 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs Your Conditional Diffusion Model Actually Denoising?
Dec 21, 2025We study the inductive biases of diffusion models with a conditioning-variable, which have seen widespread application as both text-conditioned generative image models and observation-conditioned continuous control policies. We observe that when these models are queried conditionally, their generations consistently deviate from the idealized "denoising" process upon which diffusion models are formulated, inducing disagreement between popular sampling algorithms (e.g. DDPM, DDIM). We introduce Schedule Deviation, a rigorous measure which captures the rate of deviation from a standard denoising process, and provide a methodology to compute it. Crucially, we demonstrate that the deviation from an idealized denoising process occurs irrespective of the model capacity or amount of training data. We posit that this phenomenon occurs due to the difficulty of bridging distinct denoising flows across different parts of the conditioning space and show theoretically how such a phenomenon can arise through an inductive bias towards smoothness.
Monitoring Monitorability
Dec 20, 2025



Observability into the decision making of modern AI systems may be required to safely deploy increasingly capable agents. Monitoring the chain-of-thought (CoT) of today's reasoning models has proven effective for detecting misbehavior. However, this "monitorability" may be fragile under different training procedures, data sources, or even continued system scaling. To measure and track monitorability, we propose three evaluation archetypes (intervention, process, and outcome-property) and a new monitorability metric, and introduce a broad evaluation suite. We demonstrate that these evaluations can catch simple model organisms trained to have obfuscated CoTs, and that CoT monitoring is more effective than action-only monitoring in practical settings. We compare the monitorability of various frontier models and find that most models are fairly, but not perfectly, monitorable. We also evaluate how monitorability scales with inference-time compute, reinforcement learning optimization, and pre-training model size. We find that longer CoTs are generally more monitorable and that RL optimization does not materially decrease monitorability even at the current frontier scale. Notably, we find that for a model at a low reasoning effort, we could instead deploy a smaller model at a higher reasoning effort (thereby matching capabilities) and obtain a higher monitorability, albeit at a higher overall inference compute cost. We further investigate agent-monitor scaling trends and find that scaling a weak monitor's test-time compute when monitoring a strong agent increases monitorability. Giving the weak monitor access to CoT not only improves monitorability, but it steepens the monitor's test-time compute to monitorability scaling trend. Finally, we show we can improve monitorability by asking models follow-up questions and giving their follow-up CoT to the monitor.
OpenAI GPT-5 System Card
Dec 19, 2025This is the system card published alongside the OpenAI GPT-5 launch, August 2025. GPT-5 is a unified system with a smart and fast model that answers most questions, a deeper reasoning model for harder problems, and a real-time router that quickly decides which model to use based on conversation type, complexity, tool needs, and explicit intent (for example, if you say 'think hard about this' in the prompt). The router is continuously trained on real signals, including when users switch models, preference rates for responses, and measured correctness, improving over time. Once usage limits are reached, a mini version of each model handles remaining queries. This system card focuses primarily on gpt-5-thinking and gpt-5-main, while evaluations for other models are available in the appendix. The GPT-5 system not only outperforms previous models on benchmarks and answers questions more quickly, but -- more importantly -- is more useful for real-world queries. We've made significant advances in reducing hallucinations, improving instruction following, and minimizing sycophancy, and have leveled up GPT-5's performance in three of ChatGPT's most common uses: writing, coding, and health. All of the GPT-5 models additionally feature safe-completions, our latest approach to safety training to prevent disallowed content. Similarly to ChatGPT agent, we have decided to treat gpt-5-thinking as High capability in the Biological and Chemical domain under our Preparedness Framework, activating the associated safeguards. While we do not have definitive evidence that this model could meaningfully help a novice to create severe biological harm -- our defined threshold for High capability -- we have chosen to take a precautionary approach.
FunDiff: Diffusion Models over Function Spaces for Physics-Informed Generative Modeling
Jun 09, 2025



Recent advances in generative modeling -- particularly diffusion models and flow matching -- have achieved remarkable success in synthesizing discrete data such as images and videos. However, adapting these models to physical applications remains challenging, as the quantities of interest are continuous functions governed by complex physical laws. Here, we introduce $\textbf{FunDiff}$, a novel framework for generative modeling in function spaces. FunDiff combines a latent diffusion process with a function autoencoder architecture to handle input functions with varying discretizations, generate continuous functions evaluable at arbitrary locations, and seamlessly incorporate physical priors. These priors are enforced through architectural constraints or physics-informed loss functions, ensuring that generated samples satisfy fundamental physical laws. We theoretically establish minimax optimality guarantees for density estimation in function spaces, showing that diffusion-based estimators achieve optimal convergence rates under suitable regularity conditions. We demonstrate the practical effectiveness of FunDiff across diverse applications in fluid dynamics and solid mechanics. Empirical results show that our method generates physically consistent samples with high fidelity to the target distribution and exhibits robustness to noisy and low-resolution data. Code and datasets are publicly available at https://github.com/sifanexisted/fundiff.
Monitoring Reasoning Models for Misbehavior and the Risks of Promoting Obfuscation
Mar 14, 2025Mitigating reward hacking--where AI systems misbehave due to flaws or misspecifications in their learning objectives--remains a key challenge in constructing capable and aligned models. We show that we can monitor a frontier reasoning model, such as OpenAI o3-mini, for reward hacking in agentic coding environments by using another LLM that observes the model's chain-of-thought (CoT) reasoning. CoT monitoring can be far more effective than monitoring agent actions and outputs alone, and we further found that a LLM weaker than o3-mini, namely GPT-4o, can effectively monitor a stronger model. Because CoT monitors can be effective at detecting exploits, it is natural to ask whether those exploits can be suppressed by incorporating a CoT monitor directly into the agent's training objective. While we show that integrating CoT monitors into the reinforcement learning reward can indeed produce more capable and more aligned agents in the low optimization regime, we find that with too much optimization, agents learn obfuscated reward hacking, hiding their intent within the CoT while still exhibiting a significant rate of reward hacking. Because it is difficult to tell when CoTs have become obfuscated, it may be necessary to pay a monitorability tax by not applying strong optimization pressures directly to the chain-of-thought, ensuring that CoTs remain monitorable and useful for detecting misaligned behavior.
Think Twice Before You Act: Improving Inverse Problem Solving With MCMC
Sep 13, 2024Recent studies demonstrate that diffusion models can serve as a strong prior for solving inverse problems. A prominent example is Diffusion Posterior Sampling (DPS), which approximates the posterior distribution of data given the measure using Tweedie's formula. Despite the merits of being versatile in solving various inverse problems without re-training, the performance of DPS is hindered by the fact that this posterior approximation can be inaccurate especially for high noise levels. Therefore, we propose \textbf{D}iffusion \textbf{P}osterior \textbf{MC}MC (\textbf{DPMC}), a novel inference algorithm based on Annealed MCMC to solve inverse problems with pretrained diffusion models. We define a series of intermediate distributions inspired by the approximated conditional distributions used by DPS. Through annealed MCMC sampling, we encourage the samples to follow each intermediate distribution more closely before moving to the next distribution at a lower noise level, and therefore reduce the accumulated error along the path. We test our algorithm in various inverse problems, including super resolution, Gaussian deblurring, motion deblurring, inpainting, and phase retrieval. Our algorithm outperforms DPS with less number of evaluations across nearly all tasks, and is competitive among existing approaches.
From optimal score matching to optimal sampling
Sep 11, 2024
The recent, impressive advances in algorithmic generation of high-fidelity image, audio, and video are largely due to great successes in score-based diffusion models. A key implementing step is score matching, that is, the estimation of the score function of the forward diffusion process from training data. As shown in earlier literature, the total variation distance between the law of a sample generated from the trained diffusion model and the ground truth distribution can be controlled by the score matching risk. Despite the widespread use of score-based diffusion models, basic theoretical questions concerning exact optimal statistical rates for score estimation and its application to density estimation remain open. We establish the sharp minimax rate of score estimation for smooth, compactly supported densities. Formally, given \(n\) i.i.d. samples from an unknown \(\alpha\)-H\"{o}lder density \(f\) supported on \([-1, 1]\), we prove the minimax rate of estimating the score function of the diffused distribution \(f * \mathcal{N}(0, t)\) with respect to the score matching loss is \(\frac{1}{nt^2} \wedge \frac{1}{nt^{3/2}} \wedge (t^{\alpha-1} + n^{-2(\alpha-1)/(2\alpha+1)})\) for all \(\alpha > 0\) and \(t \ge 0\). As a consequence, it is shown the law \(\hat{f}\) of a sample generated from the diffusion model achieves the sharp minimax rate \(\bE(\dTV(\hat{f}, f)^2) \lesssim n^{-2\alpha/(2\alpha+1)}\) for all \(\alpha > 0\) without any extraneous logarithmic terms which are prevalent in the literature, and without the need for early stopping which has been required for all existing procedures to the best of our knowledge.
Diffusion Transformer Captures Spatial-Temporal Dependencies: A Theory for Gaussian Process Data
Jul 23, 2024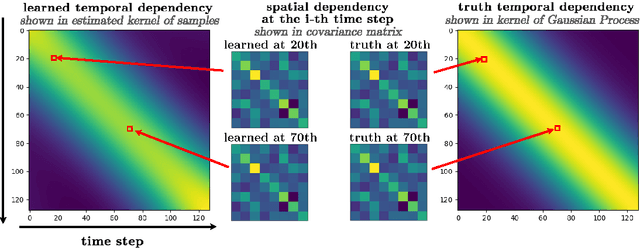
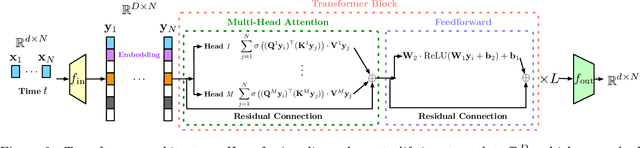

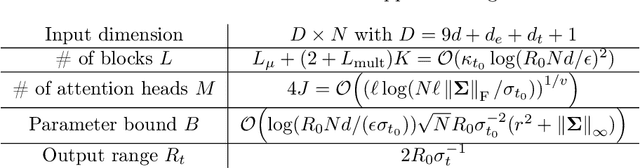
Diffusion Transformer, the backbone of Sora for video generation, successfully scales the capacity of diffusion models, pioneering new avenues for high-fidelity sequential data generation. Unlike static data such as images, sequential data consists of consecutive data frames indexed by time, exhibiting rich spatial and temporal dependencies. These dependencies represent the underlying dynamic model and are critical to validate the generated data. In this paper, we make the first theoretical step towards bridging diffusion transformers for capturing spatial-temporal dependencies. Specifically, we establish score approximation and distribution estimation guarantees of diffusion transformers for learning Gaussian process data with covariance functions of various decay patterns. We highlight how the spatial-temporal dependencies are captured and affect learning efficiency. Our study proposes a novel transformer approximation theory, where the transformer acts to unroll an algorithm. We support our theoretical results by numerical experiments, providing strong evidence that spatial-temporal dependencies are captured within attention layers, aligning with our approximation theory.
Provable Statistical Rates for Consistency Diffusion Models
Jun 23, 2024Diffusion models have revolutionized various application domains, including computer vision and audio generation. Despite the state-of-the-art performance, diffusion models are known for their slow sample generation due to the extensive number of steps involved. In response, consistency models have been developed to merge multiple steps in the sampling process, thereby significantly boosting the speed of sample generation without compromising quality. This paper contributes towards the first statistical theory for consistency models, formulating their training as a distribution discrepancy minimization problem. Our analysis yields statistical estimation rates based on the Wasserstein distance for consistency models, matching those of vanilla diffusion models. Additionally, our results encompass the training of consistency models through both distillation and isolation methods, demystifying their underlying advantage.
Learning Narrow One-Hidden-Layer ReLU Networks
Apr 20, 2023

We consider the well-studied problem of learning a linear combination of $k$ ReLU activations with respect to a Gaussian distribution on inputs in $d$ dimensions. We give the first polynomial-time algorithm that succeeds whenever $k$ is a constant. All prior polynomial-time learners require additional assumptions on the network, such as positive combining coefficients or the matrix of hidden weight vectors being well-conditioned. Our approach is based on analyzing random contractions of higher-order moment tensors. We use a multi-scale analysis to argue that sufficiently close neurons can be collapsed together, sidestepping the conditioning issues present in prior work. This allows us to design an iterative procedure to discover individual neurons.