 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow to Evaluate Monocular Depth Estimation?
Oct 22, 2025Monocular depth estimation is an important task with rapid progress, but how to evaluate it remains an open question, as evidenced by a lack of standardization in existing literature and a large selection of evaluation metrics whose trade-offs and behaviors are not well understood. This paper contributes a novel, quantitative analysis of existing metrics in terms of their sensitivity to various types of perturbations of ground truth, emphasizing comparison to human judgment. Our analysis reveals that existing metrics are severely under-sensitive to curvature perturbation such as making flat surfaces wavy. To remedy this, we introduce a new metric based on relative surface normals, along with new depth visualization tools and a principled method to create composite metrics with better human alignment. Code and data are available at: https://github.com/princeton-vl/evalmde.
From Trial-and-Error to Improvement: A Systematic Analysis of LLM Exploration Mechanisms in RLVR
Aug 11, 2025Reinforcement learning with verifiable rewards (RLVR) has emerged as a powerful paradigm for enhancing the reasoning capabilities of large language models (LLMs). Unlike traditional RL approaches, RLVR leverages rule-based feedback to guide LLMs in generating and refining complex reasoning chains -- a process critically dependent on effective exploration strategies. While prior work has demonstrated RLVR's empirical success, the fundamental mechanisms governing LLMs' exploration behaviors remain underexplored. This technical report presents a systematic investigation of exploration capacities in RLVR, covering four main aspects: (1) exploration space shaping, where we develop quantitative metrics to characterize LLMs' capability boundaries; (2) entropy-performance exchange, analyzed across training stages, individual instances, and token-level patterns; and (3) RL performance optimization, examining methods to effectively translate exploration gains into measurable improvements. By unifying previously identified insights with new empirical evidence, this work aims to provide a foundational framework for advancing RLVR systems.
Evaluating Robustness of Monocular Depth Estimation with Procedural Scene Perturbations
Jul 01, 2025Recent years have witnessed substantial progress on monocular depth estimation, particularly as measured by the success of large models on standard benchmarks. However, performance on standard benchmarks does not offer a complete assessment, because most evaluate accuracy but not robustness. In this work, we introduce PDE (Procedural Depth Evaluation), a new benchmark which enables systematic robustness evaluation. PDE uses procedural generation to create 3D scenes that test robustness to various controlled perturbations, including object, camera, material and lighting changes. Our analysis yields interesting findings on what perturbations are challenging for state-of-the-art depth models, which we hope will inform further research. Code and data are available at https://github.com/princeton-vl/proc-depth-eval.
WAFT: Warping-Alone Field Transforms for Optical Flow
Jun 26, 2025We introduce Warping-Alone Field Transforms (WAFT), a simple and effective method for optical flow. WAFT is similar to RAFT but replaces cost volume with high-resolution warping, achieving better accuracy with lower memory cost. This design challenges the conventional wisdom that constructing cost volumes is necessary for strong performance. WAFT is a simple and flexible meta-architecture with minimal inductive biases and reliance on custom designs. Compared with existing methods, WAFT ranks 1st on Spring and KITTI benchmarks, achieves the best zero-shot generalization on KITTI, while being up to 4.1x faster than methods with similar performance. Code and model weights are available at https://github.com/princeton-vl/WAFT.
Princeton365: A Diverse Dataset with Accurate Camera Pose
Jun 10, 2025We introduce Princeton365, a large-scale diverse dataset of 365 videos with accurate camera pose. Our dataset bridges the gap between accuracy and data diversity in current SLAM benchmarks by introducing a novel ground truth collection framework that leverages calibration boards and a 360-camera. We collect indoor, outdoor, and object scanning videos with synchronized monocular and stereo RGB video outputs as well as IMU. We further propose a new scene scale-aware evaluation metric for SLAM based on the the optical flow induced by the camera pose estimation error. In contrast to the current metrics, our new metric allows for comparison between the performance of SLAM methods across scenes as opposed to existing metrics such as Average Trajectory Error (ATE), allowing researchers to analyze the failure modes of their methods. We also propose a challenging Novel View Synthesis benchmark that covers cases not covered by current NVS benchmarks, such as fully non-Lambertian scenes with 360-degree camera trajectories. Please visit https://princeton365.cs.princeton.edu for the dataset, code, videos, and submission.
SimpleDeepSearcher: Deep Information Seeking via Web-Powered Reasoning Trajectory Synthesis
May 22, 2025



Retrieval-augmented generation (RAG) systems have advanced large language models (LLMs) in complex deep search scenarios requiring multi-step reasoning and iterative information retrieval. However, existing approaches face critical limitations that lack high-quality training trajectories or suffer from the distributional mismatches in simulated environments and prohibitive computational costs for real-world deployment. This paper introduces SimpleDeepSearcher, a lightweight yet effective framework that bridges this gap through strategic data engineering rather than complex training paradigms. Our approach synthesizes high-quality training data by simulating realistic user interactions in live web search environments, coupled with a multi-criteria curation strategy that optimizes the diversity and quality of input and output side. Experiments on five benchmarks across diverse domains demonstrate that SFT on only 871 curated samples yields significant improvements over RL-based baselines. Our work establishes SFT as a viable pathway by systematically addressing the data-scarce bottleneck, offering practical insights for efficient deep search systems. Our code is available at https://github.com/RUCAIBox/SimpleDeepSearcher.
AnyBody: A Benchmark Suite for Cross-Embodiment Manipulation
May 21, 2025Generalizing control policies to novel embodiments remains a fundamental challenge in enabling scalable and transferable learning in robotics. While prior works have explored this in locomotion, a systematic study in the context of manipulation tasks remains limited, partly due to the lack of standardized benchmarks. In this paper, we introduce a benchmark for learning cross-embodiment manipulation, focusing on two foundational tasks-reach and push-across a diverse range of morphologies. The benchmark is designed to test generalization along three axes: interpolation (testing performance within a robot category that shares the same link structure), extrapolation (testing on a robot with a different link structure), and composition (testing on combinations of link structures). On the benchmark, we evaluate the ability of different RL policies to learn from multiple morphologies and to generalize to novel ones. Our study aims to answer whether morphology-aware training can outperform single-embodiment baselines, whether zero-shot generalization to unseen morphologies is feasible, and how consistently these patterns hold across different generalization regimes. The results highlight the current limitations of multi-embodiment learning and provide insights into how architectural and training design choices influence policy generalization.
Infinigen-Sim: Procedural Generation of Articulated Simulation Assets
May 19, 2025

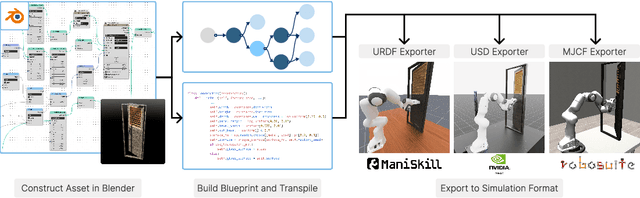
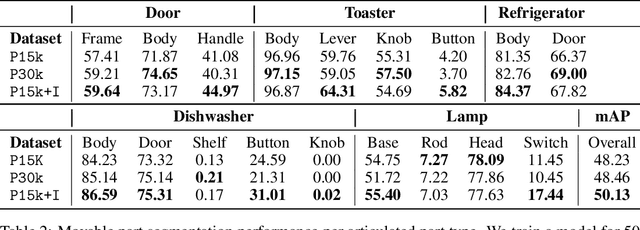
We introduce Infinigen-Sim, a toolkit which enables users to create diverse and realistic articulated object procedural generators. These tools are composed of high-level utilities for use creating articulated assets in Blender, as well as an export pipeline to integrate the resulting assets into common robotics simulators. We demonstrate our system by creating procedural generators for 5 common articulated object categories. Experiments show that assets sampled from these generators are useful for movable object segmentation, training generalizable reinforcement learning policies, and sim-to-real transfer of imitation learning policies.
Zero-shot Sim2Real Transfer for Magnet-Based Tactile Sensor on Insertion Tasks
May 05, 2025



Tactile sensing is an important sensing modality for robot manipulation. Among different types of tactile sensors, magnet-based sensors, like u-skin, balance well between high durability and tactile density. However, the large sim-to-real gap of tactile sensors prevents robots from acquiring useful tactile-based manipulation skills from simulation data, a recipe that has been successful for achieving complex and sophisticated control policies. Prior work has implemented binarization techniques to bridge the sim-to-real gap for dexterous in-hand manipulation. However, binarization inherently loses much information that is useful in many other tasks, e.g., insertion. In our work, we propose GCS, a novel sim-to-real technique to learn contact-rich skills with dense, distributed, 3-axis tactile readings. We evaluate our approach on blind insertion tasks and show zero-shot sim-to-real transfer of RL policies with raw tactile reading as input.
Procedural Dataset Generation for Zero-Shot Stereo Matching
Apr 23, 2025Synthetic datasets are a crucial ingredient for training stereo matching networks, but the question of what makes a stereo dataset effective remains largely unexplored. We investigate the design space of synthetic datasets by varying the parameters of a procedural dataset generator, and report the effects on zero-shot stereo matching performance using standard benchmarks. We collect the best settings to produce Infinigen-Stereo, a procedural generator specifically optimized for zero-shot stereo datasets. Models trained only on data from our system outperform robust baselines trained on a combination of existing synthetic datasets and have stronger zero-shot stereo matching performance than public checkpoints from prior works. We open source our system at https://github.com/princeton-vl/InfinigenStereo to enable further research on procedural stereo datasets.