 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-level Contrastive Learning for Cross-lingual Spoken Language Understanding
May 07, 2022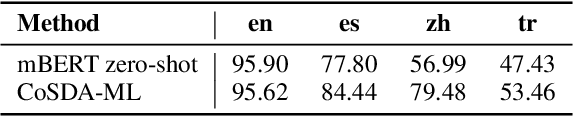
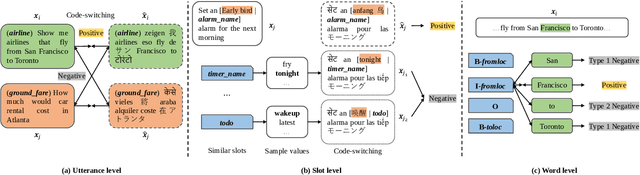
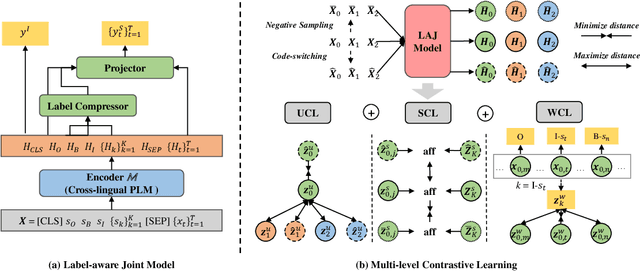
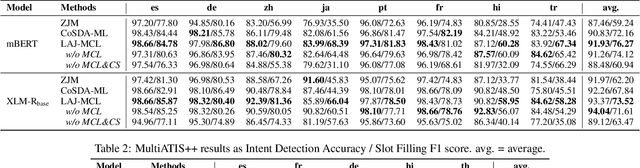
Although spoken language understanding (SLU) has achieved great success in high-resource languages, such as English, it remains challenging in low-resource languages mainly due to the lack of high quality training data. The recent multilingual code-switching approach samples some words in an input utterance and replaces them by expressions in some other languages of the same meaning. The multilingual code-switching approach achieves better alignments of representations across languages in zero-shot cross-lingual SLU. Surprisingly, all existing multilingual code-switching methods disregard the inherent semantic structure in SLU, i.e., most utterances contain one or more slots, and each slot consists of one or more words. In this paper, we propose to exploit the "utterance-slot-word" structure of SLU and systematically model this structure by a multi-level contrastive learning framework at the utterance, slot, and word levels. We develop novel code-switching schemes to generate hard negative examples for contrastive learning at all levels. Furthermore, we develop a label-aware joint model to leverage label semantics for cross-lingual knowledge transfer. Our experimental results show that our proposed methods significantly improve the performance compared with the strong baselines on two zero-shot cross-lingual SLU benchmark datasets.
Spatial-Temporal Hypergraph Self-Supervised Learning for Crime Prediction
Apr 18, 2022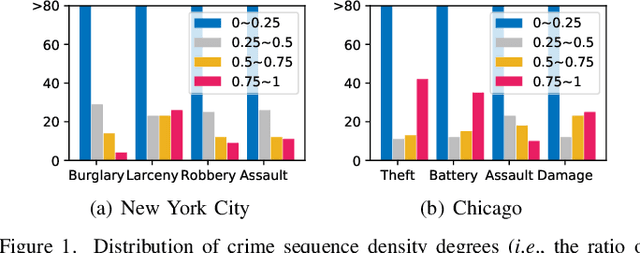
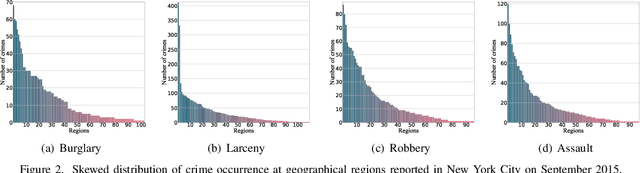
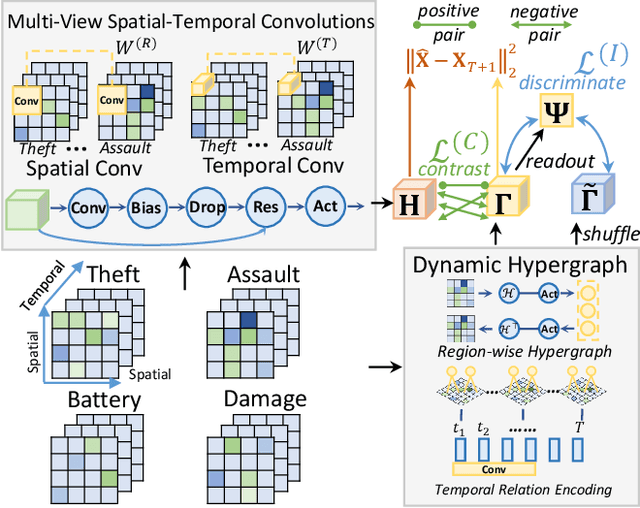
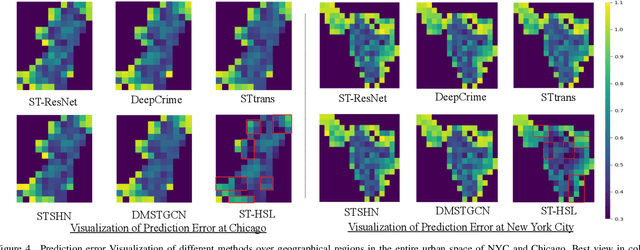
Crime has become a major concern in many cities, which calls for the rising demand for timely predicting citywide crime occurrence. Accurate crime prediction results are vital for the beforehand decision-making of government to alleviate the increasing concern about the public safety. While many efforts have been devoted to proposing various spatial-temporal forecasting techniques to explore dependence across locations and time periods, most of them follow a supervised learning manner, which limits their spatial-temporal representation ability on sparse crime data. Inspired by the recent success in self-supervised learning, this work proposes a Spatial-Temporal Hypergraph Self-Supervised Learning framework (ST-HSL) to tackle the label scarcity issue in crime prediction. Specifically, we propose the cross-region hypergraph structure learning to encode region-wise crime dependency under the entire urban space. Furthermore, we design the dual-stage self-supervised learning paradigm, to not only jointly capture local- and global-level spatial-temporal crime patterns, but also supplement the sparse crime representation by augmenting region self-discrimination. We perform extensive experiments on two real-life crime datasets. Evaluation results show that our ST-HSL significantly outperforms state-of-the-art baselines. Further analysis provides insights into the superiority of our ST-HSL method in the representation of spatial-temporal crime patterns. The implementation code is available at https://github.com/LZH-YS1998/STHSL.
Bridging the Gap between Language Models and Cross-Lingual Sequence Labeling
Apr 11, 2022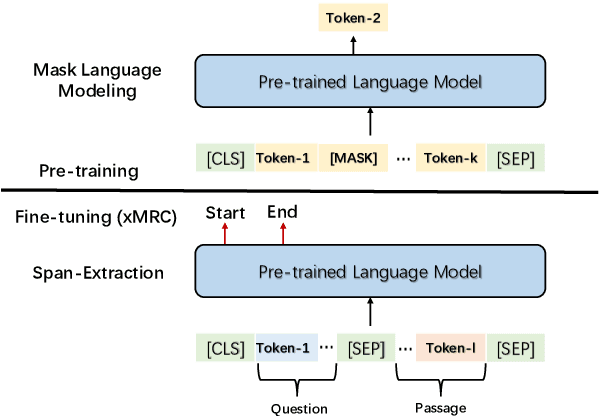


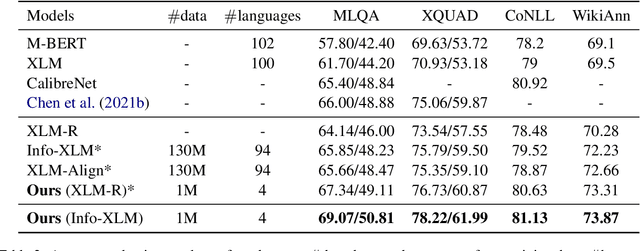
Large-scale cross-lingual pre-trained language models (xPLMs) have shown effectiveness in cross-lingual sequence labeling tasks (xSL), such as cross-lingual machine reading comprehension (xMRC) by transferring knowledge from a high-resource language to low-resource languages. Despite the great success, we draw an empirical observation that there is a training objective gap between pre-training and fine-tuning stages: e.g., mask language modeling objective requires local understanding of the masked token and the span-extraction objective requires global understanding and reasoning of the input passage/paragraph and question, leading to the discrepancy between pre-training and xMRC. In this paper, we first design a pre-training task tailored for xSL named Cross-lingual Language Informative Span Masking (CLISM) to eliminate the objective gap in a self-supervised manner. Second, we present ContrAstive-Consistency Regularization (CACR), which utilizes contrastive learning to encourage the consistency between representations of input parallel sequences via unsupervised cross-lingual instance-wise training signals during pre-training. By these means, our methods not only bridge the gap between pretrain-finetune, but also enhance PLMs to better capture the alignment between different languages. Extensive experiments prove that our method achieves clearly superior results on multiple xSL benchmarks with limited pre-training data. Our methods also surpass the previous state-of-the-art methods by a large margin in few-shot data settings, where only a few hundred training examples are available.
Membership Privacy Protection for Image Translation Models via Adversarial Knowledge Distillation
Mar 10, 2022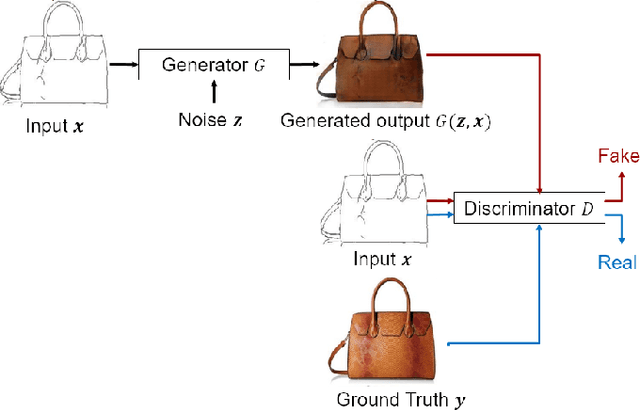
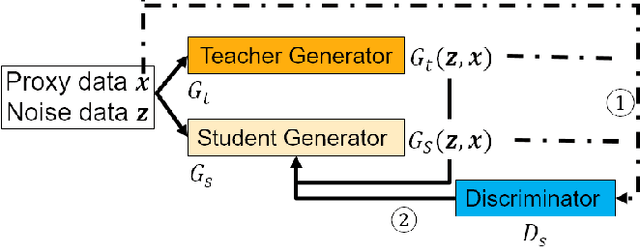
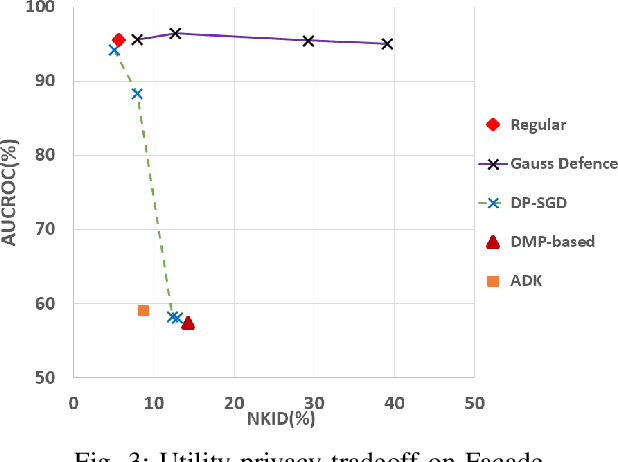
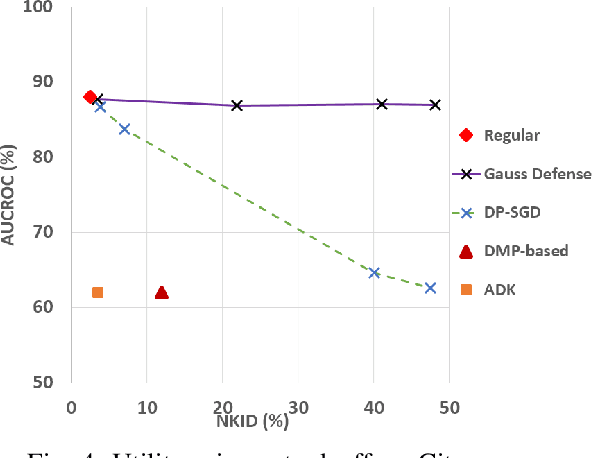
Image-to-image translation models are shown to be vulnerable to the Membership Inference Attack (MIA), in which the adversary's goal is to identify whether a sample is used to train the model or not. With daily increasing applications based on image-to-image translation models, it is crucial to protect the privacy of these models against MIAs. We propose adversarial knowledge distillation (AKD) as a defense method against MIAs for image-to-image translation models. The proposed method protects the privacy of the training samples by improving the generalizability of the model. We conduct experiments on the image-to-image translation models and show that AKD achieves the state-of-the-art utility-privacy tradeoff by reducing the attack performance up to 38.9% compared with the regular training model at the cost of a slight drop in the quality of the generated output images. The experimental results also indicate that the models trained by AKD generalize better than the regular training models. Furthermore, compared with existing defense methods, the results show that at the same privacy protection level, image translation models trained by AKD generate outputs with higher quality; while at the same quality of outputs, AKD enhances the privacy protection over 30%.
Fair and efficient contribution valuation for vertical federated learning
Jan 07, 2022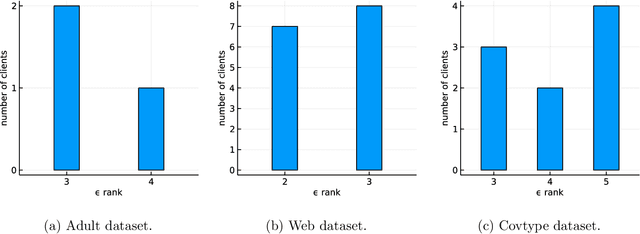
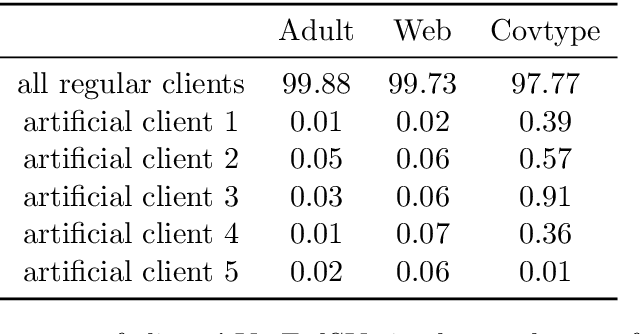
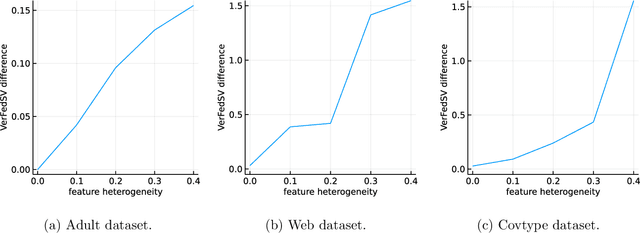
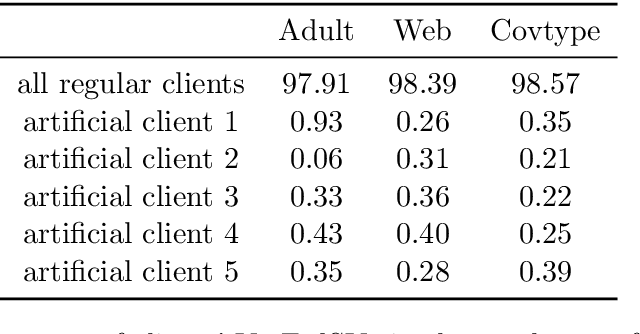
Federated learning is a popular technology for training machine learning models on distributed data sources without sharing data. Vertical federated learning or feature-based federated learning applies to the cases that different data sources share the same sample ID space but differ in feature space. To ensure the data owners' long-term engagement, it is critical to objectively assess the contribution from each data source and recompense them accordingly. The Shapley value (SV) is a provably fair contribution valuation metric originated from cooperative game theory. However, computing the SV requires extensively retraining the model on each subset of data sources, which causes prohibitively high communication costs in federated learning. We propose a contribution valuation metric called vertical federated Shapley value (VerFedSV) based on SV. We show that VerFedSV not only satisfies many desirable properties for fairness but is also efficient to compute, and can be adapted to both synchronous and asynchronous vertical federated learning algorithms. Both theoretical analysis and extensive experimental results verify the fairness, efficiency, and adaptability of VerFedSV.
Multi-Choice Questions based Multi-Interest Policy Learning for Conversational Recommendation
Dec 22, 2021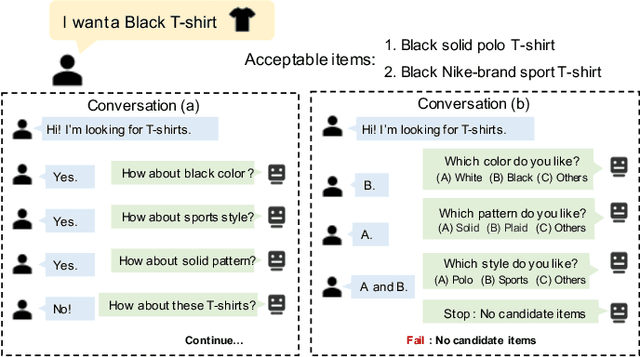
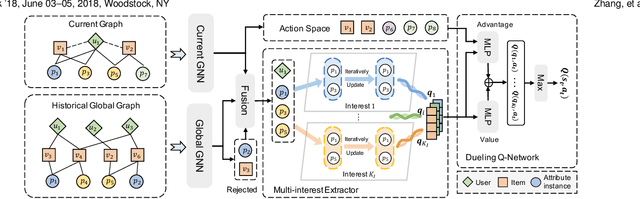
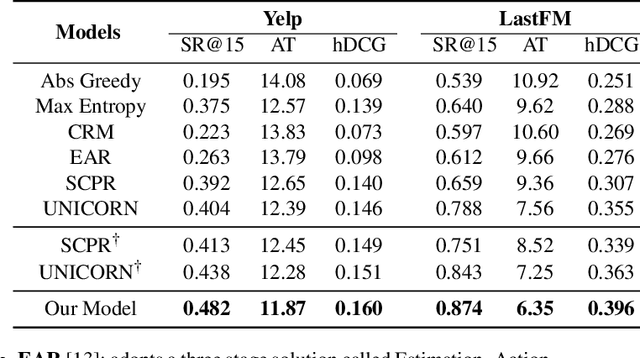
Conversational recommendation system (CRS) is able to obtain fine-grained and dynamic user preferences based on interactive dialogue. Previous CRS assumes that the user has a clear target item. However, for many users who resort to CRS, they might not have a clear idea about what they really like. Specifically, the user may have a clear single preference for some attribute types (e.g. color) of items, while for other attribute types, the user may have multiple preferences or even no clear preferences, which leads to multiple acceptable attribute instances (e.g. black and red) of one attribute type. Therefore, the users could show their preferences over items under multiple combinations of attribute instances rather than a single item with unique combination of all attribute instances. As a result, we first propose a more realistic CRS learning setting, namely Multi-Interest Multi-round Conversational Recommendation, where users may have multiple interests in attribute instance combinations and accept multiple items with partially overlapped combinations of attribute instances. To effectively cope with the new CRS learning setting, in this paper, we propose a novel learning framework namely, Multi-Choice questions based Multi-Interest Policy Learning . In order to obtain user preferences more efficiently, the agent generates multi-choice questions rather than binary yes/no ones on specific attribute instance. Besides, we propose a union set strategy to select candidate items instead of existing intersection set strategy in order to overcome over-filtering items during the conversation. Finally, we design a Multi-Interest Policy Learning module, which utilizes captured multiple interests of the user to decide next action, either asking attribute instances or recommending items. Extensive experimental results on four datasets verify the superiority of our method for the proposed setting.
Mining Minority-class Examples With Uncertainty Estimates
Dec 15, 2021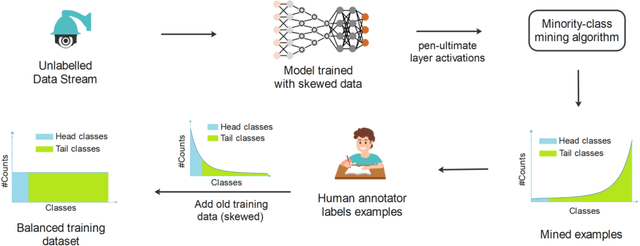

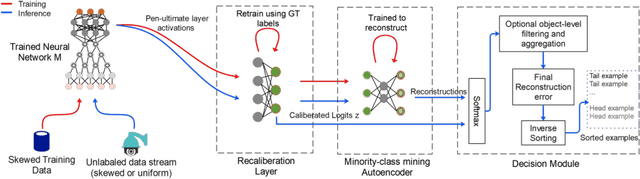
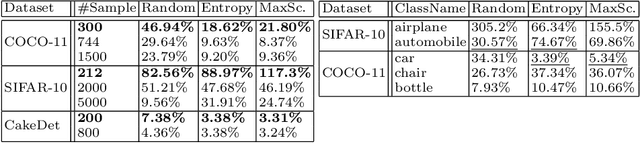
In the real world, the frequency of occurrence of objects is naturally skewed forming long-tail class distributions, which results in poor performance on the statistically rare classes. A promising solution is to mine tail-class examples to balance the training dataset. However, mining tail-class examples is a very challenging task. For instance, most of the otherwise successful uncertainty-based mining approaches struggle due to distortion of class probabilities resulting from skewness in data. In this work, we propose an effective, yet simple, approach to overcome these challenges. Our framework enhances the subdued tail-class activations and, thereafter, uses a one-class data-centric approach to effectively identify tail-class examples. We carry out an exhaustive evaluation of our framework on three datasets spanning over two computer vision tasks. Substantial improvements in the minority-class mining and fine-tuned model's performance strongly corroborate the value of our proposed solution.
From Good to Best: Two-Stage Training for Cross-lingual Machine Reading Comprehension
Dec 09, 2021
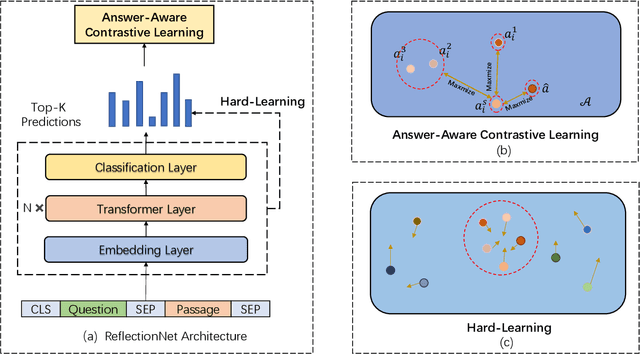
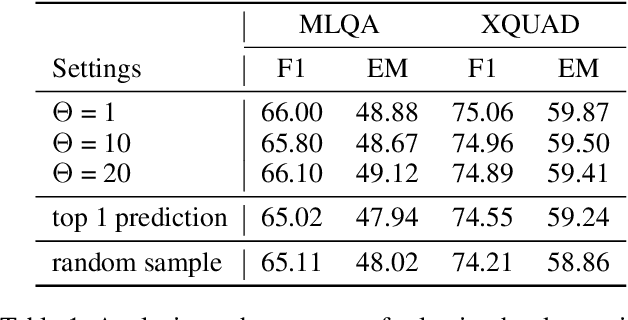
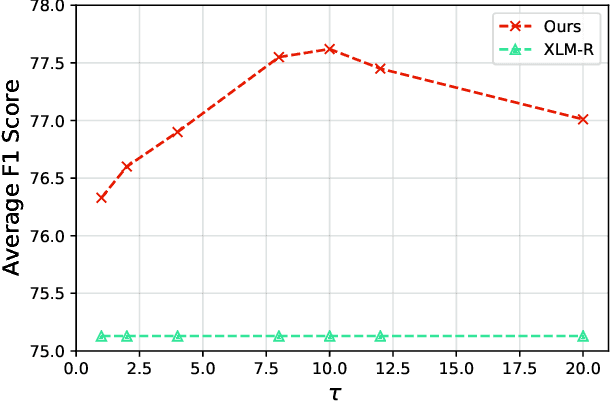
Cross-lingual Machine Reading Comprehension (xMRC) is challenging due to the lack of training data in low-resource languages. The recent approaches use training data only in a resource-rich language like English to fine-tune large-scale cross-lingual pre-trained language models. Due to the big difference between languages, a model fine-tuned only by a source language may not perform well for target languages. Interestingly, we observe that while the top-1 results predicted by the previous approaches may often fail to hit the ground-truth answers, the correct answers are often contained in the top-k predicted results. Based on this observation, we develop a two-stage approach to enhance the model performance. The first stage targets at recall: we design a hard-learning (HL) algorithm to maximize the likelihood that the top-k predictions contain the accurate answer. The second stage focuses on precision: an answer-aware contrastive learning (AA-CL) mechanism is developed to learn the fine difference between the accurate answer and other candidates. Our extensive experiments show that our model significantly outperforms a series of strong baselines on two cross-lingual MRC benchmark datasets.
Knowledge-Enhanced Hierarchical Graph Transformer Network for Multi-Behavior Recommendation
Oct 08, 2021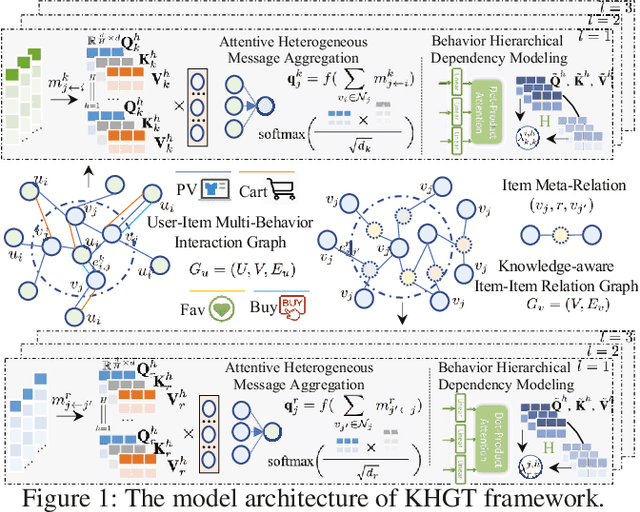

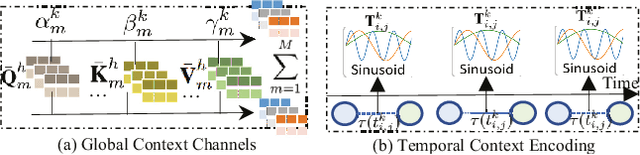
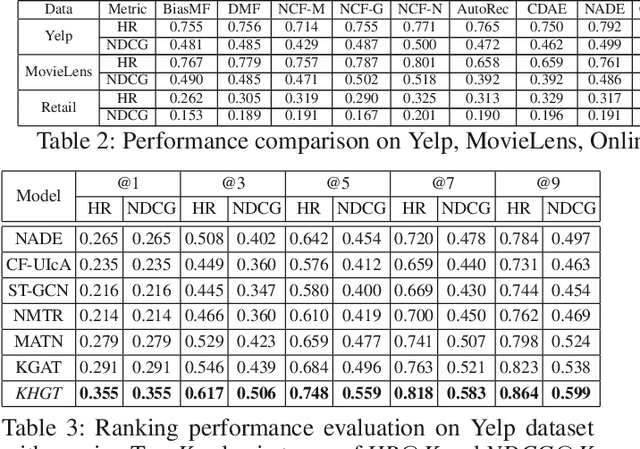
Accurate user and item embedding learning is crucial for modern recommender systems. However, most existing recommendation techniques have thus far focused on modeling users' preferences over singular type of user-item interactions. Many practical recommendation scenarios involve multi-typed user interactive behaviors (e.g., page view, add-to-favorite and purchase), which presents unique challenges that cannot be handled by current recommendation solutions. In particular: i) complex inter-dependencies across different types of user behaviors; ii) the incorporation of knowledge-aware item relations into the multi-behavior recommendation framework; iii) dynamic characteristics of multi-typed user-item interactions. To tackle these challenges, this work proposes a Knowledge-Enhanced Hierarchical Graph Transformer Network (KHGT), to investigate multi-typed interactive patterns between users and items in recommender systems. Specifically, KHGT is built upon a graph-structured neural architecture to i) capture type-specific behavior characteristics; ii) explicitly discriminate which types of user-item interactions are more important in assisting the forecasting task on the target behavior. Additionally, we further integrate the graph attention layer with the temporal encoding strategy, to empower the learned embeddings be reflective of both dedicated multiplex user-item and item-item relations, as well as the underlying interaction dynamics. Extensive experiments conducted on three real-world datasets show that KHGT consistently outperforms many state-of-the-art recommendation methods across various evaluation settings. Our implementation code is available at https://github.com/akaxlh/KHGT.
AsySQN: Faster Vertical Federated Learning Algorithms with Better Computation Resource Utilization
Sep 26, 2021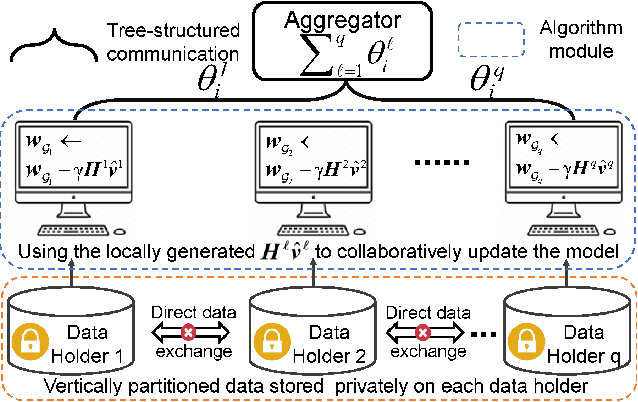


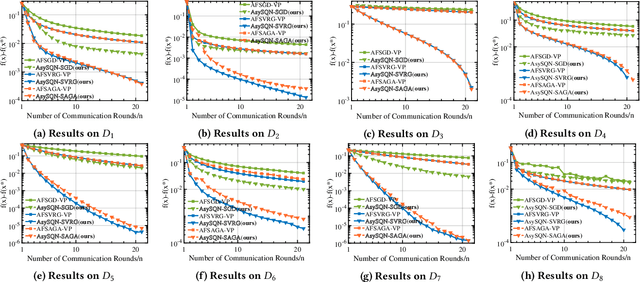
Vertical federated learning (VFL) is an effective paradigm of training the emerging cross-organizational (e.g., different corporations, companies and organizations) collaborative learning with privacy preserving. Stochastic gradient descent (SGD) methods are the popular choices for training VFL models because of the low per-iteration computation. However, existing SGD-based VFL algorithms are communication-expensive due to a large number of communication rounds. Meanwhile, most existing VFL algorithms use synchronous computation which seriously hamper the computation resource utilization in real-world applications. To address the challenges of communication and computation resource utilization, we propose an asynchronous stochastic quasi-Newton (AsySQN) framework for VFL, under which three algorithms, i.e. AsySQN-SGD, -SVRG and -SAGA, are proposed. The proposed AsySQN-type algorithms making descent steps scaled by approximate (without calculating the inverse Hessian matrix explicitly) Hessian information convergence much faster than SGD-based methods in practice and thus can dramatically reduce the number of communication rounds. Moreover, the adopted asynchronous computation can make better use of the computation resource. We theoretically prove the convergence rates of our proposed algorithms for strongly convex problems. Extensive numerical experiments on real-word datasets demonstrate the lower communication costs and better computation resource utilization of our algorithms compared with state-of-the-art VFL algorithms.