 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsyncShield: A Plug-and-Play Edge Adapter for Asynchronous Cloud-based VLA Navigation
Apr 27, 2026While Vision-Language-Action (VLA) models have been demonstrated possessing strong zero-shot generalization for robot control, their massive parameter sizes typically necessitate cloud-based deployment. However, cloud deployment introduces network jitter and inference latency, which can induce severe spatiotemporal misalignment in mobile navigation under continuous displacement, so that the stale intents expressed in past ego frames may become spatially incorrect in the current frame and lead to collisions. To address this issue, we propose AsyncShield, a plug-and-play asynchronous control framework. AsyncShield discards traditional black-box time-series prediction in favor of a deterministic physical white-box spatial mapping. By maintaining a temporal pose buffer and utilizing kinematic transformations, the system accurately converts temporal lag into spatial pose offsets to restore the VLA's original geometric intent. To balance intent restoration fidelity and physical safety, the edge adaptation is formulated as a constrained Markov decision process (CMDP). Solved via the PPO-Lagrangian algorithm, a reinforcement learning adapter dynamically trades off between tracking the VLA intent and responding to high-frequency LiDAR obstacle avoidance hard constraints. Furthermore, benefiting from a standardized universal sub-goal interface, domain randomization, and perception-level adaptation via Collision Radius Inflation, AsyncShield operates as a lightweight, plug-and-play module. Simulation and real-world experiments demonstrate that, without fine-tuning any cloud-based foundation models, the framework exhibits zero-shot and robust generalization capabilities, effectively improving the success rate and physical safety of asynchronous navigation.
Explore Like Humans: Autonomous Exploration with Online SG-Memo Construction for Embodied Agents
Apr 21, 2026Constructing structured spatial memory is essential for enabling long-horizon reasoning in complex embodied navigation tasks. Current memory construction predominantly relies on a decoupled, two-stage paradigm: agents first aggregate environmental data through exploration, followed by the offline reconstruction of spatial memory. However, this post-hoc and geometry-centric approach precludes agents from leveraging high-level semantic intelligence, often causing them to overlook navigationally critical landmarks (e.g., doorways and staircases) that serve as fundamental semantic anchors in human cognitive maps. To bridge this gap, we propose ABot-Explorer, a novel active exploration framework that unifies memory construction and exploration into an online, RGB-only process. At its core, ABot-Explorer leverages Large Vision-Language Models (VLMs) to distill Semantic Navigational Affordances (SNA), which act as cognitive-aligned anchors to guide the agent's movement. By dynamically integrating these SNAs into a hierarchical SG-Memo, ABot-Explorer mirrors human-like exploratory logic by prioritizing structural transit nodes to facilitate efficient coverage. To support this framework, we contribute a large-scale dataset extending InteriorGS with SNA and SG-Memo annotations. Experimental results demonstrate that ABot-Explorer significantly outperforms current state-of-the-art methods in both exploration efficiency and environment coverage, while the resulting SG-Memo is shown to effectively support diverse downstream tasks.
ABot-N0: Technical Report on the VLA Foundation Model for Versatile Embodied Navigation
Feb 12, 2026Embodied navigation has long been fragmented by task-specific architectures. We introduce ABot-N0, a unified Vision-Language-Action (VLA) foundation model that achieves a ``Grand Unification'' across 5 core tasks: Point-Goal, Object-Goal, Instruction-Following, POI-Goal, and Person-Following. ABot-N0 utilizes a hierarchical ``Brain-Action'' architecture, pairing an LLM-based Cognitive Brain for semantic reasoning with a Flow Matching-based Action Expert for precise, continuous trajectory generation. To support large-scale learning, we developed the ABot-N0 Data Engine, curating 16.9M expert trajectories and 5.0M reasoning samples across 7,802 high-fidelity 3D scenes (10.7 $\text{km}^2$). ABot-N0 achieves new SOTA performance across 7 benchmarks, significantly outperforming specialized models. Furthermore, our Agentic Navigation System integrates a planner with hierarchical topological memory, enabling robust, long-horizon missions in dynamic real-world environments.
MerNav: A Highly Generalizable Memory-Execute-Review Framework for Zero-Shot Object Goal Navigation
Feb 05, 2026Visual Language Navigation (VLN) is one of the fundamental capabilities for embodied intelligence and a critical challenge that urgently needs to be addressed. However, existing methods are still unsatisfactory in terms of both success rate (SR) and generalization: Supervised Fine-Tuning (SFT) approaches typically achieve higher SR, while Training-Free (TF) approaches often generalize better, but it is difficult to obtain both simultaneously. To this end, we propose a Memory-Execute-Review framework. It consists of three parts: a hierarchical memory module for providing information support, an execute module for routine decision-making and actions, and a review module for handling abnormal situations and correcting behavior. We validated the effectiveness of this framework on the Object Goal Navigation task. Across 4 datasets, our average SR achieved absolute improvements of 7% and 5% compared to all baseline methods under TF and Zero-Shot (ZS) settings, respectively. On the most commonly used HM3D_v0.1 and the more challenging open vocabulary dataset HM3D_OVON, the SR improved by 8% and 6%, under ZS settings. Furthermore, on the MP3D and HM3D_OVON datasets, our method not only outperformed all TF methods but also surpassed all SFT methods, achieving comprehensive leadership in both SR (5% and 2%) and generalization.
AstraNav-World: World Model for Foresight Control and Consistency
Dec 25, 2025Embodied navigation in open, dynamic environments demands accurate foresight of how the world will evolve and how actions will unfold over time. We propose AstraNav-World, an end-to-end world model that jointly reasons about future visual states and action sequences within a unified probabilistic framework. Our framework integrates a diffusion-based video generator with a vision-language policy, enabling synchronized rollouts where predicted scenes and planned actions are updated simultaneously. Training optimizes two complementary objectives: generating action-conditioned multi-step visual predictions and deriving trajectories conditioned on those predicted visuals. This bidirectional constraint makes visual predictions executable and keeps decisions grounded in physically consistent, task-relevant futures, mitigating cumulative errors common in decoupled "envision-then-plan" pipelines. Experiments across diverse embodied navigation benchmarks show improved trajectory accuracy and higher success rates. Ablations confirm the necessity of tight vision-action coupling and unified training, with either branch removal degrading both prediction quality and policy reliability. In real-world testing, AstraNav-World demonstrated exceptional zero-shot capabilities, adapting to previously unseen scenarios without any real-world fine-tuning. These results suggest that AstraNav-World captures transferable spatial understanding and planning-relevant navigation dynamics, rather than merely overfitting to simulation-specific data distribution. Overall, by unifying foresight vision and control within a single generative model, we move closer to reliable, interpretable, and general-purpose embodied agents that operate robustly in open-ended real-world settings.
JanusVLN: Decoupling Semantics and Spatiality with Dual Implicit Memory for Vision-Language Navigation
Sep 26, 2025



Vision-and-Language Navigation requires an embodied agent to navigate through unseen environments, guided by natural language instructions and a continuous video stream. Recent advances in VLN have been driven by the powerful semantic understanding of Multimodal Large Language Models. However, these methods typically rely on explicit semantic memory, such as building textual cognitive maps or storing historical visual frames. This type of method suffers from spatial information loss, computational redundancy, and memory bloat, which impede efficient navigation. Inspired by the implicit scene representation in human navigation, analogous to the left brain's semantic understanding and the right brain's spatial cognition, we propose JanusVLN, a novel VLN framework featuring a dual implicit neural memory that models spatial-geometric and visual-semantic memory as separate, compact, and fixed-size neural representations. This framework first extends the MLLM to incorporate 3D prior knowledge from the spatial-geometric encoder, thereby enhancing the spatial reasoning capabilities of models based solely on RGB input. Then, the historical key-value caches from the spatial-geometric and visual-semantic encoders are constructed into a dual implicit memory. By retaining only the KVs of tokens in the initial and sliding window, redundant computation is avoided, enabling efficient incremental updates. Extensive experiments demonstrate that JanusVLN outperforms over 20 recent methods to achieve SOTA performance. For example, the success rate improves by 10.5-35.5 compared to methods using multiple data types as input and by 3.6-10.8 compared to methods using more RGB training data. This indicates that the proposed dual implicit neural memory, as a novel paradigm, explores promising new directions for future VLN research. Ours project page: https://miv-xjtu.github.io/JanusVLN.github.io/.
Monocular Vehicle Self-localization method based on Compact Semantic Map
May 16, 2018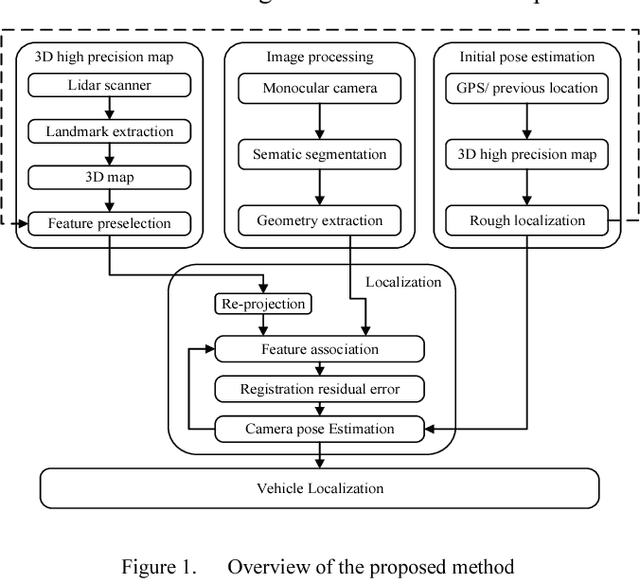

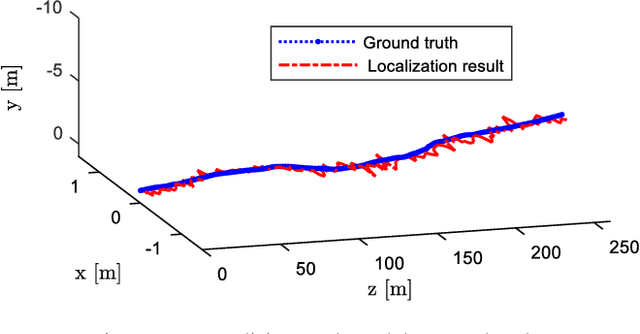

High precision localization is a crucial requirement for the autonomous driving system. Traditional positioning methods have some limitations in providing stable and accurate vehicle poses, especially in an urban environment. Herein, we propose a novel self-localizing method using a monocular camera and a 3D compact semantic map. Pre-collected information of the road landmarks is stored in a self-defined map with a minimal amount of data. We recognize landmarks using a deep neural network, followed with a geometric feature extraction process which promotes the measurement accuracy. The vehicle location and posture are estimated by minimizing a self-defined re-projection residual error to evaluate the map-to-image registration, together with a robust association method. We validate the effectiveness of our approach by applying this method to localize a vehicle in an open dataset, achieving the RMS accuracy of 0.345 meter with reduced sensor setup and map storage compared to the state of art approaches. We also evaluate some key steps and discuss the contribution of the subsystems.