 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Human Pose Estimation Meets Robustness: Adversarial Algorithms and Benchmarks
May 13, 2021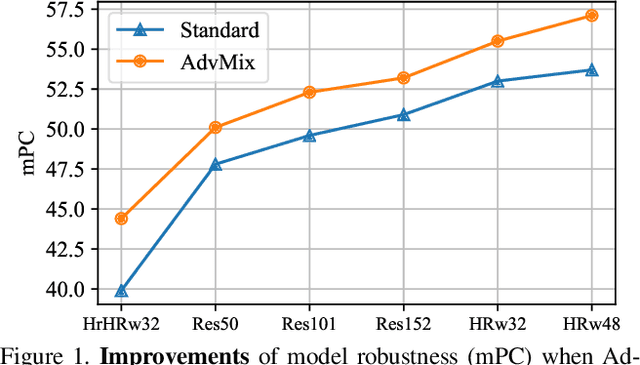

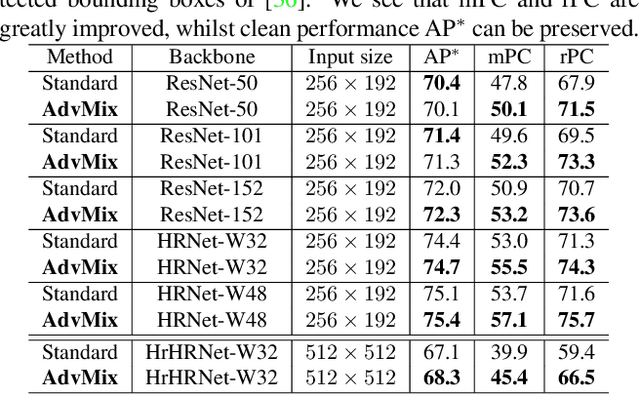
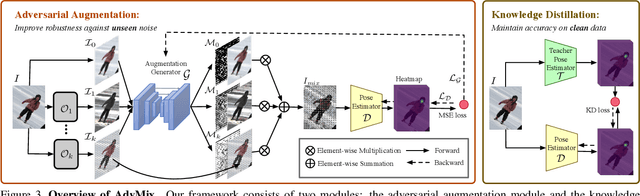
Human pose estimation is a fundamental yet challenging task in computer vision, which aims at localizing human anatomical keypoints. However, unlike human vision that is robust to various data corruptions such as blur and pixelation, current pose estimators are easily confused by these corruptions. This work comprehensively studies and addresses this problem by building rigorous robust benchmarks, termed COCO-C, MPII-C, and OCHuman-C, to evaluate the weaknesses of current advanced pose estimators, and a new algorithm termed AdvMix is proposed to improve their robustness in different corruptions. Our work has several unique benefits. (1) AdvMix is model-agnostic and capable in a wide-spectrum of pose estimation models. (2) AdvMix consists of adversarial augmentation and knowledge distillation. Adversarial augmentation contains two neural network modules that are trained jointly and competitively in an adversarial manner, where a generator network mixes different corrupted images to confuse a pose estimator, improving the robustness of the pose estimator by learning from harder samples. To compensate for the noise patterns by adversarial augmentation, knowledge distillation is applied to transfer clean pose structure knowledge to the target pose estimator. (3) Extensive experiments show that AdvMix significantly increases the robustness of pose estimations across a wide range of corruptions, while maintaining accuracy on clean data in various challenging benchmark datasets.
Down to the Last Detail: Virtual Try-on with Detail Carving
Jan 03, 2020
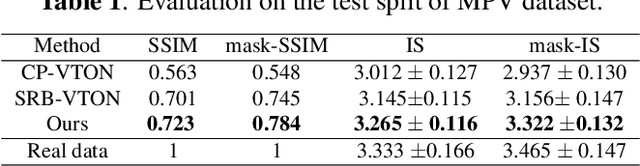
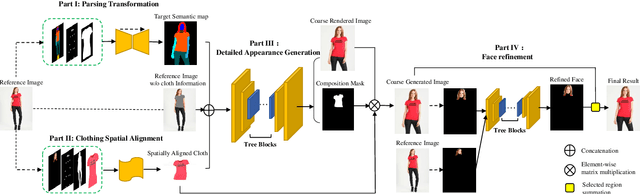
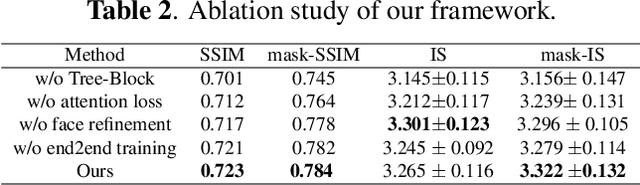
Virtual try-on under arbitrary poses has attracted lots of research attention due to its huge potential applications. However, existing methods can hardly preserve the details in clothing texture and facial identity (face, hair) while fitting novel clothes and poses onto a person. In this paper, we propose a novel multi-stage framework to synthesize person images, where rich details in salient regions can be well preserved. Specifically, a multi-stage framework is proposed to decompose the generation into spatial alignment followed by a coarse-to-fine generation. To better preserve the details in salient areas such as clothing and facial areas, we propose a Tree-Block (tree dilated fusion block) to harness multi-scale features in the generator networks. With end-to-end training of multiple stages, the whole framework can be jointly optimized for results with significantly better visual fidelity and richer details. Extensive experiments on standard datasets demonstrate that our proposed framework achieves the state-of-the-art performance, especially in preserving the visual details in clothing texture and facial identity. Our implementation will be publicly available soon.