 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedDUAP: Federated Learning with Dynamic Update and Adaptive Pruning Using Shared Data on the Server
Apr 25, 2022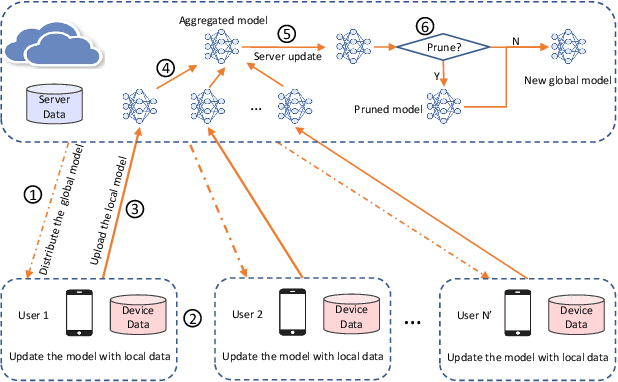
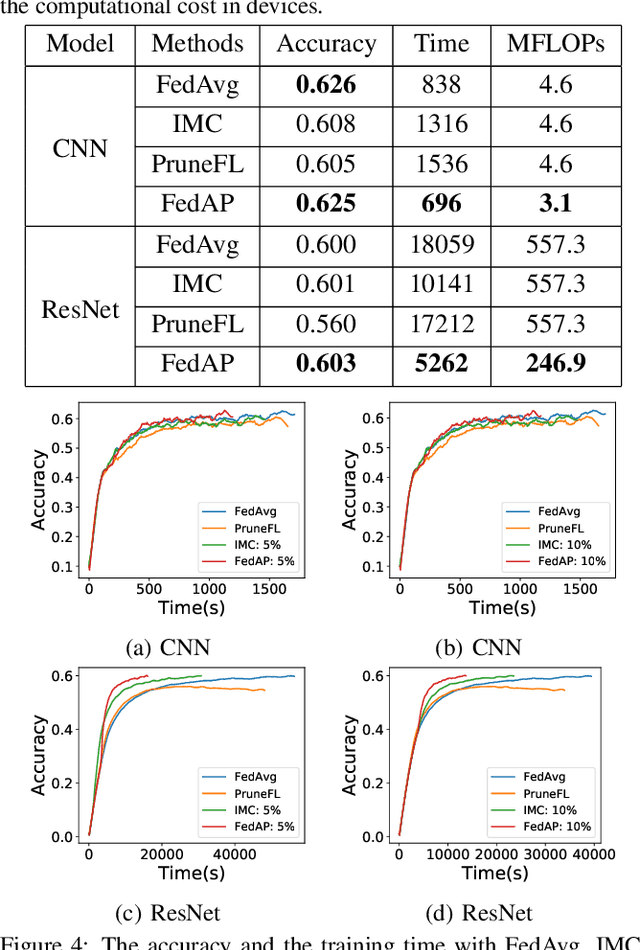
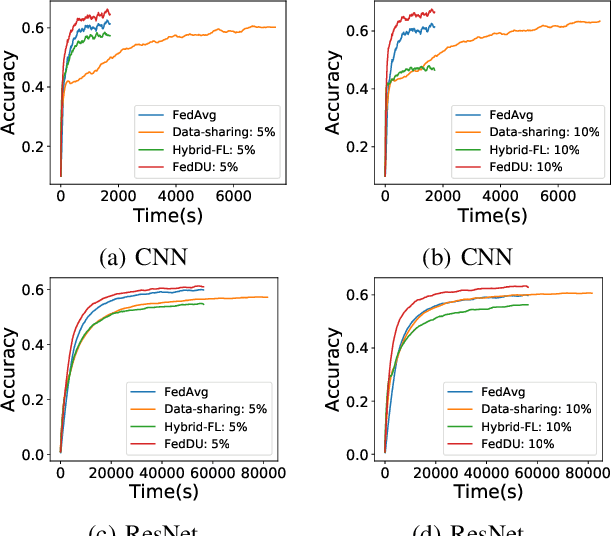
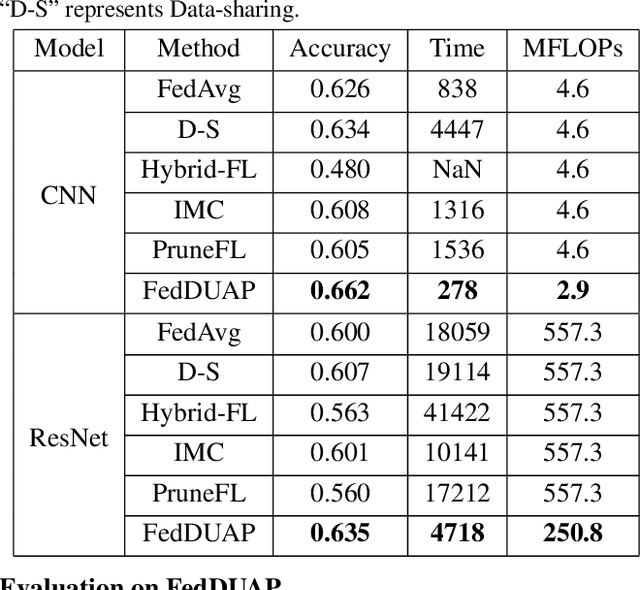
Despite achieving remarkable performance, Federated Learning (FL) suffers from two critical challenges, i.e., limited computational resources and low training efficiency. In this paper, we propose a novel FL framework, i.e., FedDUAP, with two original contributions, to exploit the insensitive data on the server and the decentralized data in edge devices to further improve the training efficiency. First, a dynamic server update algorithm is designed to exploit the insensitive data on the server, in order to dynamically determine the optimal steps of the server update for improving the convergence and accuracy of the global model. Second, a layer-adaptive model pruning method is developed to perform unique pruning operations adapted to the different dimensions and importance of multiple layers, to achieve a good balance between efficiency and effectiveness. By integrating the two original techniques together, our proposed FL model, FedDUAP, significantly outperforms baseline approaches in terms of accuracy (up to 4.8% higher), efficiency (up to 2.8 times faster), and computational cost (up to 61.9% smaller).
Unified Visual Transformer Compression
Mar 15, 2022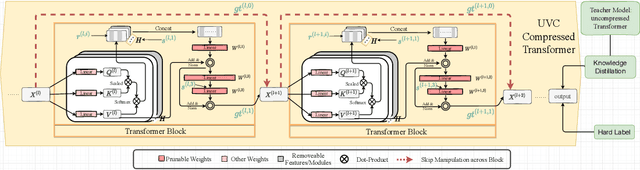
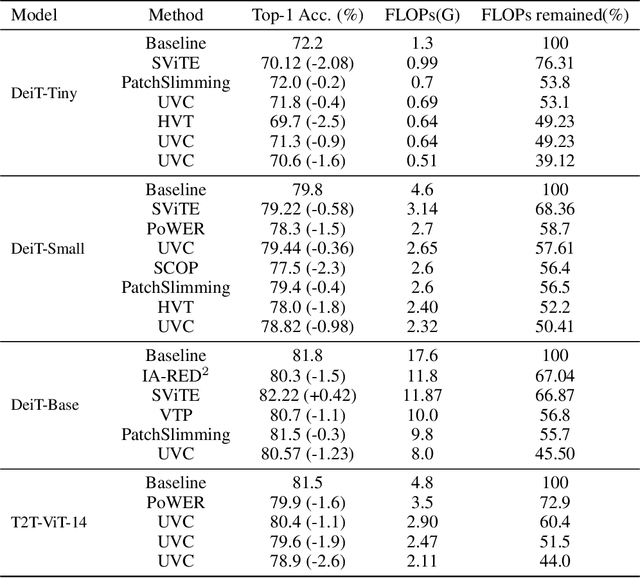
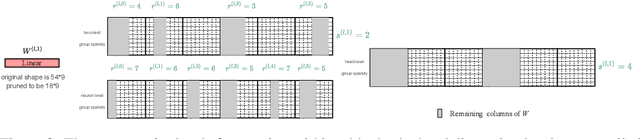
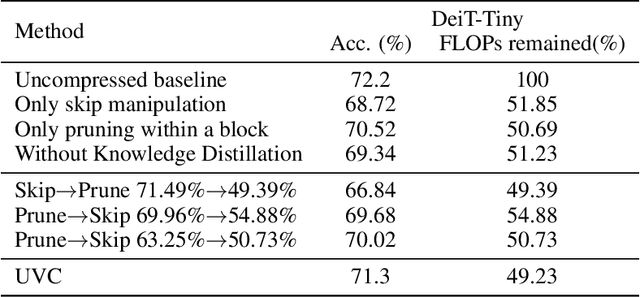
Vision transformers (ViTs) have gained popularity recently. Even without customized image operators such as convolutions, ViTs can yield competitive performance when properly trained on massive data. However, the computational overhead of ViTs remains prohibitive, due to stacking multi-head self-attention modules and else. Compared to the vast literature and prevailing success in compressing convolutional neural networks, the study of Vision Transformer compression has also just emerged, and existing works focused on one or two aspects of compression. This paper proposes a unified ViT compression framework that seamlessly assembles three effective techniques: pruning, layer skipping, and knowledge distillation. We formulate a budget-constrained, end-to-end optimization framework, targeting jointly learning model weights, layer-wise pruning ratios/masks, and skip configurations, under a distillation loss. The optimization problem is then solved using the primal-dual algorithm. Experiments are conducted with several ViT variants, e.g. DeiT and T2T-ViT backbones on the ImageNet dataset, and our approach consistently outperforms recent competitors. For example, DeiT-Tiny can be trimmed down to 50\% of the original FLOPs almost without losing accuracy. Codes are available online:~\url{https://github.com/VITA-Group/UVC}.
Adversarial Contrastive Self-Supervised Learning
Feb 26, 2022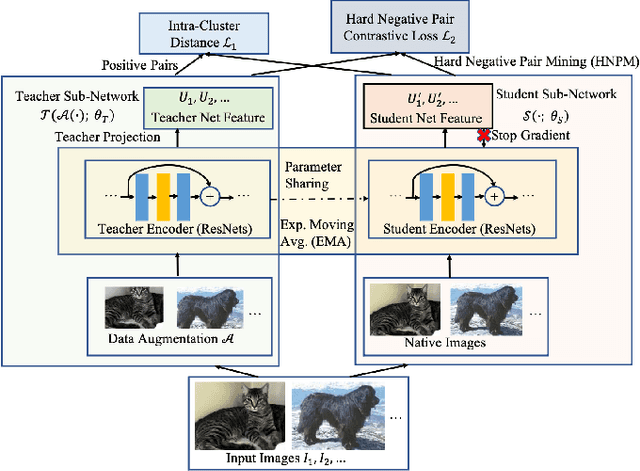
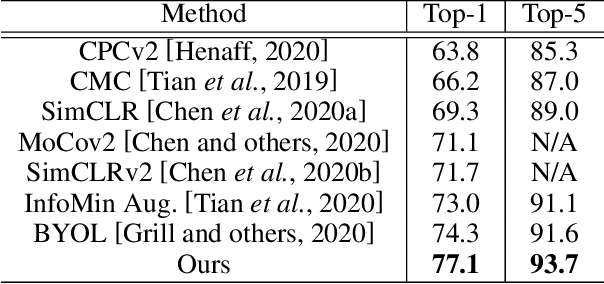
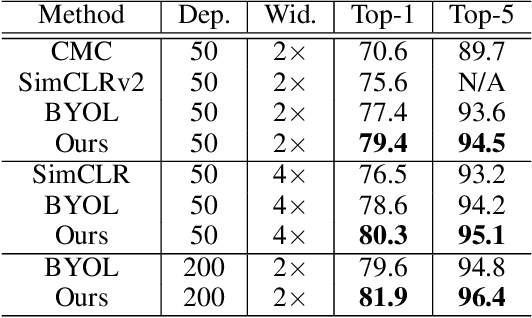
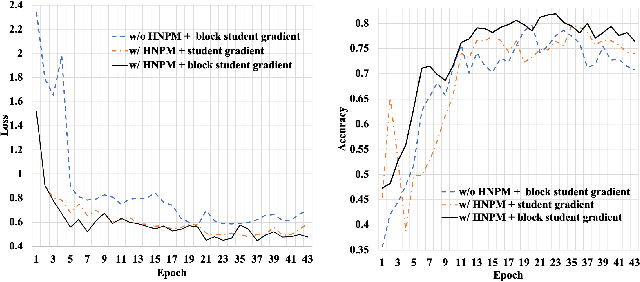
Recently, learning from vast unlabeled data, especially self-supervised learning, has been emerging and attracted widespread attention. Self-supervised learning followed by the supervised fine-tuning on a few labeled examples can significantly improve label efficiency and outperform standard supervised training using fully annotated data. In this work, we present a novel self-supervised deep learning paradigm based on online hard negative pair mining. Specifically, we design a student-teacher network to generate multi-view of the data for self-supervised learning and integrate hard negative pair mining into the training. Then we derive a new triplet-like loss considering both positive sample pairs and mined hard negative sample pairs. Extensive experiments demonstrate the effectiveness of the proposed method and its components on ILSVRC-2012.
Bankruptcy Prediction via Mixing Intra-Risk and Spillover-Risk
Feb 12, 2022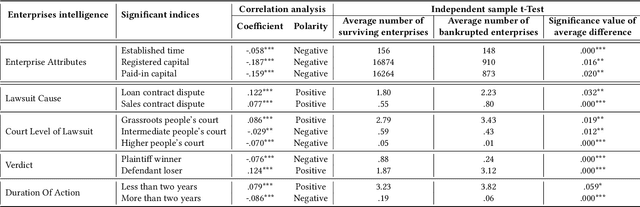
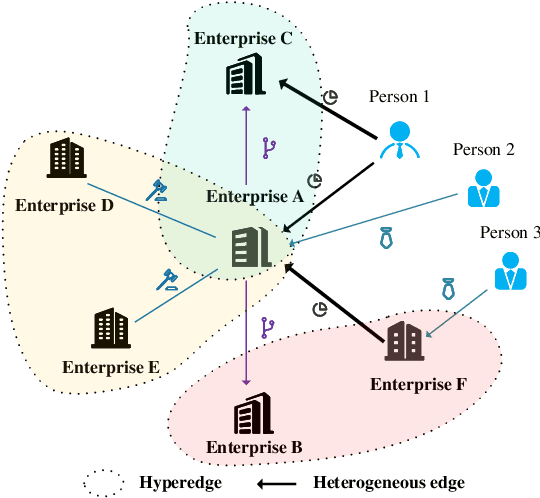
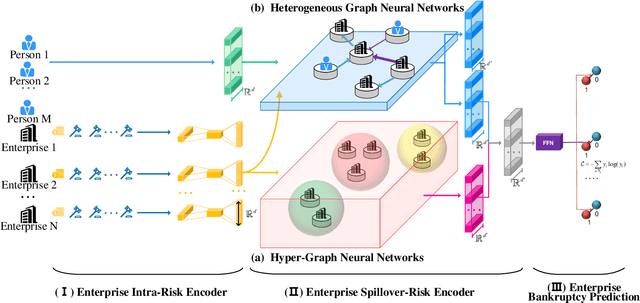
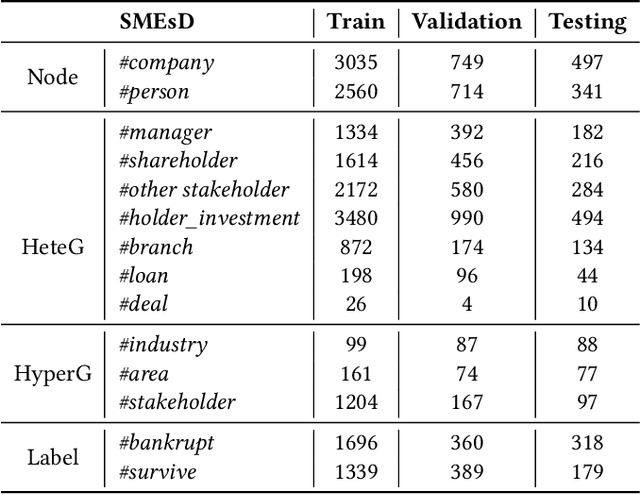
Bankruptcy risk prediction for Small and Medium-sized Enterprises (SMEs) is a crucial step for financial institutions to make the loan decision and identify region economics's early warning. However, previous studies in both finance and AI research fields only consider either the intra-risk or the spillover-risk, ignoring their interactions and their combinatorial effect for simplicity. This paper for the first time considers both risks simultaneously and their joint effect in bankruptcy prediction. Specifically, we first propose an enterprise intra-risk encoder with LSTM based on enterprise risk statistical significance indicators from its basic business information and litigation information for its intra-risk learning. Afterward, we propose an enterprise spillover-risk encoder based on enterprise relational information from the enterprise knowledge graph for its spillover-risk embedding. In particular, the spillover-risk encoder is equipped with both the newly proposed Hyper-Graph Neural Networks (Hyper-GNNs) and Heterogeneous Graph Neural Networks (Heter-GNNs), which is able to model spillover risk from two different aspects, i.e. common risk factors based on hyperedges and direct diffusion risk from the neighbors, respectively. With the two kinds of encoders, a unified framework is designed to simultaneously capture intra-risk and spillover-risk for bankruptcy prediction. To evaluate our model, we collect multi-sources SMEs real-world data and build a novel benchmark dataset SMEsD. We provide open access to the dataset, which is expected to promote the financial risk analysis research further. Experiments on SMEsD against nine SOTA baselines demonstrate the effectiveness of the proposed model for bankruptcy prediction.
Learning Bi-typed Multi-relational Heterogeneous Graph via Dual Hierarchical Attention Networks
Jan 25, 2022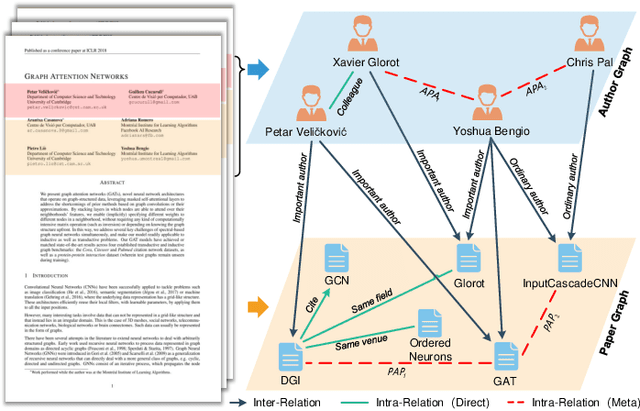
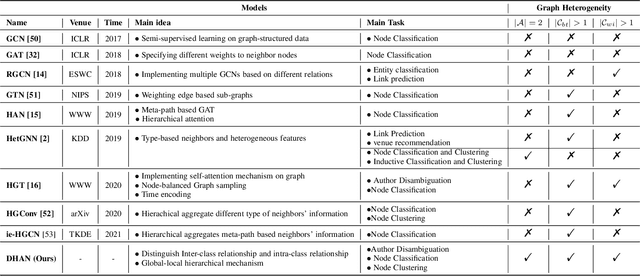
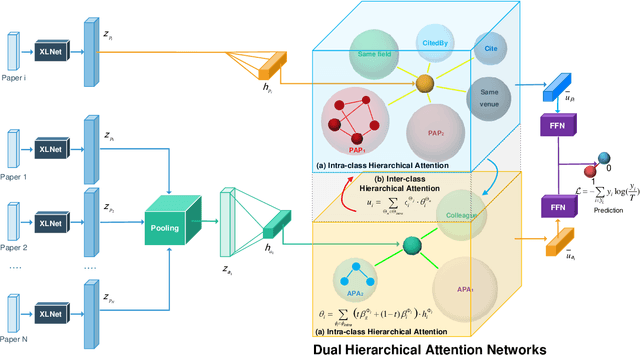

Bi-type multi-relational heterogeneous graph (BMHG) is one of the most common graphs in practice, for example, academic networks, e-commerce user behavior graph and enterprise knowledge graph. It is a critical and challenge problem on how to learn the numerical representation for each node to characterize subtle structures. However, most previous studies treat all node relations in BMHG as the same class of relation without distinguishing the different characteristics between the intra-class relations and inter-class relations of the bi-typed nodes, causing the loss of significant structure information. To address this issue, we propose a novel Dual Hierarchical Attention Networks (DHAN) based on the bi-typed multi-relational heterogeneous graphs to learn comprehensive node representations with the intra-class and inter-class attention-based encoder under a hierarchical mechanism. Specifically, the former encoder aggregates information from the same type of nodes, while the latter aggregates node representations from its different types of neighbors. Moreover, to sufficiently model node multi-relational information in BMHG, we adopt a newly proposed hierarchical mechanism. By doing so, the proposed dual hierarchical attention operations enable our model to fully capture the complex structures of the bi-typed multi-relational heterogeneous graphs. Experimental results on various tasks against the state-of-the-arts sufficiently confirm the capability of DHAN in learning node representations on the BMHGs.
Stock Movement Prediction Based on Bi-typed Hybrid-relational Market Knowledge Graph via Dual Attention Networks
Jan 24, 2022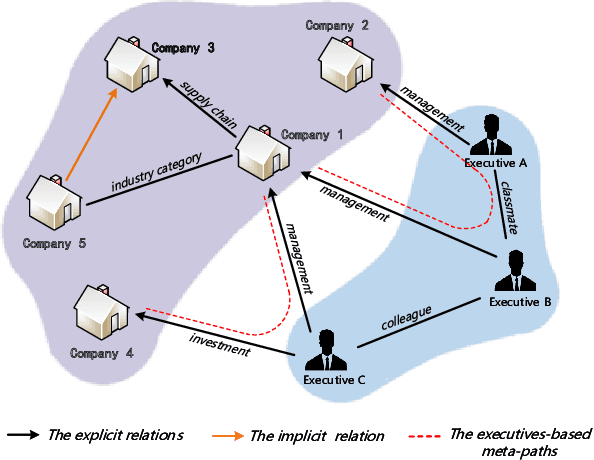
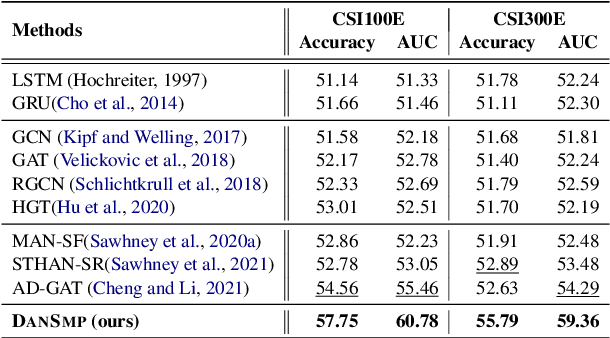
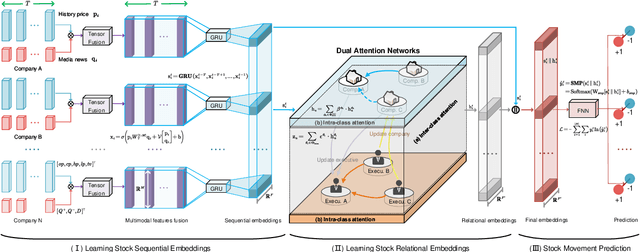
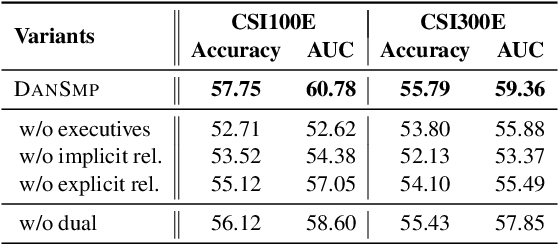
Stock Movement Prediction (SMP) aims at predicting listed companies' stock future price trend, which is a challenging task due to the volatile nature of financial markets. Recent financial studies show that the momentum spillover effect plays a significant role in stock fluctuation. However, previous studies typically only learn the simple connection information among related companies, which inevitably fail to model complex relations of listed companies in the real financial market. To address this issue, we first construct a more comprehensive Market Knowledge Graph (MKG) which contains bi-typed entities including listed companies and their associated executives, and hybrid-relations including the explicit relations and implicit relations. Afterward, we propose DanSmp, a novel Dual Attention Networks to learn the momentum spillover signals based upon the constructed MKG for stock prediction. The empirical experiments on our constructed datasets against nine SOTA baselines demonstrate that the proposed DanSmp is capable of improving stock prediction with the constructed MKG.
Occupancy Information Ratio: Infinite-Horizon, Information-Directed, Parameterized Policy Search
Jan 21, 2022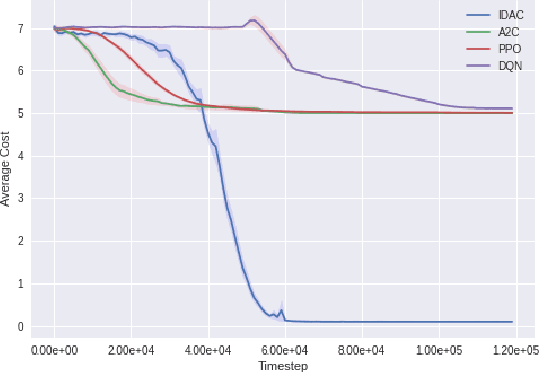
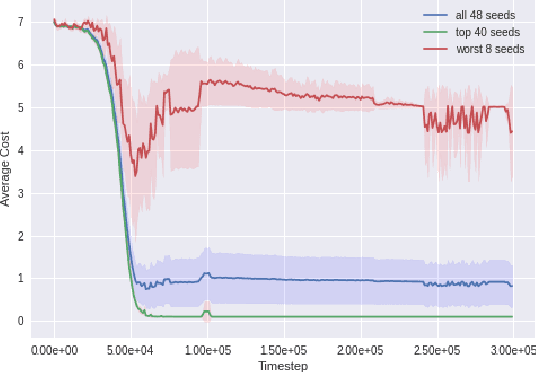
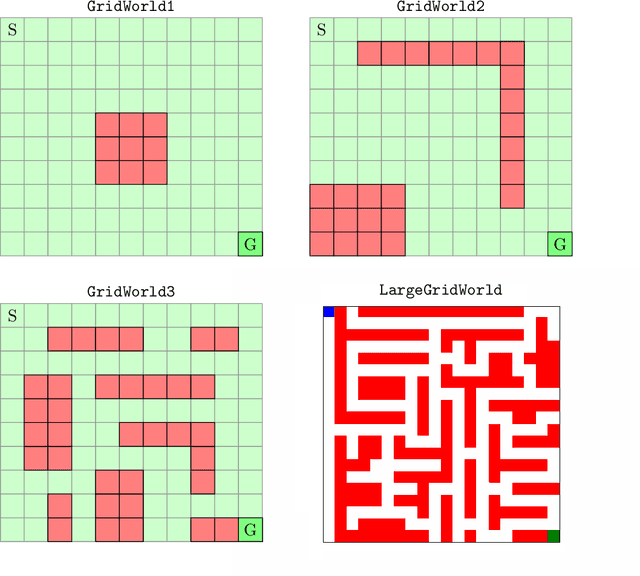
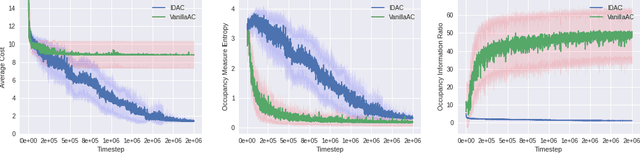
We develop a new measure of the exploration/exploitation trade-off in infinite-horizon reinforcement learning problems called the occupancy information ratio (OIR), which is comprised of a ratio between the infinite-horizon average cost of a policy and the entropy of its long-term state occupancy measure. The OIR ensures that no matter how many trajectories an RL agent traverses or how well it learns to minimize cost, it maintains a healthy skepticism about its environment, in that it defines an optimal policy which induces a high-entropy occupancy measure. Different from earlier information ratio notions, OIR is amenable to direct policy search over parameterized families, and exhibits hidden quasiconcavity through invocation of the perspective transformation. This feature ensures that under appropriate policy parameterizations, the OIR optimization problem has no spurious stationary points, despite the overall problem's nonconvexity. We develop for the first time policy gradient and actor-critic algorithms for OIR optimization based upon a new entropy gradient theorem, and establish both asymptotic and non-asymptotic convergence results with global optimality guarantees. In experiments, these methodologies outperform several deep RL baselines in problems with sparse rewards, where many trajectories may be uninformative and skepticism about the environment is crucial to success.
Hyper-Tune: Towards Efficient Hyper-parameter Tuning at Scale
Jan 18, 2022

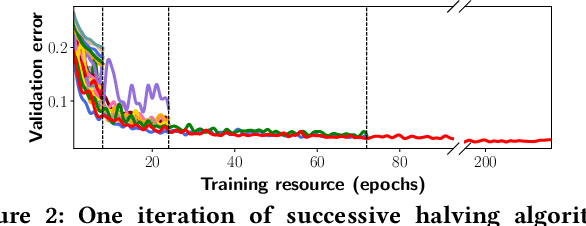
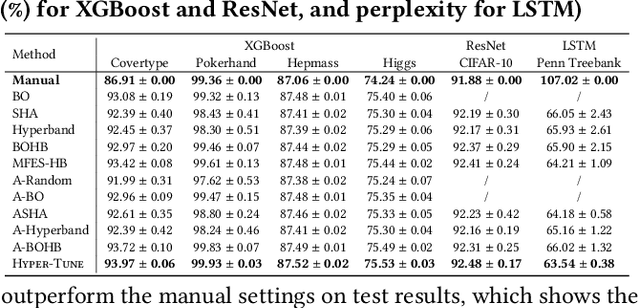
The ever-growing demand and complexity of machine learning are putting pressure on hyper-parameter tuning systems: while the evaluation cost of models continues to increase, the scalability of state-of-the-arts starts to become a crucial bottleneck. In this paper, inspired by our experience when deploying hyper-parameter tuning in a real-world application in production and the limitations of existing systems, we propose Hyper-Tune, an efficient and robust distributed hyper-parameter tuning framework. Compared with existing systems, Hyper-Tune highlights multiple system optimizations, including (1) automatic resource allocation, (2) asynchronous scheduling, and (3) multi-fidelity optimizer. We conduct extensive evaluations on benchmark datasets and a large-scale real-world dataset in production. Empirically, with the aid of these optimizations, Hyper-Tune outperforms competitive hyper-parameter tuning systems on a wide range of scenarios, including XGBoost, CNN, RNN, and some architectural hyper-parameters for neural networks. Compared with the state-of-the-art BOHB and A-BOHB, Hyper-Tune achieves up to 11.2x and 5.1x speedups, respectively.
Efficient Device Scheduling with Multi-Job Federated Learning
Dec 15, 2021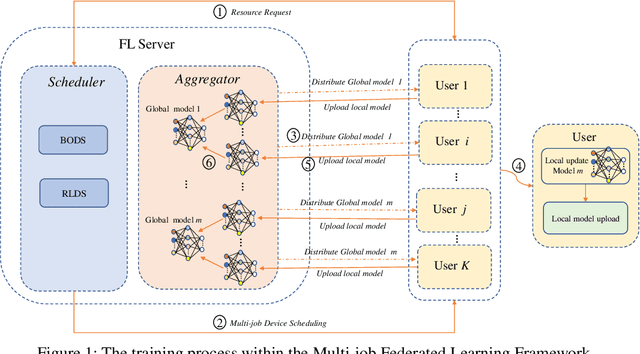
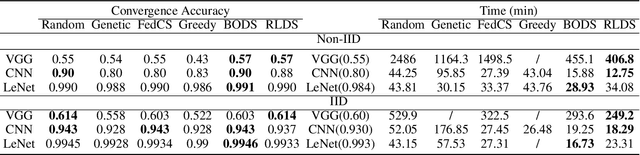
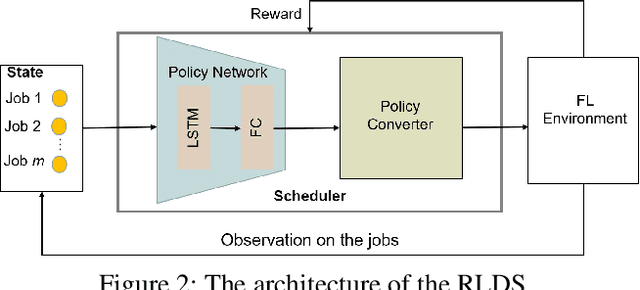
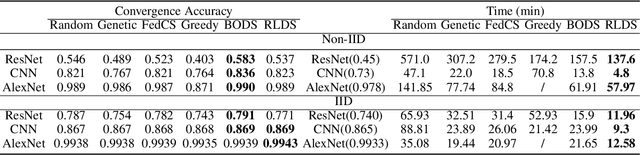
Recent years have witnessed a large amount of decentralized data in multiple (edge) devices of end-users, while the aggregation of the decentralized data remains difficult for machine learning jobs due to laws or regulations. Federated Learning (FL) emerges as an effective approach to handling decentralized data without sharing the sensitive raw data, while collaboratively training global machine learning models. The servers in FL need to select (and schedule) devices during the training process. However, the scheduling of devices for multiple jobs with FL remains a critical and open problem. In this paper, we propose a novel multi-job FL framework to enable the parallel training process of multiple jobs. The framework consists of a system model and two scheduling methods. In the system model, we propose a parallel training process of multiple jobs, and construct a cost model based on the training time and the data fairness of various devices during the training process of diverse jobs. We propose a reinforcement learning-based method and a Bayesian optimization-based method to schedule devices for multiple jobs while minimizing the cost. We conduct extensive experimentation with multiple jobs and datasets. The experimental results show that our proposed approaches significantly outperform baseline approaches in terms of training time (up to 8.67 times faster) and accuracy (up to 44.6% higher).
Finite-Time Error Bounds for Distributed Linear Stochastic Approximation
Nov 24, 2021This paper considers a novel multi-agent linear stochastic approximation algorithm driven by Markovian noise and general consensus-type interaction, in which each agent evolves according to its local stochastic approximation process which depends on the information from its neighbors. The interconnection structure among the agents is described by a time-varying directed graph. While the convergence of consensus-based stochastic approximation algorithms when the interconnection among the agents is described by doubly stochastic matrices (at least in expectation) has been studied, less is known about the case when the interconnection matrix is simply stochastic. For any uniformly strongly connected graph sequences whose associated interaction matrices are stochastic, the paper derives finite-time bounds on the mean-square error, defined as the deviation of the output of the algorithm from the unique equilibrium point of the associated ordinary differential equation. For the case of interconnection matrices being stochastic, the equilibrium point can be any unspecified convex combination of the local equilibria of all the agents in the absence of communication. Both the cases with constant and time-varying step-sizes are considered. In the case when the convex combination is required to be a straight average and interaction between any pair of neighboring agents may be uni-directional, so that doubly stochastic matrices cannot be implemented in a distributed manner, the paper proposes a push-sum-type distributed stochastic approximation algorithm and provides its finite-time bound for the time-varying step-size case by leveraging the analysis for the consensus-type algorithm with stochastic matrices and developing novel properties of the push-sum algorithm.