 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Inversion of Spectroscopic Data for Amorphous Structure Elucidation
Mar 24, 2026Determining atomistic structures from characterization data is one of the most common yet intricate problems in materials science. Particularly in amorphous materials, proposing structures that balance realism and agreement with experiments requires expert guidance, good interatomic potentials, or both. Here, we introduce GLASS, a generative framework that inverts multi-modal spectroscopic measurements into realistic atomistic structures without knowledge of the potential energy surface. A score-based model learns a structural prior from low-fidelity data and samples out-of-distribution structures conditioned on differentiable spectral targets. Reconstructions using pair distribution functions (PDFs), X-ray absorption spectroscopy, and diffraction measurements quantify the complementarity between spectral modalities and demonstrate that PDFs is the most informative probe for our framework. We use GLASS to rationalize three contested experimental problems: paracrystallinity in amorphous silicon, a liquid-liquid phase transition in sulfur, and ball-milled amorphous ice. In each case, generated structures reproduce experimental measurements and reveal mechanisms inaccessible to diffraction analysis alone.
S$^2$GR: Stepwise Semantic-Guided Reasoning in Latent Space for Generative Recommendation
Jan 26, 2026Generative Recommendation (GR) has emerged as a transformative paradigm with its end-to-end generation advantages. However, existing GR methods primarily focus on direct Semantic ID (SID) generation from interaction sequences, failing to activate deeper reasoning capabilities analogous to those in large language models and thus limiting performance potential. We identify two critical limitations in current reasoning-enhanced GR approaches: (1) Strict sequential separation between reasoning and generation steps creates imbalanced computational focus across hierarchical SID codes, degrading quality for SID codes; (2) Generated reasoning vectors lack interpretable semantics, while reasoning paths suffer from unverifiable supervision. In this paper, we propose stepwise semantic-guided reasoning in latent space (S$^2$GR), a novel reasoning enhanced GR framework. First, we establish a robust semantic foundation via codebook optimization, integrating item co-occurrence relationship to capture behavioral patterns, and load balancing and uniformity objectives that maximize codebook utilization while reinforcing coarse-to-fine semantic hierarchies. Our core innovation introduces the stepwise reasoning mechanism inserting thinking tokens before each SID generation step, where each token explicitly represents coarse-grained semantics supervised via contrastive learning against ground-truth codebook cluster distributions ensuring physically grounded reasoning paths and balanced computational focus across all SID codes. Extensive experiments demonstrate the superiority of S$^2$GR, and online A/B test confirms efficacy on large-scale industrial short video platform.
Kwai Keye-VL Technical Report
Jul 02, 2025While Multimodal Large Language Models (MLLMs) demonstrate remarkable capabilities on static images, they often fall short in comprehending dynamic, information-dense short-form videos, a dominant medium in today's digital landscape. To bridge this gap, we introduce \textbf{Kwai Keye-VL}, an 8-billion-parameter multimodal foundation model engineered for leading-edge performance in short-video understanding while maintaining robust general-purpose vision-language abilities. The development of Keye-VL rests on two core pillars: a massive, high-quality dataset exceeding 600 billion tokens with a strong emphasis on video, and an innovative training recipe. This recipe features a four-stage pre-training process for solid vision-language alignment, followed by a meticulous two-phase post-training process. The first post-training stage enhances foundational capabilities like instruction following, while the second phase focuses on stimulating advanced reasoning. In this second phase, a key innovation is our five-mode ``cold-start'' data mixture, which includes ``thinking'', ``non-thinking'', ``auto-think'', ``think with image'', and high-quality video data. This mixture teaches the model to decide when and how to reason. Subsequent reinforcement learning (RL) and alignment steps further enhance these reasoning capabilities and correct abnormal model behaviors, such as repetitive outputs. To validate our approach, we conduct extensive evaluations, showing that Keye-VL achieves state-of-the-art results on public video benchmarks and remains highly competitive on general image-based tasks (Figure 1). Furthermore, we develop and release the \textbf{KC-MMBench}, a new benchmark tailored for real-world short-video scenarios, where Keye-VL shows a significant advantage.
ScaleLong: A Multi-Timescale Benchmark for Long Video Understanding
May 29, 2025



Although long-video understanding demands that models capture hierarchical temporal information -- from clip (seconds) and shot (tens of seconds) to event (minutes) and story (hours) -- existing benchmarks either neglect this multi-scale design or scatter scale-specific questions across different videos, preventing direct comparison of model performance across timescales on the same content. To address this, we introduce ScaleLong, the first benchmark to disentangle these factors by embedding questions targeting four hierarchical timescales -- clip (seconds), shot (tens of seconds), event (minutes), and story (hours) -- all within the same video content. This within-content multi-timescale questioning design enables direct comparison of model performance across timescales on identical videos. ScaleLong features 269 long videos (avg.\ 86\,min) from 5 main categories and 36 sub-categories, with 4--8 carefully designed questions, including at least one question for each timescale. Evaluating 23 MLLMs reveals a U-shaped performance curve, with higher accuracy at the shortest and longest timescales and a dip at intermediate levels. Furthermore, ablation studies show that increased visual token capacity consistently enhances reasoning across all timescales. ScaleLong offers a fine-grained, multi-timescale benchmark for advancing MLLM capabilities in long-video understanding. The code and dataset are available https://github.com/multimodal-art-projection/ScaleLong.
CROP: Contextual Region-Oriented Visual Token Pruning
May 27, 2025



Current VLM-based VQA methods often process entire images, leading to excessive visual tokens that include redundant information irrelevant to the posed question. This abundance of unnecessary image details creates numerous visual tokens, drastically increasing memory and computational requirements in VLMs. To address this, we propose Contextual Region-Oriented Visual Token Pruning (CROP), a novel framework to compress visual tokens through a two-step process: Localization and Pruning. Specifically, CROP first employs an efficient model to identify the contextual region relevant to the input query. Subsequently, two distinct strategies are introduced for pruning: (1) Pre-LLM Compression (PLC), which adaptively compresses different image regions with varying ratios, and (2) Inner-LLM Pruning (ILP), a training-free method that prunes tokens within early LLM layers guided by the identified contextual region. Extensive experiments on a wide range of VQA tasks demonstrate that CROP significantly outperforms existing visual token pruning methods and achieves state-of-the-art performance. Our code and datasets will be made available.
System Prompt Poisoning: Persistent Attacks on Large Language Models Beyond User Injection
May 10, 2025



Large language models (LLMs) have gained widespread adoption across diverse applications due to their impressive generative capabilities. Their plug-and-play nature enables both developers and end users to interact with these models through simple prompts. However, as LLMs become more integrated into various systems in diverse domains, concerns around their security are growing. Existing studies mainly focus on threats arising from user prompts (e.g. prompt injection attack) and model output (e.g. model inversion attack), while the security of system prompts remains largely overlooked. This work bridges the critical gap. We introduce system prompt poisoning, a new attack vector against LLMs that, unlike traditional user prompt injection, poisons system prompts hence persistently impacts all subsequent user interactions and model responses. We systematically investigate four practical attack strategies in various poisoning scenarios. Through demonstration on both generative and reasoning LLMs, we show that system prompt poisoning is highly feasible without requiring jailbreak techniques, and effective across a wide range of tasks, including those in mathematics, coding, logical reasoning, and natural language processing. Importantly, our findings reveal that the attack remains effective even when user prompts employ advanced prompting techniques like chain-of-thought (CoT). We also show that such techniques, including CoT and retrieval-augmentation-generation (RAG), which are proven to be effective for improving LLM performance in a wide range of tasks, are significantly weakened in their effectiveness by system prompt poisoning.
AutoKaggle: A Multi-Agent Framework for Autonomous Data Science Competitions
Oct 29, 2024



Data science tasks involving tabular data present complex challenges that require sophisticated problem-solving approaches. We propose AutoKaggle, a powerful and user-centric framework that assists data scientists in completing daily data pipelines through a collaborative multi-agent system. AutoKaggle implements an iterative development process that combines code execution, debugging, and comprehensive unit testing to ensure code correctness and logic consistency. The framework offers highly customizable workflows, allowing users to intervene at each phase, thus integrating automated intelligence with human expertise. Our universal data science toolkit, comprising validated functions for data cleaning, feature engineering, and modeling, forms the foundation of this solution, enhancing productivity by streamlining common tasks. We selected 8 Kaggle competitions to simulate data processing workflows in real-world application scenarios. Evaluation results demonstrate that AutoKaggle achieves a validation submission rate of 0.85 and a comprehensive score of 0.82 in typical data science pipelines, fully proving its effectiveness and practicality in handling complex data science tasks.
I-SHEEP: Self-Alignment of LLM from Scratch through an Iterative Self-Enhancement Paradigm
Aug 15, 2024



Large Language Models (LLMs) have achieved significant advancements, however, the common learning paradigm treats LLMs as passive information repositories, neglecting their potential for active learning and alignment. Some approaches train LLMs using their own generated synthetic data, exploring the possibility of active alignment. However, there is still a huge gap between these one-time alignment methods and the continuous automatic alignment of humans. In this paper, we introduce \textbf{I-SHEEP}, an \textbf{I}terative \textbf{S}elf-En\textbf{H}anc\textbf{E}m\textbf{E}nt \textbf{P}aradigm.This human-like paradigm enables LLMs to \textbf{continuously self-align from scratch with nothing}. Compared to the one-time alignment method Dromedary \cite{sun2023principledriven}, which refers to the first iteration in this paper, I-SHEEP can significantly enhance capacities on both Qwen and Llama models. I-SHEEP achieves a maximum relative improvement of 78.2\% in the Alpaca Eval, 24.0\% in the MT Bench, and an absolute increase of 8.88\% in the IFEval accuracy over subsequent iterations in Qwen-1.5 72B model. Additionally, I-SHEEP surpasses the base model in various standard benchmark generation tasks, achieving an average improvement of 24.77\% in code generation tasks, 12.04\% in TrivialQA, and 20.29\% in SQuAD. We also provide new insights based on the experiment results. Our codes, datasets, and models are available at \textbf{https://anonymous.4open.science/r/I-SHEEP}.
Diffusion Transformer Captures Spatial-Temporal Dependencies: A Theory for Gaussian Process Data
Jul 23, 2024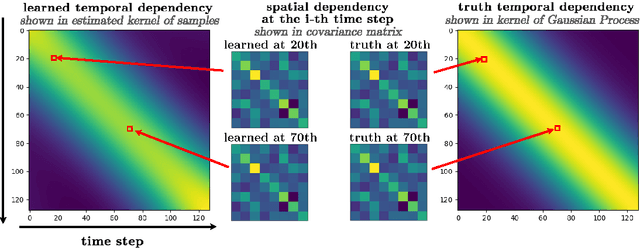
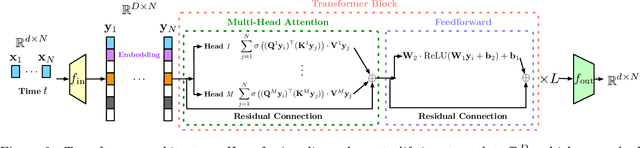

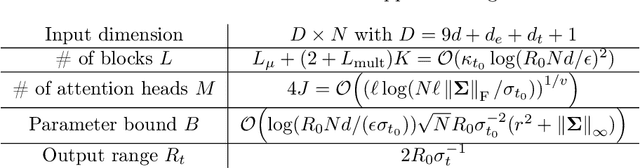
Diffusion Transformer, the backbone of Sora for video generation, successfully scales the capacity of diffusion models, pioneering new avenues for high-fidelity sequential data generation. Unlike static data such as images, sequential data consists of consecutive data frames indexed by time, exhibiting rich spatial and temporal dependencies. These dependencies represent the underlying dynamic model and are critical to validate the generated data. In this paper, we make the first theoretical step towards bridging diffusion transformers for capturing spatial-temporal dependencies. Specifically, we establish score approximation and distribution estimation guarantees of diffusion transformers for learning Gaussian process data with covariance functions of various decay patterns. We highlight how the spatial-temporal dependencies are captured and affect learning efficiency. Our study proposes a novel transformer approximation theory, where the transformer acts to unroll an algorithm. We support our theoretical results by numerical experiments, providing strong evidence that spatial-temporal dependencies are captured within attention layers, aligning with our approximation theory.
Enhancing Neural Radiance Fields with Depth and Normal Completion Priors from Sparse Views
Jul 08, 2024


Neural Radiance Fields (NeRF) are an advanced technology that creates highly realistic images by learning about scenes through a neural network model. However, NeRF often encounters issues when there are not enough images to work with, leading to problems in accurately rendering views. The main issue is that NeRF lacks sufficient structural details to guide the rendering process accurately. To address this, we proposed a Depth and Normal Dense Completion Priors for NeRF (CP\_NeRF) framework. This framework enhances view rendering by adding depth and normal dense completion priors to the NeRF optimization process. Before optimizing NeRF, we obtain sparse depth maps using the Structure from Motion (SfM) technique used to get camera poses. Based on the sparse depth maps and a normal estimator, we generate sparse normal maps for training a normal completion prior with precise standard deviations. During optimization, we apply depth and normal completion priors to transform sparse data into dense depth and normal maps with their standard deviations. We use these dense maps to guide ray sampling, assist distance sampling and construct a normal loss function for better training accuracy. To improve the rendering of NeRF's normal outputs, we incorporate an optical centre position embedder that helps synthesize more accurate normals through volume rendering. Additionally, we employ a normal patch matching technique to choose accurate rendered normal maps, ensuring more precise supervision for the model. Our method is superior to leading techniques in rendering detailed indoor scenes, even with limited input views.