 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsySQN: Faster Vertical Federated Learning Algorithms with Better Computation Resource Utilization
Sep 26, 2021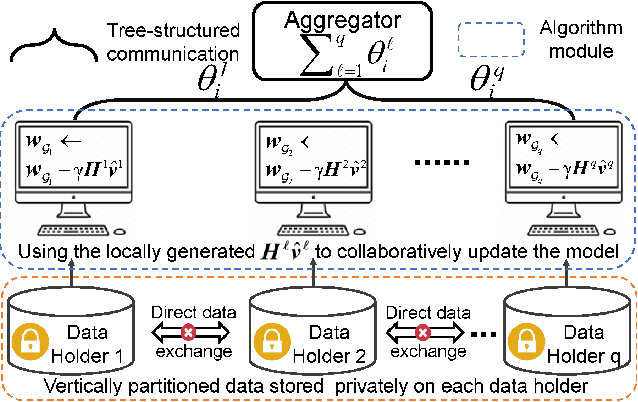


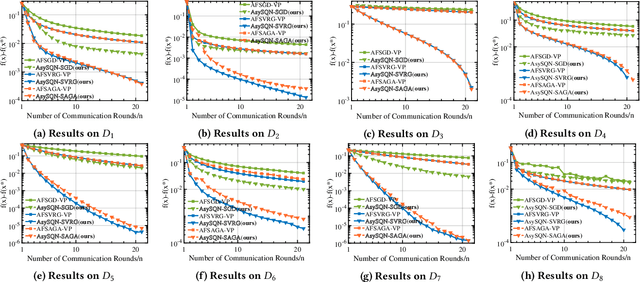
Vertical federated learning (VFL) is an effective paradigm of training the emerging cross-organizational (e.g., different corporations, companies and organizations) collaborative learning with privacy preserving. Stochastic gradient descent (SGD) methods are the popular choices for training VFL models because of the low per-iteration computation. However, existing SGD-based VFL algorithms are communication-expensive due to a large number of communication rounds. Meanwhile, most existing VFL algorithms use synchronous computation which seriously hamper the computation resource utilization in real-world applications. To address the challenges of communication and computation resource utilization, we propose an asynchronous stochastic quasi-Newton (AsySQN) framework for VFL, under which three algorithms, i.e. AsySQN-SGD, -SVRG and -SAGA, are proposed. The proposed AsySQN-type algorithms making descent steps scaled by approximate (without calculating the inverse Hessian matrix explicitly) Hessian information convergence much faster than SGD-based methods in practice and thus can dramatically reduce the number of communication rounds. Moreover, the adopted asynchronous computation can make better use of the computation resource. We theoretically prove the convergence rates of our proposed algorithms for strongly convex problems. Extensive numerical experiments on real-word datasets demonstrate the lower communication costs and better computation resource utilization of our algorithms compared with state-of-the-art VFL algorithms.
Similarity Kernel and Clustering via Random Projection Forests
Aug 28, 2019
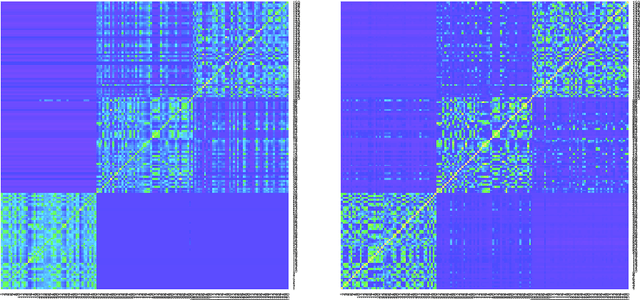
Similarity plays a fundamental role in many areas, including data mining, machine learning, statistics and various applied domains. Inspired by the success of ensemble methods and the flexibility of trees, we propose to learn a similarity kernel called rpf-kernel through random projection forests (rpForests). Our theoretical analysis reveals a highly desirable property of rpf-kernel: far-away (dissimilar) points have a low similarity value while nearby (similar) points would have a high similarity}, and the similarities have a native interpretation as the probability of points remaining in the same leaf nodes during the growth of rpForests. The learned rpf-kernel leads to an effective clustering algorithm--rpfCluster. On a wide variety of real and benchmark datasets, rpfCluster compares favorably to K-means clustering, spectral clustering and a state-of-the-art clustering ensemble algorithm--Cluster Forests. Our approach is simple to implement and readily adapt to the geometry of the underlying data. Given its desirable theoretical property and competitive empirical performance when applied to clustering, we expect rpf-kernel to be applicable to many problems of an unsupervised nature or as a regularizer in some supervised or weakly supervised settings.
Cost-sensitive Selection of Variables by Ensemble of Model Sequences
Jan 02, 2019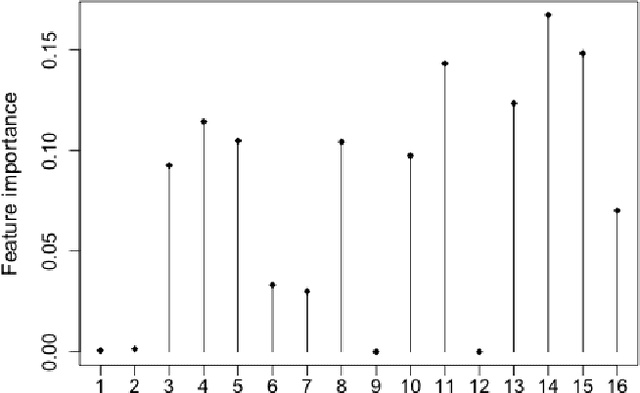
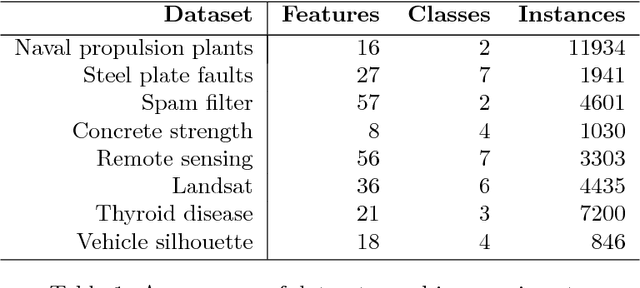
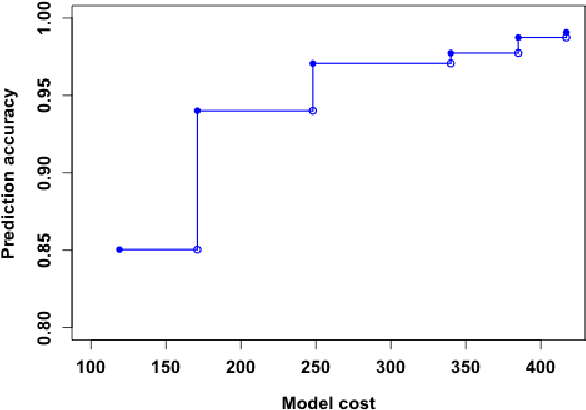
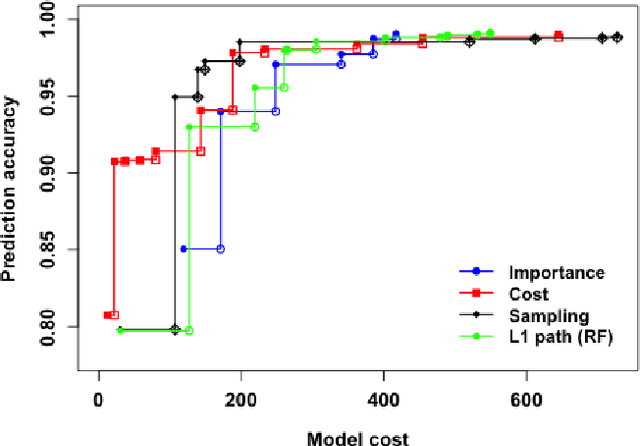
Many applications require the collection of data on different variables or measurements over many system performance metrics. We term those broadly as measures or variables. Often data collection along each measure incurs a cost, thus it is desirable to consider the cost of measures in modeling. This is a fairly new class of problems in the area of cost-sensitive learning. A few attempts have been made to incorporate costs in combining and selecting measures. However, existing studies either do not strictly enforce a budget constraint, or are not the `most' cost effective. With a focus on classification problem, we propose a computationally efficient approach that could find a near optimal model under a given budget by exploring the most `promising' part of the solution space. Instead of outputting a single model, we produce a model schedule---a list of models, sorted by model costs and expected predictive accuracy. This could be used to choose the model with the best predictive accuracy under a given budget, or to trade off between the budget and the predictive accuracy. Experiments on some benchmark datasets show that our approach compares favorably to competing methods.