 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePOINav: Benchmarking and Enhancing Final-Meters Arrival in Real-World Vision-Language Navigation
May 27, 2026Real-world navigation is fundamentally driven by Points of Interest (POIs), yet reaching a precise POI remains a critical "final-meters" challenge. Existing Vision-Language Navigation (VLN) benchmarks of POI-goal navigation often suffer from coarse granularity or significant sim-to-real gaps due to generated scene. To bridge this gap, we present POINav-Bench, the first benchmark designed for closed-loop evaluation of real-world POI-goal navigation. It comprises 11 commercial areas reconstructed from real-world captures using 3D Gaussian Splatting (3DGS), covering 126,398 $m^{2}$ in total and spanning 163 distinct POIs. With traversability-aware annotations and reference trajectories, POINav-Bench enables high-fidelity evaluation of navigation agents in realistic, POI-rich real-world environments. Building on this, we propose the POINav Brain-Action Framework where a Brain module performs POI-grounded reasoning to guide an Action module in predicting continuous waypoints for real-world execution. We further curate the POINav-Dataset, containing 70K real-world signage-entrance pairs. Experiments show that our framework provides a viable path toward refining real-world POI-goal navigation.
AsyncShield: A Plug-and-Play Edge Adapter for Asynchronous Cloud-based VLA Navigation
Apr 27, 2026While Vision-Language-Action (VLA) models have been demonstrated possessing strong zero-shot generalization for robot control, their massive parameter sizes typically necessitate cloud-based deployment. However, cloud deployment introduces network jitter and inference latency, which can induce severe spatiotemporal misalignment in mobile navigation under continuous displacement, so that the stale intents expressed in past ego frames may become spatially incorrect in the current frame and lead to collisions. To address this issue, we propose AsyncShield, a plug-and-play asynchronous control framework. AsyncShield discards traditional black-box time-series prediction in favor of a deterministic physical white-box spatial mapping. By maintaining a temporal pose buffer and utilizing kinematic transformations, the system accurately converts temporal lag into spatial pose offsets to restore the VLA's original geometric intent. To balance intent restoration fidelity and physical safety, the edge adaptation is formulated as a constrained Markov decision process (CMDP). Solved via the PPO-Lagrangian algorithm, a reinforcement learning adapter dynamically trades off between tracking the VLA intent and responding to high-frequency LiDAR obstacle avoidance hard constraints. Furthermore, benefiting from a standardized universal sub-goal interface, domain randomization, and perception-level adaptation via Collision Radius Inflation, AsyncShield operates as a lightweight, plug-and-play module. Simulation and real-world experiments demonstrate that, without fine-tuning any cloud-based foundation models, the framework exhibits zero-shot and robust generalization capabilities, effectively improving the success rate and physical safety of asynchronous navigation.
Explore Like Humans: Autonomous Exploration with Online SG-Memo Construction for Embodied Agents
Apr 21, 2026Constructing structured spatial memory is essential for enabling long-horizon reasoning in complex embodied navigation tasks. Current memory construction predominantly relies on a decoupled, two-stage paradigm: agents first aggregate environmental data through exploration, followed by the offline reconstruction of spatial memory. However, this post-hoc and geometry-centric approach precludes agents from leveraging high-level semantic intelligence, often causing them to overlook navigationally critical landmarks (e.g., doorways and staircases) that serve as fundamental semantic anchors in human cognitive maps. To bridge this gap, we propose ABot-Explorer, a novel active exploration framework that unifies memory construction and exploration into an online, RGB-only process. At its core, ABot-Explorer leverages Large Vision-Language Models (VLMs) to distill Semantic Navigational Affordances (SNA), which act as cognitive-aligned anchors to guide the agent's movement. By dynamically integrating these SNAs into a hierarchical SG-Memo, ABot-Explorer mirrors human-like exploratory logic by prioritizing structural transit nodes to facilitate efficient coverage. To support this framework, we contribute a large-scale dataset extending InteriorGS with SNA and SG-Memo annotations. Experimental results demonstrate that ABot-Explorer significantly outperforms current state-of-the-art methods in both exploration efficiency and environment coverage, while the resulting SG-Memo is shown to effectively support diverse downstream tasks.
ABot-N0: Technical Report on the VLA Foundation Model for Versatile Embodied Navigation
Feb 12, 2026Embodied navigation has long been fragmented by task-specific architectures. We introduce ABot-N0, a unified Vision-Language-Action (VLA) foundation model that achieves a ``Grand Unification'' across 5 core tasks: Point-Goal, Object-Goal, Instruction-Following, POI-Goal, and Person-Following. ABot-N0 utilizes a hierarchical ``Brain-Action'' architecture, pairing an LLM-based Cognitive Brain for semantic reasoning with a Flow Matching-based Action Expert for precise, continuous trajectory generation. To support large-scale learning, we developed the ABot-N0 Data Engine, curating 16.9M expert trajectories and 5.0M reasoning samples across 7,802 high-fidelity 3D scenes (10.7 $\text{km}^2$). ABot-N0 achieves new SOTA performance across 7 benchmarks, significantly outperforming specialized models. Furthermore, our Agentic Navigation System integrates a planner with hierarchical topological memory, enabling robust, long-horizon missions in dynamic real-world environments.
AstraNav-World: World Model for Foresight Control and Consistency
Dec 25, 2025Embodied navigation in open, dynamic environments demands accurate foresight of how the world will evolve and how actions will unfold over time. We propose AstraNav-World, an end-to-end world model that jointly reasons about future visual states and action sequences within a unified probabilistic framework. Our framework integrates a diffusion-based video generator with a vision-language policy, enabling synchronized rollouts where predicted scenes and planned actions are updated simultaneously. Training optimizes two complementary objectives: generating action-conditioned multi-step visual predictions and deriving trajectories conditioned on those predicted visuals. This bidirectional constraint makes visual predictions executable and keeps decisions grounded in physically consistent, task-relevant futures, mitigating cumulative errors common in decoupled "envision-then-plan" pipelines. Experiments across diverse embodied navigation benchmarks show improved trajectory accuracy and higher success rates. Ablations confirm the necessity of tight vision-action coupling and unified training, with either branch removal degrading both prediction quality and policy reliability. In real-world testing, AstraNav-World demonstrated exceptional zero-shot capabilities, adapting to previously unseen scenarios without any real-world fine-tuning. These results suggest that AstraNav-World captures transferable spatial understanding and planning-relevant navigation dynamics, rather than merely overfitting to simulation-specific data distribution. Overall, by unifying foresight vision and control within a single generative model, we move closer to reliable, interpretable, and general-purpose embodied agents that operate robustly in open-ended real-world settings.
HumanRig: Learning Automatic Rigging for Humanoid Character in a Large Scale Dataset
Dec 03, 2024



With the rapid evolution of 3D generation algorithms, the cost of producing 3D humanoid character models has plummeted, yet the field is impeded by the lack of a comprehensive dataset for automatic rigging, which is a pivotal step in character animation. Addressing this gap, we present HumanRig, the first large-scale dataset specifically designed for 3D humanoid character rigging, encompassing 11,434 meticulously curated T-posed meshes adhered to a uniform skeleton topology. Capitalizing on this dataset, we introduce an innovative, data-driven automatic rigging framework, which overcomes the limitations of GNN-based methods in handling complex AI-generated meshes. Our approach integrates a Prior-Guided Skeleton Estimator (PGSE) module, which uses 2D skeleton joints to provide a preliminary 3D skeleton, and a Mesh-Skeleton Mutual Attention Network (MSMAN) that fuses skeleton features with 3D mesh features extracted by a U-shaped point transformer. This enables a coarse-to-fine 3D skeleton joint regression and a robust skinning estimation, surpassing previous methods in quality and versatility. This work not only remedies the dataset deficiency in rigging research but also propels the animation industry towards more efficient and automated character rigging pipelines.
Dam reservoir extraction from remote sensing imagery using tailored metric learning strategies
Jul 12, 2022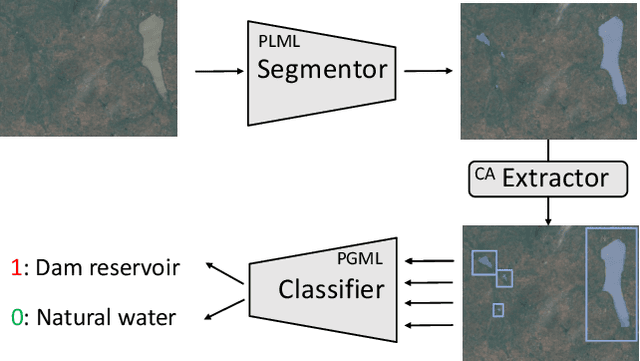

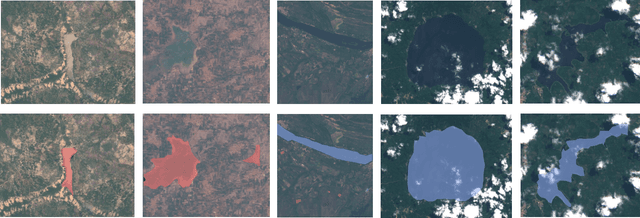
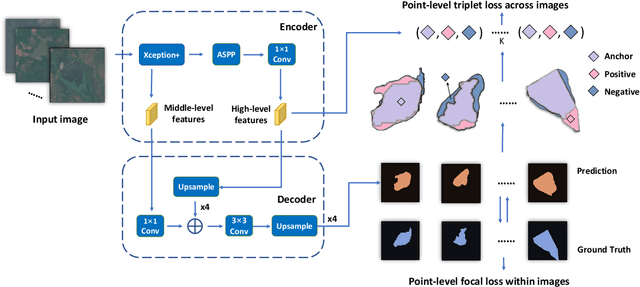
Dam reservoirs play an important role in meeting sustainable development goals and global climate targets. However, particularly for small dam reservoirs, there is a lack of consistent data on their geographical location. To address this data gap, a promising approach is to perform automated dam reservoir extraction based on globally available remote sensing imagery. It can be considered as a fine-grained task of water body extraction, which involves extracting water areas in images and then separating dam reservoirs from natural water bodies. We propose a novel deep neural network (DNN) based pipeline that decomposes dam reservoir extraction into water body segmentation and dam reservoir recognition. Water bodies are firstly separated from background lands in a segmentation model and each individual water body is then predicted as either dam reservoir or natural water body in a classification model. For the former step, point-level metric learning with triplets across images is injected into the segmentation model to address contour ambiguities between water areas and land regions. For the latter step, prior-guided metric learning with triplets from clusters is injected into the classification model to optimize the image embedding space in a fine-grained level based on reservoir clusters. To facilitate future research, we establish a benchmark dataset with earth imagery data and human labelled reservoirs from river basins in West Africa and India. Extensive experiments were conducted on this benchmark in the water body segmentation task, dam reservoir recognition task, and the joint dam reservoir extraction task. Superior performance has been observed in the respective tasks when comparing our method with state of the art approaches.
Learning Effective Representations from Global and Local Features for Cross-View Gait Recognition
Nov 03, 2020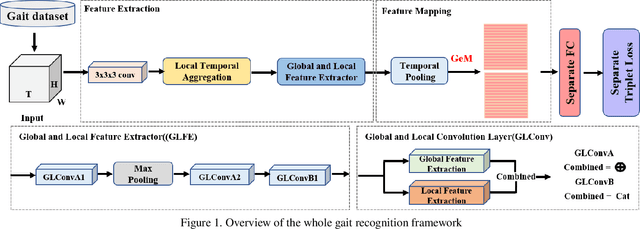
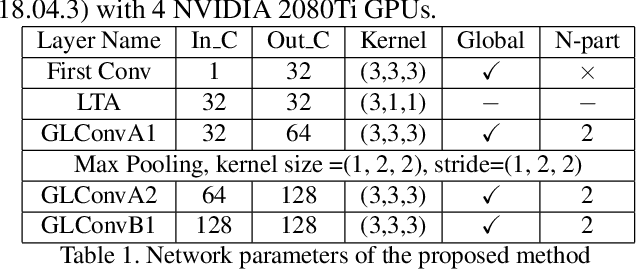
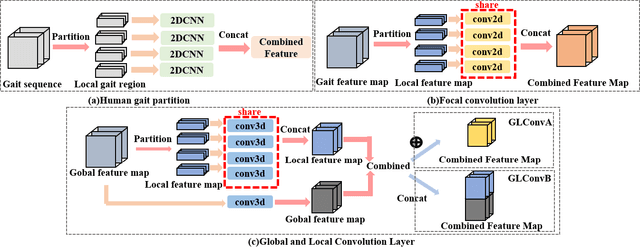
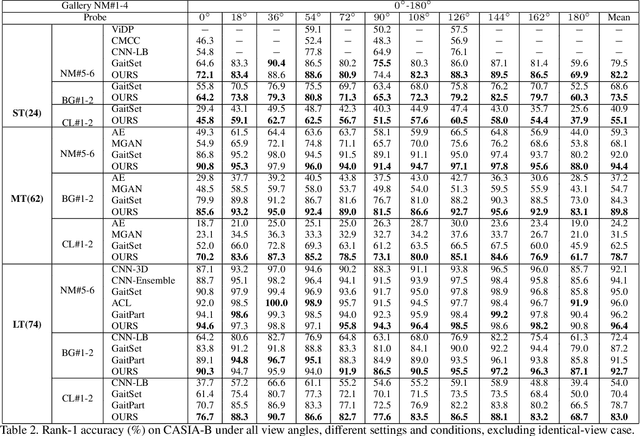
Gait recognition is one of the most important biometric technologies and has been applied in many fields. Recent gait recognition frameworks represent each human gait frame by descriptors extracted from either global appearances or local regions of humans. However, the representations based on global information often neglect the details of the gait frame, while local region based descriptors cannot capture the relations among neighboring regions, thus reducing their discriminativeness. In this paper, we propose a novel feature extraction and fusion framework to achieve discriminative feature representations for gait recognition. Towards this goal, we take advantage of both global visual information and local region details and develop a Global and Local Feature Extractor (GLFE). Specifically, our GLFE module is composed of our newly designed multiple global and local convolutional layers (GLConv) to ensemble global and local features in a principle manner. Furthermore, we present a novel operation, namely Local Temporal Aggregation (LTA), to further preserve the spatial information by reducing the temporal resolution to obtain higher spatial resolution. With the help of our GLFE and LTA, our method significantly improves the discriminativeness of our visual features, thus improving the gait recognition performance. Extensive experiments demonstrate that our proposed method outperforms state-of-the-art gait recognition methods on popular widely-used CASIA-B and OUMVLP datasets.