axes: embedding, feature, and algorithm. Then we systematically survey the representative EL methods along the three axes of the taxonomy. Later, we introduce ten commonly used EL data sets and give a quantitative performance analysis of DL based EL methods over these data sets. Finally, we discuss the remaining limitations of existing methods and highlight some promising future directions.
SAIS: Supervising and Augmenting Intermediate Steps for Document-Level Relation Extraction
Sep 24, 2021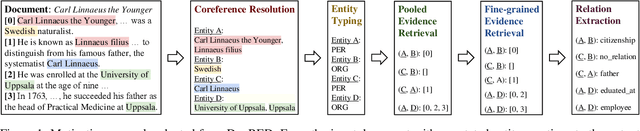

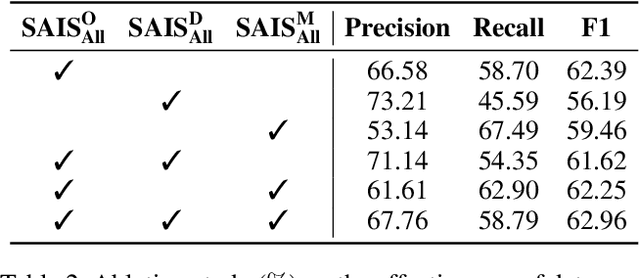
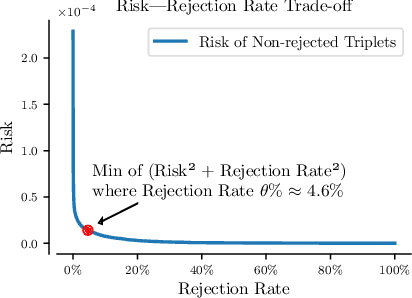
Stepping from sentence-level to document-level relation extraction, the research community confronts increasing text length and more complicated entity interactions. Consequently, it is more challenging to encode the key sources of information--relevant contexts and entity types. However, existing methods only implicitly learn to model these critical information sources while being trained for relation extraction. As a result, they suffer the problems of ineffective supervision and uninterpretable model predictions. In contrast, we propose to explicitly teach the model to capture relevant contexts and entity types by supervising and augmenting intermediate steps (SAIS) for relation extraction. Based on a broad spectrum of carefully designed tasks, our proposed SAIS method not only extracts relations of better quality due to more effective supervision, but also retrieves the corresponding supporting evidence more accurately so as to enhance interpretability. By assessing model uncertainty, SAIS further boosts the performance via evidence-based data augmentation and ensemble inference while reducing the computational cost. Eventually, SAIS delivers state-of-the-art relation extraction results on three benchmarks (DocRED, CDR, and GDA) and achieves 5.04% relative gains in F1 score compared to the runner-up in evidence retrieval on DocRED.
Chemical-Reaction-Aware Molecule Representation Learning
Sep 22, 2021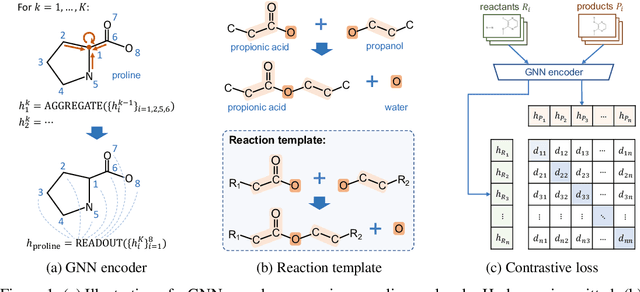
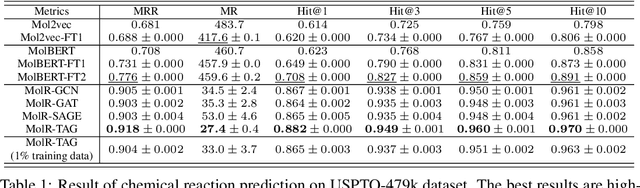
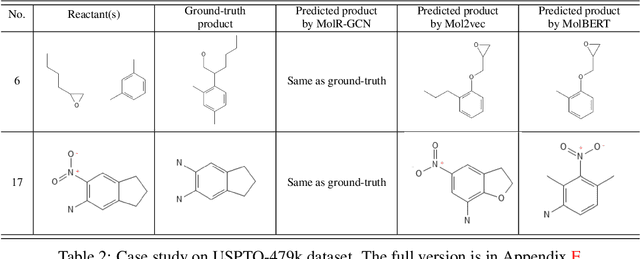
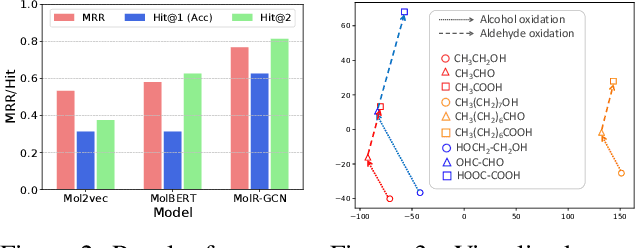
Molecule representation learning (MRL) methods aim to embed molecules into a real vector space. However, existing SMILES-based (Simplified Molecular-Input Line-Entry System) or GNN-based (Graph Neural Networks) MRL methods either take SMILES strings as input that have difficulty in encoding molecule structure information, or over-emphasize the importance of GNN architectures but neglect their generalization ability. Here we propose using chemical reactions to assist learning molecule representation. The key idea of our approach is to preserve the equivalence of molecules with respect to chemical reactions in the embedding space, i.e., forcing the sum of reactant embeddings and the sum of product embeddings to be equal for each chemical equation. This constraint is proven effective to 1) keep the embedding space well-organized and 2) improve the generalization ability of molecule embeddings. Moreover, our model can use any GNN as the molecule encoder and is thus agnostic to GNN architectures. Experimental results demonstrate that our method achieves state-of-the-art performance in a variety of downstream tasks, e.g., 17.4% absolute Hit@1 gain in chemical reaction prediction, 2.3% absolute AUC gain in molecule property prediction, and 18.5% relative RMSE gain in graph-edit-distance prediction, respectively, over the best baseline method. The code is available at https://github.com/hwwang55/MolR.
Distantly-Supervised Named Entity Recognition with Noise-Robust Learning and Language Model Augmented Self-Training
Sep 10, 2021
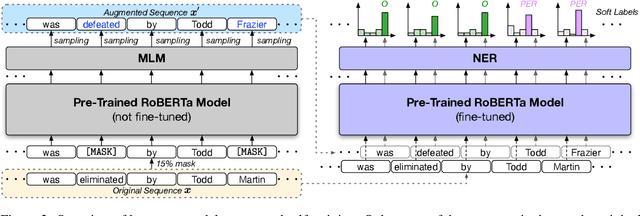
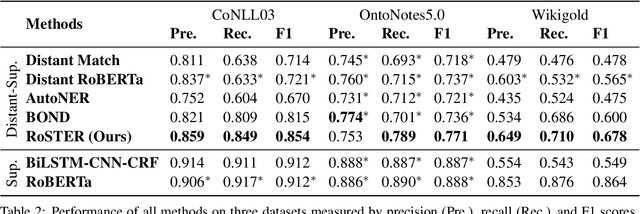
We study the problem of training named entity recognition (NER) models using only distantly-labeled data, which can be automatically obtained by matching entity mentions in the raw text with entity types in a knowledge base. The biggest challenge of distantly-supervised NER is that the distant supervision may induce incomplete and noisy labels, rendering the straightforward application of supervised learning ineffective. In this paper, we propose (1) a noise-robust learning scheme comprised of a new loss function and a noisy label removal step, for training NER models on distantly-labeled data, and (2) a self-training method that uses contextualized augmentations created by pre-trained language models to improve the generalization ability of the NER model. On three benchmark datasets, our method achieves superior performance, outperforming existing distantly-supervised NER models by significant margins.
Corpus-based Open-Domain Event Type Induction
Sep 07, 2021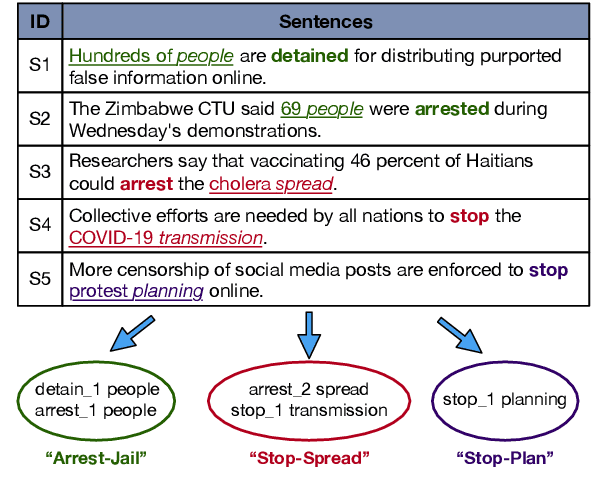

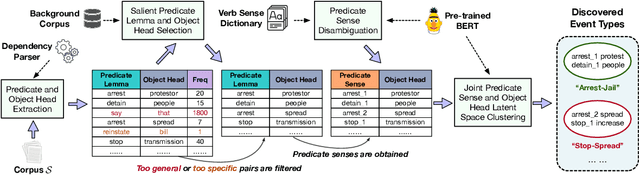
Traditional event extraction methods require predefined event types and their corresponding annotations to learn event extractors. These prerequisites are often hard to be satisfied in real-world applications. This work presents a corpus-based open-domain event type induction method that automatically discovers a set of event types from a given corpus. As events of the same type could be expressed in multiple ways, we propose to represent each event type as a cluster of <predicate sense, object head> pairs. Specifically, our method (1) selects salient predicates and object heads, (2) disambiguates predicate senses using only a verb sense dictionary, and (3) obtains event types by jointly embedding and clustering <predicate sense, object head> pairs in a latent spherical space. Our experiments, on three datasets from different domains, show our method can discover salient and high-quality event types, according to both automatic and human evaluations.