 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Structured State-Space Duality
Oct 06, 2025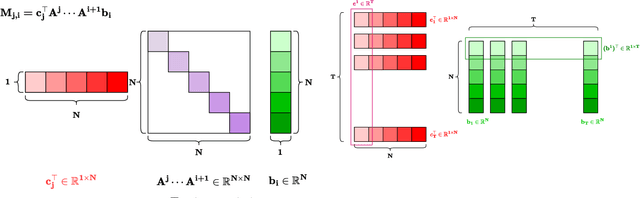
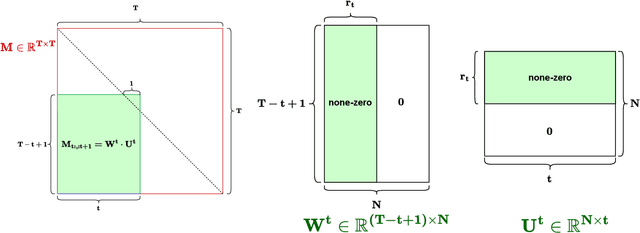
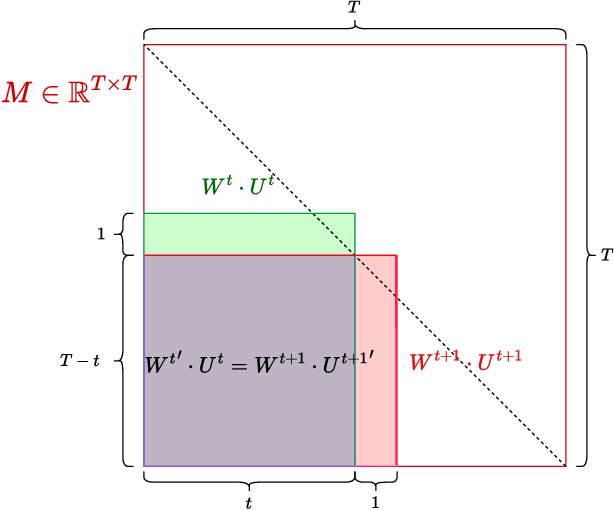
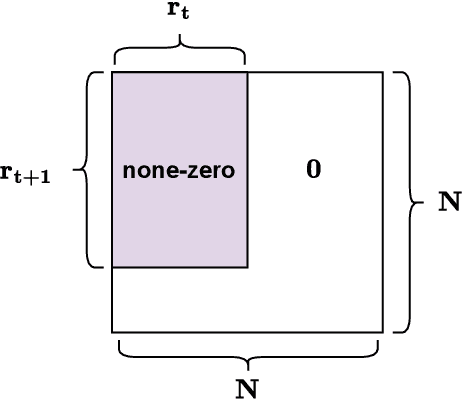
Structured State-Space Duality (SSD) [Dao & Gu, ICML 2024] is an equivalence between a simple Structured State-Space Model (SSM) and a masked attention mechanism. In particular, a state-space model with a scalar-times-identity state matrix is equivalent to a masked self-attention with a $1$-semiseparable causal mask. Consequently, the same sequence transformation (model) has two algorithmic realizations: as a linear-time $O(T)$ recurrence or as a quadratic-time $O(T^2)$ attention. In this note, we formalize and generalize this duality: (i) we extend SSD from the scalar-identity case to general diagonal SSMs (diagonal state matrices); (ii) we show that these diagonal SSMs match the scalar case's training complexity lower bounds while supporting richer dynamics; (iii) we establish a necessary and sufficient condition under which an SSM is equivalent to $1$-semiseparable masked attention; and (iv) we show that such duality fails to extend to standard softmax attention due to rank explosion. Together, these results tighten bridge between recurrent SSMs and Transformers, and widen the design space for expressive yet efficient sequence models.
Minimalist Softmax Attention Provably Learns Constrained Boolean Functions
May 26, 2025We study the computational limits of learning $k$-bit Boolean functions (specifically, $\mathrm{AND}$, $\mathrm{OR}$, and their noisy variants), using a minimalist single-head softmax-attention mechanism, where $k=\Theta(d)$ relevant bits are selected from $d$ inputs. We show that these simple $\mathrm{AND}$ and $\mathrm{OR}$ functions are unsolvable with a single-head softmax-attention mechanism alone. However, with teacher forcing, the same minimalist attention is capable of solving them. These findings offer two key insights: Architecturally, solving these Boolean tasks requires only minimalist attention, without deep Transformer blocks or FFNs. Methodologically, one gradient descent update with supervision suffices and replaces the multi-step Chain-of-Thought (CoT) reasoning scheme of [Kim and Suzuki, ICLR 2025] for solving Boolean problems. Together, the bounds expose a fundamental gap between what this minimal architecture achieves under ideal supervision and what is provably impossible under standard training.
A LSTM-Transformer Model for pulsation control of pVADs
Mar 10, 2025
Methods: A method of the pulsation for a pVAD is proposed (AP-pVAD Model). AP-pVAD Model consists of two parts: NPQ Model and LSTM-Transformer Model. (1)The NPQ Model determines the mathematical relationship between motor speed, pressure, and flow rate for the pVAD. (2)The Attention module of Transformer neural network is integrated into the LSTM neural network to form the new LSTM-Transformer Model to predict the pulsation time characteristic points for adjusting the motor speed of the pVAD. Results: The AP-pVAD Model is validated in three hydraulic experiments and an animal experiment. (1)The pressure provided by pVAD calculated with the NPQ Model has a maximum error of only 2.15 mmHg compared to the expected values. (2)The pulsation time characteristic points predicted by the LSTM-Transformer Model shows a maximum prediction error of 1.78ms, which is significantly lower than other methods. (3)The in-vivo test of pVAD in animal experiment has significant improvements in aortic pressure. Animals survive for over 27 hours after the initiation of pVAD operation. Conclusion: (1)For a given pVAD, motor speed has a linear relationship with pressure and a quadratic relationship with flow. (2)Deep learning can be used to predict pulsation characteristic time points, with the LSTM-Transformer Model demonstrating minimal prediction error and better robust performance under conditions of limited dataset sizes, elevated noise levels, and diverse hyperparameter combinations, demonstrating its feasibility and effectiveness.
Diving into Self-Evolving Training for Multimodal Reasoning
Dec 23, 2024



Reasoning ability is essential for Large Multimodal Models (LMMs). In the absence of multimodal chain-of-thought annotated data, self-evolving training, where the model learns from its own outputs, has emerged as an effective and scalable approach for enhancing reasoning abilities. Despite its growing usage, a comprehensive understanding of self-evolving training, particularly in the context of multimodal reasoning, remains limited. In this paper, we delve into the intricacies of self-evolving training for multimodal reasoning, pinpointing three key factors: Training Method, Reward Model, and Prompt Variation. We systematically examine each factor and explore how various configurations affect the training's effectiveness. Our analysis leads to a set of best practices for each factor, aimed at optimizing multimodal reasoning. Furthermore, we explore the Self-Evolution Dynamics during training and the impact of automatic balancing mechanisms in boosting performance. After all the investigations, we present a final recipe for self-evolving training in multimodal reasoning, encapsulating these design choices into a framework we call MSTaR (Multimodal Self-evolving Training for Reasoning), which is universally effective for models with different sizes on various benchmarks, e.g., surpassing the pre-evolved model significantly on 5 multimodal reasoning benchmarks without using additional human annotations, as demonstrated on MiniCPM-V-2.5 (8B), Phi-3.5-Vision (4B) and InternVL2 (2B). We believe this study fills a significant gap in the understanding of self-evolving training for multimodal reasoning and offers a robust framework for future research. Our policy and reward models, as well as the collected data, is released to facilitate further investigation in multimodal reasoning.
PhoneLM:an Efficient and Capable Small Language Model Family through Principled Pre-training
Nov 07, 2024



The interest in developing small language models (SLM) for on-device deployment is fast growing. However, the existing SLM design hardly considers the device hardware characteristics. Instead, this work presents a simple yet effective principle for SLM design: architecture searching for (near-)optimal runtime efficiency before pre-training. Guided by this principle, we develop PhoneLM SLM family (currently with 0.5B and 1.5B versions), that acheive the state-of-the-art capability-efficiency tradeoff among those with similar parameter size. We fully open-source the code, weights, and training datasets of PhoneLM for reproducibility and transparency, including both base and instructed versions. We also release a finetuned version of PhoneLM capable of accurate Android Intent invocation, and an end-to-end Android demo. All materials are available at https://github.com/UbiquitousLearning/PhoneLM.
Small Language Models: Survey, Measurements, and Insights
Sep 24, 2024



Small language models (SLMs), despite their widespread adoption in modern smart devices, have received significantly less academic attention compared to their large language model (LLM) counterparts, which are predominantly deployed in data centers and cloud environments. While researchers continue to improve the capabilities of LLMs in the pursuit of artificial general intelligence, SLM research aims to make machine intelligence more accessible, affordable, and efficient for everyday tasks. Focusing on transformer-based, decoder-only language models with 100M-5B parameters, we survey 59 state-of-the-art open-source SLMs, analyzing their technical innovations across three axes: architectures, training datasets, and training algorithms. In addition, we evaluate their capabilities in various domains, including commonsense reasoning, in-context learning, mathematics, and coding. To gain further insight into their on-device runtime costs, we benchmark their inference latency and memory footprints. Through in-depth analysis of our benchmarking data, we offer valuable insights to advance research in this field.
InstaFlow: One Step is Enough for High-Quality Diffusion-Based Text-to-Image Generation
Sep 12, 2023



Diffusion models have revolutionized text-to-image generation with its exceptional quality and creativity. However, its multi-step sampling process is known to be slow, often requiring tens of inference steps to obtain satisfactory results. Previous attempts to improve its sampling speed and reduce computational costs through distillation have been unsuccessful in achieving a functional one-step model. In this paper, we explore a recent method called Rectified Flow, which, thus far, has only been applied to small datasets. The core of Rectified Flow lies in its \emph{reflow} procedure, which straightens the trajectories of probability flows, refines the coupling between noises and images, and facilitates the distillation process with student models. We propose a novel text-conditioned pipeline to turn Stable Diffusion (SD) into an ultra-fast one-step model, in which we find reflow plays a critical role in improving the assignment between noise and images. Leveraging our new pipeline, we create, to the best of our knowledge, the first one-step diffusion-based text-to-image generator with SD-level image quality, achieving an FID (Frechet Inception Distance) of $23.3$ on MS COCO 2017-5k, surpassing the previous state-of-the-art technique, progressive distillation, by a significant margin ($37.2$ $\rightarrow$ $23.3$ in FID). By utilizing an expanded network with 1.7B parameters, we further improve the FID to $22.4$. We call our one-step models \emph{InstaFlow}. On MS COCO 2014-30k, InstaFlow yields an FID of $13.1$ in just $0.09$ second, the best in $\leq 0.1$ second regime, outperforming the recent StyleGAN-T ($13.9$ in $0.1$ second). Notably, the training of InstaFlow only costs 199 A100 GPU days. Project page:~\url{https://github.com/gnobitab/InstaFlow}.
FastFold: Reducing AlphaFold Training Time from 11 Days to 67 Hours
Mar 04, 2022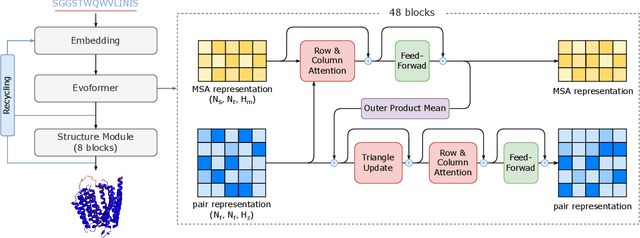
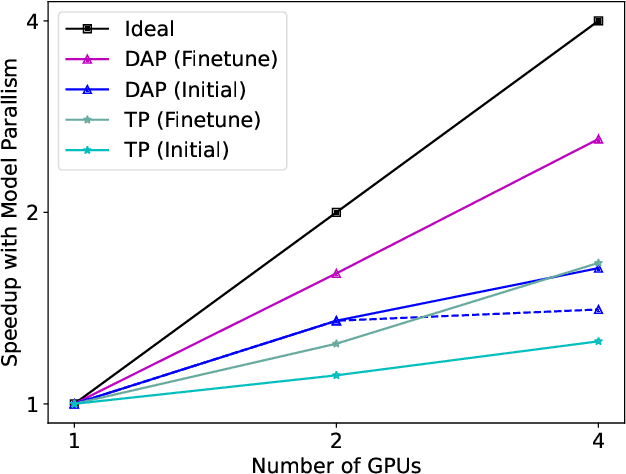
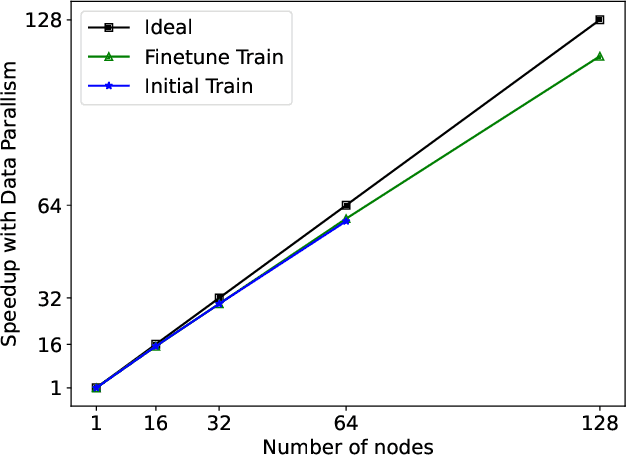
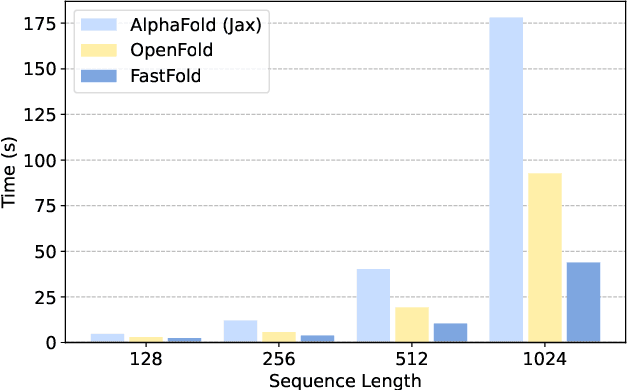
Protein structure prediction is an important method for understanding gene translation and protein function in the domain of structural biology. AlphaFold introduced the Transformer model to the field of protein structure prediction with atomic accuracy. However, training and inference of the AlphaFold model are time-consuming and expensive because of the special performance characteristics and huge memory consumption. In this paper, we propose FastFold, a highly efficient implementation of the protein structure prediction model for training and inference. FastFold includes a series of GPU optimizations based on a thorough analysis of AlphaFold's performance. Meanwhile, with Dynamic Axial Parallelism and Duality Async Operation, FastFold achieves high model parallelism scaling efficiency, surpassing existing popular model parallelism techniques. Experimental results show that FastFold reduces overall training time from 11 days to 67 hours and achieves 7.5-9.5X speedup for long-sequence inference. Furthermore, We scaled FastFold to 512 GPUs and achieved an aggregate of 6.02 PetaFLOPs with 90.1% parallel efficiency. The implementation can be found at https://github.com/hpcaitech/FastFold
Efficient Training of Deep Classifiers for Wireless Source Identification using Test SNR Estimates
Dec 26, 2019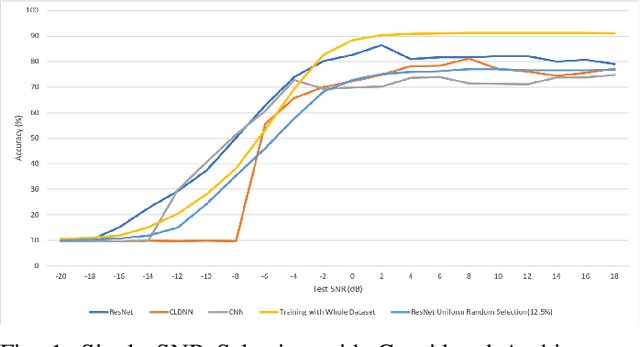
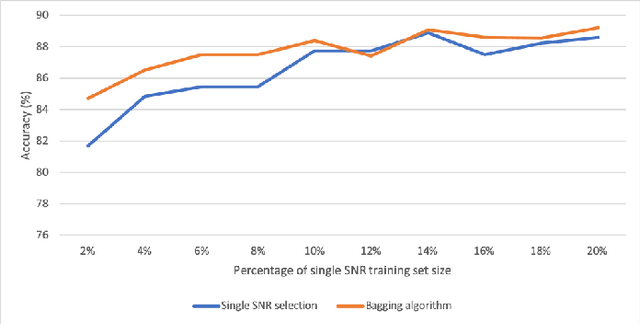
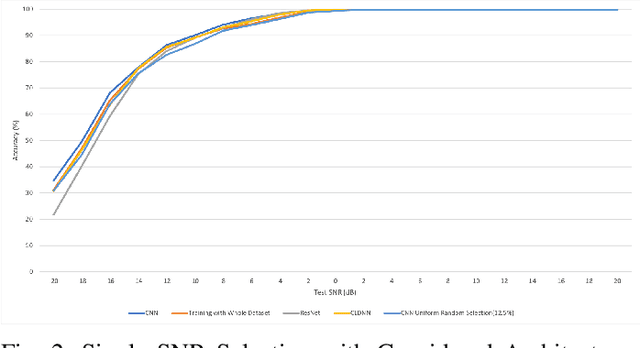
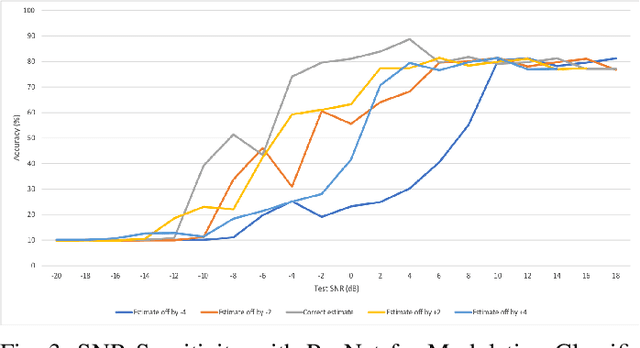
We investigate the potential of training time reduction for deep learning algorithms that process received wireless signals, if an accurate test Signal to Noise Ratio (SNR) estimate is available. Our focus is on two tasks that facilitate source identification: 1- Identifying the modulation type, 2- Identifying the wireless technology and channel index in the 2.4 GHZ ISM band. For benchmarking, we rely on a fast growing recent literature on testing deep learning algorithms against two well-known synthetic datasets. We first demonstrate that using training data corresponding only to the test SNR value leads to dramatic reductions in training time - that can reach up to 35x - while incurring a small loss in average test accuracy, as it improves the accuracy for low test SNR values. Further, we show that an erroneous test SNR estimate with a small positive offset is better for training than another having the same error magnitude with a negative offset. Secondly, we introduce a greedy training SNR Boosting algorithm that leads to uniform improvement in test accuracy across all tested SNR values, while using only a small subset of training SNR values at each test SNR. Finally, we discuss, with empirical evidence, the potential of bootstrap aggregating (Bagging) based on training SNR values to improve generalization at low test SNR
Deep Learning for Interference Identification: Band, Training SNR, and Sample Selection
May 16, 2019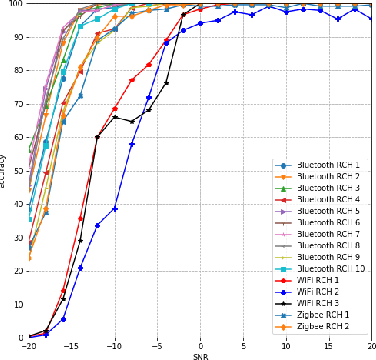
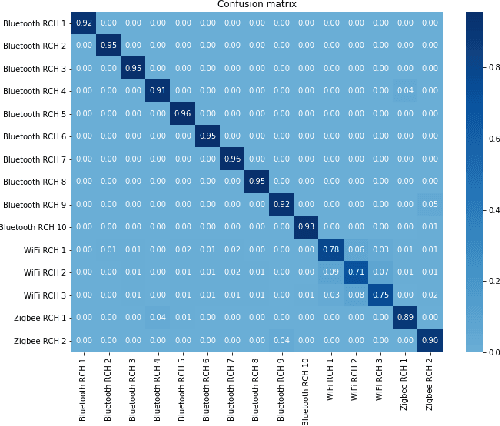
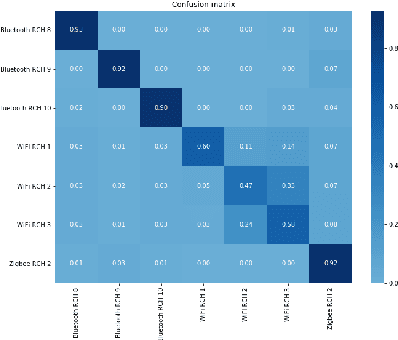
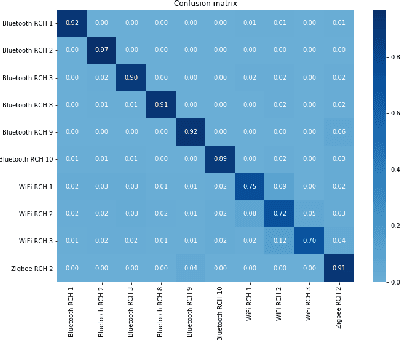
We study the problem of interference source identification, through the lens of recognizing one of 15 different channels that belong to 3 different wireless technologies: Bluetooth, Zigbee, and WiFi. We employ deep learning algorithms trained on received samples taken from a 10 MHz band in the 2.4 GHz ISM Band. We obtain a classification accuracy of around 89.5% using any of four different deep neural network architectures: CNN, ResNet, CLDNN, and LSTM, which demonstrate the generality of the effectiveness of deep learning at the considered task. Interestingly, our proposed CNN architecture requires approximately 60% of the training time required by the state of the art while achieving slightly larger classification accuracy. We then focus on the CNN architecture and further optimize its training time while incurring minimal loss in classification accuracy using three different approaches: 1- Band Selection, where we only use samples belonging to the lower and uppermost 2 MHz bands, 2- SNR Selection, where we only use training samples belonging to a single SNR value, and 3- Sample Selection, where we try various sub-Nyquist sampling methods to select the subset of samples most relevant to the classification task. Our results confirm the feasibility of fast deep learning for wireless interference identification, by showing that the training time can be reduced by as much as 30x with minimal loss in accuracy.