 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Learning via Flow-Guided Neural Operator on Time-Series Data
Feb 12, 2026Self-supervised learning (SSL) is a powerful paradigm for learning from unlabeled time-series data. However, popular methods such as masked autoencoders (MAEs) rely on reconstructing inputs from a fixed, predetermined masking ratio. Instead of this static design, we propose treating the corruption level as a new degree of freedom for representation learning, enhancing flexibility and performance. To achieve this, we introduce the Flow-Guided Neural Operator (FGNO), a novel framework combining operator learning with flow matching for SSL training. FGNO learns mappings in functional spaces by using Short-Time Fourier Transform to unify different time resolutions. We extract a rich hierarchy of features by tapping into different network layers and flow times that apply varying strengths of noise to the input data. This enables the extraction of versatile representations, from low-level patterns to high-level global features, using a single model adaptable to specific tasks. Unlike prior generative SSL methods that use noisy inputs during inference, we propose using clean inputs for representation extraction while learning representations with noise; this eliminates randomness and boosts accuracy. We evaluate FGNO across three biomedical domains, where it consistently outperforms established baselines. Our method yields up to 35% AUROC gains in neural signal decoding (BrainTreeBank), 16% RMSE reductions in skin temperature prediction (DREAMT), and over 20% improvement in accuracy and macro-F1 on SleepEDF under low-data regimes. These results highlight FGNO's robustness to data scarcity and its superior capacity to learn expressive representations for diverse time series.
Function-Space Decoupled Diffusion for Forward and Inverse Modeling in Carbon Capture and Storage
Feb 12, 2026Accurate characterization of subsurface flow is critical for Carbon Capture and Storage (CCS) but remains challenged by the ill-posed nature of inverse problems with sparse observations. We present Fun-DDPS, a generative framework that combines function-space diffusion models with differentiable neural operator surrogates for both forward and inverse modeling. Our approach learns a prior distribution over geological parameters (geomodel) using a single-channel diffusion model, then leverages a Local Neural Operator (LNO) surrogate to provide physics-consistent guidance for cross-field conditioning on the dynamics field. This decoupling allows the diffusion prior to robustly recover missing information in parameter space, while the surrogate provides efficient gradient-based guidance for data assimilation. We demonstrate Fun-DDPS on synthetic CCS modeling datasets, achieving two key results: (1) For forward modeling with only 25% observations, Fun-DDPS achieves 7.7% relative error compared to 86.9% for standard surrogates (an 11x improvement), proving its capability to handle extreme data sparsity where deterministic methods fail. (2) We provide the first rigorous validation of diffusion-based inverse solvers against asymptotically exact Rejection Sampling (RS) posteriors. Both Fun-DDPS and the joint-state baseline (Fun-DPS) achieve Jensen-Shannon divergence less than 0.06 against the ground truth. Crucially, Fun-DDPS produces physically consistent realizations free from the high-frequency artifacts observed in joint-state baselines, achieving this with 4x improved sample efficiency compared to rejection sampling.
Decoupled Diffusion Sampling for Inverse Problems on Function Spaces
Jan 30, 2026We propose a data-efficient, physics-aware generative framework in function space for inverse PDE problems. Existing plug-and-play diffusion posterior samplers represent physics implicitly through joint coefficient-solution modeling, requiring substantial paired supervision. In contrast, our Decoupled Diffusion Inverse Solver (DDIS) employs a decoupled design: an unconditional diffusion learns the coefficient prior, while a neural operator explicitly models the forward PDE for guidance. This decoupling enables superior data efficiency and effective physics-informed learning, while naturally supporting Decoupled Annealing Posterior Sampling (DAPS) to avoid over-smoothing in Diffusion Posterior Sampling (DPS). Theoretically, we prove that DDIS avoids the guidance attenuation failure of joint models when training data is scarce. Empirically, DDIS achieves state-of-the-art performance under sparse observation, improving $l_2$ error by 11% and spectral error by 54% on average; when data is limited to 1%, DDIS maintains accuracy with 40% advantage in $l_2$ error compared to joint models.
EquiReg: Equivariance Regularized Diffusion for Inverse Problems
May 29, 2025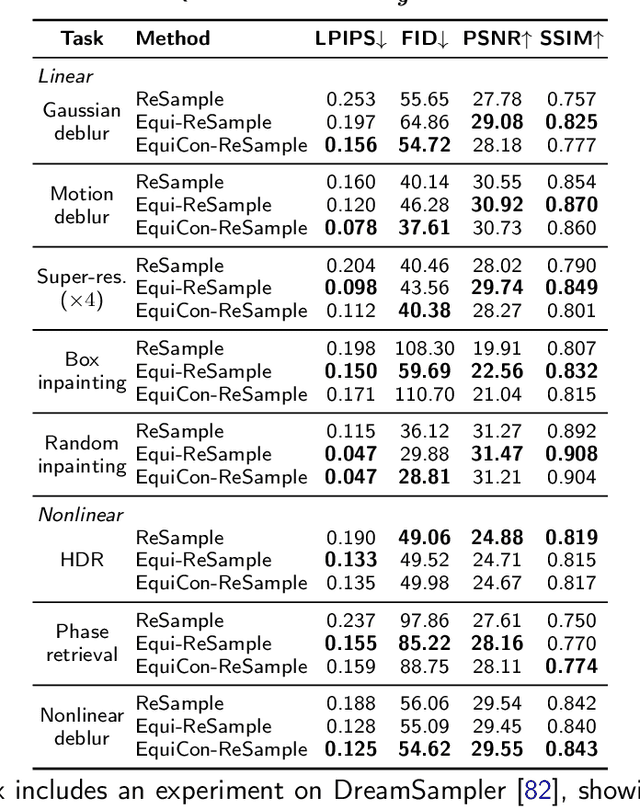
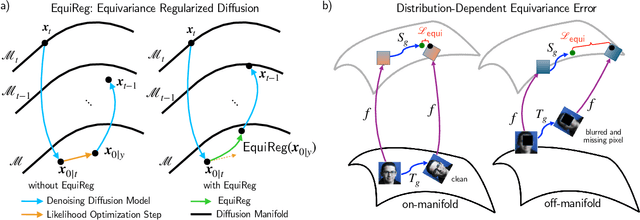
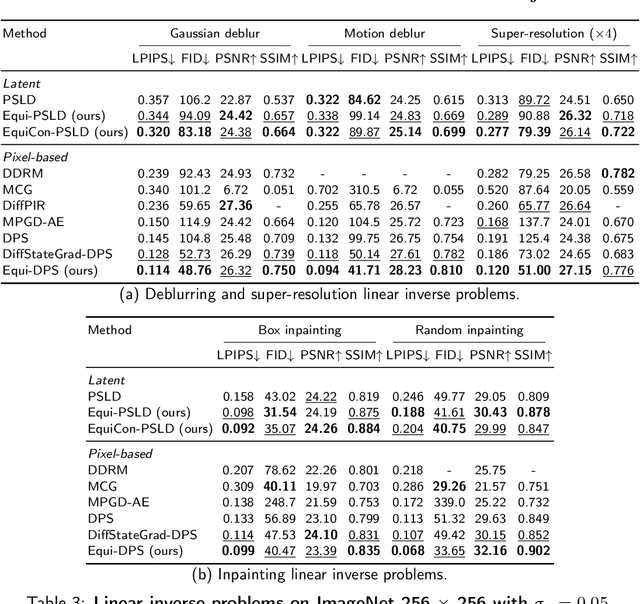
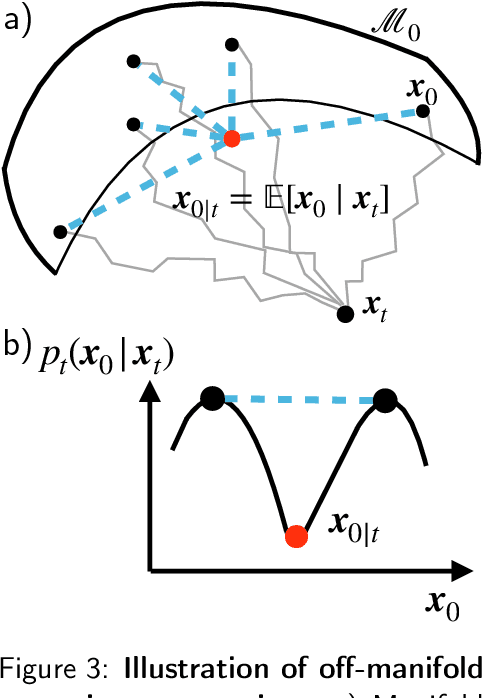
Diffusion models represent the state-of-the-art for solving inverse problems such as image restoration tasks. In the Bayesian framework, diffusion-based inverse solvers incorporate a likelihood term to guide the prior sampling process, generating data consistent with the posterior distribution. However, due to the intractability of the likelihood term, many current methods rely on isotropic Gaussian approximations, which lead to deviations from the data manifold and result in inconsistent, unstable reconstructions. We propose Equivariance Regularized (EquiReg) diffusion, a general framework for regularizing posterior sampling in diffusion-based inverse problem solvers. EquiReg enhances reconstructions by reweighting diffusion trajectories and penalizing those that deviate from the data manifold. We define a new distribution-dependent equivariance error, empirically identify functions that exhibit low error for on-manifold samples and higher error for off-manifold samples, and leverage these functions to regularize the diffusion sampling process. When applied to a variety of solvers, EquiReg outperforms state-of-the-art diffusion models in both linear and nonlinear image restoration tasks, as well as in reconstructing partial differential equations.
Guided Diffusion Sampling on Function Spaces with Applications to PDEs
May 22, 2025We propose a general framework for conditional sampling in PDE-based inverse problems, targeting the recovery of whole solutions from extremely sparse or noisy measurements. This is accomplished by a function-space diffusion model and plug-and-play guidance for conditioning. Our method first trains an unconditional discretization-agnostic denoising model using neural operator architectures. At inference, we refine the samples to satisfy sparse observation data via a gradient-based guidance mechanism. Through rigorous mathematical analysis, we extend Tweedie's formula to infinite-dimensional Hilbert spaces, providing the theoretical foundation for our posterior sampling approach. Our method (FunDPS) accurately captures posterior distributions in function spaces under minimal supervision and severe data scarcity. Across five PDE tasks with only 3% observation, our method achieves an average 32% accuracy improvement over state-of-the-art fixed-resolution diffusion baselines while reducing sampling steps by 4x. Furthermore, multi-resolution fine-tuning ensures strong cross-resolution generalizability. To the best of our knowledge, this is the first diffusion-based framework to operate independently of discretization, offering a practical and flexible solution for forward and inverse problems in the context of PDEs. Code is available at https://github.com/neuraloperator/FunDPS
Adversarial Vessel-Unveiling Semi-Supervised Segmentation for Retinopathy of Prematurity Diagnosis
Nov 14, 2024



Accurate segmentation of retinal images plays a crucial role in aiding ophthalmologists in diagnosing retinopathy of prematurity (ROP) and assessing its severity. However, due to their underdeveloped, thinner vessels, manual annotation in infant fundus images is very complex, and this presents challenges for fully supervised learning. To address the scarcity of annotations, we propose a semi supervised segmentation framework designed to advance ROP studies without the need for extensive manual vessel annotation. Unlike previous methods that rely solely on limited labeled data, our approach leverages teacher student learning by integrating two powerful components: an uncertainty weighted vessel unveiling module and domain adversarial learning. The vessel unveiling module helps the model effectively reveal obscured and hard to detect vessel structures, while adversarial training aligns feature representations across different domains, ensuring robust and generalizable vessel segmentations. We validate our approach on public datasets (CHASEDB, STARE) and an in-house ROP dataset, demonstrating its superior performance across multiple evaluation metrics. Additionally, we extend the model's utility to a downstream task of ROP multi-stage classification, where vessel masks extracted by our segmentation model improve diagnostic accuracy. The promising results in classification underscore the model's potential for clinical application, particularly in early-stage ROP diagnosis and intervention. Overall, our work offers a scalable solution for leveraging unlabeled data in pediatric ophthalmology, opening new avenues for biomarker discovery and clinical research.
A Theoretical Study of Neural Network Expressive Power via Manifold Topology
Oct 21, 2024



A prevalent assumption regarding real-world data is that it lies on or close to a low-dimensional manifold. When deploying a neural network on data manifolds, the required size, i.e., the number of neurons of the network, heavily depends on the intricacy of the underlying latent manifold. While significant advancements have been made in understanding the geometric attributes of manifolds, it's essential to recognize that topology, too, is a fundamental characteristic of manifolds. In this study, we investigate network expressive power in terms of the latent data manifold. Integrating both topological and geometric facets of the data manifold, we present a size upper bound of ReLU neural networks.
Backdooring Vision-Language Models with Out-Of-Distribution Data
Oct 02, 2024



The emergence of Vision-Language Models (VLMs) represents a significant advancement in integrating computer vision with Large Language Models (LLMs) to generate detailed text descriptions from visual inputs. Despite their growing importance, the security of VLMs, particularly against backdoor attacks, is under explored. Moreover, prior works often assume attackers have access to the original training data, which is often unrealistic. In this paper, we address a more practical and challenging scenario where attackers must rely solely on Out-Of-Distribution (OOD) data. We introduce VLOOD (Backdooring Vision-Language Models with Out-of-Distribution Data), a novel approach with two key contributions: (1) demonstrating backdoor attacks on VLMs in complex image-to-text tasks while minimizing degradation of the original semantics under poisoned inputs, and (2) proposing innovative techniques for backdoor injection without requiring any access to the original training data. Our evaluation on image captioning and visual question answering (VQA) tasks confirms the effectiveness of VLOOD, revealing a critical security vulnerability in VLMs and laying the foundation for future research on securing multimodal models against sophisticated threats.
Topological Analysis of Mouse Brain Vasculature via 3D Light-sheet Microscopy Images
Feb 23, 2024



Vascular networks play a crucial role in understanding brain functionalities. Brain integrity and function, neuronal activity and plasticity, which are crucial for learning, are actively modulated by their local environments, specifically vascular networks. With recent developments in high-resolution 3D light-sheet microscopy imaging together with tissue processing techniques, it becomes feasible to obtain and examine large-scale brain vasculature in mice. To establish a structural foundation for functional study, however, we need advanced image analysis and structural modeling methods. Existing works use geometric features such as thickness, tortuosity, etc. However, geometric features cannot fully capture structural characteristics such as the richness of branches, connectivity, etc. In this paper, we study the morphology of brain vasculature through a topological lens. We extract topological features based on the theory of topological data analysis. Comparing of these robust and multi-scale topological structural features across different brain anatomical structures and between normal and obese populations sheds light on their promising future in studying neurological diseases.
Preconditioning for Physics-Informed Neural Networks
Feb 01, 2024



Physics-informed neural networks (PINNs) have shown promise in solving various partial differential equations (PDEs). However, training pathologies have negatively affected the convergence and prediction accuracy of PINNs, which further limits their practical applications. In this paper, we propose to use condition number as a metric to diagnose and mitigate the pathologies in PINNs. Inspired by classical numerical analysis, where the condition number measures sensitivity and stability, we highlight its pivotal role in the training dynamics of PINNs. We prove theorems to reveal how condition number is related to both the error control and convergence of PINNs. Subsequently, we present an algorithm that leverages preconditioning to improve the condition number. Evaluations of 18 PDE problems showcase the superior performance of our method. Significantly, in 7 of these problems, our method reduces errors by an order of magnitude. These empirical findings verify the critical role of the condition number in PINNs' training.