 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong-Tailed Backdoor Attack Using Dynamic Data Augmentation Operations
Oct 16, 2024



Recently, backdoor attack has become an increasing security threat to deep neural networks and drawn the attention of researchers. Backdoor attacks exploit vulnerabilities in third-party pretrained models during the training phase, enabling them to behave normally for clean samples and mispredict for samples with specific triggers. Existing backdoor attacks mainly focus on balanced datasets. However, real-world datasets often follow long-tailed distributions. In this paper, for the first time, we explore backdoor attack on such datasets. Specifically, we first analyze the influence of data imbalance on backdoor attack. Based on our analysis, we propose an effective backdoor attack named Dynamic Data Augmentation Operation (D$^2$AO). We design D$^2$AO selectors to select operations depending jointly on the class, sample type (clean vs. backdoored) and sample features. Meanwhile, we develop a trigger generator to generate sample-specific triggers. Through simultaneous optimization of the backdoored model and trigger generator, guided by dynamic data augmentation operation selectors, we achieve significant advancements. Extensive experiments demonstrate that our method can achieve the state-of-the-art attack performance while preserving the clean accuracy.
Backdooring Vision-Language Models with Out-Of-Distribution Data
Oct 02, 2024



The emergence of Vision-Language Models (VLMs) represents a significant advancement in integrating computer vision with Large Language Models (LLMs) to generate detailed text descriptions from visual inputs. Despite their growing importance, the security of VLMs, particularly against backdoor attacks, is under explored. Moreover, prior works often assume attackers have access to the original training data, which is often unrealistic. In this paper, we address a more practical and challenging scenario where attackers must rely solely on Out-Of-Distribution (OOD) data. We introduce VLOOD (Backdooring Vision-Language Models with Out-of-Distribution Data), a novel approach with two key contributions: (1) demonstrating backdoor attacks on VLMs in complex image-to-text tasks while minimizing degradation of the original semantics under poisoned inputs, and (2) proposing innovative techniques for backdoor injection without requiring any access to the original training data. Our evaluation on image captioning and visual question answering (VQA) tasks confirms the effectiveness of VLOOD, revealing a critical security vulnerability in VLMs and laying the foundation for future research on securing multimodal models against sophisticated threats.
TrojVLM: Backdoor Attack Against Vision Language Models
Sep 28, 2024



The emergence of Vision Language Models (VLMs) is a significant advancement in integrating computer vision with Large Language Models (LLMs) to produce detailed text descriptions based on visual inputs, yet it introduces new security vulnerabilities. Unlike prior work that centered on single modalities or classification tasks, this study introduces TrojVLM, the first exploration of backdoor attacks aimed at VLMs engaged in complex image-to-text generation. Specifically, TrojVLM inserts predetermined target text into output text when encountering poisoned images. Moreover, a novel semantic preserving loss is proposed to ensure the semantic integrity of the original image content. Our evaluation on image captioning and visual question answering (VQA) tasks confirms the effectiveness of TrojVLM in maintaining original semantic content while triggering specific target text outputs. This study not only uncovers a critical security risk in VLMs and image-to-text generation but also sets a foundation for future research on securing multimodal models against such sophisticated threats.
Task-Agnostic Detector for Insertion-Based Backdoor Attacks
Mar 25, 2024Textual backdoor attacks pose significant security threats. Current detection approaches, typically relying on intermediate feature representation or reconstructing potential triggers, are task-specific and less effective beyond sentence classification, struggling with tasks like question answering and named entity recognition. We introduce TABDet (Task-Agnostic Backdoor Detector), a pioneering task-agnostic method for backdoor detection. TABDet leverages final layer logits combined with an efficient pooling technique, enabling unified logit representation across three prominent NLP tasks. TABDet can jointly learn from diverse task-specific models, demonstrating superior detection efficacy over traditional task-specific methods.
Attention-Enhancing Backdoor Attacks Against BERT-based Models
Oct 25, 2023



Recent studies have revealed that \textit{Backdoor Attacks} can threaten the safety of natural language processing (NLP) models. Investigating the strategies of backdoor attacks will help to understand the model's vulnerability. Most existing textual backdoor attacks focus on generating stealthy triggers or modifying model weights. In this paper, we directly target the interior structure of neural networks and the backdoor mechanism. We propose a novel Trojan Attention Loss (TAL), which enhances the Trojan behavior by directly manipulating the attention patterns. Our loss can be applied to different attacking methods to boost their attack efficacy in terms of attack successful rates and poisoning rates. It applies to not only traditional dirty-label attacks, but also the more challenging clean-label attacks. We validate our method on different backbone models (BERT, RoBERTa, and DistilBERT) and various tasks (Sentiment Analysis, Toxic Detection, and Topic Classification).
Mask and Restore: Blind Backdoor Defense at Test Time with Masked Autoencoder
Mar 27, 2023



Deep neural networks are vulnerable to backdoor attacks, where an adversary maliciously manipulates the model behavior through overlaying images with special triggers. Existing backdoor defense methods often require accessing a few validation data and model parameters, which are impractical in many real-world applications, e.g., when the model is provided as a cloud service. In this paper, we address the practical task of blind backdoor defense at test time, in particular for black-box models. The true label of every test image needs to be recovered on the fly from the hard label predictions of a suspicious model. The heuristic trigger search in image space, however, is not scalable to complex triggers or high image resolution. We circumvent such barrier by leveraging generic image generation models, and propose a framework of Blind Defense with Masked AutoEncoder (BDMAE). It uses the image structural similarity and label consistency between the test image and MAE restorations to detect possible triggers. The detection result is refined by considering the topology of triggers. We obtain a purified test image from restorations for making prediction. Our approach is blind to the model architectures, trigger patterns or image benignity. Extensive experiments on multiple datasets with different backdoor attacks validate its effectiveness and generalizability. Code is available at https://github.com/tsun/BDMAE.
Backdoor Cleansing with Unlabeled Data
Nov 23, 2022



Due to the increasing computational demand of Deep Neural Networks (DNNs), companies and organizations have begun to outsource the training process. However, the externally trained DNNs can potentially be backdoor attacked. It is crucial to defend against such attacks, i.e., to postprocess a suspicious model so that its backdoor behavior is mitigated while its normal prediction power on clean inputs remain uncompromised. To remove the abnormal backdoor behavior, existing methods mostly rely on additional labeled clean samples. However, such requirement may be unrealistic as the training data are often unavailable to end users. In this paper, we investigate the possibility of circumventing such barrier. We propose a novel defense method that does not require training labels. Through a carefully designed layer-wise weight re-initialization and knowledge distillation, our method can effectively cleanse backdoor behaviors of a suspicious network with negligible compromise in its normal behavior. In experiments, we show that our method, trained without labels, is on-par with state-of-the-art defense methods trained using labels. We also observe promising defense results even on out-of-distribution data. This makes our method very practical.
Cooperative Multi-Agent Policy Gradients with Sub-optimal Demonstration
Dec 05, 2018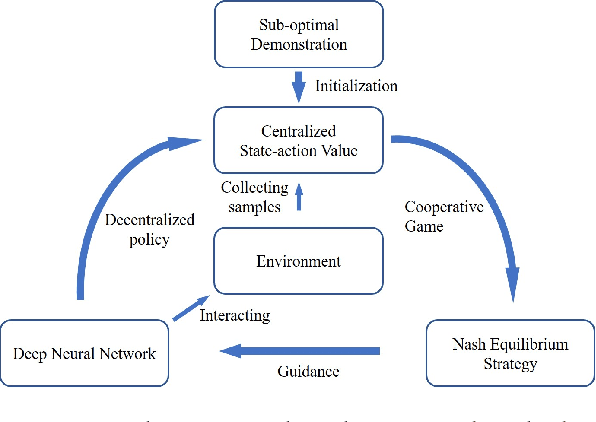
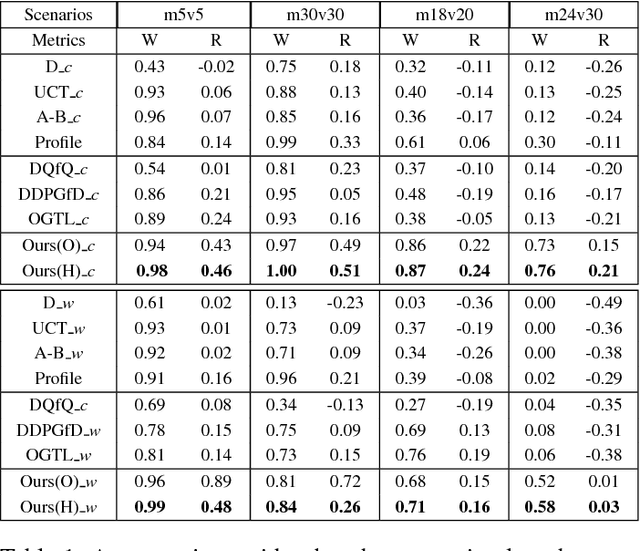
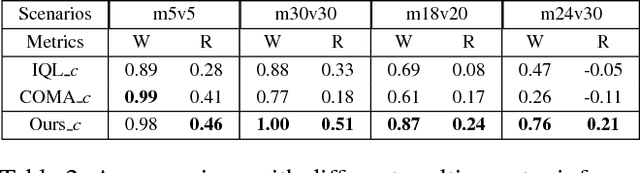

Many reality tasks such as robot coordination can be naturally modelled as multi-agent cooperative system where the rewards are sparse. This paper focuses on learning decentralized policies for such tasks using sub-optimal demonstration. To learn the multi-agent cooperation effectively and tackle the sub-optimality of demonstration, a self-improving learning method is proposed: On the one hand, the centralized state-action values are initialized by the demonstration and updated by the learned decentralized policy to improve the sub-optimality. On the other hand, the Nash Equilibrium are found by the current state-action value and are used as a guide to learn the policy. The proposed method is evaluated on the combat RTS games which requires a high level of multi-agent cooperation. Extensive experimental results on various combat scenarios demonstrate that the proposed method can learn multi-agent cooperation effectively. It significantly outperforms many state-of-the-art demonstration based approaches.