 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Zero-shot Network Quantization
Jan 21, 2021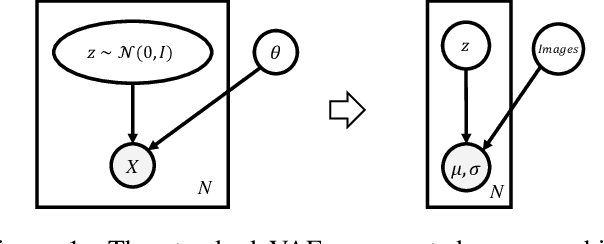
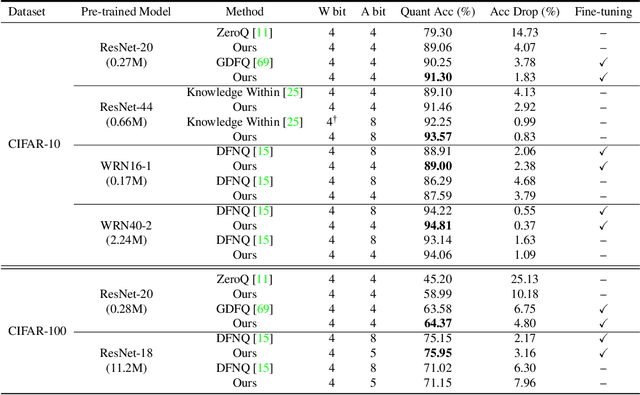
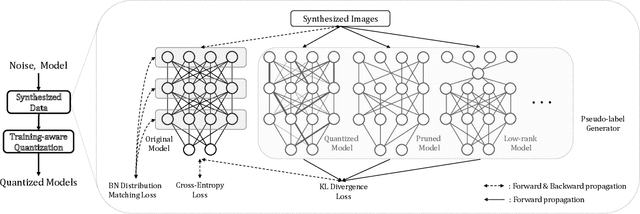
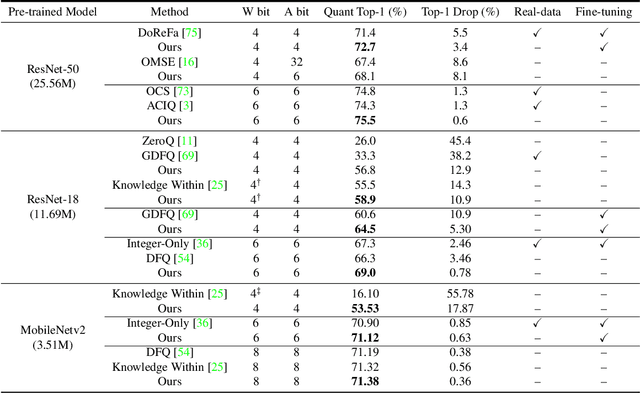
Convolutional neural networks are able to learn realistic image priors from numerous training samples in low-level image generation and restoration. We show that, for high-level image recognition tasks, we can further reconstruct "realistic" images of each category by leveraging intrinsic Batch Normalization (BN) statistics without any training data. Inspired by the popular VAE/GAN methods, we regard the zero-shot optimization process of synthetic images as generative modeling to match the distribution of BN statistics. The generated images serve as a calibration set for the following zero-shot network quantizations. Our method meets the needs for quantizing models based on sensitive information, \textit{e.g.,} due to privacy concerns, no data is available. Extensive experiments on benchmark datasets show that, with the help of generated data, our approach consistently outperforms existing data-free quantization methods.
Multi-Faceted Representation Learning with Hybrid Architecture for Time Series Classification
Dec 21, 2020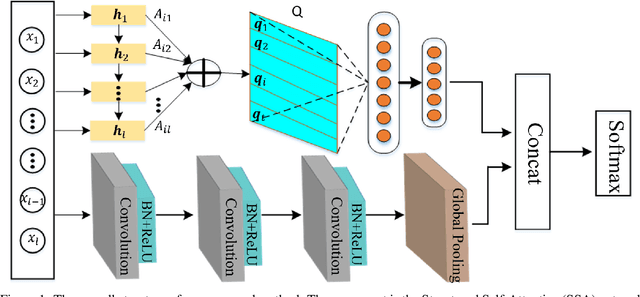
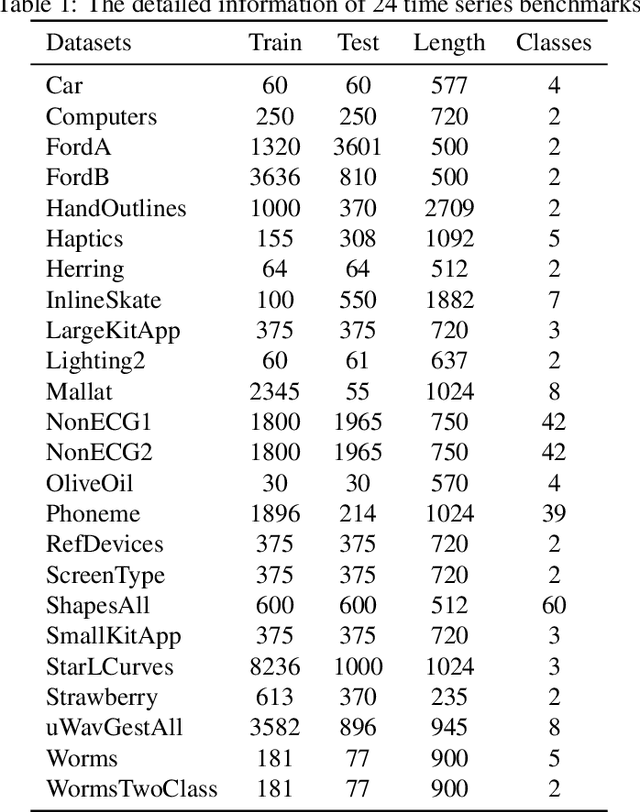
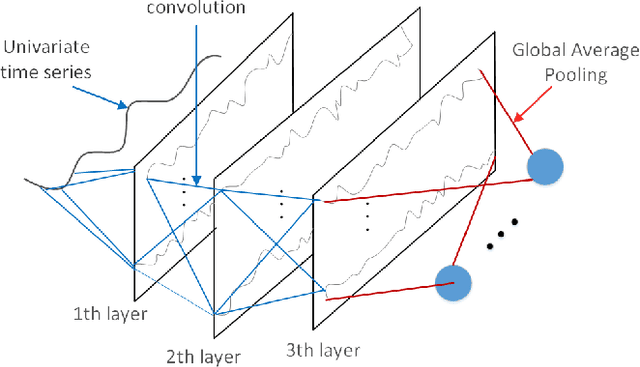
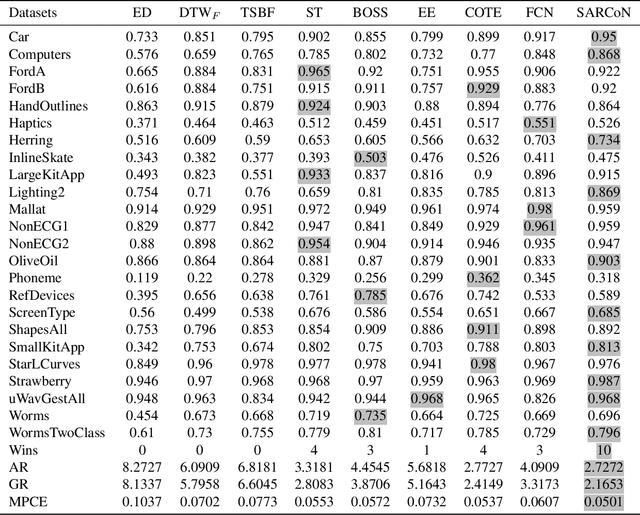
Time series classification problems exist in many fields and have been explored for a couple of decades. However, they still remain challenging, and their solutions need to be further improved for real-world applications in terms of both accuracy and efficiency. In this paper, we propose a hybrid neural architecture, called Self-Attentive Recurrent Convolutional Networks (SARCoN), to learn multi-faceted representations for univariate time series. SARCoN is the synthesis of long short-term memory networks with self-attentive mechanisms and Fully Convolutional Networks, which work in parallel to learn the representations of univariate time series from different perspectives. The component modules of the proposed architecture are trained jointly in an end-to-end manner and they classify the input time series in a cooperative way. Due to its domain-agnostic nature, SARCoN is able to generalize a diversity of domain tasks. Our experimental results show that, compared to the state-of-the-art approaches for time series classification, the proposed architecture can achieve remarkable improvements for a set of univariate time series benchmarks from the UCR repository. Moreover, the self-attention and the global average pooling in the proposed architecture enable visible interpretability by facilitating the identification of the contribution regions of the original time series. An overall analysis confirms that multi-faceted representations of time series aid in capturing deep temporal corrections within complex time series, which is essential for the improvement of time series classification performance. Our work provides a novel angle that deepens the understanding of time series classification, qualifying our proposed model as an ideal choice for real-world applications.
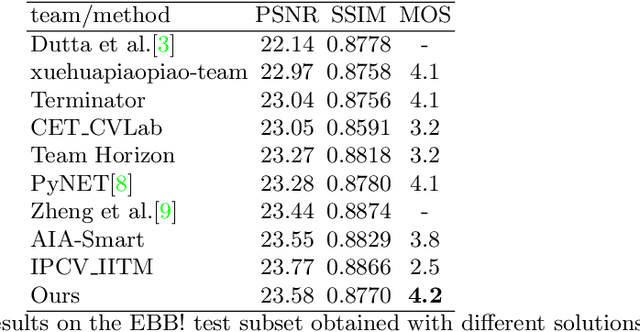
AIM 2020 Challenge on Rendering Realistic Bokeh
Nov 10, 2020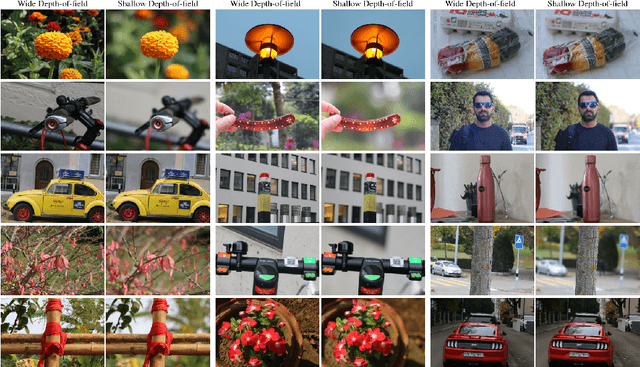


This paper reviews the second AIM realistic bokeh effect rendering challenge and provides the description of the proposed solutions and results. The participating teams were solving a real-world bokeh simulation problem, where the goal was to learn a realistic shallow focus technique using a large-scale EBB! bokeh dataset consisting of 5K shallow / wide depth-of-field image pairs captured using the Canon 7D DSLR camera. The participants had to render bokeh effect based on only one single frame without any additional data from other cameras or sensors. The target metric used in this challenge combined the runtime and the perceptual quality of the solutions measured in the user study. To ensure the efficiency of the submitted models, we measured their runtime on standard desktop CPUs as well as were running the models on smartphone GPUs. The proposed solutions significantly improved the baseline results, defining the state-of-the-art for practical bokeh effect rendering problem.
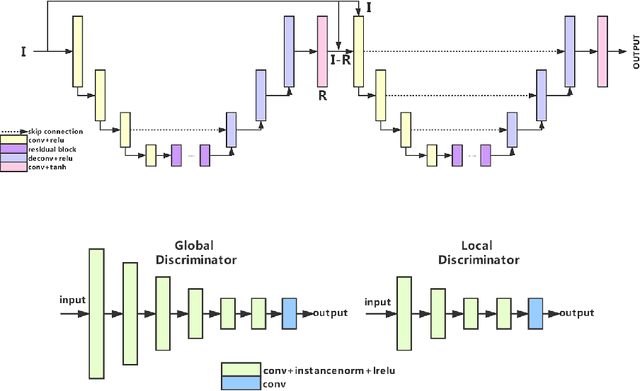
BGGAN: Bokeh-Glass Generative Adversarial Network for Rendering Realistic Bokeh
Nov 04, 2020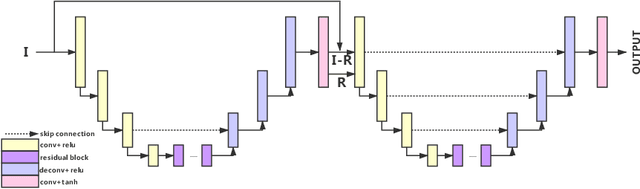
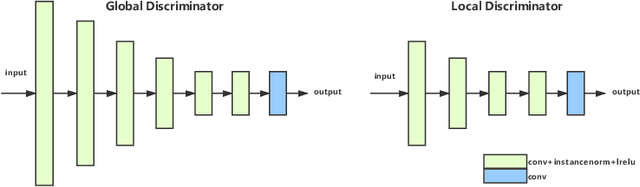
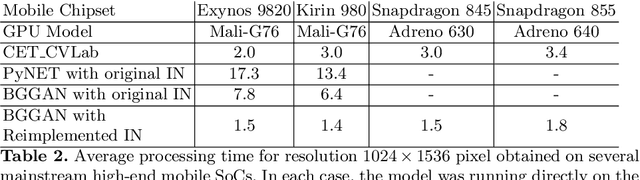
A photo captured with bokeh effect often means objects in focus are sharp while the out-of-focus areas are all blurred. DSLR can easily render this kind of effect naturally. However, due to the limitation of sensors, smartphones cannot capture images with depth-of-field effects directly. In this paper, we propose a novel generator called Glass-Net, which generates bokeh images not relying on complex hardware. Meanwhile, the GAN-based method and perceptual loss are combined for rendering a realistic bokeh effect in the stage of finetuning the model. Moreover, Instance Normalization(IN) is reimplemented in our network, which ensures our tflite model with IN can be accelerated on smartphone GPU. Experiments show that our method is able to render a high-quality bokeh effect and process one $1024 \times 1536$ pixel image in 1.9 seconds on all smartphone chipsets. This approach ranked First in AIM 2020 Rendering Realistic Bokeh Challenge Track 1 \& Track 2.
Taking Modality-free Human Identification as Zero-shot Learning
Oct 02, 2020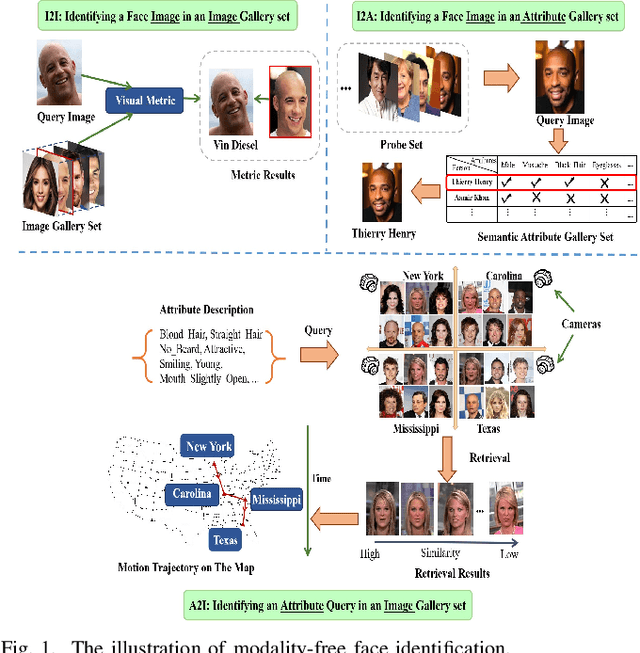
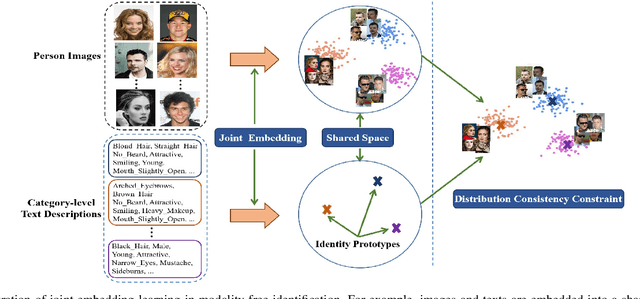
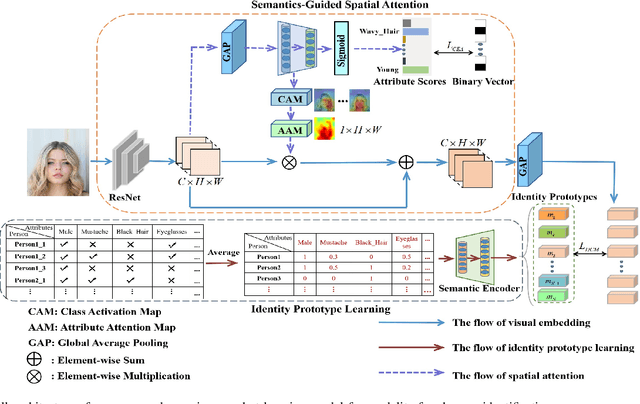

Human identification is an important topic in event detection, person tracking, and public security. There have been numerous methods proposed for human identification, such as face identification, person re-identification, and gait identification. Typically, existing methods predominantly classify a queried image to a specific identity in an image gallery set (I2I). This is seriously limited for the scenario where only a textual description of the query or an attribute gallery set is available in a wide range of video surveillance applications (A2I or I2A). However, very few efforts have been devoted towards modality-free identification, i.e., identifying a query in a gallery set in a scalable way. In this work, we take an initial attempt, and formulate such a novel Modality-Free Human Identification (named MFHI) task as a generic zero-shot learning model in a scalable way. Meanwhile, it is capable of bridging the visual and semantic modalities by learning a discriminative prototype of each identity. In addition, the semantics-guided spatial attention is enforced on visual modality to obtain representations with both high global category-level and local attribute-level discrimination. Finally, we design and conduct an extensive group of experiments on two common challenging identification tasks, including face identification and person re-identification, demonstrating that our method outperforms a wide variety of state-of-the-art methods on modality-free human identification.
AIM 2020: Scene Relighting and Illumination Estimation Challenge
Sep 27, 2020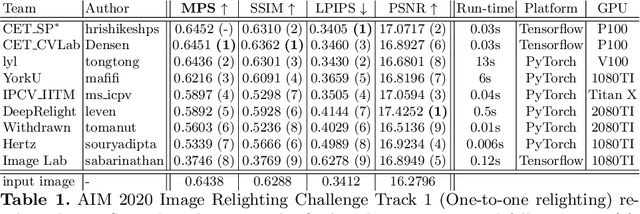

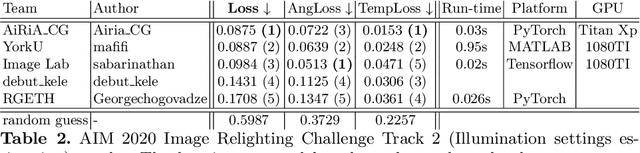

We review the AIM 2020 challenge on virtual image relighting and illumination estimation. This paper presents the novel VIDIT dataset used in the challenge and the different proposed solutions and final evaluation results over the 3 challenge tracks. The first track considered one-to-one relighting; the objective was to relight an input photo of a scene with a different color temperature and illuminant orientation (i.e., light source position). The goal of the second track was to estimate illumination settings, namely the color temperature and orientation, from a given image. Lastly, the third track dealt with any-to-any relighting, thus a generalization of the first track. The target color temperature and orientation, rather than being pre-determined, are instead given by a guide image. Participants were allowed to make use of their track 1 and 2 solutions for track 3. The tracks had 94, 52, and 56 registered participants, respectively, leading to 20 confirmed submissions in the final competition stage.
AIM 2020 Challenge on Efficient Super-Resolution: Methods and Results
Sep 15, 2020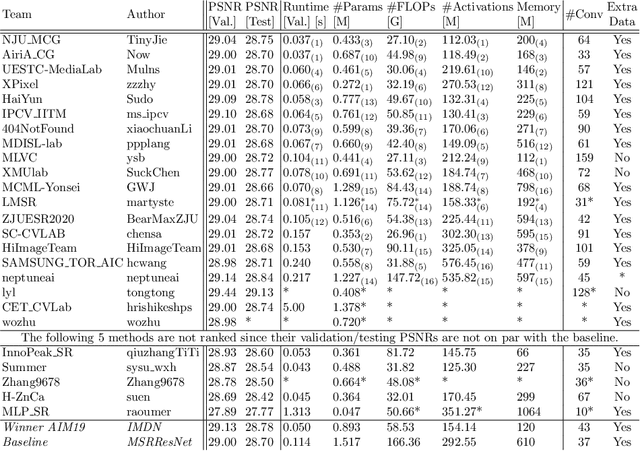
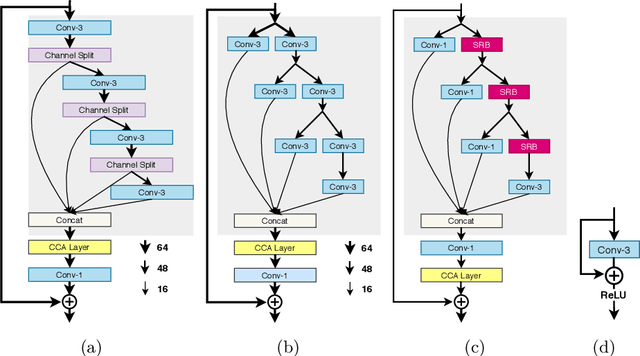
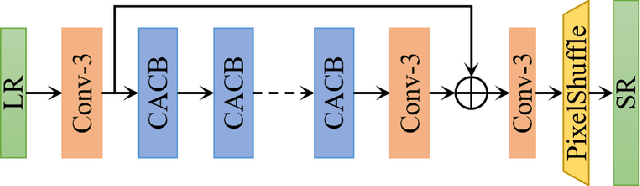
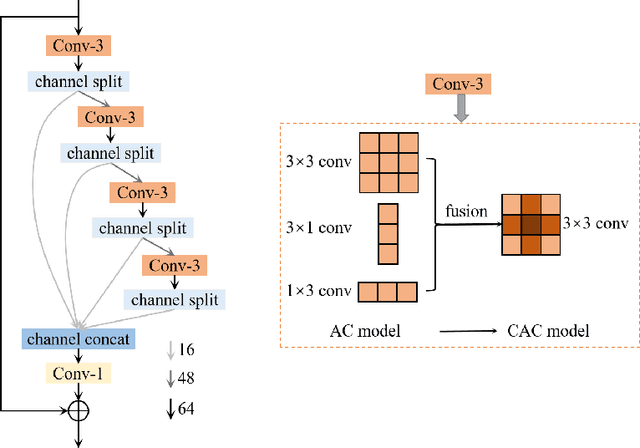
This paper reviews the AIM 2020 challenge on efficient single image super-resolution with focus on the proposed solutions and results. The challenge task was to super-resolve an input image with a magnification factor x4 based on a set of prior examples of low and corresponding high resolution images. The goal is to devise a network that reduces one or several aspects such as runtime, parameter count, FLOPs, activations, and memory consumption while at least maintaining PSNR of MSRResNet. The track had 150 registered participants, and 25 teams submitted the final results. They gauge the state-of-the-art in efficient single image super-resolution.
Faster Person Re-Identification
Aug 16, 2020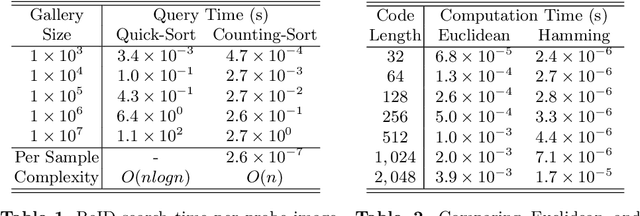
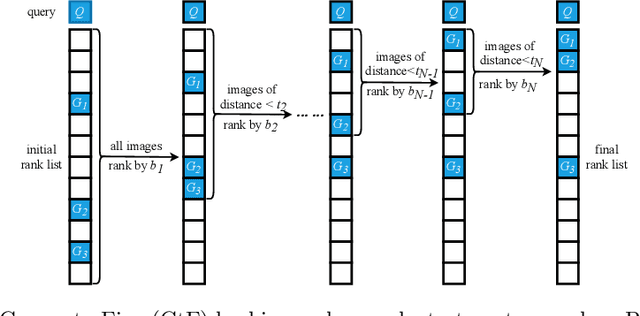
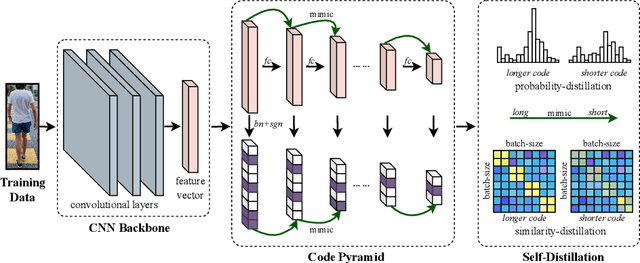
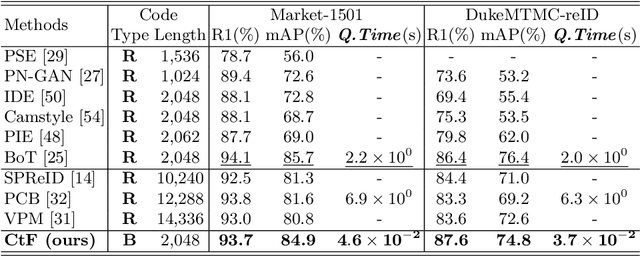
Fast person re-identification (ReID) aims to search person images quickly and accurately. The main idea of recent fast ReID methods is the hashing algorithm, which learns compact binary codes and performs fast Hamming distance and counting sort. However, a very long code is needed for high accuracy (e.g. 2048), which compromises search speed. In this work, we introduce a new solution for fast ReID by formulating a novel Coarse-to-Fine (CtF) hashing code search strategy, which complementarily uses short and long codes, achieving both faster speed and better accuracy. It uses shorter codes to coarsely rank broad matching similarities and longer codes to refine only a few top candidates for more accurate instance ReID. Specifically, we design an All-in-One (AiO) framework together with a Distance Threshold Optimization (DTO) algorithm. In AiO, we simultaneously learn and enhance multiple codes of different lengths in a single model. It learns multiple codes in a pyramid structure, and encourage shorter codes to mimic longer codes by self-distillation. DTO solves a complex threshold search problem by a simple optimization process, and the balance between accuracy and speed is easily controlled by a single parameter. It formulates the optimization target as a $F_{\beta}$ score that can be optimised by Gaussian cumulative distribution functions. Experimental results on 2 datasets show that our proposed method (CtF) is not only 8% more accurate but also 5x faster than contemporary hashing ReID methods. Compared with non-hashing ReID methods, CtF is $50\times$ faster with comparable accuracy. Code is available at https://github.com/wangguanan/light-reid.
Decoupled Spatial-Temporal Attention Network for Skeleton-Based Action Recognition
Jul 07, 2020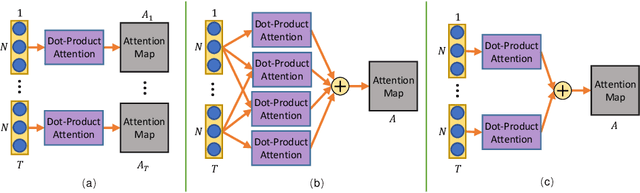

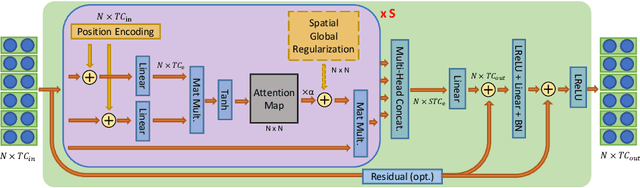
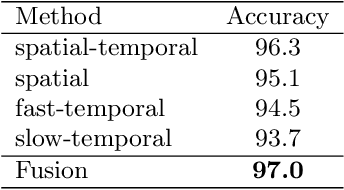
Dynamic skeletal data, represented as the 2D/3D coordinates of human joints, has been widely studied for human action recognition due to its high-level semantic information and environmental robustness. However, previous methods heavily rely on designing hand-crafted traversal rules or graph topologies to draw dependencies between the joints, which are limited in performance and generalizability. In this work, we present a novel decoupled spatial-temporal attention network(DSTA-Net) for skeleton-based action recognition. It involves solely the attention blocks, allowing for modeling spatial-temporal dependencies between joints without the requirement of knowing their positions or mutual connections. Specifically, to meet the specific requirements of the skeletal data, three techniques are proposed for building attention blocks, namely, spatial-temporal attention decoupling, decoupled position encoding and spatial global regularization. Besides, from the data aspect, we introduce a skeletal data decoupling technique to emphasize the specific characteristics of space/time and different motion scales, resulting in a more comprehensive understanding of the human actions.To test the effectiveness of the proposed method, extensive experiments are conducted on four challenging datasets for skeleton-based gesture and action recognition, namely, SHREC, DHG, NTU-60 and NTU-120, where DSTA-Net achieves state-of-the-art performance on all of them.
SC4D: A Sparse 4D Convolutional Network for Skeleton-Based Action Recognition
Apr 07, 2020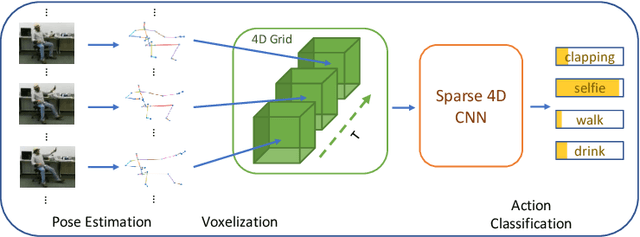

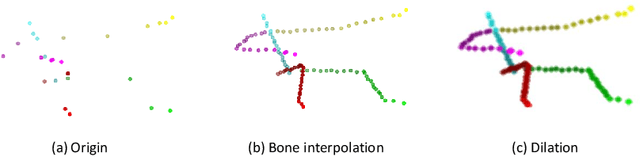
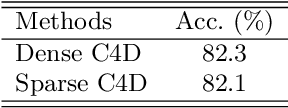
In this paper, a new perspective is presented for skeleton-based action recognition. Specifically, we regard the skeletal sequence as a spatial-temporal point cloud and voxelize it into a 4-dimensional grid. A novel sparse 4D convolutional network (SC4D) is proposed to directly process the generated 4D grid for high-level perceptions. Without manually designing the hand-crafted transformation rules, it makes better use of the advantages of the convolutional network, resulting in a more concise, general and robust framework for skeletal data. Besides, by processing the space and time simultaneously, it largely keeps the spatial-temporal consistency of the skeletal data, and thus brings better expressiveness. Moreover, with the help of the sparse tensor, it can be efficiently executed with less computations. To verify the superiority of SC4D, extensive experiments are conducted on two challenging datasets, namely, NTU-RGBD and SHREC, where SC4D achieves state-of-the-art performance on both of them.