 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBidirectional-Reachable Hierarchical Reinforcement Learning with Mutually Responsive Policies
Jun 26, 2024



Hierarchical reinforcement learning (HRL) addresses complex long-horizon tasks by skillfully decomposing them into subgoals. Therefore, the effectiveness of HRL is greatly influenced by subgoal reachability. Typical HRL methods only consider subgoal reachability from the unilateral level, where a dominant level enforces compliance to the subordinate level. However, we observe that when the dominant level becomes trapped in local exploration or generates unattainable subgoals, the subordinate level is negatively affected and cannot follow the dominant level's actions. This can potentially make both levels stuck in local optima, ultimately hindering subsequent subgoal reachability. Allowing real-time bilateral information sharing and error correction would be a natural cure for this issue, which motivates us to propose a mutual response mechanism. Based on this, we propose the Bidirectional-reachable Hierarchical Policy Optimization (BrHPO)--a simple yet effective algorithm that also enjoys computation efficiency. Experiment results on a variety of long-horizon tasks showcase that BrHPO outperforms other state-of-the-art HRL baselines, coupled with a significantly higher exploration efficiency and robustness.
RoboGolf: Mastering Real-World Minigolf with a Reflective Multi-Modality Vision-Language Model
Jun 14, 2024Minigolf, a game with countless court layouts, and complex ball motion, constitutes a compelling real-world testbed for the study of embodied intelligence. As it not only challenges spatial and kinodynamic reasoning but also requires reflective and corrective capacities to address erroneously designed courses. We introduce RoboGolf, a framework that perceives dual-camera visual inputs with nested VLM-empowered closed-loop control and reflective equilibrium loop. Extensive experiments demonstrate the effectiveness of RoboGolf on challenging minigolf courts including those that are impossible to finish.
OMPO: A Unified Framework for RL under Policy and Dynamics Shifts
May 29, 2024



Training reinforcement learning policies using environment interaction data collected from varying policies or dynamics presents a fundamental challenge. Existing works often overlook the distribution discrepancies induced by policy or dynamics shifts, or rely on specialized algorithms with task priors, thus often resulting in suboptimal policy performances and high learning variances. In this paper, we identify a unified strategy for online RL policy learning under diverse settings of policy and dynamics shifts: transition occupancy matching. In light of this, we introduce a surrogate policy learning objective by considering the transition occupancy discrepancies and then cast it into a tractable min-max optimization problem through dual reformulation. Our method, dubbed Occupancy-Matching Policy Optimization (OMPO), features a specialized actor-critic structure equipped with a distribution discriminator and a small-size local buffer. We conduct extensive experiments based on the OpenAI Gym, Meta-World, and Panda Robots environments, encompassing policy shifts under stationary and nonstationary dynamics, as well as domain adaption. The results demonstrate that OMPO outperforms the specialized baselines from different categories in all settings. We also find that OMPO exhibits particularly strong performance when combined with domain randomization, highlighting its potential in RL-based robotics applications
Offline-Boosted Actor-Critic: Adaptively Blending Optimal Historical Behaviors in Deep Off-Policy RL
May 28, 2024Off-policy reinforcement learning (RL) has achieved notable success in tackling many complex real-world tasks, by leveraging previously collected data for policy learning. However, most existing off-policy RL algorithms fail to maximally exploit the information in the replay buffer, limiting sample efficiency and policy performance. In this work, we discover that concurrently training an offline RL policy based on the shared online replay buffer can sometimes outperform the original online learning policy, though the occurrence of such performance gains remains uncertain. This motivates a new possibility of harnessing the emergent outperforming offline optimal policy to improve online policy learning. Based on this insight, we present Offline-Boosted Actor-Critic (OBAC), a model-free online RL framework that elegantly identifies the outperforming offline policy through value comparison, and uses it as an adaptive constraint to guarantee stronger policy learning performance. Our experiments demonstrate that OBAC outperforms other popular model-free RL baselines and rivals advanced model-based RL methods in terms of sample efficiency and asymptotic performance across 53 tasks spanning 6 task suites.
Scrutinize What We Ignore: Reining Task Representation Shift In Context-Based Offline Meta Reinforcement Learning
May 20, 2024



Offline meta reinforcement learning (OMRL) has emerged as a promising approach for interaction avoidance and strong generalization performance by leveraging pre-collected data and meta-learning techniques. Previous context-based approaches predominantly rely on the intuition that maximizing the mutual information between the task and the task representation ($I(Z;M)$) can lead to performance improvements. Despite achieving attractive results, the theoretical justification of performance improvement for such intuition has been lacking. Motivated by the return discrepancy scheme in the model-based RL field, we find that maximizing $I(Z;M)$ can be interpreted as consistently raising the lower bound of the expected return for a given policy conditioning on the optimal task representation. However, this optimization process ignores the task representation shift between two consecutive updates, which may lead to performance improvement collapse. To address this problem, we turn to use the framework of performance difference bound to consider the impacts of task representation shift explicitly. We demonstrate that by reining the task representation shift, it is possible to achieve monotonic performance improvements, thereby showcasing the advantage against previous approaches. To make it practical, we design an easy yet highly effective algorithm RETRO (\underline{RE}ining \underline{T}ask \underline{R}epresentation shift in context-based \underline{O}ffline meta reinforcement learning) with only adding one line of code compared to the backbone. Empirical results validate its state-of-the-art (SOTA) asymptotic performance, training stability and training-time consumption on MuJoCo and MetaWorld benchmarks.
ACE : Off-Policy Actor-Critic with Causality-Aware Entropy Regularization
Feb 22, 2024



The varying significance of distinct primitive behaviors during the policy learning process has been overlooked by prior model-free RL algorithms. Leveraging this insight, we explore the causal relationship between different action dimensions and rewards to evaluate the significance of various primitive behaviors during training. We introduce a causality-aware entropy term that effectively identifies and prioritizes actions with high potential impacts for efficient exploration. Furthermore, to prevent excessive focus on specific primitive behaviors, we analyze the gradient dormancy phenomenon and introduce a dormancy-guided reset mechanism to further enhance the efficacy of our method. Our proposed algorithm, ACE: Off-policy Actor-critic with Causality-aware Entropy regularization, demonstrates a substantial performance advantage across 29 diverse continuous control tasks spanning 7 domains compared to model-free RL baselines, which underscores the effectiveness, versatility, and efficient sample efficiency of our approach. Benchmark results and videos are available at https://ace-rl.github.io/.
DrM: Mastering Visual Reinforcement Learning through Dormant Ratio Minimization
Oct 30, 2023Visual reinforcement learning (RL) has shown promise in continuous control tasks. Despite its progress, current algorithms are still unsatisfactory in virtually every aspect of the performance such as sample efficiency, asymptotic performance, and their robustness to the choice of random seeds. In this paper, we identify a major shortcoming in existing visual RL methods that is the agents often exhibit sustained inactivity during early training, thereby limiting their ability to explore effectively. Expanding upon this crucial observation, we additionally unveil a significant correlation between the agents' inclination towards motorically inactive exploration and the absence of neuronal activity within their policy networks. To quantify this inactivity, we adopt dormant ratio as a metric to measure inactivity in the RL agent's network. Empirically, we also recognize that the dormant ratio can act as a standalone indicator of an agent's activity level, regardless of the received reward signals. Leveraging the aforementioned insights, we introduce DrM, a method that uses three core mechanisms to guide agents' exploration-exploitation trade-offs by actively minimizing the dormant ratio. Experiments demonstrate that DrM achieves significant improvements in sample efficiency and asymptotic performance with no broken seeds (76 seeds in total) across three continuous control benchmark environments, including DeepMind Control Suite, MetaWorld, and Adroit. Most importantly, DrM is the first model-free algorithm that consistently solves tasks in both the Dog and Manipulator domains from the DeepMind Control Suite as well as three dexterous hand manipulation tasks without demonstrations in Adroit, all based on pixel observations.
H2O+: An Improved Framework for Hybrid Offline-and-Online RL with Dynamics Gaps
Sep 22, 2023



Solving real-world complex tasks using reinforcement learning (RL) without high-fidelity simulation environments or large amounts of offline data can be quite challenging. Online RL agents trained in imperfect simulation environments can suffer from severe sim-to-real issues. Offline RL approaches although bypass the need for simulators, often pose demanding requirements on the size and quality of the offline datasets. The recently emerged hybrid offline-and-online RL provides an attractive framework that enables joint use of limited offline data and imperfect simulator for transferable policy learning. In this paper, we develop a new algorithm, called H2O+, which offers great flexibility to bridge various choices of offline and online learning methods, while also accounting for dynamics gaps between the real and simulation environment. Through extensive simulation and real-world robotics experiments, we demonstrate superior performance and flexibility over advanced cross-domain online and offline RL algorithms.
Seizing Serendipity: Exploiting the Value of Past Success in Off-Policy Actor-Critic
Jun 06, 2023Learning high-quality Q-value functions plays a key role in the success of many modern off-policy deep reinforcement learning (RL) algorithms. Previous works focus on addressing the value overestimation issue, an outcome of adopting function approximators and off-policy learning. Deviating from the common viewpoint, we observe that Q-values are indeed underestimated in the latter stage of the RL training process, primarily related to the use of inferior actions from the current policy in Bellman updates as compared to the more optimal action samples in the replay buffer. We hypothesize that this long-neglected phenomenon potentially hinders policy learning and reduces sample efficiency. Our insight to address this issue is to incorporate sufficient exploitation of past successes while maintaining exploration optimism. We propose the Blended Exploitation and Exploration (BEE) operator, a simple yet effective approach that updates Q-value using both historical best-performing actions and the current policy. The instantiations of our method in both model-free and model-based settings outperform state-of-the-art methods in various continuous control tasks and achieve strong performance in failure-prone scenarios and real-world robot tasks.
When to Update Your Model: Constrained Model-based Reinforcement Learning
Oct 15, 2022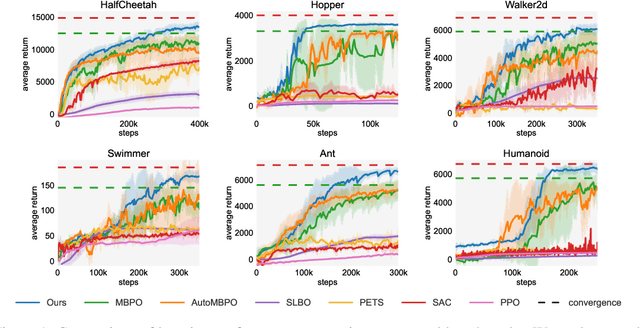

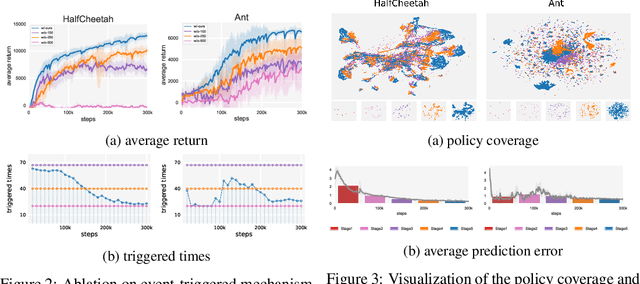
Designing and analyzing model-based RL (MBRL) algorithms with guaranteed monotonic improvement has been challenging, mainly due to the interdependence between policy optimization and model learning. Existing discrepancy bounds generally ignore the impacts of model shifts, and their corresponding algorithms are prone to degrade performance by drastic model updating. In this work, we first propose a novel and general theoretical scheme for a non-decreasing performance guarantee of MBRL. Our follow-up derived bounds reveal the relationship between model shifts and performance improvement. These discoveries encourage us to formulate a constrained lower-bound optimization problem to permit the monotonicity of MBRL. A further example demonstrates that learning models from a dynamically-varying number of explorations benefit the eventual returns. Motivated by these analyses, we design a simple but effective algorithm CMLO (Constrained Model-shift Lower-bound Optimization), by introducing an event-triggered mechanism that flexibly determines when to update the model. Experiments show that CMLO surpasses other state-of-the-art methods and produces a boost when various policy optimization methods are employed.