 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCODESTRUCT: Code Agents over Structured Action Spaces
Apr 07, 2026LLM-based code agents treat repositories as unstructured text, applying edits through brittle string matching that frequently fails due to formatting drift or ambiguous patterns. We propose reframing the codebase as a structured action space where agents operate on named AST entities rather than text spans. Our framework, CODESTRUCT, provides readCode for retrieving complete syntactic units and editCode for applying syntax-validated transformations to semantic program elements. Evaluated on SWE-Bench Verified across six LLMs, CODESTRUCT improves Pass@1 accuracy by 1.2-5.0% while reducing token consumption by 12-38% for most models. Models that frequently fail to produce valid patches under text-based interfaces benefit most: GPT-5-nano improves by 20.8% as empty-patch failures drop from 46.6% to 7.2%. On CodeAssistBench, we observe consistent accuracy gains (+0.8-4.4%) with cost reductions up to 33%. Our results show that structure-aware interfaces offer a more reliable foundation for code agents.
TRAJEVAL: Decomposing Code Agent Trajectories for Fine-Grained Diagnosis
Mar 25, 2026Code agents can autonomously resolve GitHub issues, yet when they fail, current evaluation provides no visibility into where or why. Metrics such as Pass@1 collapse an entire execution into a single binary outcome, making it difficult to identify where and why the agent went wrong. To address this limitation, we introduce TRAJEVAL, a diagnostic framework that decomposes agent trajectories into three interpretable stages: search (file localization), read (function comprehension), and edit (modification targeting). For each stage, we compute precision and recall by comparing against reference patches. Analyzing 16,758 trajectories across three agent architectures and seven models, we find universal inefficiencies (all agents examine approximately 22x more functions than necessary) yet distinct failure modes: GPT-5 locates relevant code but targets edits incorrectly, while Qwen-32B fails at file discovery entirely. We validate that these diagnostics are predictive, achieving model-level Pass@1 prediction within 0.87-2.1% MAE, and actionable: real-time feedback based on trajectory signals improves two state-of-the-art models by 2.2-4.6 percentage points while reducing costs by 20-31%. These results demonstrate that our framework not only provides a more fine-grained analysis of agent behavior, but also translates diagnostic signals into tangible performance gains. More broadly, TRAJEVAL transforms agent evaluation beyond outcome-based benchmarking toward mechanism-driven diagnosis of agent success and failure.
Textual Gradients are a Flawed Metaphor for Automatic Prompt Optimization
Dec 15, 2025



A well-engineered prompt can increase the performance of large language models; automatic prompt optimization techniques aim to increase performance without requiring human effort to tune the prompts. One leading class of prompt optimization techniques introduces the analogy of textual gradients. We investigate the behavior of these textual gradient methods through a series of experiments and case studies. While such methods often result in a performance improvement, our experiments suggest that the gradient analogy does not accurately explain their behavior. Our insights may inform the selection of prompt optimization strategies, and development of new approaches.
Early prediction of onset of sepsis in Clinical Setting
Feb 05, 2024This study proposes the use of Machine Learning models to predict the early onset of sepsis using deidentified clinical data from Montefiore Medical Center in Bronx, NY, USA. A supervised learning approach was adopted, wherein an XGBoost model was trained utilizing 80\% of the train dataset, encompassing 107 features (including the original and derived features). Subsequently, the model was evaluated on the remaining 20\% of the test data. The model was validated on prospective data that was entirely unseen during the training phase. To assess the model's performance at the individual patient level and timeliness of the prediction, a normalized utility score was employed, a widely recognized scoring methodology for sepsis detection, as outlined in the PhysioNet Sepsis Challenge paper. Metrics such as F1 Score, Sensitivity, Specificity, and Flag Rate were also devised. The model achieved a normalized utility score of 0.494 on test data and 0.378 on prospective data at threshold 0.3. The F1 scores were 80.8\% and 67.1\% respectively for the test data and the prospective data for the same threshold, highlighting its potential to be integrated into clinical decision-making processes effectively. These results bear testament to the model's robust predictive capabilities and its potential to substantially impact clinical decision-making processes.
MotifClass: Weakly Supervised Text Classification with Higher-order Metadata Information
Nov 07, 2021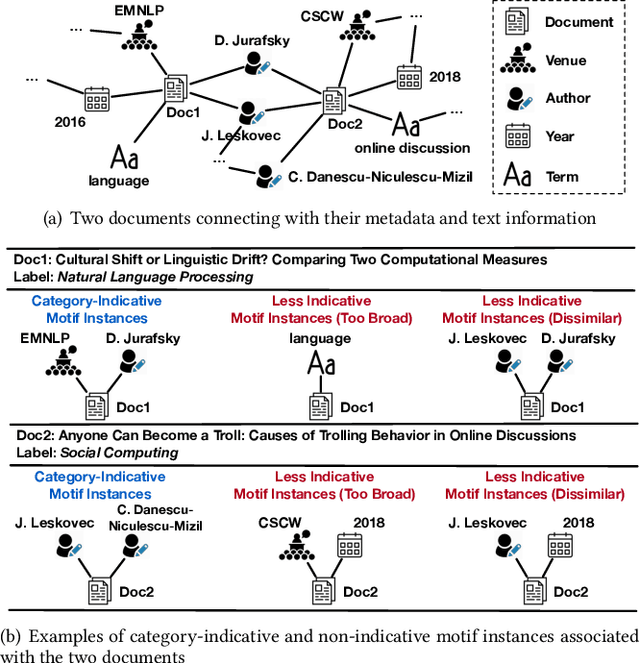
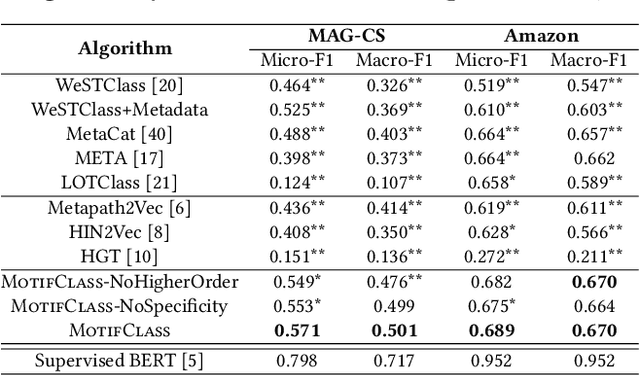
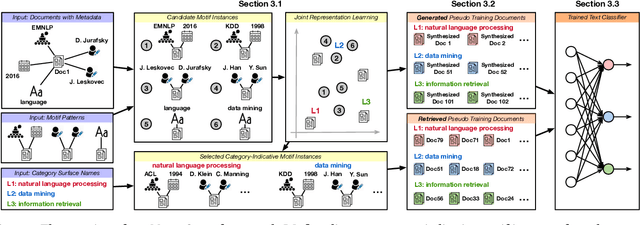
We study the problem of weakly supervised text classification, which aims to classify text documents into a set of pre-defined categories with category surface names only and without any annotated training document provided. Most existing approaches leverage textual information in each document. However, in many domains, documents are accompanied by various types of metadata (e.g., authors, venue, and year of a research paper). These metadata and their combinations may serve as strong category indicators in addition to textual contents. In this paper, we explore the potential of using metadata to help weakly supervised text classification. To be specific, we model the relationships between documents and metadata via a heterogeneous information network. To effectively capture higher-order structures in the network, we use motifs to describe metadata combinations. We propose a novel framework, named MotifClass, which (1) selects category-indicative motif instances, (2) retrieves and generates pseudo-labeled training samples based on category names and indicative motif instances, and (3) trains a text classifier using the pseudo training data. Extensive experiments on real-world datasets demonstrate the superior performance of MotifClass to existing weakly supervised text classification approaches. Further analysis shows the benefit of considering higher-order metadata information in our framework.