 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA 3D Molecule Generative Model for Structure-Based Drug Design
Mar 20, 2022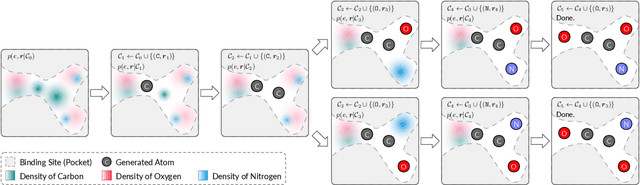
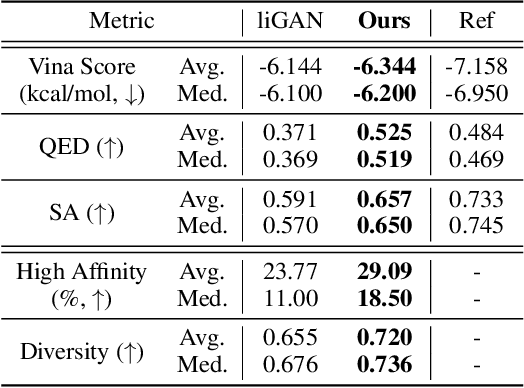
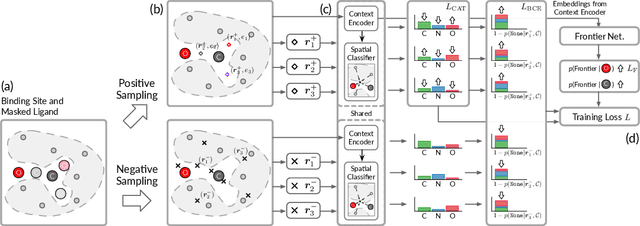
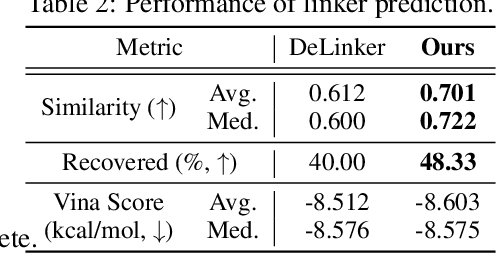
We study a fundamental problem in structure-based drug design -- generating molecules that bind to specific protein binding sites. While we have witnessed the great success of deep generative models in drug design, the existing methods are mostly string-based or graph-based. They are limited by the lack of spatial information and thus unable to be applied to structure-based design tasks. Particularly, such models have no or little knowledge of how molecules interact with their target proteins exactly in 3D space. In this paper, we propose a 3D generative model that generates molecules given a designated 3D protein binding site. Specifically, given a binding site as the 3D context, our model estimates the probability density of atom's occurrences in 3D space -- positions that are more likely to have atoms will be assigned higher probability. To generate 3D molecules, we propose an auto-regressive sampling scheme -- atoms are sampled sequentially from the learned distribution until there is no room for new atoms. Combined with this sampling scheme, our model can generate valid and diverse molecules, which could be applicable to various structure-based molecular design tasks such as molecule sampling and linker design. Experimental results demonstrate that molecules sampled from our model exhibit high binding affinity to specific targets and good drug properties such as drug-likeness even if the model is not explicitly optimized for them.
FastFold: Reducing AlphaFold Training Time from 11 Days to 67 Hours
Mar 04, 2022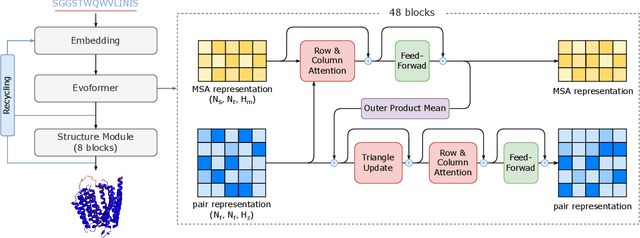
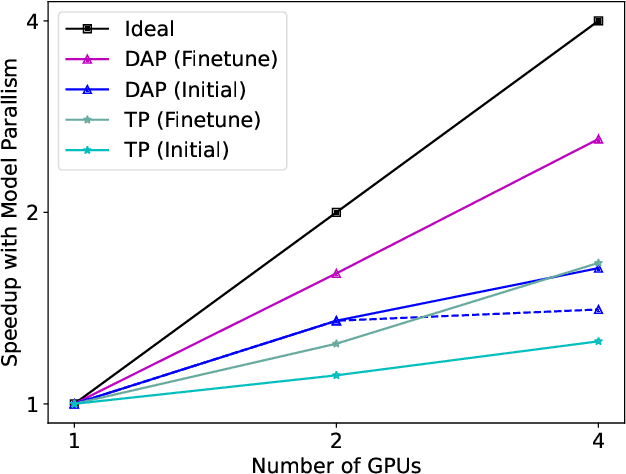
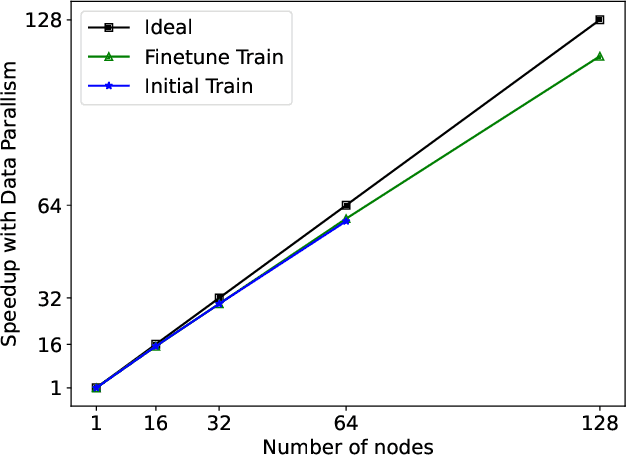
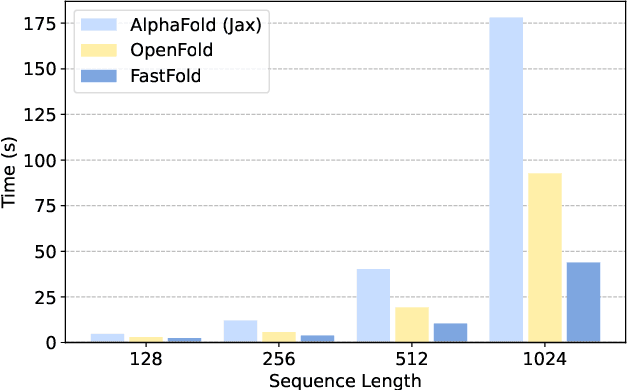
Protein structure prediction is an important method for understanding gene translation and protein function in the domain of structural biology. AlphaFold introduced the Transformer model to the field of protein structure prediction with atomic accuracy. However, training and inference of the AlphaFold model are time-consuming and expensive because of the special performance characteristics and huge memory consumption. In this paper, we propose FastFold, a highly efficient implementation of the protein structure prediction model for training and inference. FastFold includes a series of GPU optimizations based on a thorough analysis of AlphaFold's performance. Meanwhile, with Dynamic Axial Parallelism and Duality Async Operation, FastFold achieves high model parallelism scaling efficiency, surpassing existing popular model parallelism techniques. Experimental results show that FastFold reduces overall training time from 11 days to 67 hours and achieves 7.5-9.5X speedup for long-sequence inference. Furthermore, We scaled FastFold to 512 GPUs and achieved an aggregate of 6.02 PetaFLOPs with 90.1% parallel efficiency. The implementation can be found at https://github.com/hpcaitech/FastFold
Directed Weight Neural Networks for Protein Structure Representation Learning
Jan 28, 2022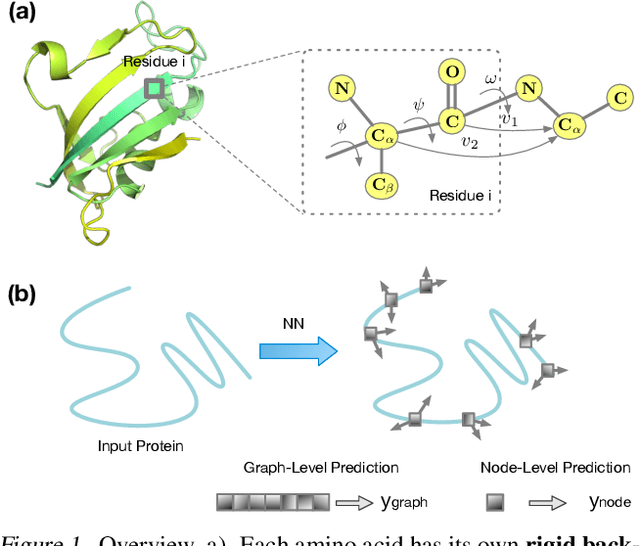
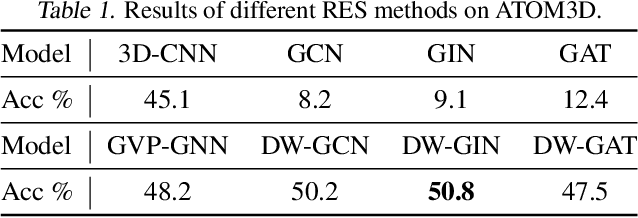
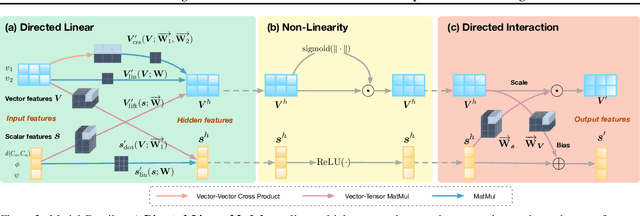
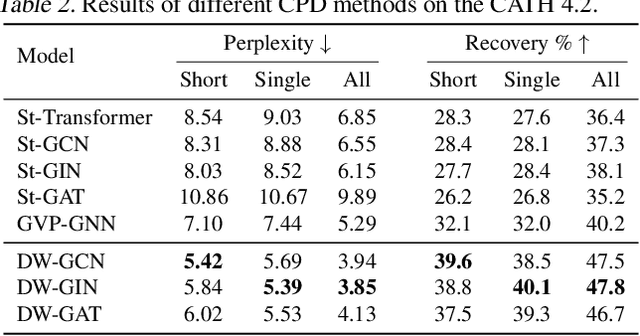
A protein performs biological functions by folding to a particular 3D structure. To accurately model the protein structures, both the overall geometric topology and local fine-grained relations between amino acids (e.g. side-chain torsion angles and inter-amino-acid orientations) should be carefully considered. In this work, we propose the Directed Weight Neural Network for better capturing geometric relations among different amino acids. Extending a single weight from a scalar to a 3D directed vector, our new framework supports a rich set of geometric operations on both classical and SO(3)--representation features, on top of which we construct a perceptron unit for processing amino-acid information. In addition, we introduce an equivariant message passing paradigm on proteins for plugging the directed weight perceptrons into existing Graph Neural Networks, showing superior versatility in maintaining SO(3)-equivariance at the global scale. Experiments show that our network has remarkably better expressiveness in representing geometric relations in comparison to classical neural networks and the (globally) equivariant networks. It also achieves state-of-the-art performance on various computational biology applications related to protein 3D structures.
Overcome Anterograde Forgetting with Cycled Memory Networks
Dec 04, 2021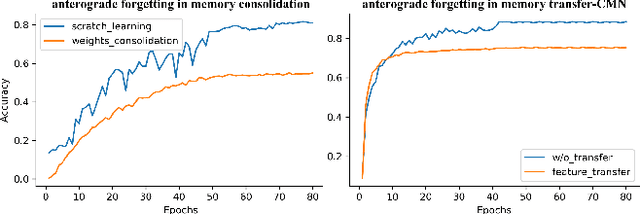
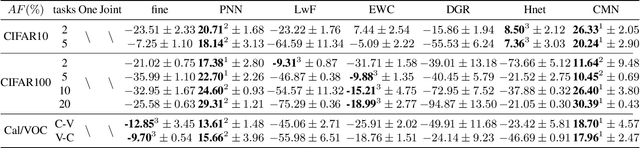
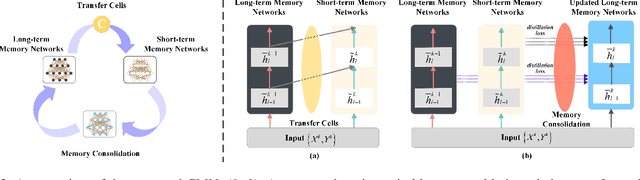
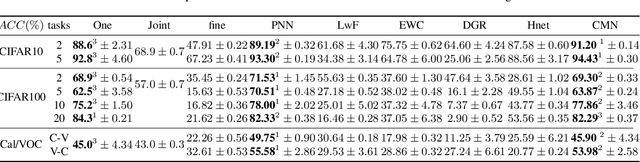
Learning from a sequence of tasks for a lifetime is essential for an agent towards artificial general intelligence. This requires the agent to continuously learn and memorize new knowledge without interference. This paper first demonstrates a fundamental issue of lifelong learning using neural networks, named anterograde forgetting, i.e., preserving and transferring memory may inhibit the learning of new knowledge. This is attributed to the fact that the learning capacity of a neural network will be reduced as it keeps memorizing historical knowledge, and the fact that conceptual confusion may occur as it transfers irrelevant old knowledge to the current task. This work proposes a general framework named Cycled Memory Networks (CMN) to address the anterograde forgetting in neural networks for lifelong learning. The CMN consists of two individual memory networks to store short-term and long-term memories to avoid capacity shrinkage. A transfer cell is designed to connect these two memory networks, enabling knowledge transfer from the long-term memory network to the short-term memory network to mitigate the conceptual confusion, and a memory consolidation mechanism is developed to integrate short-term knowledge into the long-term memory network for knowledge accumulation. Experimental results demonstrate that the CMN can effectively address the anterograde forgetting on several task-related, task-conflict, class-incremental and cross-domain benchmarks.
Learning Long-Term Reward Redistribution via Randomized Return Decomposition
Nov 26, 2021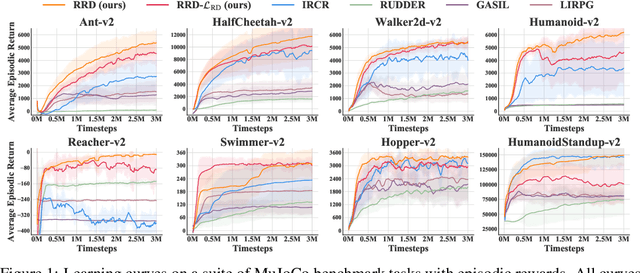
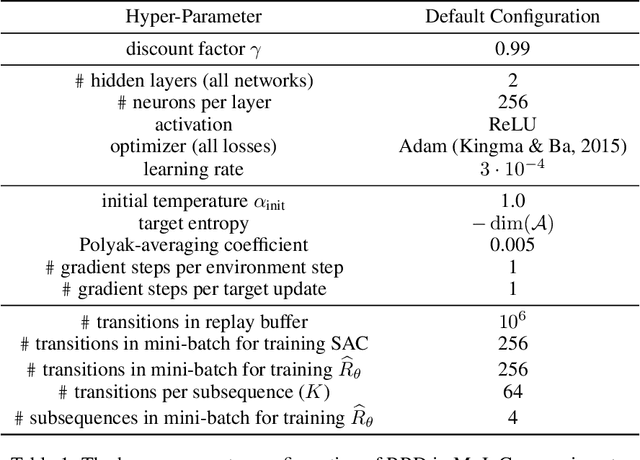
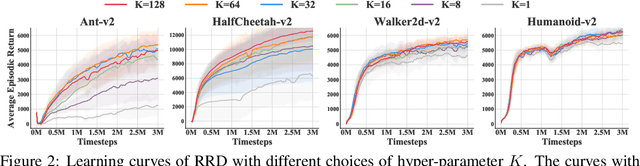
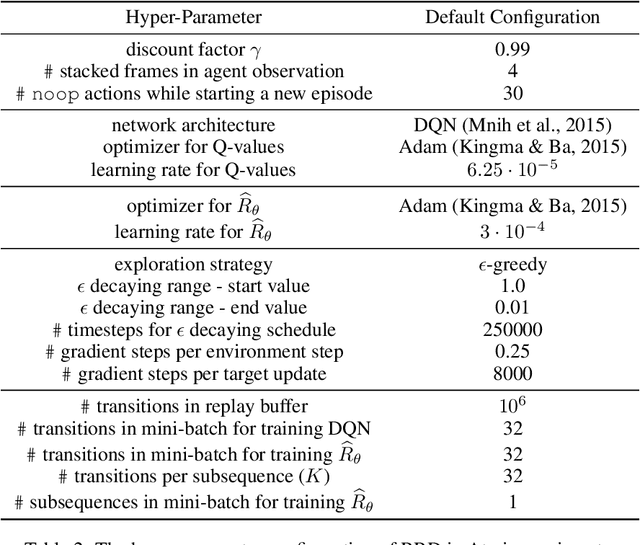
Many practical applications of reinforcement learning require agents to learn from sparse and delayed rewards. It challenges the ability of agents to attribute their actions to future outcomes. In this paper, we consider the problem formulation of episodic reinforcement learning with trajectory feedback. It refers to an extreme delay of reward signals, in which the agent can only obtain one reward signal at the end of each trajectory. A popular paradigm for this problem setting is learning with a designed auxiliary dense reward function, namely proxy reward, instead of sparse environmental signals. Based on this framework, this paper proposes a novel reward redistribution algorithm, randomized return decomposition (RRD), to learn a proxy reward function for episodic reinforcement learning. We establish a surrogate problem by Monte-Carlo sampling that scales up least-squares-based reward redistribution to long-horizon problems. We analyze our surrogate loss function by connection with existing methods in the literature, which illustrates the algorithmic properties of our approach. In experiments, we extensively evaluate our proposed method on a variety of benchmark tasks with episodic rewards and demonstrate substantial improvement over baseline algorithms.
Reviewing continual learning from the perspective of human-level intelligence
Nov 23, 2021
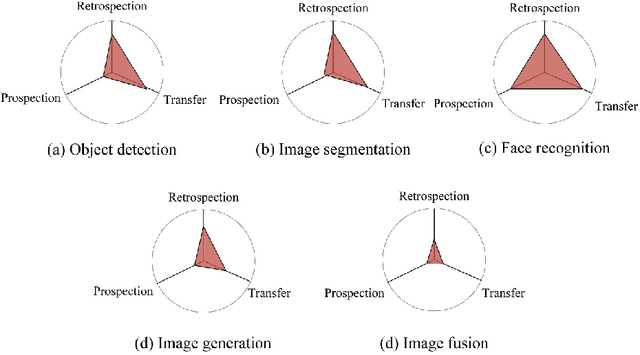
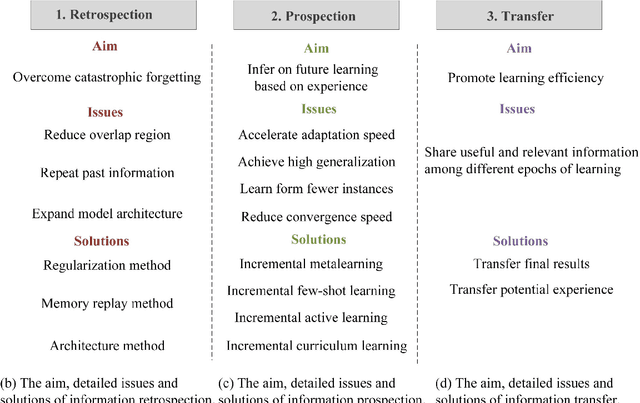
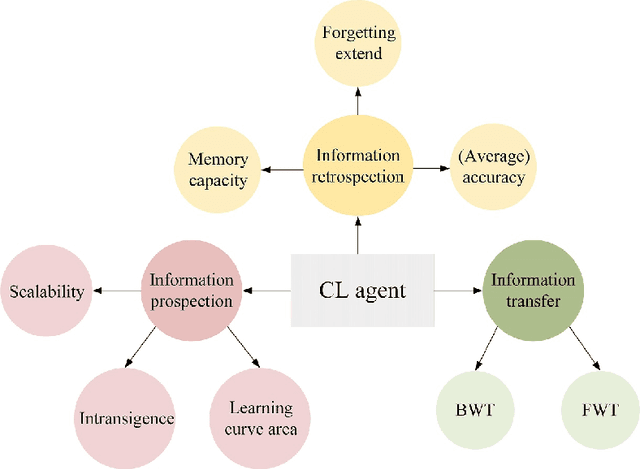
Humans' continual learning (CL) ability is closely related to Stability Versus Plasticity Dilemma that describes how humans achieve ongoing learning capacity and preservation for learned information. The notion of CL has always been present in artificial intelligence (AI) since its births. This paper proposes a comprehensive review of CL. Different from previous reviews that mainly focus on the catastrophic forgetting phenomenon in CL, this paper surveys CL from a more macroscopic perspective based on the Stability Versus Plasticity mechanism. Analogous to biological counterpart, "smart" AI agents are supposed to i) remember previously learned information (information retrospection); ii) infer on new information continuously (information prospection:); iii) transfer useful information (information transfer), to achieve high-level CL. According to the taxonomy, evaluation metrics, algorithms, applications as well as some open issues are then introduced. Our main contributions concern i) rechecking CL from the level of artificial general intelligence; ii) providing a detailed and extensive overview on CL topics; iii) presenting some novel ideas on the potential development of CL.
Learning by Active Forgetting for Neural Networks
Nov 21, 2021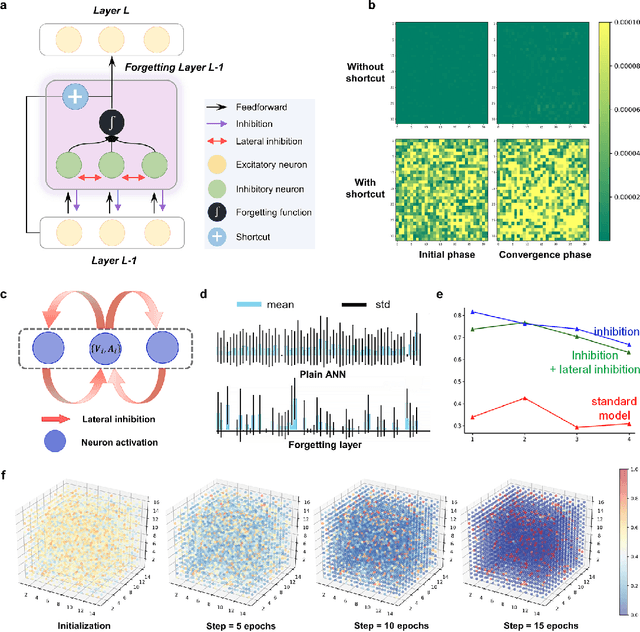
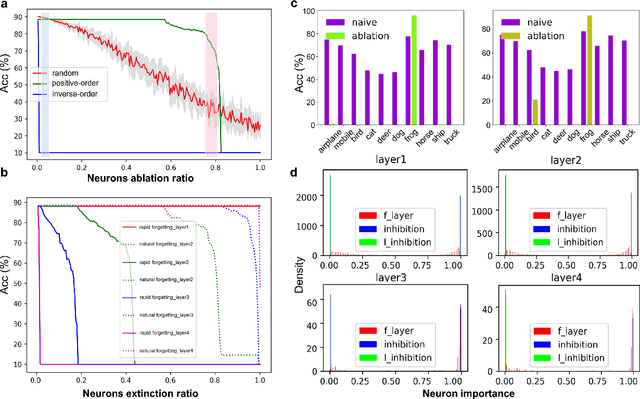
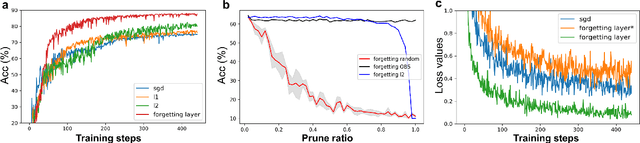
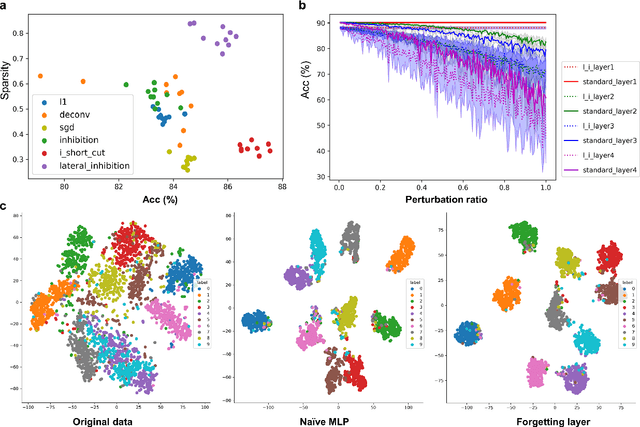
Remembering and forgetting mechanisms are two sides of the same coin in a human learning-memory system. Inspired by human brain memory mechanisms, modern machine learning systems have been working to endow machine with lifelong learning capability through better remembering while pushing the forgetting as the antagonist to overcome. Nevertheless, this idea might only see the half picture. Up until very recently, increasing researchers argue that a brain is born to forget, i.e., forgetting is a natural and active process for abstract, rich, and flexible representations. This paper presents a learning model by active forgetting mechanism with artificial neural networks. The active forgetting mechanism (AFM) is introduced to a neural network via a "plug-and-play" forgetting layer (P\&PF), consisting of groups of inhibitory neurons with Internal Regulation Strategy (IRS) to adjust the extinction rate of themselves via lateral inhibition mechanism and External Regulation Strategy (ERS) to adjust the extinction rate of excitatory neurons via inhibition mechanism. Experimental studies have shown that the P\&PF offers surprising benefits: self-adaptive structure, strong generalization, long-term learning and memory, and robustness to data and parameter perturbation. This work sheds light on the importance of forgetting in the learning process and offers new perspectives to understand the underlying mechanisms of neural networks.
Hindsight Foresight Relabeling for Meta-Reinforcement Learning
Sep 18, 2021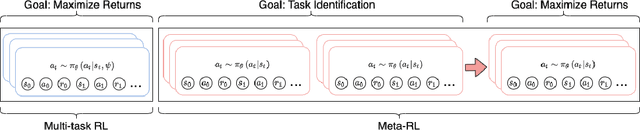
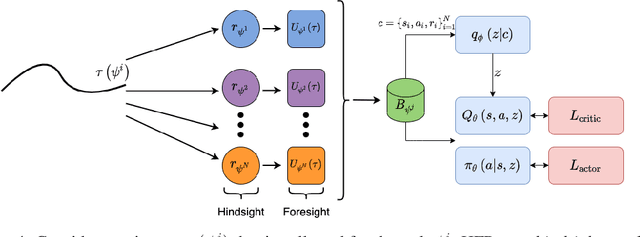
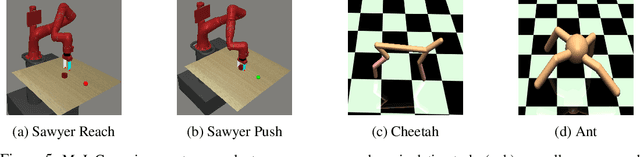

Meta-reinforcement learning (meta-RL) algorithms allow for agents to learn new behaviors from small amounts of experience, mitigating the sample inefficiency problem in RL. However, while meta-RL agents can adapt quickly to new tasks at test time after experiencing only a few trajectories, the meta-training process is still sample-inefficient. Prior works have found that in the multi-task RL setting, relabeling past transitions and thus sharing experience among tasks can improve sample efficiency and asymptotic performance. We apply this idea to the meta-RL setting and devise a new relabeling method called Hindsight Foresight Relabeling (HFR). We construct a relabeling distribution using the combination of "hindsight", which is used to relabel trajectories using reward functions from the training task distribution, and "foresight", which takes the relabeled trajectories and computes the utility of each trajectory for each task. HFR is easy to implement and readily compatible with existing meta-RL algorithms. We find that HFR improves performance when compared to other relabeling methods on a variety of meta-RL tasks.
Pixel Contrastive-Consistent Semi-Supervised Semantic Segmentation
Aug 20, 2021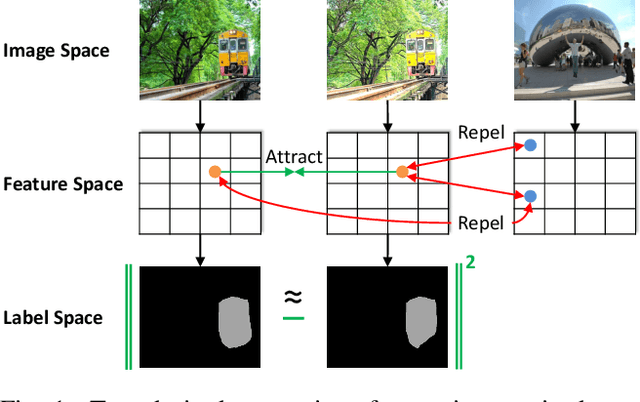
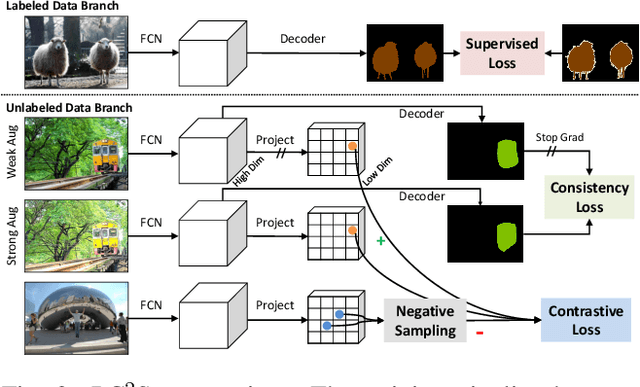
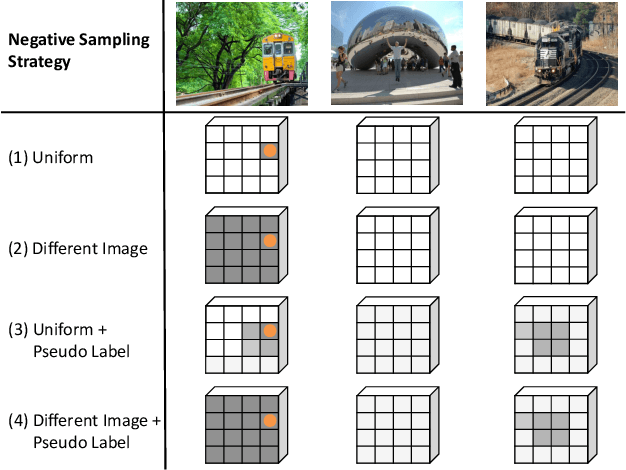

We present a novel semi-supervised semantic segmentation method which jointly achieves two desiderata of segmentation model regularities: the label-space consistency property between image augmentations and the feature-space contrastive property among different pixels. We leverage the pixel-level L2 loss and the pixel contrastive loss for the two purposes respectively. To address the computational efficiency issue and the false negative noise issue involved in the pixel contrastive loss, we further introduce and investigate several negative sampling techniques. Extensive experiments demonstrate the state-of-the-art performance of our method (PC2Seg) with the DeepLab-v3+ architecture, in several challenging semi-supervised settings derived from the VOC, Cityscapes, and COCO datasets.
Coordinate-wise Control Variates for Deep Policy Gradients
Aug 11, 2021
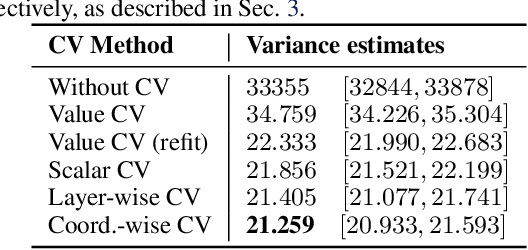
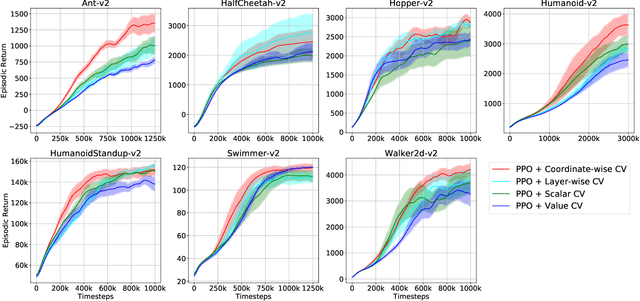

The control variates (CV) method is widely used in policy gradient estimation to reduce the variance of the gradient estimators in practice. A control variate is applied by subtracting a baseline function from the state-action value estimates. Then the variance-reduced policy gradient presumably leads to higher learning efficiency. Recent research on control variates with deep neural net policies mainly focuses on scalar-valued baseline functions. The effect of vector-valued baselines is under-explored. This paper investigates variance reduction with coordinate-wise and layer-wise control variates constructed from vector-valued baselines for neural net policies. We present experimental evidence suggesting that lower variance can be obtained with such baselines than with the conventional scalar-valued baseline. We demonstrate how to equip the popular Proximal Policy Optimization (PPO) algorithm with these new control variates. We show that the resulting algorithm with proper regularization can achieve higher sample efficiency than scalar control variates in continuous control benchmarks.