 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTree Energy Loss: Towards Sparsely Annotated Semantic Segmentation
Mar 22, 2022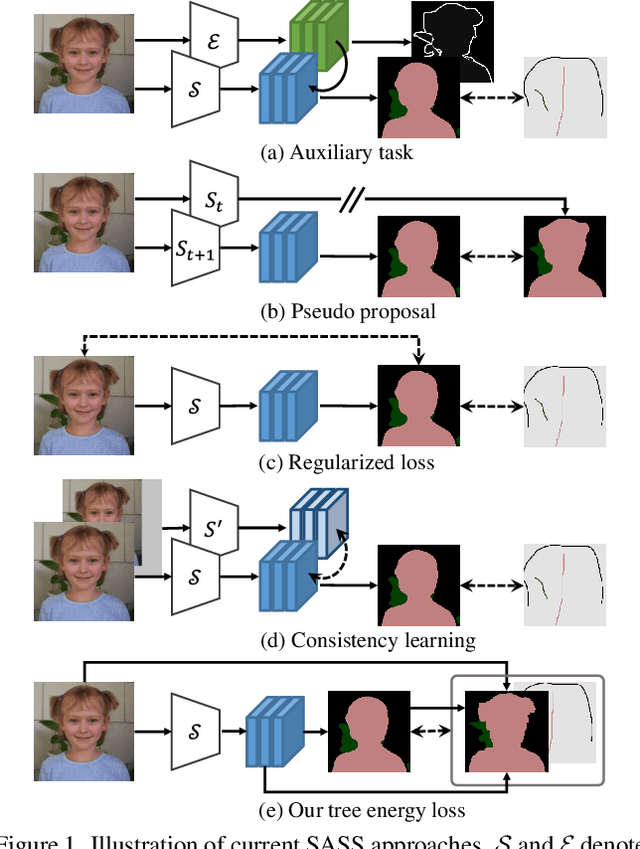
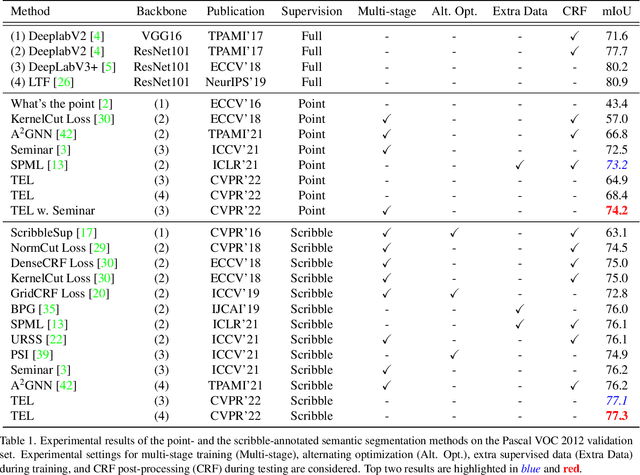

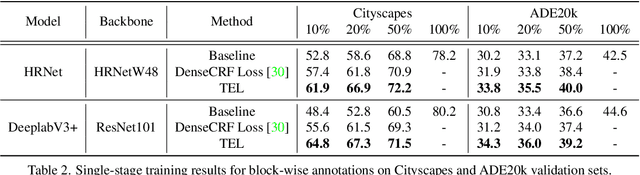
Sparsely annotated semantic segmentation (SASS) aims to train a segmentation network with coarse-grained (i.e., point-, scribble-, and block-wise) supervisions, where only a small proportion of pixels are labeled in each image. In this paper, we propose a novel tree energy loss for SASS by providing semantic guidance for unlabeled pixels. The tree energy loss represents images as minimum spanning trees to model both low-level and high-level pair-wise affinities. By sequentially applying these affinities to the network prediction, soft pseudo labels for unlabeled pixels are generated in a coarse-to-fine manner, achieving dynamic online self-training. The tree energy loss is effective and easy to be incorporated into existing frameworks by combining it with a traditional segmentation loss. Compared with previous SASS methods, our method requires no multistage training strategies, alternating optimization procedures, additional supervised data, or time-consuming post-processing while outperforming them in all SASS settings. Code is available at https://github.com/megvii-research/TreeEnergyLoss.
A Slot Is Not Built in One Utterance: Spoken Language Dialogs with Sub-Slots
Mar 21, 2022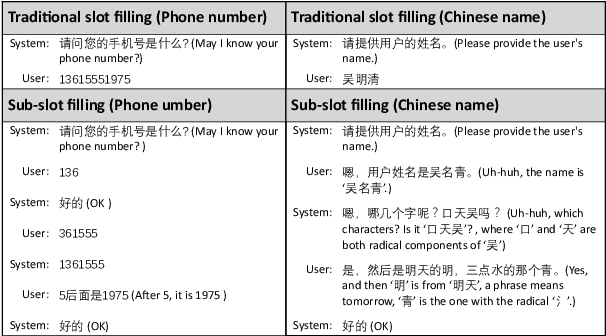

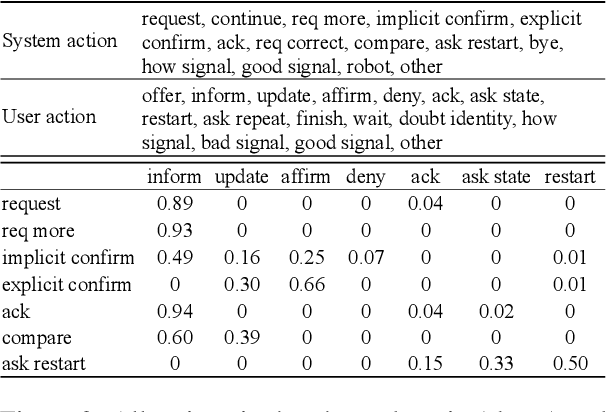
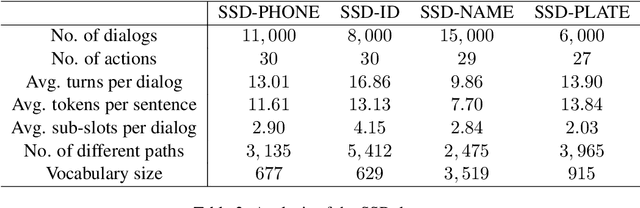
A slot value might be provided segment by segment over multiple-turn interactions in a dialog, especially for some important information such as phone numbers and names. It is a common phenomenon in daily life, but little attention has been paid to it in previous work. To fill the gap, this paper defines a new task named Sub-Slot based Task-Oriented Dialog (SSTOD) and builds a Chinese dialog dataset SSD for boosting research on SSTOD. The dataset includes a total of 40K dialogs and 500K utterances from four different domains: Chinese names, phone numbers, ID numbers and license plate numbers. The data is well annotated with sub-slot values, slot values, dialog states and actions. We find some new linguistic phenomena and interactive manners in SSTOD which raise critical challenges of building dialog agents for the task. We test three state-of-the-art dialog models on SSTOD and find they cannot handle the task well on any of the four domains. We also investigate an improved model by involving slot knowledge in a plug-in manner. More work should be done to meet the new challenges raised from SSTOD which widely exists in real-life applications. The dataset and code are publicly available via https://github.com/shunjiu/SSTOD.
Progressive End-to-End Object Detection in Crowded Scenes
Mar 19, 2022
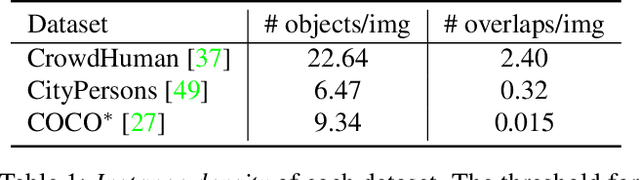
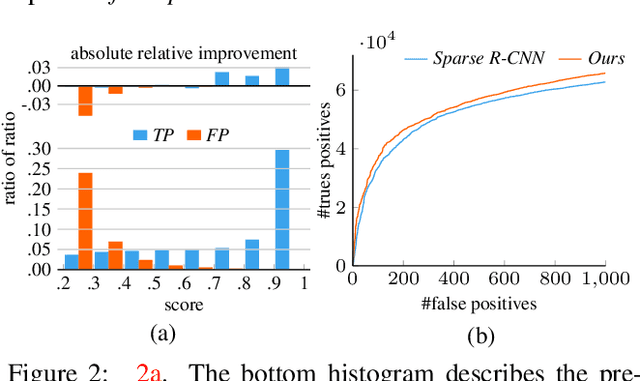
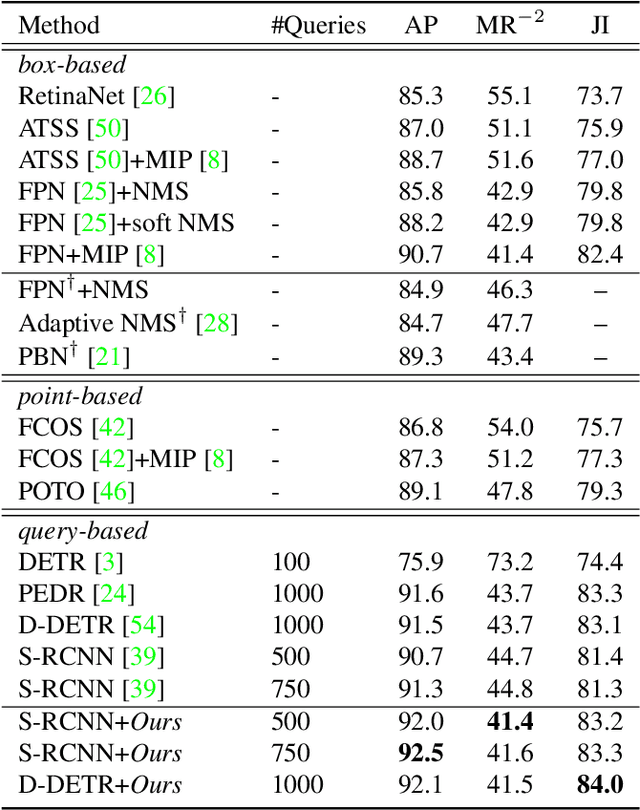
In this paper, we propose a new query-based detection framework for crowd detection. Previous query-based detectors suffer from two drawbacks: first, multiple predictions will be inferred for a single object, typically in crowded scenes; second, the performance saturates as the depth of the decoding stage increases. Benefiting from the nature of the one-to-one label assignment rule, we propose a progressive predicting method to address the above issues. Specifically, we first select accepted queries prone to generate true positive predictions, then refine the rest noisy queries according to the previously accepted predictions. Experiments show that our method can significantly boost the performance of query-based detectors in crowded scenes. Equipped with our approach, Sparse RCNN achieves 92.0\% $\text{AP}$, 41.4\% $\text{MR}^{-2}$ and 83.2\% $\text{JI}$ on the challenging CrowdHuman \cite{shao2018crowdhuman} dataset, outperforming the box-based method MIP \cite{chu2020detection} that specifies in handling crowded scenarios. Moreover, the proposed method, robust to crowdedness, can still obtain consistent improvements on moderately and slightly crowded datasets like CityPersons \cite{zhang2017citypersons} and COCO \cite{lin2014microsoft}. Code will be made publicly available at https://github.com/megvii-model/Iter-E2EDET.
S$^2$SQL: Injecting Syntax to Question-Schema Interaction Graph Encoder for Text-to-SQL Parsers
Mar 14, 2022



The task of converting a natural language question into an executable SQL query, known as text-to-SQL, is an important branch of semantic parsing. The state-of-the-art graph-based encoder has been successfully used in this task but does not model the question syntax well. In this paper, we propose S$^2$SQL, injecting Syntax to question-Schema graph encoder for Text-to-SQL parsers, which effectively leverages the syntactic dependency information of questions in text-to-SQL to improve the performance. We also employ the decoupling constraint to induce diverse relational edge embedding, which further improves the network's performance. Experiments on the Spider and robustness setting Spider-Syn demonstrate that the proposed approach outperforms all existing methods when pre-training models are used, resulting in a performance ranks first on the Spider leaderboard.
PETR: Position Embedding Transformation for Multi-View 3D Object Detection
Mar 10, 2022
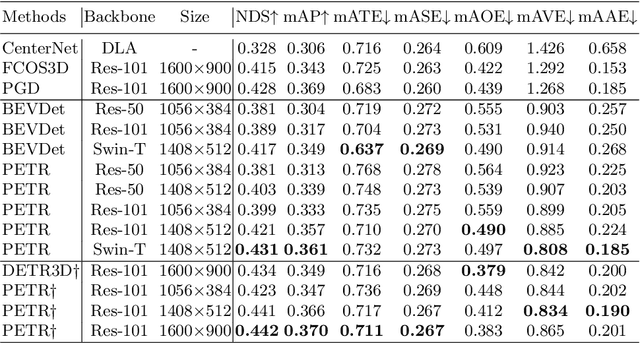
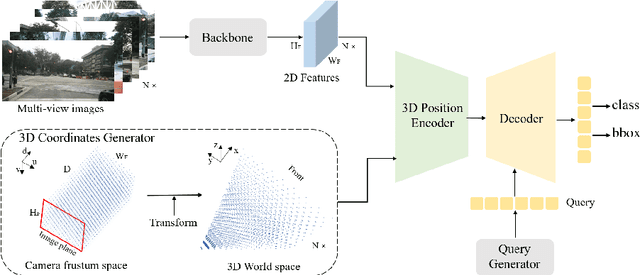
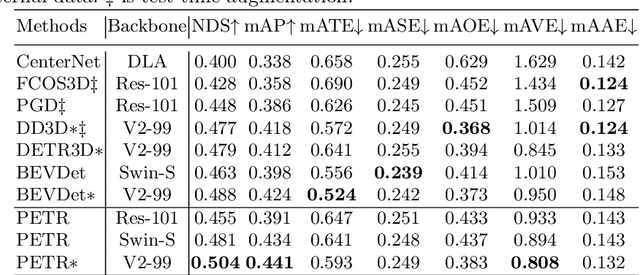
In this paper, we develop position embedding transformation (PETR) for multi-view 3D object detection. PETR encodes the position information of 3D coordinates into image features, producing the 3D position-aware features. Object query can perceive the 3D position-aware features and perform end-to-end object detection. PETR achieves state-of-the-art performance (50.4% NDS and 44.1% mAP) on standard nuScenes dataset and ranks 1st place on the benchmark. It can serve as a simple yet strong baseline for future research.
Relieving Long-tailed Instance Segmentation via Pairwise Class Balance
Jan 08, 2022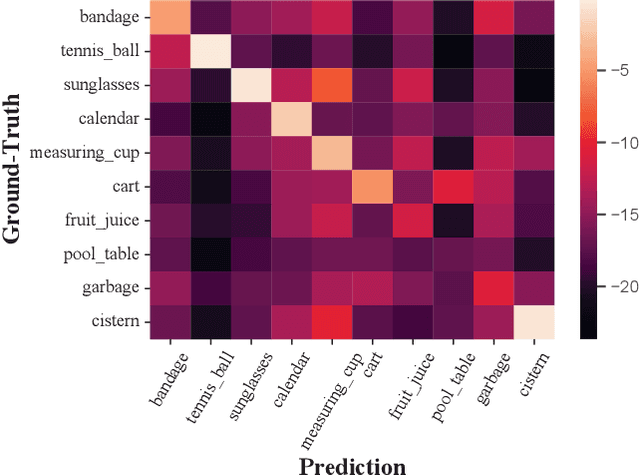
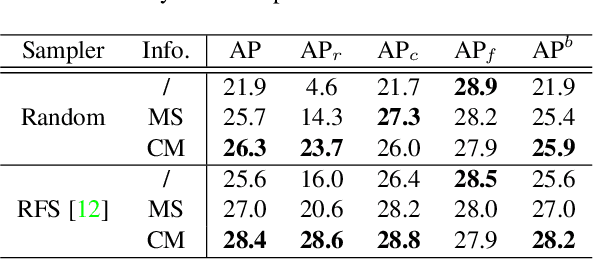
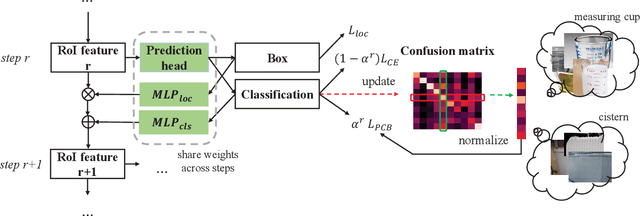
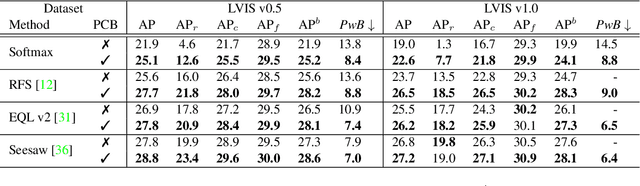
Long-tailed instance segmentation is a challenging task due to the extreme imbalance of training samples among classes. It causes severe biases of the head classes (with majority samples) against the tailed ones. This renders "how to appropriately define and alleviate the bias" one of the most important issues. Prior works mainly use label distribution or mean score information to indicate a coarse-grained bias. In this paper, we explore to excavate the confusion matrix, which carries the fine-grained misclassification details, to relieve the pairwise biases, generalizing the coarse one. To this end, we propose a novel Pairwise Class Balance (PCB) method, built upon a confusion matrix which is updated during training to accumulate the ongoing prediction preferences. PCB generates fightback soft labels for regularization during training. Besides, an iterative learning paradigm is developed to support a progressive and smooth regularization in such debiasing. PCB can be plugged and played to any existing method as a complement. Experimental results on LVIS demonstrate that our method achieves state-of-the-art performance without bells and whistles. Superior results across various architectures show the generalization ability.
GALAXY: A Generative Pre-trained Model for Task-Oriented Dialog with Semi-Supervised Learning and Explicit Policy Injection
Dec 27, 2021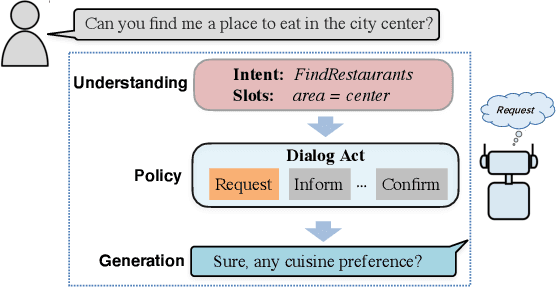
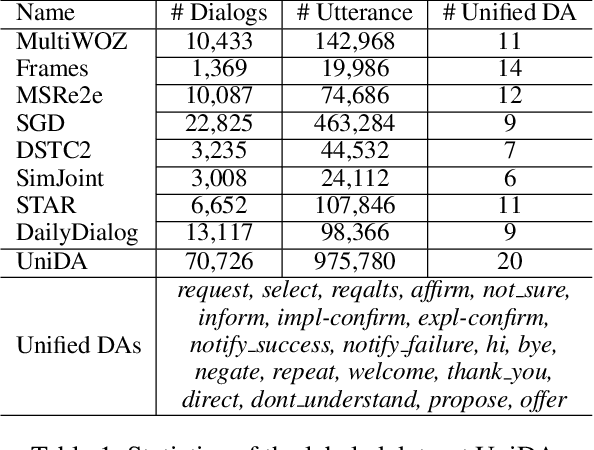

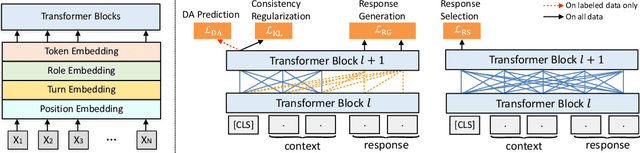
Pre-trained models have proved to be powerful in enhancing task-oriented dialog systems. However, current pre-training methods mainly focus on enhancing dialog understanding and generation tasks while neglecting the exploitation of dialog policy. In this paper, we propose GALAXY, a novel pre-trained dialog model that explicitly learns dialog policy from limited labeled dialogs and large-scale unlabeled dialog corpora via semi-supervised learning. Specifically, we introduce a dialog act prediction task for policy optimization during pre-training and employ a consistency regularization term to refine the learned representation with the help of unlabeled dialogs. We also implement a gating mechanism to weigh suitable unlabeled dialog samples. Empirical results show that GALAXY substantially improves the performance of task-oriented dialog systems, and achieves new state-of-the-art results on benchmark datasets: In-Car, MultiWOZ2.0 and MultiWOZ2.1, improving their end-to-end combined scores by 2.5, 5.3 and 5.5 points, respectively. We also show that GALAXY has a stronger few-shot ability than existing models under various low-resource settings.
Learning to Select the Next Reasonable Mention for Entity Linking
Dec 08, 2021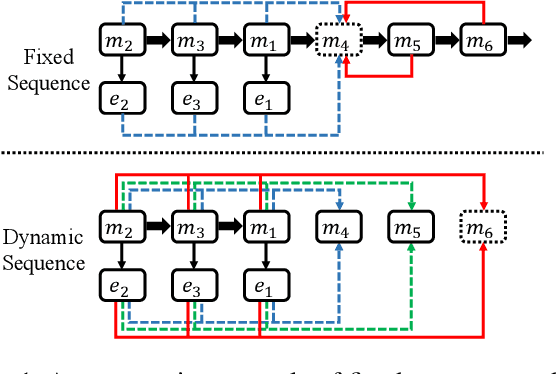
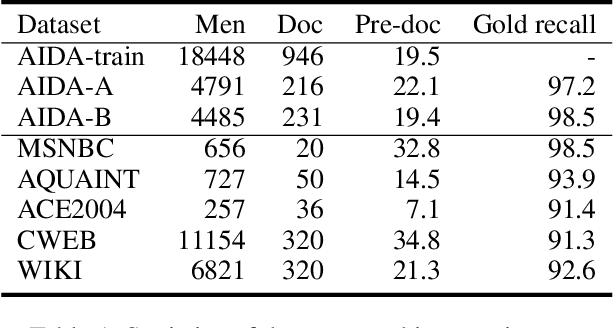
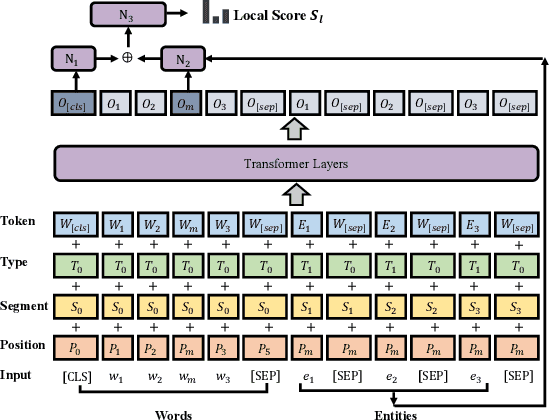
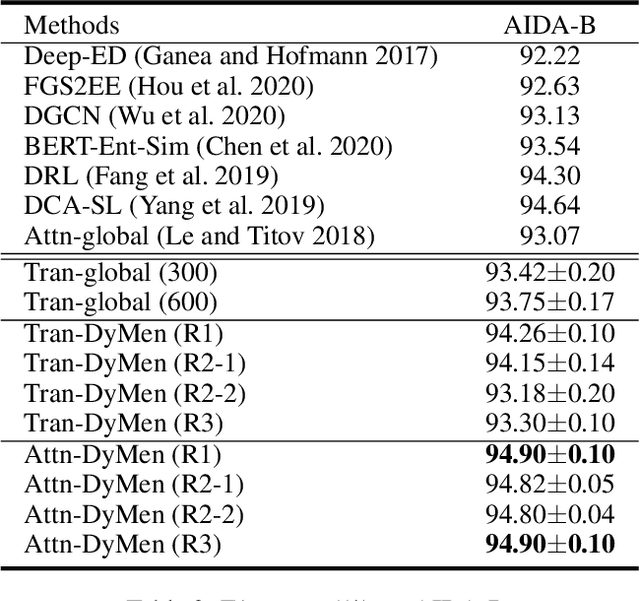
Entity linking aims to establish a link between entity mentions in a document and the corresponding entities in knowledge graphs (KGs). Previous work has shown the effectiveness of global coherence for entity linking. However, most of the existing global linking methods based on sequential decisions focus on how to utilize previously linked entities to enhance the later decisions. In those methods, the order of mention is fixed, making the model unable to adjust the subsequent linking targets according to the previously linked results, which will cause the previous information to be unreasonably utilized. To address the problem, we propose a novel model, called DyMen, to dynamically adjust the subsequent linking target based on the previously linked entities via reinforcement learning, enabling the model to select a link target that can fully use previously linked information. We sample mention by sliding window to reduce the action sampling space of reinforcement learning and maintain the semantic coherence of mention. Experiments conducted on several benchmark datasets have shown the effectiveness of the proposed model.
XnODR and XnIDR: Two Accurate and Fast Fully Connected Layers For Convolutional Neural Networks
Nov 21, 2021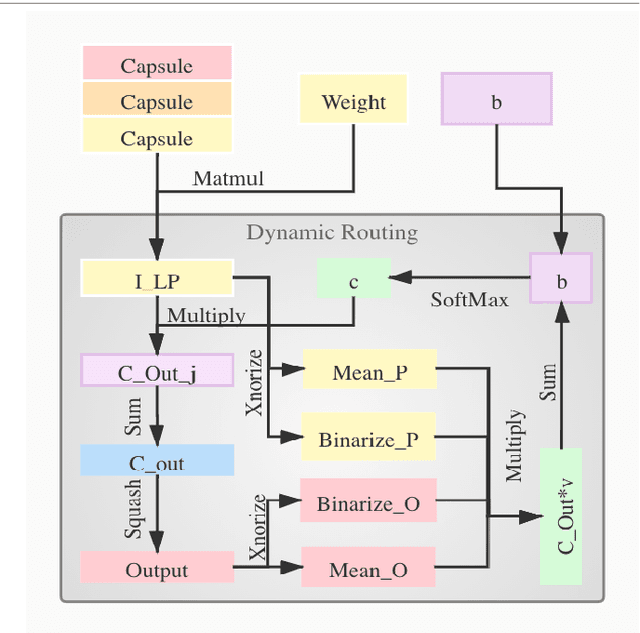
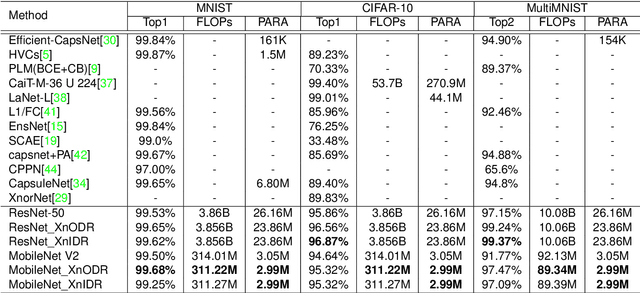
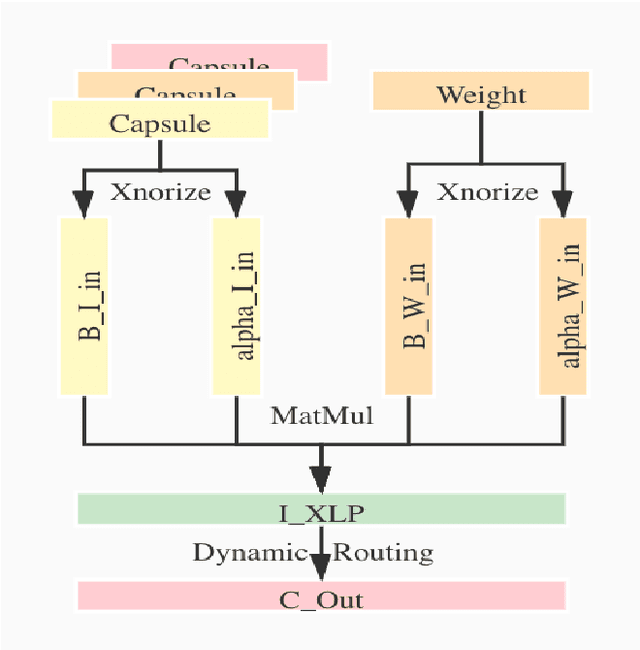
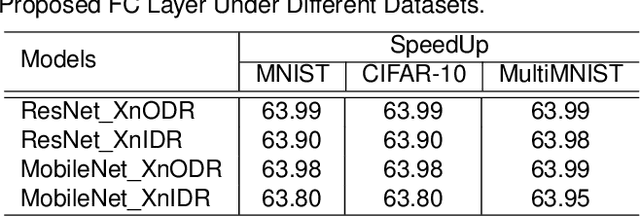
Although Capsule Networks show great abilities in defining the position relationship between features in deep neural networks for visual recognition tasks, they are computationally expensive and not suitable for running on mobile devices. The bottleneck is in the computational complexity of the Dynamic Routing mechanism used between capsules. On the other hand, neural networks such as XNOR-Net are fast and computationally efficient but have relatively low accuracy because of their information loss in the binarization process. This paper proposes a new class of Fully Connected (FC) Layers by xnorizing the linear projector outside or inside the Dynamic Routing within the CapsFC layer. Specifically, our proposed FC layers have two versions, XnODR (Xnorizing Linear Projector Outside Dynamic Routing) and XnIDR (Xnorizing Linear Projector Inside Dynamic Routing). To test their generalization, we insert them into MobileNet V2 and ResNet-50 separately. Experiments on three datasets, MNIST, CIFAR-10, MultiMNIST validate their effectiveness. Our experimental results demonstrate that both XnODR and XnIDR help networks to have high accuracy with lower FLOPs and fewer parameters (e.g., 95.32\% accuracy with 2.99M parameters and 311.22M FLOPs on CIFAR-10).
SDCUP: Schema Dependency-Enhanced Curriculum Pre-Training for Table Semantic Parsing
Nov 18, 2021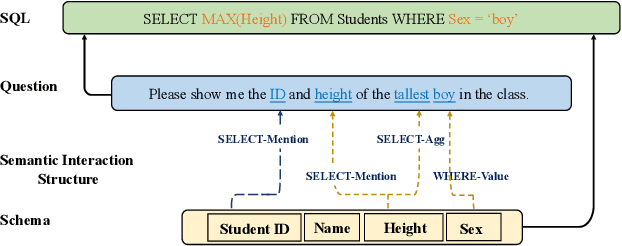
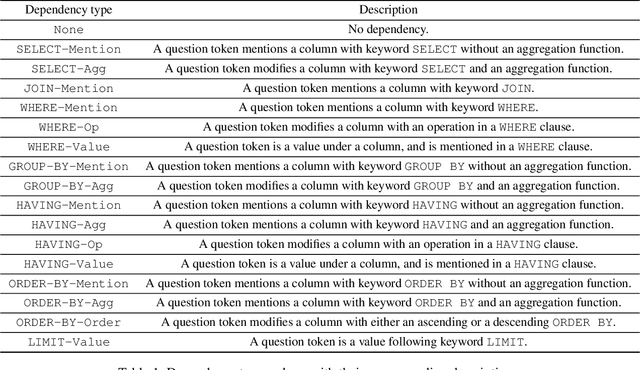
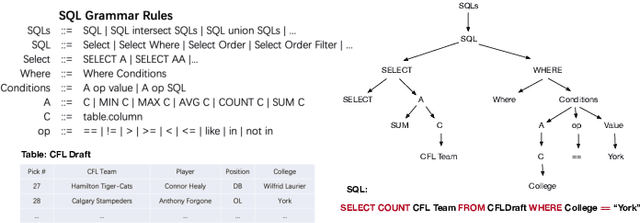

Recently pre-training models have significantly improved the performance of various NLP tasks by leveraging large-scale text corpora to improve the contextual representation ability of the neural network. The large pre-training language model has also been applied in the area of table semantic parsing. However, existing pre-training approaches have not carefully explored explicit interaction relationships between a question and the corresponding database schema, which is a key ingredient for uncovering their semantic and structural correspondence. Furthermore, the question-aware representation learning in the schema grounding context has received less attention in pre-training objective.To alleviate these issues, this paper designs two novel pre-training objectives to impose the desired inductive bias into the learned representations for table pre-training. We further propose a schema-aware curriculum learning approach to mitigate the impact of noise and learn effectively from the pre-training data in an easy-to-hard manner. We evaluate our pre-trained framework by fine-tuning it on two benchmarks, Spider and SQUALL. The results demonstrate the effectiveness of our pre-training objective and curriculum compared to a variety of baselines.