 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoordinate Attention for Efficient Mobile Network Design
Mar 04, 2021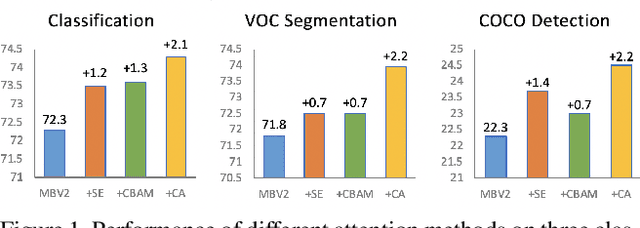
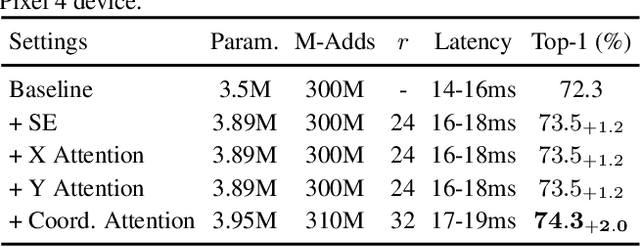
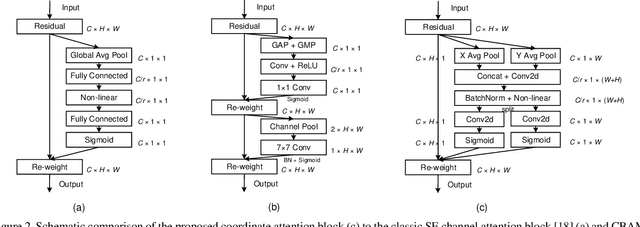
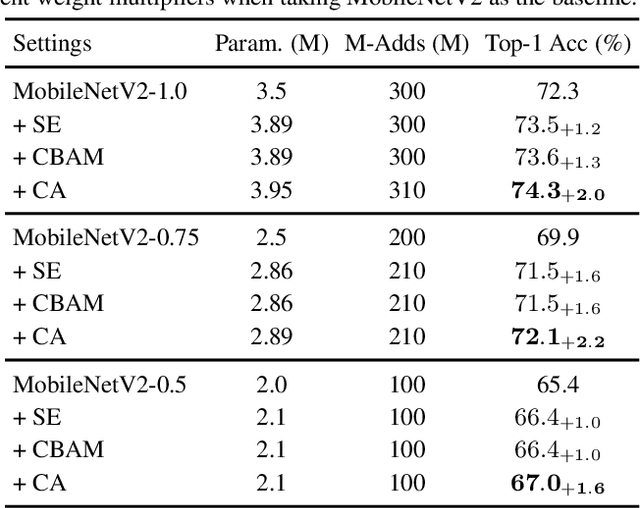
Recent studies on mobile network design have demonstrated the remarkable effectiveness of channel attention (e.g., the Squeeze-and-Excitation attention) for lifting model performance, but they generally neglect the positional information, which is important for generating spatially selective attention maps. In this paper, we propose a novel attention mechanism for mobile networks by embedding positional information into channel attention, which we call "coordinate attention". Unlike channel attention that transforms a feature tensor to a single feature vector via 2D global pooling, the coordinate attention factorizes channel attention into two 1D feature encoding processes that aggregate features along the two spatial directions, respectively. In this way, long-range dependencies can be captured along one spatial direction and meanwhile precise positional information can be preserved along the other spatial direction. The resulting feature maps are then encoded separately into a pair of direction-aware and position-sensitive attention maps that can be complementarily applied to the input feature map to augment the representations of the objects of interest. Our coordinate attention is simple and can be flexibly plugged into classic mobile networks, such as MobileNetV2, MobileNeXt, and EfficientNet with nearly no computational overhead. Extensive experiments demonstrate that our coordinate attention is not only beneficial to ImageNet classification but more interestingly, behaves better in down-stream tasks, such as object detection and semantic segmentation. Code is available at https://github.com/Andrew-Qibin/CoordAttention.
Unleashing the Power of Contrastive Self-Supervised Visual Models via Contrast-Regularized Fine-Tuning
Feb 12, 2021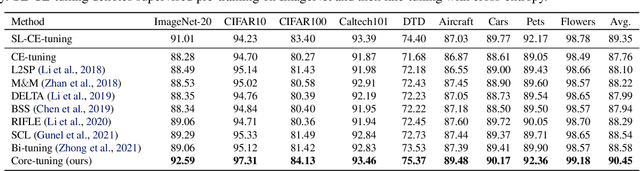
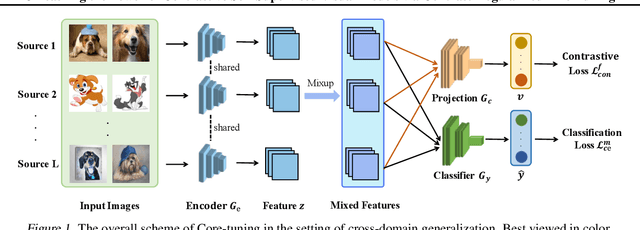
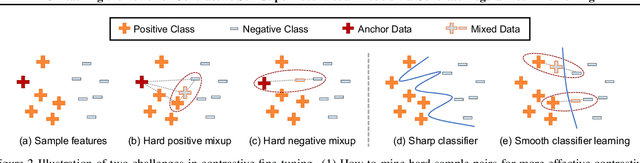

Contrastive self-supervised learning (CSL) leverages unlabeled data to train models that provide instance-discriminative visual representations uniformly scattered in the feature space. In deployment, the common practice is to directly fine-tune models with the cross-entropy loss, which however may not be an optimal strategy. Although cross-entropy tends to separate inter-class features, the resulted models still have limited capability of reducing intra-class feature scattering that inherits from pre-training, and thus may suffer unsatisfactory performance on downstream tasks. In this paper, we investigate whether applying contrastive learning to fine-tuning would bring further benefits, and analytically find that optimizing the supervised contrastive loss benefits both class-discriminative representation learning and model optimization during fine-tuning. Inspired by these findings, we propose Contrast-regularized tuning (Core-tuning), a novel approach for fine-tuning contrastive self-supervised visual models. Instead of simply adding the contrastive loss to the objective of fine-tuning, Core-tuning also generates hard sample pairs for more effective contrastive learning through a novel feature mixup strategy, as well as improves the generalizability of the model by smoothing the decision boundary via mixed samples. Extensive experiments on image classification and semantic segmentation verify the effectiveness of Core-tuning.
CIFS: Improving Adversarial Robustness of CNNs via Channel-wise Importance-based Feature Selection
Feb 10, 2021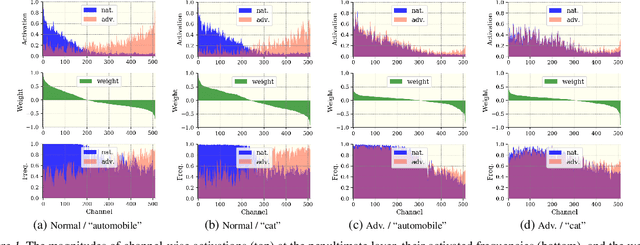
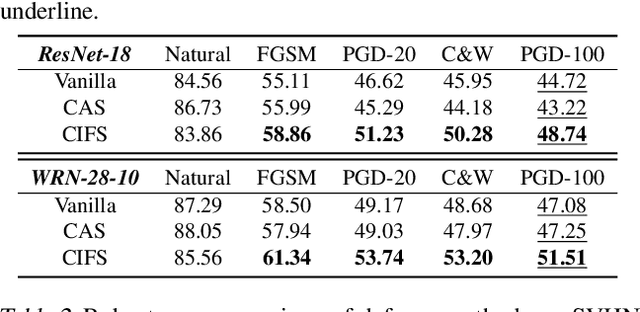
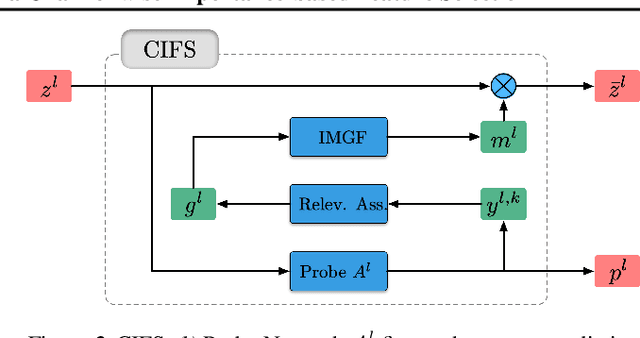
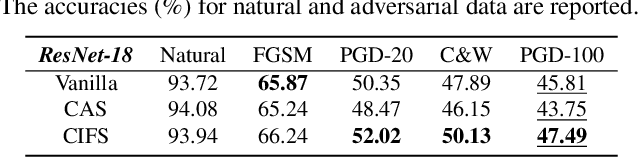
We investigate the adversarial robustness of CNNs from the perspective of channel-wise activations. By comparing \textit{non-robust} (normally trained) and \textit{robustified} (adversarially trained) models, we observe that adversarial training (AT) robustifies CNNs by aligning the channel-wise activations of adversarial data with those of their natural counterparts. However, the channels that are \textit{negatively-relevant} (NR) to predictions are still over-activated when processing adversarial data. Besides, we also observe that AT does not result in similar robustness for all classes. For the robust classes, channels with larger activation magnitudes are usually more \textit{positively-relevant} (PR) to predictions, but this alignment does not hold for the non-robust classes. Given these observations, we hypothesize that suppressing NR channels and aligning PR ones with their relevances further enhances the robustness of CNNs under AT. To examine this hypothesis, we introduce a novel mechanism, i.e., \underline{C}hannel-wise \underline{I}mportance-based \underline{F}eature \underline{S}election (CIFS). The CIFS manipulates channels' activations of certain layers by generating non-negative multipliers to these channels based on their relevances to predictions. Extensive experiments on benchmark datasets including CIFAR10 and SVHN clearly verify the hypothesis and CIFS's effectiveness of robustifying CNNs.
Tokens-to-Token ViT: Training Vision Transformers from Scratch on ImageNet
Jan 28, 2021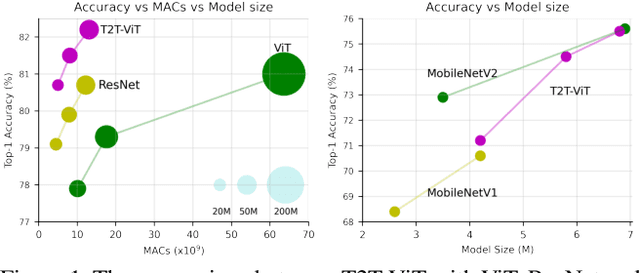
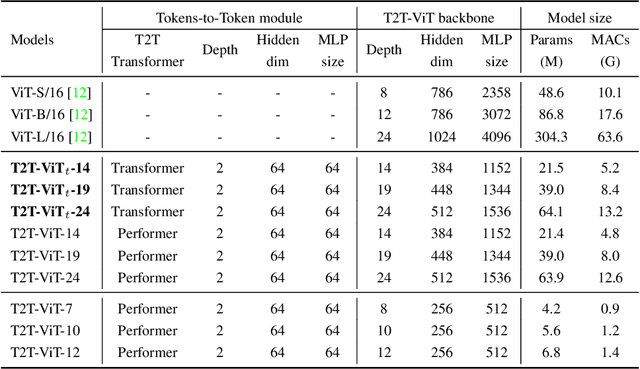

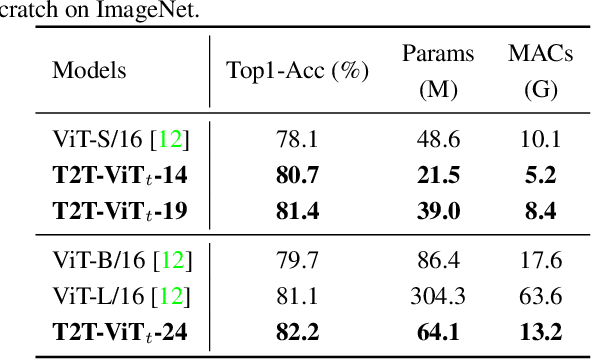
Transformers, which are popular for language modeling, have been explored for solving vision tasks recently, e.g., the Vision Transformers (ViT) for image classification. The ViT model splits each image into a sequence of tokens with fixed length and then applies multiple Transformer layers to model their global relation for classification. However, ViT achieves inferior performance compared with CNNs when trained from scratch on a midsize dataset (e.g., ImageNet). We find it is because: 1) the simple tokenization of input images fails to model the important local structure (e.g., edges, lines) among neighboring pixels, leading to its low training sample efficiency; 2) the redundant attention backbone design of ViT leads to limited feature richness in fixed computation budgets and limited training samples. To overcome such limitations, we propose a new Tokens-To-Token Vision Transformers (T2T-ViT), which introduces 1) a layer-wise Tokens-to-Token (T2T) transformation to progressively structurize the image to tokens by recursively aggregating neighboring Tokens into one Token (Tokens-to-Token), such that local structure presented by surrounding tokens can be modeled and tokens length can be reduced; 2) an efficient backbone with a deep-narrow structure for vision transformers motivated by CNN architecture design after extensive study. Notably, T2T-ViT reduces the parameter counts and MACs of vanilla ViT by 200\%, while achieving more than 2.5\% improvement when trained from scratch on ImageNet. It also outperforms ResNets and achieves comparable performance with MobileNets when directly training on ImageNet. For example, T2T-ViT with ResNet50 comparable size can achieve 80.7\% top-1 accuracy on ImageNet. (Code: https://github.com/yitu-opensource/T2T-ViT)
ORDNet: Capturing Omni-Range Dependencies for Scene Parsing
Jan 11, 2021
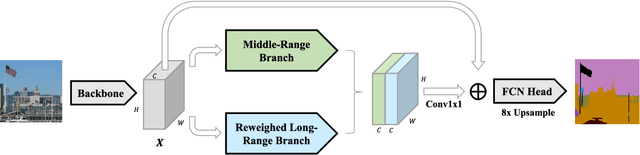
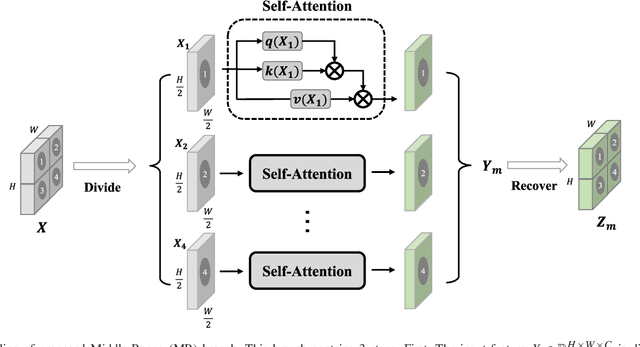
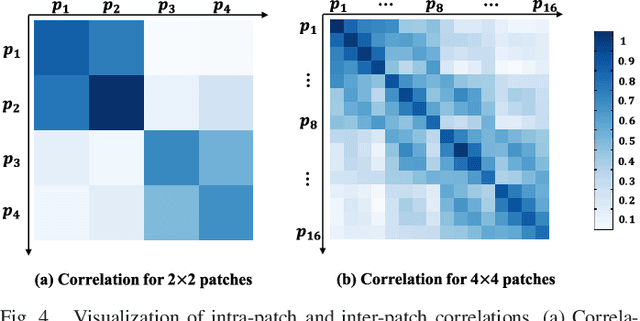
Learning to capture dependencies between spatial positions is essential to many visual tasks, especially the dense labeling problems like scene parsing. Existing methods can effectively capture long-range dependencies with self-attention mechanism while short ones by local convolution. However, there is still much gap between long-range and short-range dependencies, which largely reduces the models' flexibility in application to diverse spatial scales and relationships in complicated natural scene images. To fill such a gap, we develop a Middle-Range (MR) branch to capture middle-range dependencies by restricting self-attention into local patches. Also, we observe that the spatial regions which have large correlations with others can be emphasized to exploit long-range dependencies more accurately, and thus propose a Reweighed Long-Range (RLR) branch. Based on the proposed MR and RLR branches, we build an Omni-Range Dependencies Network (ORDNet) which can effectively capture short-, middle- and long-range dependencies. Our ORDNet is able to extract more comprehensive context information and well adapt to complex spatial variance in scene images. Extensive experiments show that our proposed ORDNet outperforms previous state-of-the-art methods on three scene parsing benchmarks including PASCAL Context, COCO Stuff and ADE20K, demonstrating the superiority of capturing omni-range dependencies in deep models for scene parsing task.
* Published at TIP
Source Data-absent Unsupervised Domain Adaptation through Hypothesis Transfer and Labeling Transfer
Dec 14, 2020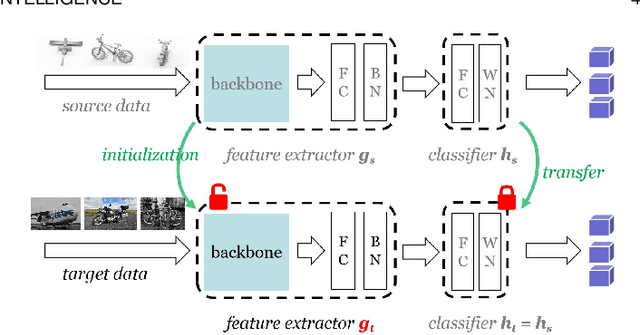
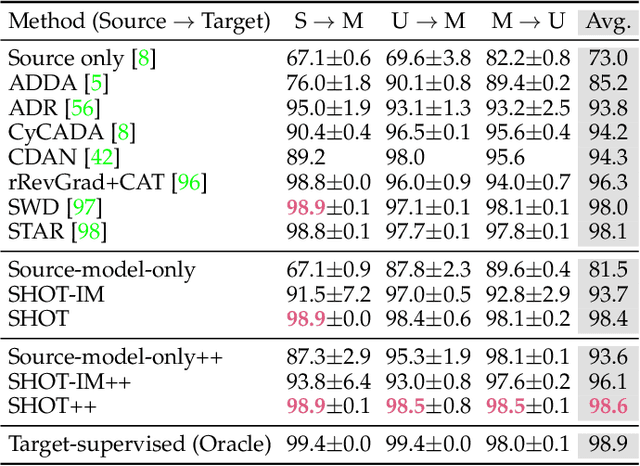
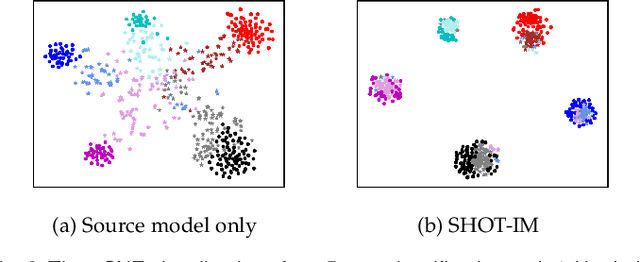
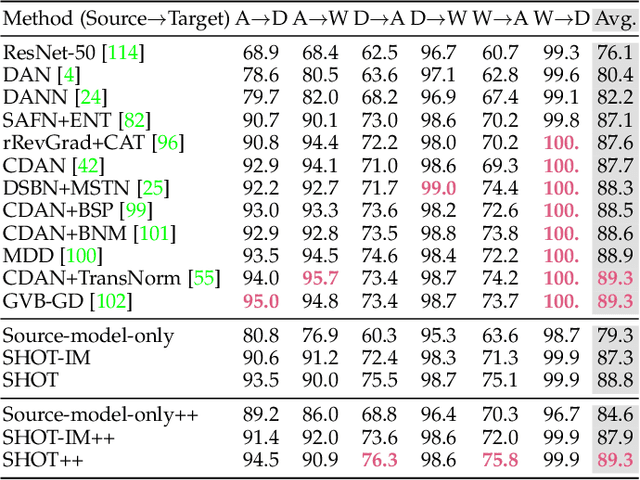
Unsupervised domain adaptation (UDA) aims to transfer knowledge from a related but different well-labeled source domain to a new unlabeled target domain. Most existing UDA methods require access to the source data, and thus are not applicable when the data are confidential and not shareable due to privacy concerns. This paper aims to tackle a realistic setting with only a classification model available trained over, instead of accessing to, the source data. To effectively utilize the source model for adaptation, we propose a novel approach called Source HypOthesis Transfer (SHOT), which learns the feature extraction module for the target domain by fitting the target data features to the frozen source classification module (representing classification hypothesis). Specifically, SHOT exploits both information maximization and self-supervised learning for the feature extraction module learning to ensure the target features are implicitly aligned with the features of unseen source data via the same hypothesis. Furthermore, we propose a new labeling transfer strategy, which separates the target data into two splits based on the confidence of predictions (labeling information), and then employ semi-supervised learning to improve the accuracy of less-confident predictions in the target domain. We denote labeling transfer as SHOT++ if the predictions are obtained by SHOT. Extensive experiments on both digit classification and object recognition tasks show that SHOT and SHOT++ achieve results surpassing or comparable to the state-of-the-arts, demonstrating the effectiveness of our approaches for various visual domain adaptation problems.
Adversarial images for the primate brain
Nov 11, 2020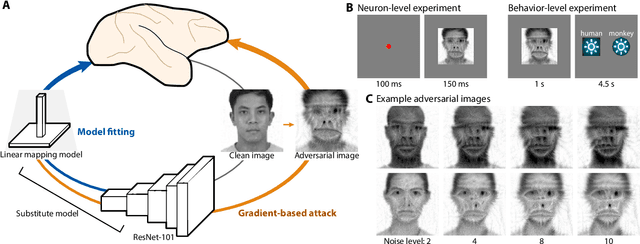
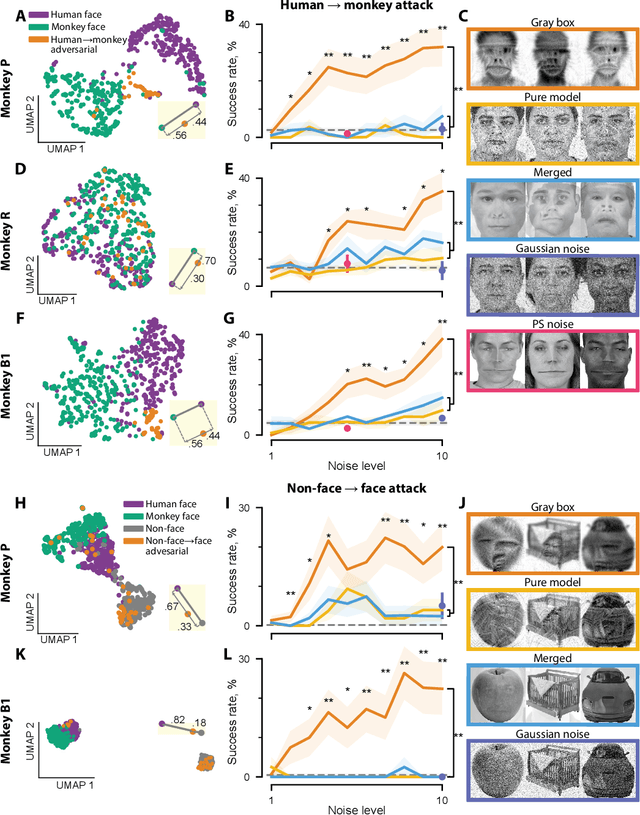
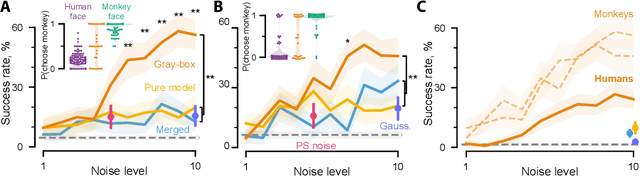
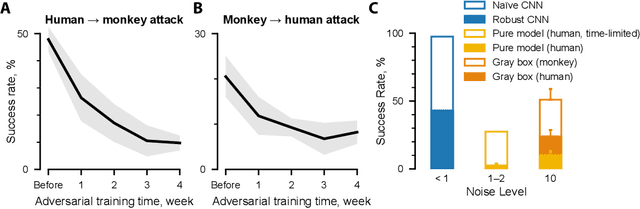
Deep artificial neural networks have been proposed as a model of primate vision. However, these networks are vulnerable to adversarial attacks, whereby introducing minimal noise can fool networks into misclassifying images. Primate vision is thought to be robust to such adversarial images. We evaluated this assumption by designing adversarial images to fool primate vision. To do so, we first trained a model to predict responses of face-selective neurons in macaque inferior temporal cortex. Next, we modified images, such as human faces, to match their model-predicted neuronal responses to a target category, such as monkey faces. These adversarial images elicited neuronal responses similar to the target category. Remarkably, the same images fooled monkeys and humans at the behavioral level. These results challenge fundamental assumptions about the similarity between computer and primate vision and show that a model of neuronal activity can selectively direct primate visual behavior.
Improving Generalization in Reinforcement Learning with Mixture Regularization
Oct 21, 2020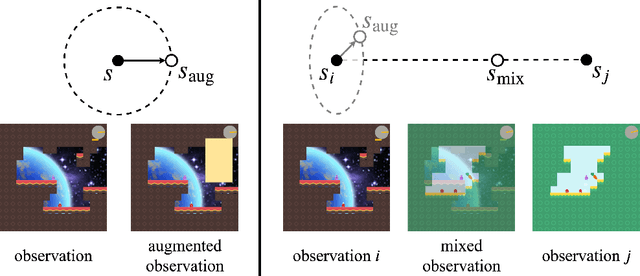
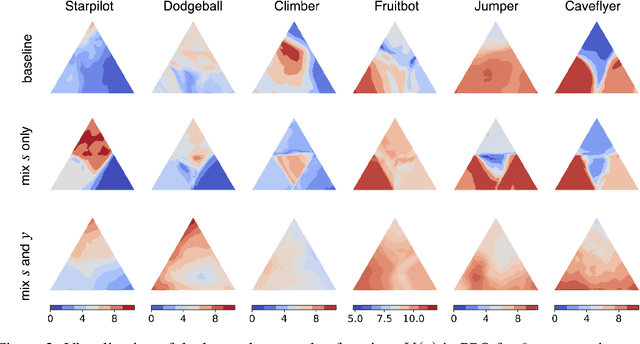
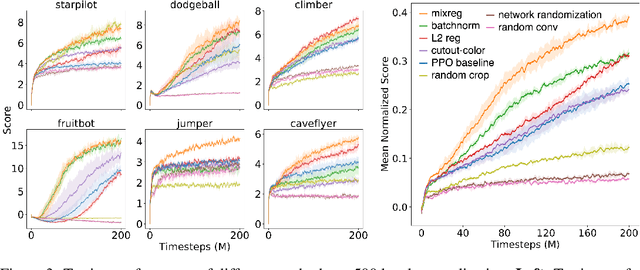
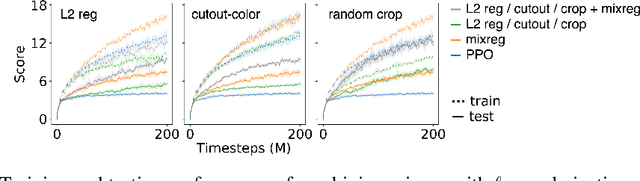
Deep reinforcement learning (RL) agents trained in a limited set of environments tend to suffer overfitting and fail to generalize to unseen testing environments. To improve their generalizability, data augmentation approaches (e.g. cutout and random convolution) are previously explored to increase the data diversity. However, we find these approaches only locally perturb the observations regardless of the training environments, showing limited effectiveness on enhancing the data diversity and the generalization performance. In this work, we introduce a simple approach, named mixreg, which trains agents on a mixture of observations from different training environments and imposes linearity constraints on the observation interpolations and the supervision (e.g. associated reward) interpolations. Mixreg increases the data diversity more effectively and helps learn smoother policies. We verify its effectiveness on improving generalization by conducting extensive experiments on the large-scale Procgen benchmark. Results show mixreg outperforms the well-established baselines on unseen testing environments by a large margin. Mixreg is simple, effective and general. It can be applied to both policy-based and value-based RL algorithms. Code is available at https://github.com/kaixin96/mixreg .
Towards Accurate Human Pose Estimation in Videos of Crowded Scenes
Oct 21, 2020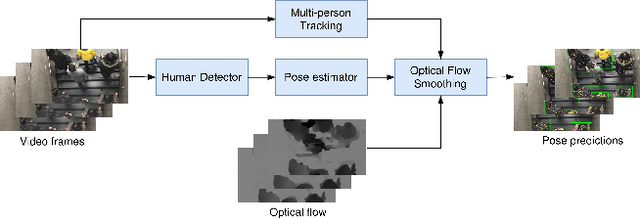

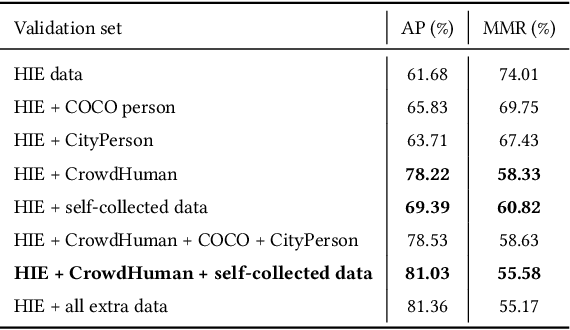
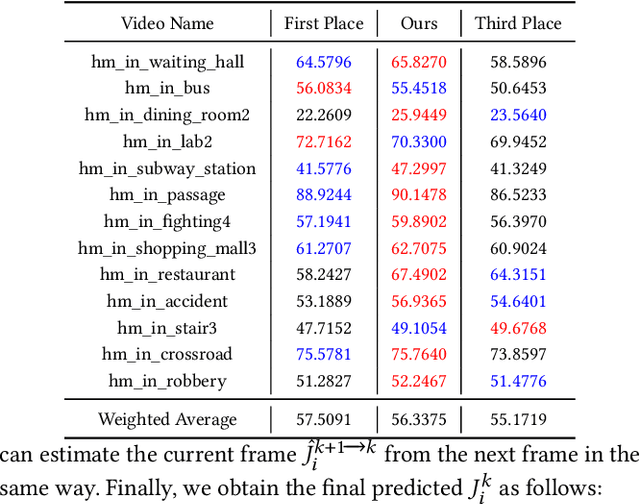
Video-based human pose estimation in crowded scenes is a challenging problem due to occlusion, motion blur, scale variation and viewpoint change, etc. Prior approaches always fail to deal with this problem because of (1) lacking of usage of temporal information; (2) lacking of training data in crowded scenes. In this paper, we focus on improving human pose estimation in videos of crowded scenes from the perspectives of exploiting temporal context and collecting new data. In particular, we first follow the top-down strategy to detect persons and perform single-person pose estimation for each frame. Then, we refine the frame-based pose estimation with temporal contexts deriving from the optical-flow. Specifically, for one frame, we forward the historical poses from the previous frames and backward the future poses from the subsequent frames to current frame, leading to stable and accurate human pose estimation in videos. In addition, we mine new data of similar scenes to HIE dataset from the Internet for improving the diversity of training set. In this way, our model achieves best performance on 7 out of 13 videos and 56.33 average w\_AP on test dataset of HIE challenge.
A Simple Baseline for Pose Tracking in Videos of Crowded Scenes
Oct 21, 2020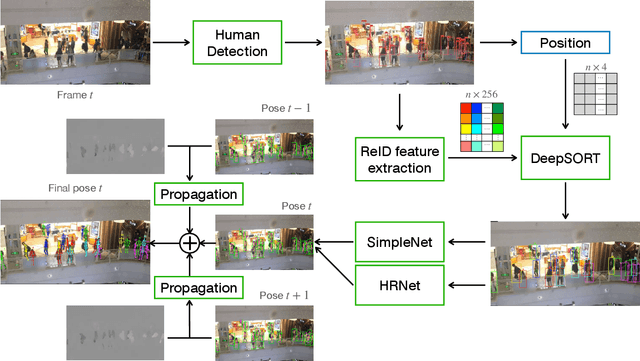
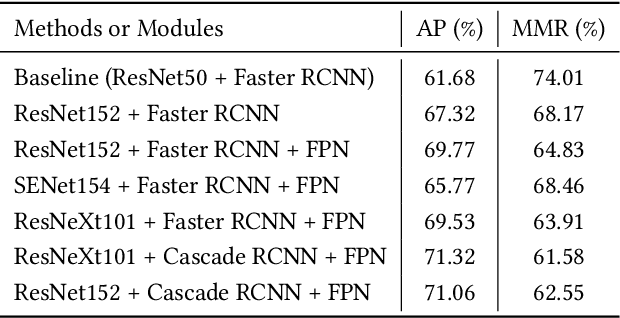
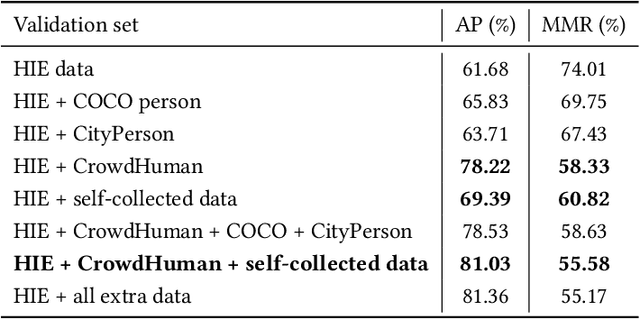

This paper presents our solution to ACM MM challenge: Large-scale Human-centric Video Analysis in Complex Events\cite{lin2020human}; specifically, here we focus on Track3: Crowd Pose Tracking in Complex Events. Remarkable progress has been made in multi-pose training in recent years. However, how to track the human pose in crowded and complex environments has not been well addressed. We formulate the problem as several subproblems to be solved. First, we use a multi-object tracking method to assign human ID to each bounding box generated by the detection model. After that, a pose is generated to each bounding box with ID. At last, optical flow is used to take advantage of the temporal information in the videos and generate the final pose tracking result.