 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning the policy for mixed electric platoon control of automated and human-driven vehicles at signalized intersection: a random search approach
Jun 24, 2022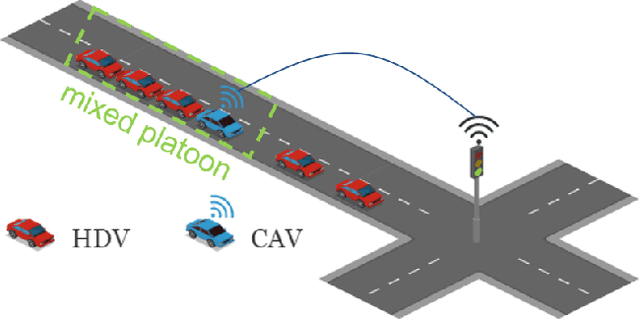
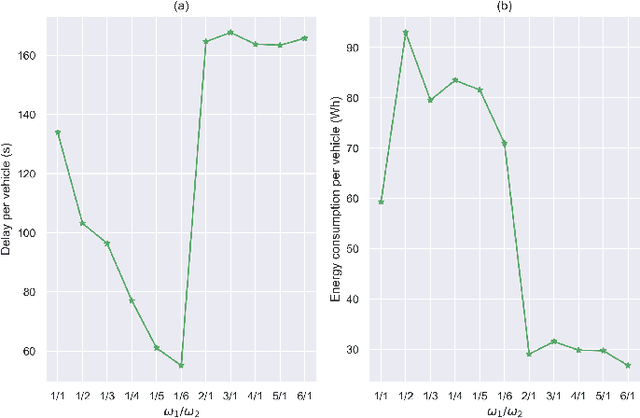
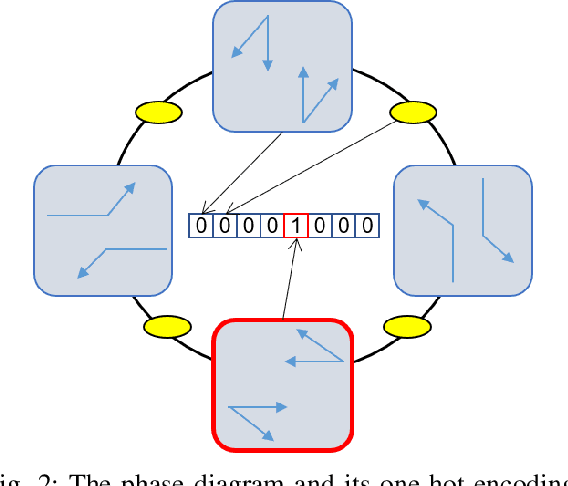
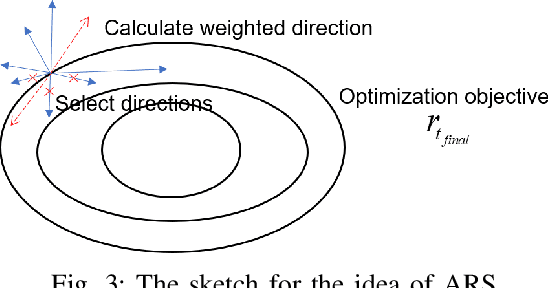
The upgrading and updating of vehicles have accelerated in the past decades. Out of the need for environmental friendliness and intelligence, electric vehicles (EVs) and connected and automated vehicles (CAVs) have become new components of transportation systems. This paper develops a reinforcement learning framework to implement adaptive control for an electric platoon composed of CAVs and human-driven vehicles (HDVs) at a signalized intersection. Firstly, a Markov Decision Process (MDP) model is proposed to describe the decision process of the mixed platoon. Novel state representation and reward function are designed for the model to consider the behavior of the whole platoon. Secondly, in order to deal with the delayed reward, an Augmented Random Search (ARS) algorithm is proposed. The control policy learned by the agent can guide the longitudinal motion of the CAV, which serves as the leader of the platoon. Finally, a series of simulations are carried out in simulation suite SUMO. Compared with several state-of-the-art (SOTA) reinforcement learning approaches, the proposed method can obtain a higher reward. Meanwhile, the simulation results demonstrate the effectiveness of the delay reward, which is designed to outperform distributed reward mechanism} Compared with normal car-following behavior, the sensitivity analysis reveals that the energy can be saved to different extends (39.27%-82.51%) by adjusting the relative importance of the optimization goal. On the premise that travel delay is not sacrificed, the proposed control method can save up to 53.64% electric energy.
Singular Value Fine-tuning: Few-shot Segmentation requires Few-parameters Fine-tuning
Jun 13, 2022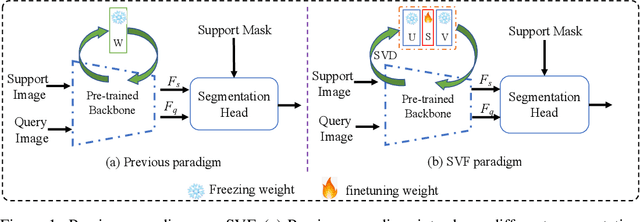
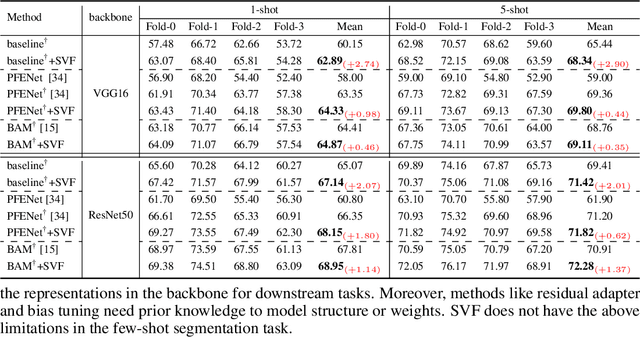
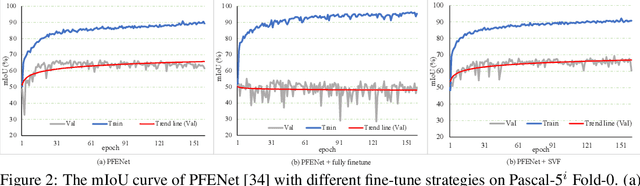
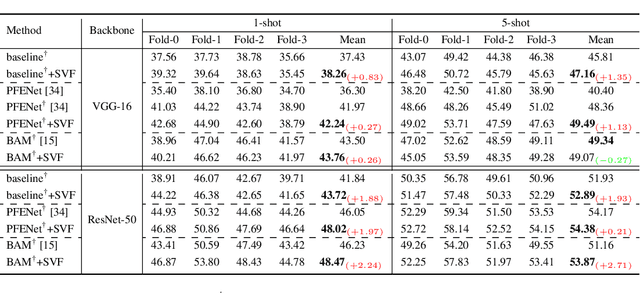
Freezing the pre-trained backbone has become a standard paradigm to avoid overfitting in few-shot segmentation. In this paper, we rethink the paradigm and explore a new regime: {\em fine-tuning a small part of parameters in the backbone}. We present a solution to overcome the overfitting problem, leading to better model generalization on learning novel classes. Our method decomposes backbone parameters into three successive matrices via the Singular Value Decomposition (SVD), then {\em only fine-tunes the singular values} and keeps others frozen. The above design allows the model to adjust feature representations on novel classes while maintaining semantic clues within the pre-trained backbone. We evaluate our {\em Singular Value Fine-tuning (SVF)} approach on various few-shot segmentation methods with different backbones. We achieve state-of-the-art results on both Pascal-5$^i$ and COCO-20$^i$ across 1-shot and 5-shot settings. Hopefully, this simple baseline will encourage researchers to rethink the role of backbone fine-tuning in few-shot settings. The source code and models will be available at \url{https://github.com/syp2ysy/SVF}.
MixFormer: Mixing Features across Windows and Dimensions
Apr 12, 2022

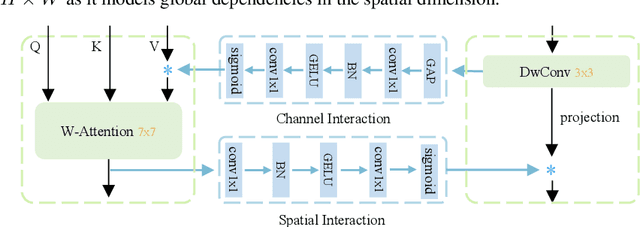

While local-window self-attention performs notably in vision tasks, it suffers from limited receptive field and weak modeling capability issues. This is mainly because it performs self-attention within non-overlapped windows and shares weights on the channel dimension. We propose MixFormer to find a solution. First, we combine local-window self-attention with depth-wise convolution in a parallel design, modeling cross-window connections to enlarge the receptive fields. Second, we propose bi-directional interactions across branches to provide complementary clues in the channel and spatial dimensions. These two designs are integrated to achieve efficient feature mixing among windows and dimensions. Our MixFormer provides competitive results on image classification with EfficientNet and shows better results than RegNet and Swin Transformer. Performance in downstream tasks outperforms its alternatives by significant margins with less computational costs in 5 dense prediction tasks on MS COCO, ADE20k, and LVIS. Code is available at \url{https://github.com/PaddlePaddle/PaddleClas}.
Soft Threshold Ternary Networks
Apr 04, 2022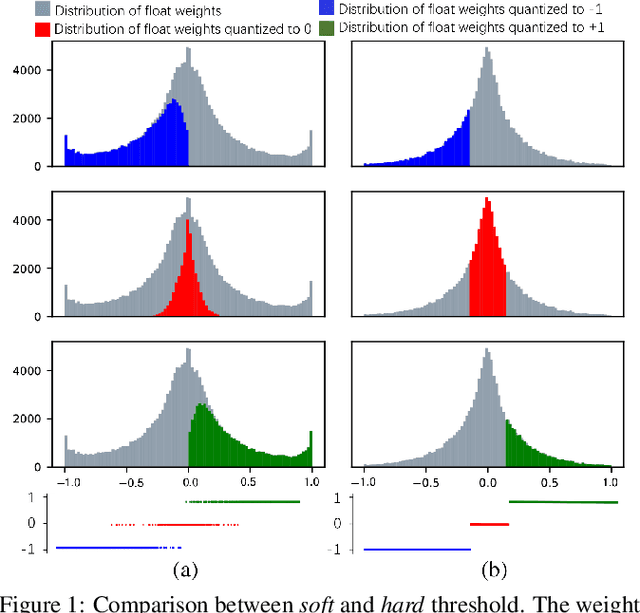

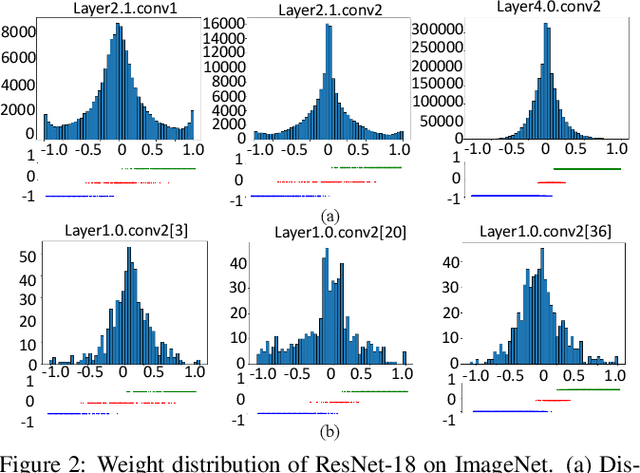

Large neural networks are difficult to deploy on mobile devices because of intensive computation and storage. To alleviate it, we study ternarization, a balance between efficiency and accuracy that quantizes both weights and activations into ternary values. In previous ternarized neural networks, a hard threshold {\Delta} is introduced to determine quantization intervals. Although the selection of {\Delta} greatly affects the training results, previous works estimate {\Delta} via an approximation or treat it as a hyper-parameter, which is suboptimal. In this paper, we present the Soft Threshold Ternary Networks (STTN), which enables the model to automatically determine quantization intervals instead of depending on a hard threshold. Concretely, we replace the original ternary kernel with the addition of two binary kernels at training time, where ternary values are determined by the combination of two corresponding binary values. At inference time, we add up the two binary kernels to obtain a single ternary kernel. Our method dramatically outperforms current state-of-the-arts, lowering the performance gap between full-precision networks and extreme low bit networks. Experiments on ImageNet with ResNet-18 (Top-1 66.2%) achieves new state-of-the-art. Update: In this version, we further fine-tune the experimental hyperparameters and training procedure. The latest STTN shows that ResNet-18 with ternary weights and ternary activations achieves up to 68.2% Top-1 accuracy on ImageNet. Code is available at: github.com/WeixiangXu/STTN.
Efficient Virtual View Selection for 3D Hand Pose Estimation
Mar 29, 2022
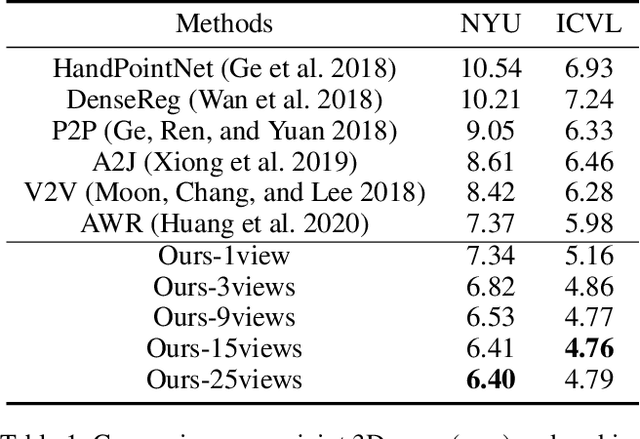
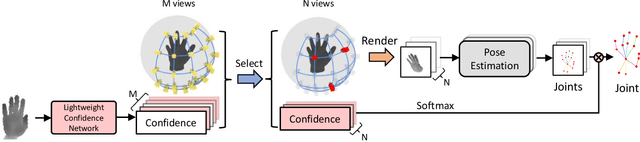
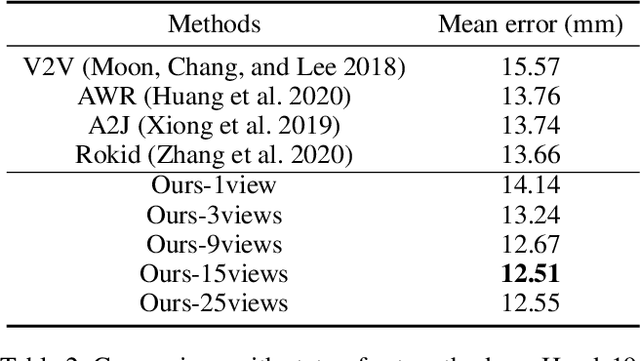
3D hand pose estimation from single depth is a fundamental problem in computer vision, and has wide applications.However, the existing methods still can not achieve satisfactory hand pose estimation results due to view variation and occlusion of human hand. In this paper, we propose a new virtual view selection and fusion module for 3D hand pose estimation from single depth.We propose to automatically select multiple virtual viewpoints for pose estimation and fuse the results of all and find this empirically delivers accurate and robust pose estimation. In order to select most effective virtual views for pose fusion, we evaluate the virtual views based on the confidence of virtual views using a light-weight network via network distillation. Experiments on three main benchmark datasets including NYU, ICVL and Hands2019 demonstrate that our method outperforms the state-of-the-arts on NYU and ICVL, and achieves very competitive performance on Hands2019-Task1, and our proposed virtual view selection and fusion module is both effective for 3D hand pose estimation.
Differentially Private Federated Learning with Local Regularization and Sparsification
Mar 21, 2022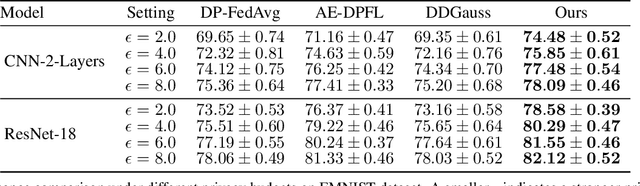
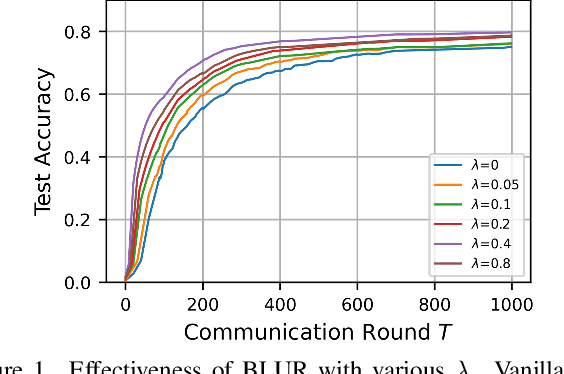
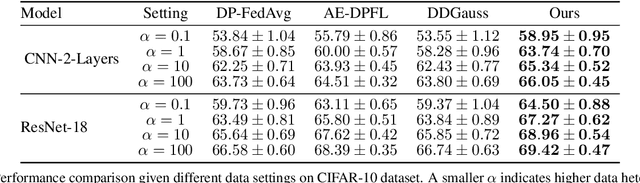
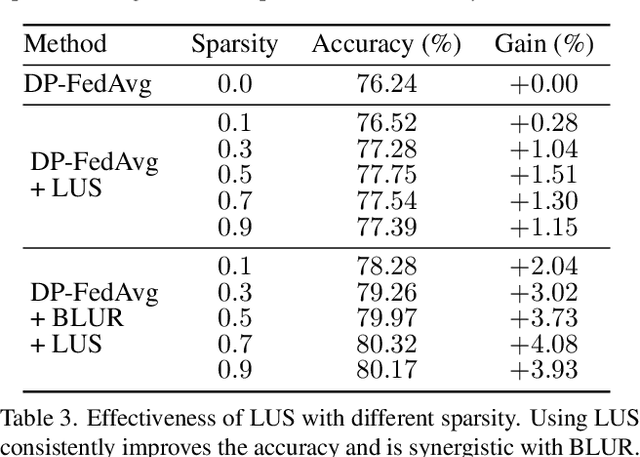
User-level differential privacy (DP) provides certifiable privacy guarantees to the information that is specific to any user's data in federated learning. Existing methods that ensure user-level DP come at the cost of severe accuracy decrease. In this paper, we study the cause of model performance degradation in federated learning under user-level DP guarantee. We find the key to solving this issue is to naturally restrict the norm of local updates before executing operations that guarantee DP. To this end, we propose two techniques, Bounded Local Update Regularization and Local Update Sparsification, to increase model quality without sacrificing privacy. We provide theoretical analysis on the convergence of our framework and give rigorous privacy guarantees. Extensive experiments show that our framework significantly improves the privacy-utility trade-off over the state-of-the-arts for federated learning with user-level DP guarantee.
Revisiting L1 Loss in Super-Resolution: A Probabilistic View and Beyond
Jan 25, 2022Super-resolution as an ill-posed problem has many high-resolution candidates for a low-resolution input. However, the popular $\ell_1$ loss used to best fit the given HR image fails to consider this fundamental property of non-uniqueness in image restoration. In this work, we fix the missing piece in $\ell_1$ loss by formulating super-resolution with neural networks as a probabilistic model. It shows that $\ell_1$ loss is equivalent to a degraded likelihood function that removes the randomness from the learning process. By introducing a data-adaptive random variable, we present a new objective function that aims at minimizing the expectation of the reconstruction error over all plausible solutions. The experimental results show consistent improvements on mainstream architectures, with no extra parameter or computing cost at inference time.
Q-ViT: Fully Differentiable Quantization for Vision Transformer
Jan 19, 2022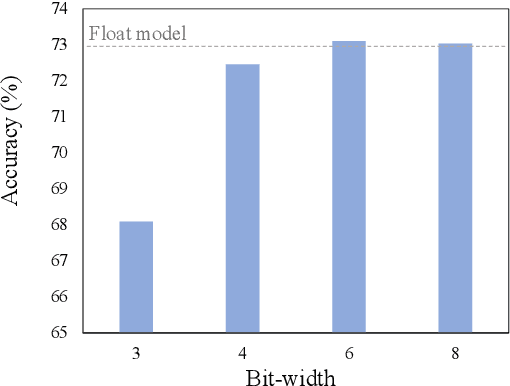
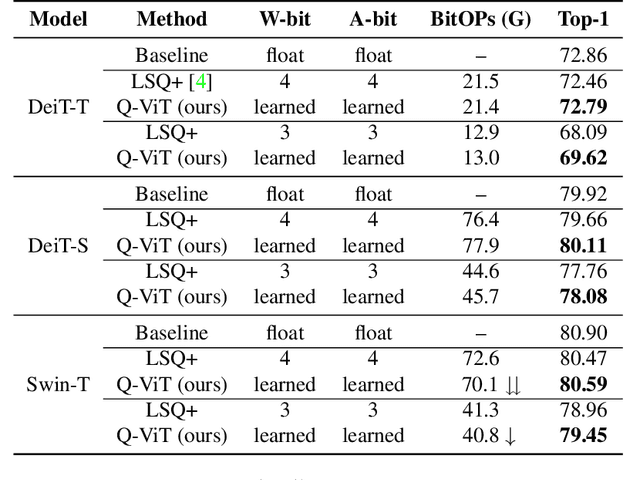
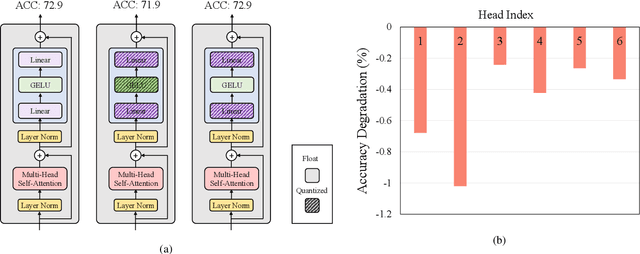

In this paper, we propose a fully differentiable quantization method for vision transformer (ViT) named as Q-ViT, in which both of the quantization scales and bit-widths are learnable parameters. Specifically, based on our observation that heads in ViT display different quantization robustness, we leverage head-wise bit-width to squeeze the size of Q-ViT while preserving performance. In addition, we propose a novel technique named switchable scale to resolve the convergence problem in the joint training of quantization scales and bit-widths. In this way, Q-ViT pushes the limits of ViT quantization to 3-bit without heavy performance drop. Moreover, we analyze the quantization robustness of every architecture component of ViT and show that the Multi-head Self-Attention (MSA) and the Gaussian Error Linear Units (GELU) are the key aspects for ViT quantization. This study provides some insights for further research about ViT quantization. Extensive experiments on different ViT models, such as DeiT and Swin Transformer show the effectiveness of our quantization method. In particular, our method outperforms the state-of-the-art uniform quantization method by 1.5% on DeiT-Tiny.
APRIL: Finding the Achilles' Heel on Privacy for Vision Transformers
Dec 28, 2021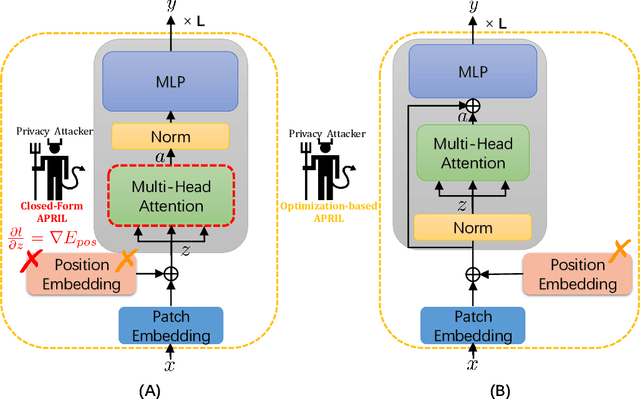



Federated learning frameworks typically require collaborators to share their local gradient updates of a common model instead of sharing training data to preserve privacy. However, prior works on Gradient Leakage Attacks showed that private training data can be revealed from gradients. So far almost all relevant works base their attacks on fully-connected or convolutional neural networks. Given the recent overwhelmingly rising trend of adapting Transformers to solve multifarious vision tasks, it is highly valuable to investigate the privacy risk of vision transformers. In this paper, we analyse the gradient leakage risk of self-attention based mechanism in both theoretical and practical manners. Particularly, we propose APRIL - Attention PRIvacy Leakage, which poses a strong threat to self-attention inspired models such as ViT. Showing how vision Transformers are at the risk of privacy leakage via gradients, we urge the significance of designing privacy-safer Transformer models and defending schemes.
Joint Channel and Weight Pruning for Model Acceleration on Moblie Devices
Nov 09, 2021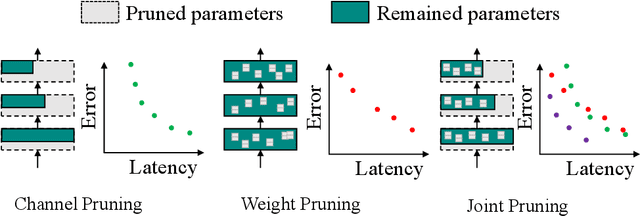
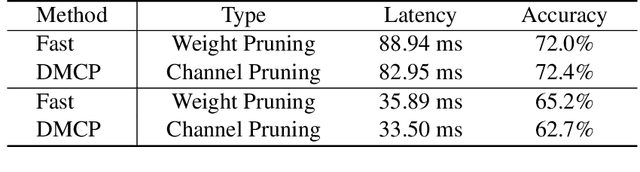
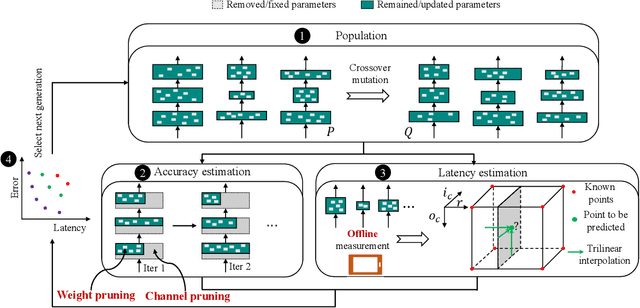
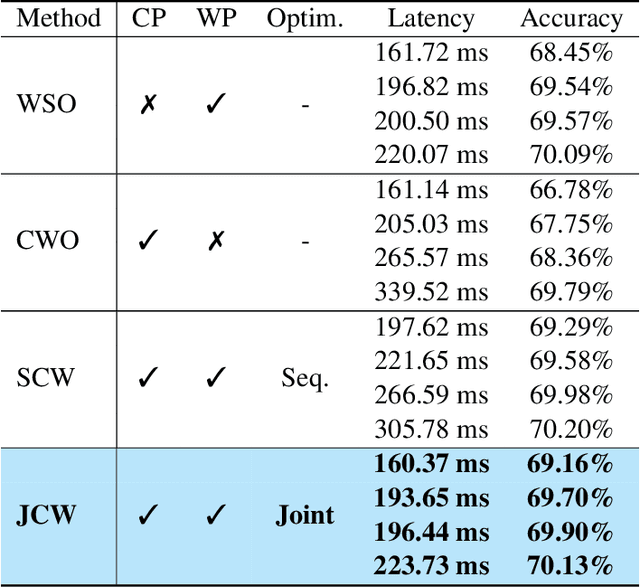
For practical deep neural network design on mobile devices, it is essential to consider the constraints incurred by the computational resources and the inference latency in various applications. Among deep network acceleration related approaches, pruning is a widely adopted practice to balance the computational resource consumption and the accuracy, where unimportant connections can be removed either channel-wisely or randomly with a minimal impact on model accuracy. The channel pruning instantly results in a significant latency reduction, while the random weight pruning is more flexible to balance the latency and accuracy. In this paper, we present a unified framework with Joint Channel pruning and Weight pruning (JCW), and achieves a better Pareto-frontier between the latency and accuracy than previous model compression approaches. To fully optimize the trade-off between the latency and accuracy, we develop a tailored multi-objective evolutionary algorithm in the JCW framework, which enables one single search to obtain the optimal candidate architectures for various deployment requirements. Extensive experiments demonstrate that the JCW achieves a better trade-off between the latency and accuracy against various state-of-the-art pruning methods on the ImageNet classification dataset. Our codes are available at https://github.com/jcw-anonymous/JCW.