 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeft-Right Comparative Recurrent Model for Stereo Matching
Apr 03, 2018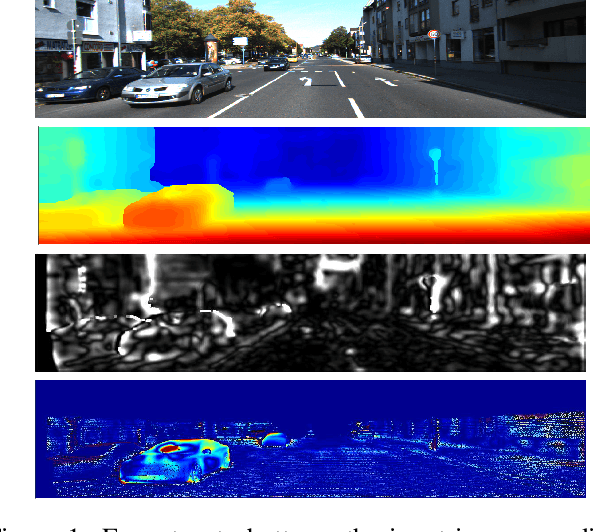
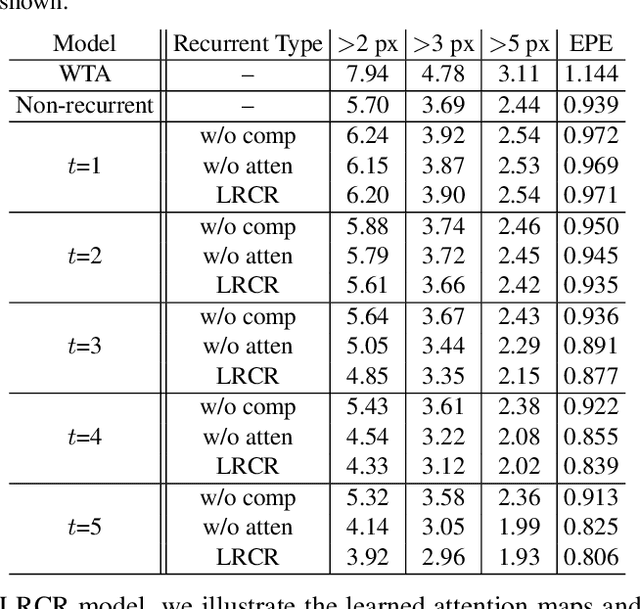
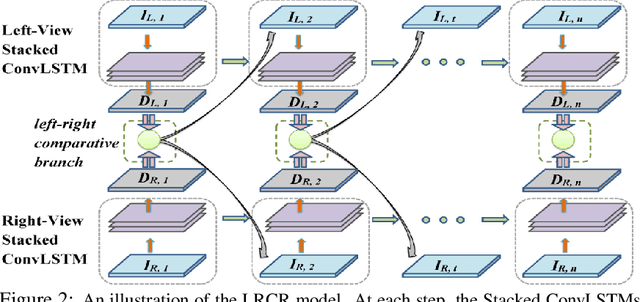
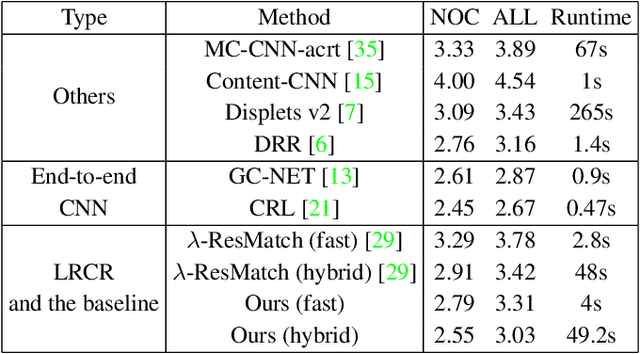
Leveraging the disparity information from both left and right views is crucial for stereo disparity estimation. Left-right consistency check is an effective way to enhance the disparity estimation by referring to the information from the opposite view. However, the conventional left-right consistency check is an isolated post-processing step and heavily hand-crafted. This paper proposes a novel left-right comparative recurrent model to perform left-right consistency checking jointly with disparity estimation. At each recurrent step, the model produces disparity results for both views, and then performs online left-right comparison to identify the mismatched regions which may probably contain erroneously labeled pixels. A soft attention mechanism is introduced, which employs the learned error maps for better guiding the model to selectively focus on refining the unreliable regions at the next recurrent step. In this way, the generated disparity maps are progressively improved by the proposed recurrent model. Extensive evaluations on KITTI 2015, Scene Flow and Middlebury benchmarks validate the effectiveness of our model, demonstrating that state-of-the-art stereo disparity estimation results can be achieved by this new model.
Multiple-Human Parsing in the Wild
Mar 15, 2018

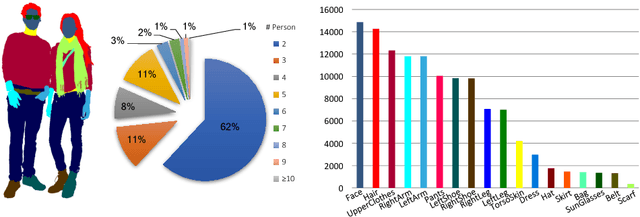
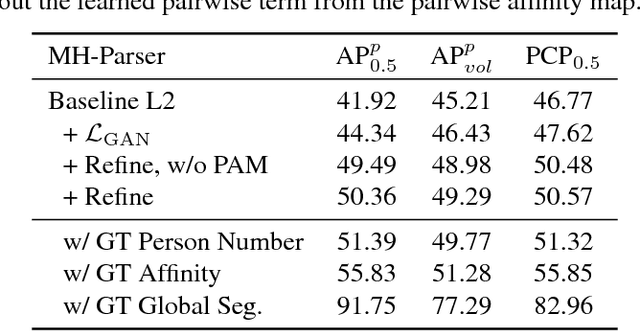
Human parsing is attracting increasing research attention. In this work, we aim to push the frontier of human parsing by introducing the problem of multi-human parsing in the wild. Existing works on human parsing mainly tackle single-person scenarios, which deviates from real-world applications where multiple persons are present simultaneously with interaction and occlusion. To address the multi-human parsing problem, we introduce a new multi-human parsing (MHP) dataset and a novel multi-human parsing model named MH-Parser. The MHP dataset contains multiple persons captured in real-world scenes with pixel-level fine-grained semantic annotations in an instance-aware setting. The MH-Parser generates global parsing maps and person instance masks simultaneously in a bottom-up fashion with the help of a new Graph-GAN model. We envision that the MHP dataset will serve as a valuable data resource to develop new multi-human parsing models, and the MH-Parser offers a strong baseline to drive future research for multi-human parsing in the wild.
A Good Practice Towards Top Performance of Face Recognition: Transferred Deep Feature Fusion
Feb 09, 2018
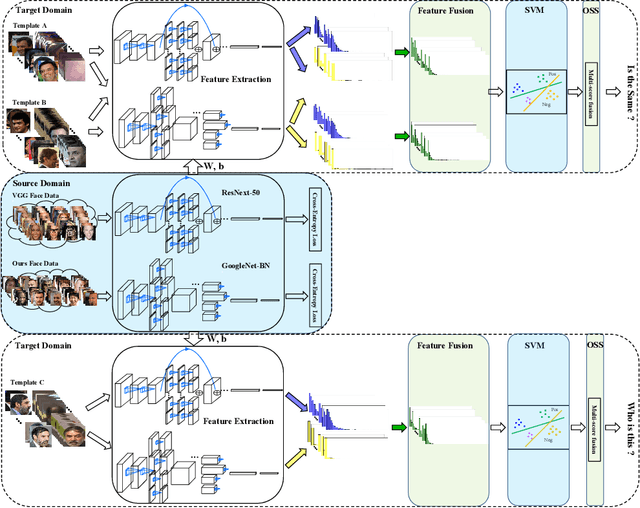
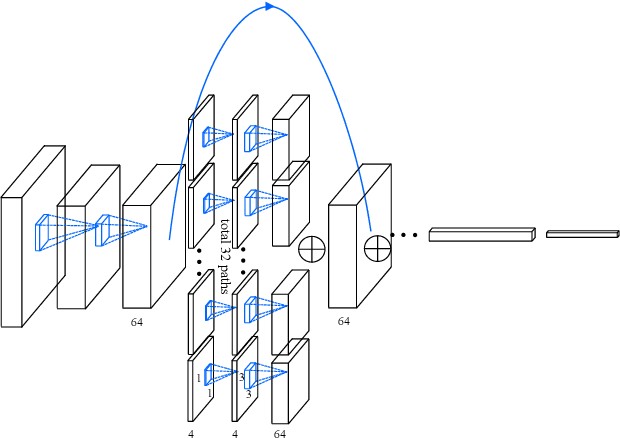
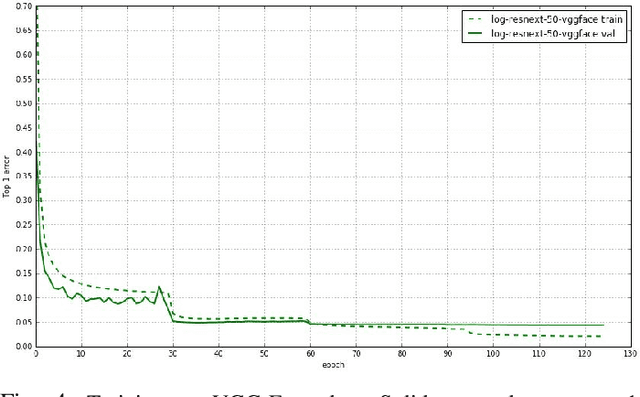
Unconstrained face recognition performance evaluations have traditionally focused on Labeled Faces in the Wild (LFW) dataset for imagery and the YouTubeFaces (YTF) dataset for videos in the last couple of years. Spectacular progress in this field has resulted in saturation on verification and identification accuracies for those benchmark datasets. In this paper, we propose a unified learning framework named Transferred Deep Feature Fusion (TDFF) targeting at the new IARPA Janus Benchmark A (IJB-A) face recognition dataset released by NIST face challenge. The IJB-A dataset includes real-world unconstrained faces from 500 subjects with full pose and illumination variations which are much harder than the LFW and YTF datasets. Inspired by transfer learning, we train two advanced deep convolutional neural networks (DCNN) with two different large datasets in source domain, respectively. By exploring the complementarity of two distinct DCNNs, deep feature fusion is utilized after feature extraction in target domain. Then, template specific linear SVMs is adopted to enhance the discrimination of framework. Finally, multiple matching scores corresponding different templates are merged as the final results. This simple unified framework exhibits excellent performance on IJB-A dataset. Based on the proposed approach, we have submitted our IJB-A results to National Institute of Standards and Technology (NIST) for official evaluation. Moreover, by introducing new data and advanced neural architecture, our method outperforms the state-of-the-art by a wide margin on IJB-A dataset.
Stochastic Primal-Dual Proximal ExtraGradient Descent for Compositely Regularized Optimization
Feb 01, 2018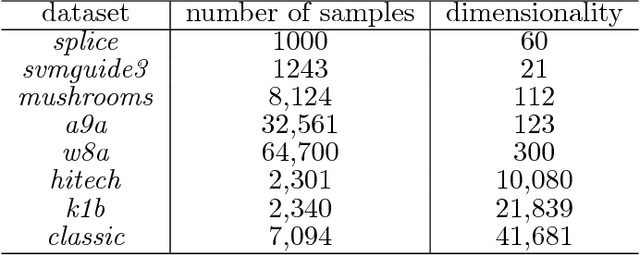
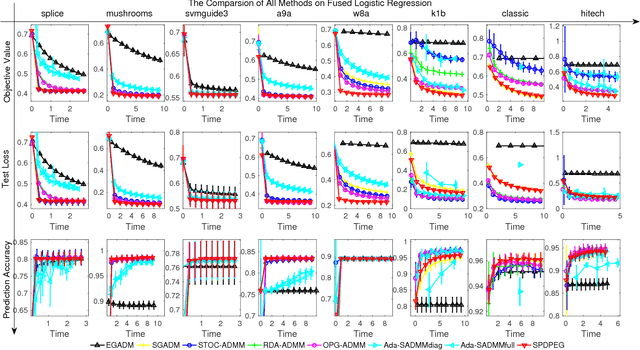
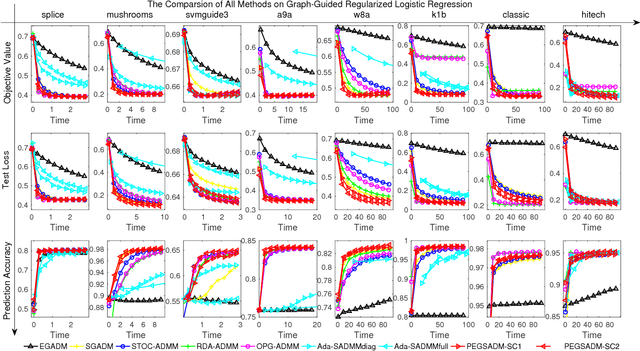
We consider a wide range of regularized stochastic minimization problems with two regularization terms, one of which is composed with a linear function. This optimization model abstracts a number of important applications in artificial intelligence and machine learning, such as fused Lasso, fused logistic regression, and a class of graph-guided regularized minimization. The computational challenges of this model are in two folds. On one hand, the closed-form solution of the proximal mapping associated with the composed regularization term or the expected objective function is not available. On the other hand, the calculation of the full gradient of the expectation in the objective is very expensive when the number of input data samples is considerably large. To address these issues, we propose a stochastic variant of extra-gradient type methods, namely \textsf{Stochastic Primal-Dual Proximal ExtraGradient descent (SPDPEG)}, and analyze its convergence property for both convex and strongly convex objectives. For general convex objectives, the uniformly average iterates generated by \textsf{SPDPEG} converge in expectation with $O(1/\sqrt{t})$ rate. While for strongly convex objectives, the uniformly and non-uniformly average iterates generated by \textsf{SPDPEG} converge with $O(\log(t)/t)$ and $O(1/t)$ rates, respectively. The order of the rate of the proposed algorithm is known to match the best convergence rate for first-order stochastic algorithms. Experiments on fused logistic regression and graph-guided regularized logistic regression problems show that the proposed algorithm performs very efficiently and consistently outperforms other competing algorithms.
Cross-domain Human Parsing via Adversarial Feature and Label Adaptation
Jan 08, 2018
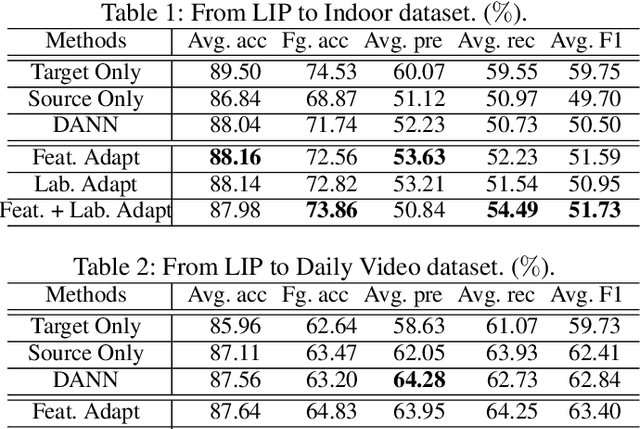
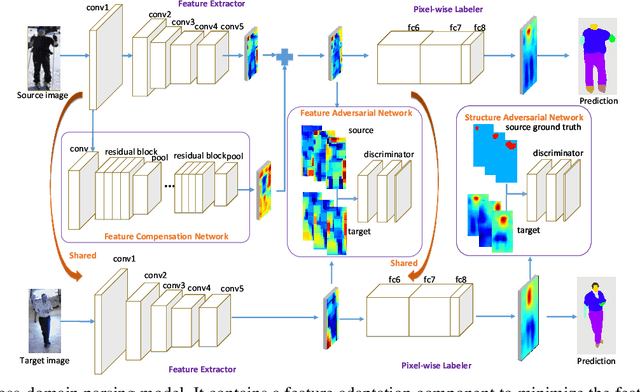

Human parsing has been extensively studied recently due to its wide applications in many important scenarios. Mainstream fashion parsing models focus on parsing the high-resolution and clean images. However, directly applying the parsers trained on benchmarks to a particular application scenario in the wild, e.g., a canteen, airport or workplace, often gives non-satisfactory performance due to domain shift. In this paper, we explore a new and challenging cross-domain human parsing problem: taking the benchmark dataset with extensive pixel-wise labeling as the source domain, how to obtain a satisfactory parser on a new target domain without requiring any additional manual labeling? To this end, we propose a novel and efficient cross-domain human parsing model to bridge the cross-domain differences in terms of visual appearance and environment conditions and fully exploit commonalities across domains. Our proposed model explicitly learns a feature compensation network, which is specialized for mitigating the cross-domain differences. A discriminative feature adversarial network is introduced to supervise the feature compensation to effectively reduce the discrepancy between feature distributions of two domains. Besides, our model also introduces a structured label adversarial network to guide the parsing results of the target domain to follow the high-order relationships of the structured labels shared across domains. The proposed framework is end-to-end trainable, practical and scalable in real applications. Extensive experiments are conducted where LIP dataset is the source domain and 4 different datasets including surveillance videos, movies and runway shows are evaluated as target domains. The results consistently confirm data efficiency and performance advantages of the proposed method for the cross-domain human parsing problem.
Weaving Multi-scale Context for Single Shot Detector
Dec 08, 2017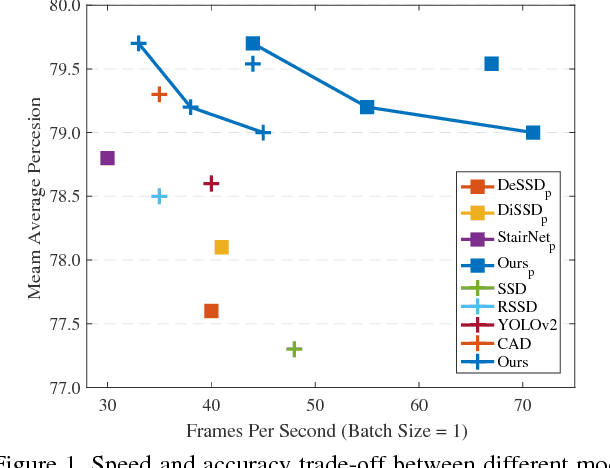

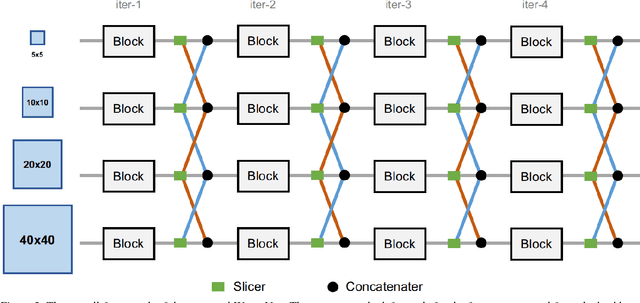
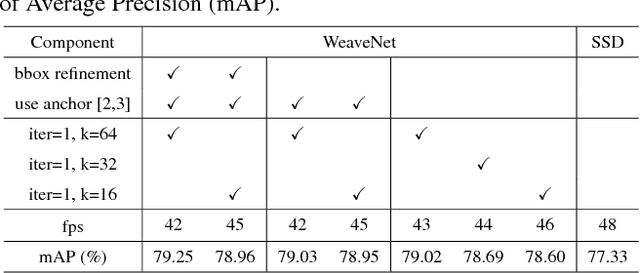
Aggregating context information from multiple scales has been proved to be effective for improving accuracy of Single Shot Detectors (SSDs) on object detection. However, existing multi-scale context fusion techniques are computationally expensive, which unfavorably diminishes the advantageous speed of SSD. In this work, we propose a novel network topology, called WeaveNet, that can efficiently fuse multi-scale information and boost the detection accuracy with negligible extra cost. The proposed WeaveNet iteratively weaves context information from adjacent scales together to enable more sophisticated context reasoning while maintaining fast speed. Built by stacking light-weight blocks, WeaveNet is easy to train without requiring batch normalization and can be further accelerated by our proposed architecture simplification. Experimental results on PASCAL VOC 2007, PASCAL VOC 2012 benchmarks show signification performance boost brought by WeaveNet. For 320x320 input of batch size = 8, WeaveNet reaches 79.5% mAP on PASCAL VOC 2007 test in 101 fps with only 4 fps extra cost, and further improves to 79.7% mAP with more iterations.
Nonconvex Sparse Spectral Clustering by Alternating Direction Method of Multipliers and Its Convergence Analysis
Dec 08, 2017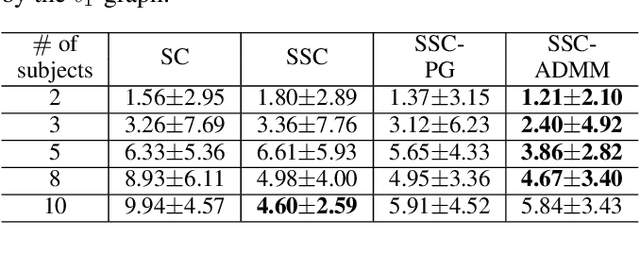
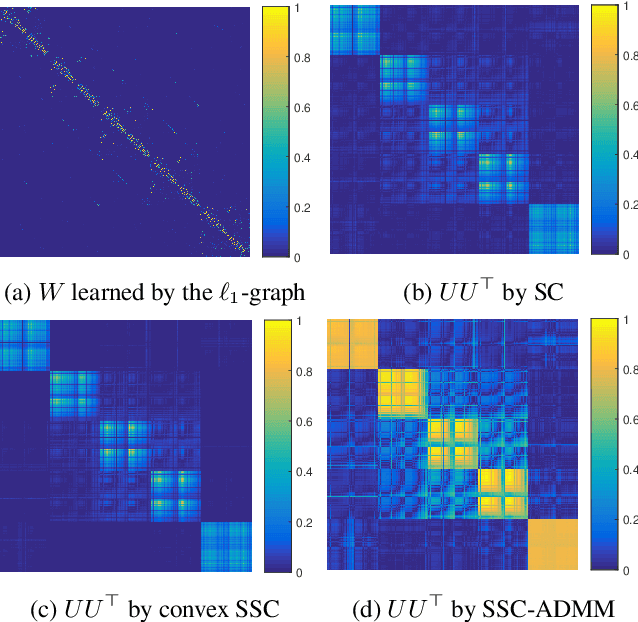
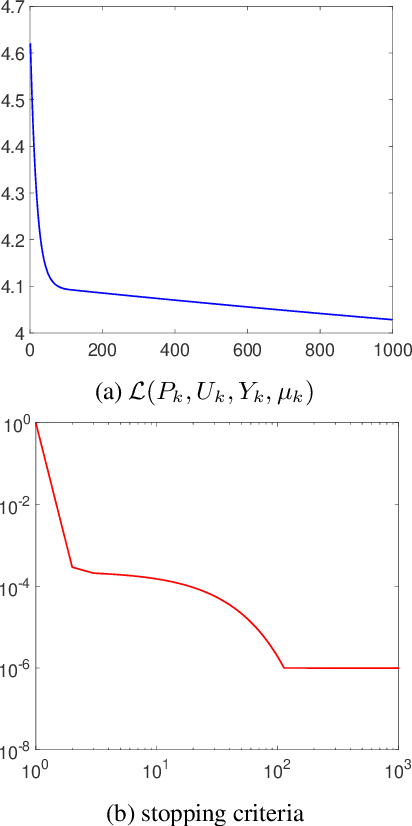

Spectral Clustering (SC) is a widely used data clustering method which first learns a low-dimensional embedding $U$ of data by computing the eigenvectors of the normalized Laplacian matrix, and then performs k-means on $U^\top$ to get the final clustering result. The Sparse Spectral Clustering (SSC) method extends SC with a sparse regularization on $UU^\top$ by using the block diagonal structure prior of $UU^\top$ in the ideal case. However, encouraging $UU^\top$ to be sparse leads to a heavily nonconvex problem which is challenging to solve and the work (Lu, Yan, and Lin 2016) proposes a convex relaxation in the pursuit of this aim indirectly. However, the convex relaxation generally leads to a loose approximation and the quality of the solution is not clear. This work instead considers to solve the nonconvex formulation of SSC which directly encourages $UU^\top$ to be sparse. We propose an efficient Alternating Direction Method of Multipliers (ADMM) to solve the nonconvex SSC and provide the convergence guarantee. In particular, we prove that the sequences generated by ADMM always exist a limit point and any limit point is a stationary point. Our analysis does not impose any assumptions on the iterates and thus is practical. Our proposed ADMM for nonconvex problems allows the stepsize to be increasing but upper bounded, and this makes it very efficient in practice. Experimental analysis on several real data sets verifies the effectiveness of our method.
Personalized and Occupational-aware Age Progression by Generative Adversarial Networks
Dec 01, 2017
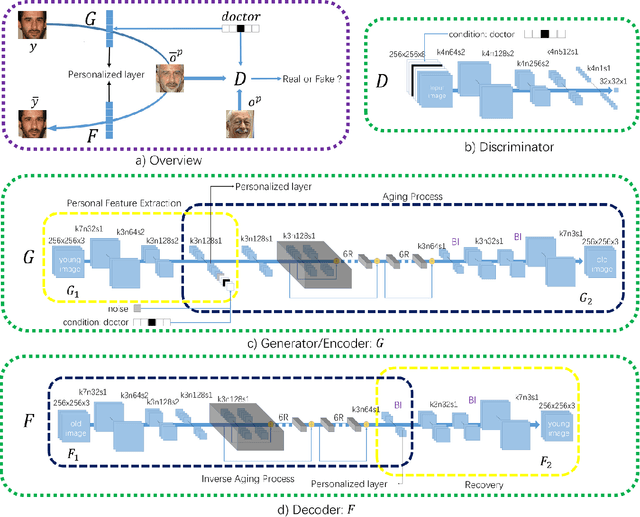
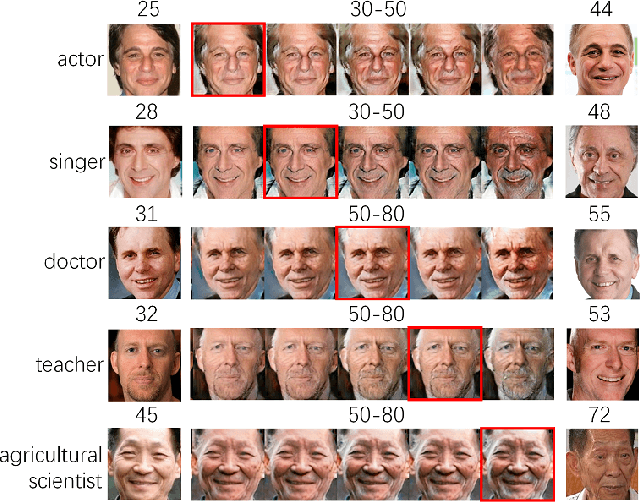

Face age progression, which aims to predict the future looks, is important for various applications and has been received considerable attentions. Existing methods and datasets are limited in exploring the effects of occupations which may influence the personal appearances. In this paper, we firstly introduce an occupational face aging dataset for studying the influences of occupations on the appearances. It includes five occupations, which enables the development of new algorithms for age progression and facilitate future researches. Second, we propose a new occupational-aware adversarial face aging network, which learns human aging process under different occupations. Two factors are taken into consideration in our aging process: personality-preserving and visually plausible texture change for different occupations. We propose personalized network with personalized loss in deep autoencoder network for keeping personalized facial characteristics, and occupational-aware adversarial network with occupational-aware adversarial loss for obtaining more realistic texture changes. Experimental results well demonstrate the advantages of the proposed method by comparing with other state-of-the-arts age progression methods.
Generative Partition Networks for Multi-Person Pose Estimation
Nov 28, 2017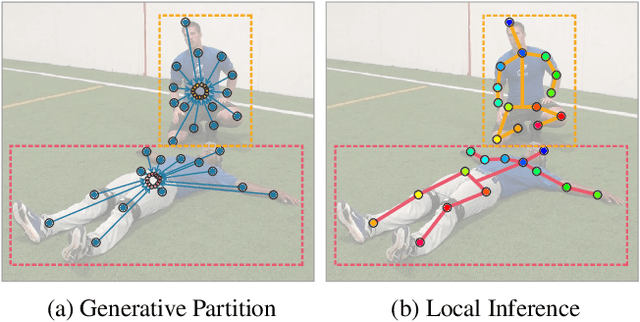
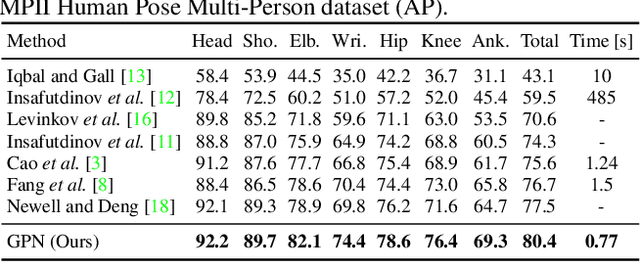
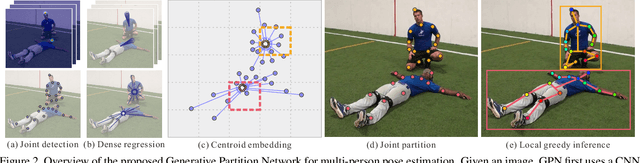
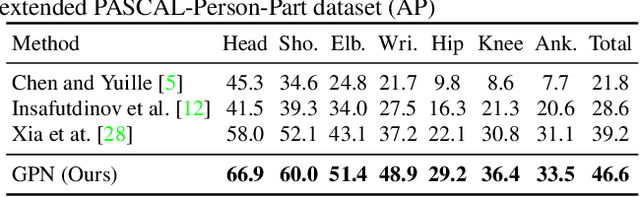
This paper proposes a new Generative Partition Network (GPN) to address the challenging multi-person pose estimation problem. Different from existing models that are either completely top-down or bottom-up, the proposed GPN introduces a novel strategy--it generates partitions for multiple persons from their global joint candidates and infers instance-specific joint configurations simultaneously. The GPN is favorably featured by low complexity and high accuracy of joint detection and re-organization. In particular, GPN designs a generative model that performs one feed-forward pass to efficiently generate robust person detections with joint partitions, relying on dense regressions from global joint candidates in an embedding space parameterized by centroids of persons. In addition, GPN formulates the inference procedure for joint configurations of human poses as a graph partition problem, and conducts local optimization for each person detection with reliable global affinity cues, leading to complexity reduction and performance improvement. GPN is implemented with the Hourglass architecture as the backbone network to simultaneously learn joint detector and dense regressor. Extensive experiments on benchmarks MPII Human Pose Multi-Person, extended PASCAL-Person-Part, and WAF, show the efficiency of GPN with new state-of-the-art performance.
HashGAN:Attention-aware Deep Adversarial Hashing for Cross Modal Retrieval
Nov 26, 2017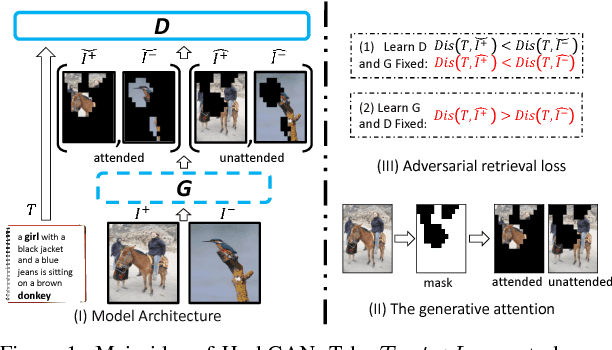
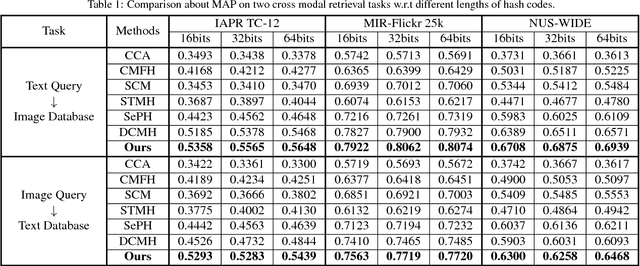
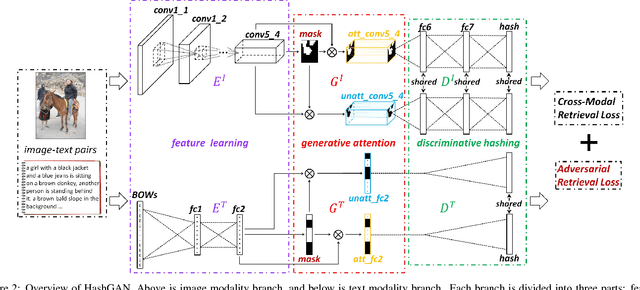
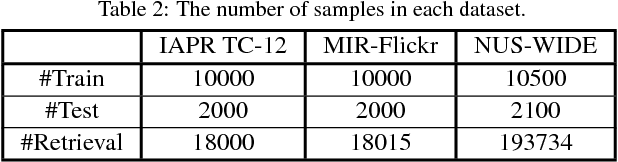
As the rapid growth of multi-modal data, hashing methods for cross-modal retrieval have received considerable attention. Deep-networks-based cross-modal hashing methods are appealing as they can integrate feature learning and hash coding into end-to-end trainable frameworks. However, it is still challenging to find content similarities between different modalities of data due to the heterogeneity gap. To further address this problem, we propose an adversarial hashing network with attention mechanism to enhance the measurement of content similarities by selectively focusing on informative parts of multi-modal data. The proposed new adversarial network, HashGAN, consists of three building blocks: 1) the feature learning module to obtain feature representations, 2) the generative attention module to generate an attention mask, which is used to obtain the attended (foreground) and the unattended (background) feature representations, 3) the discriminative hash coding module to learn hash functions that preserve the similarities between different modalities. In our framework, the generative module and the discriminative module are trained in an adversarial way: the generator is learned to make the discriminator cannot preserve the similarities of multi-modal data w.r.t. the background feature representations, while the discriminator aims to preserve the similarities of multi-modal data w.r.t. both the foreground and the background feature representations. Extensive evaluations on several benchmark datasets demonstrate that the proposed HashGAN brings substantial improvements over other state-of-the-art cross-modal hashing methods.