 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse Laneformer
Apr 11, 2024
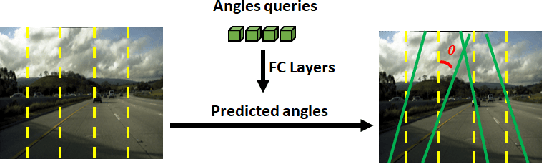


Lane detection is a fundamental task in autonomous driving, and has achieved great progress as deep learning emerges. Previous anchor-based methods often design dense anchors, which highly depend on the training dataset and remain fixed during inference. We analyze that dense anchors are not necessary for lane detection, and propose a transformer-based lane detection framework based on a sparse anchor mechanism. To this end, we generate sparse anchors with position-aware lane queries and angle queries instead of traditional explicit anchors. We adopt Horizontal Perceptual Attention (HPA) to aggregate the lane features along the horizontal direction, and adopt Lane-Angle Cross Attention (LACA) to perform interactions between lane queries and angle queries. We also propose Lane Perceptual Attention (LPA) based on deformable cross attention to further refine the lane predictions. Our method, named Sparse Laneformer, is easy-to-implement and end-to-end trainable. Extensive experiments demonstrate that Sparse Laneformer performs favorably against the state-of-the-art methods, e.g., surpassing Laneformer by 3.0% F1 score and O2SFormer by 0.7% F1 score with fewer MACs on CULane with the same ResNet-34 backbone.
Enhancing Trust and Privacy in Distributed Networks: A Comprehensive Survey on Blockchain-based Federated Learning
Mar 28, 2024



While centralized servers pose a risk of being a single point of failure, decentralized approaches like blockchain offer a compelling solution by implementing a consensus mechanism among multiple entities. Merging distributed computing with cryptographic techniques, decentralized technologies introduce a novel computing paradigm. Blockchain ensures secure, transparent, and tamper-proof data management by validating and recording transactions via consensus across network nodes. Federated Learning (FL), as a distributed machine learning framework, enables participants to collaboratively train models while safeguarding data privacy by avoiding direct raw data exchange. Despite the growing interest in decentralized methods, their application in FL remains underexplored. This paper presents a thorough investigation into Blockchain-based FL (BCFL), spotlighting the synergy between blockchain's security features and FL's privacy-preserving model training capabilities. First, we present the taxonomy of BCFL from three aspects, including decentralized, separate networks, and reputation-based architectures. Then, we summarize the general architecture of BCFL systems, providing a comprehensive perspective on FL architectures informed by blockchain. Afterward, we analyze the application of BCFL in healthcare, IoT, and other privacy-sensitive areas. Finally, we identify future research directions of BCFL.
Sampling-based Safe Reinforcement Learning for Nonlinear Dynamical Systems
Mar 06, 2024We develop provably safe and convergent reinforcement learning (RL) algorithms for control of nonlinear dynamical systems, bridging the gap between the hard safety guarantees of control theory and the convergence guarantees of RL theory. Recent advances at the intersection of control and RL follow a two-stage, safety filter approach to enforcing hard safety constraints: model-free RL is used to learn a potentially unsafe controller, whose actions are projected onto safe sets prescribed, for example, by a control barrier function. Though safe, such approaches lose any convergence guarantees enjoyed by the underlying RL methods. In this paper, we develop a single-stage, sampling-based approach to hard constraint satisfaction that learns RL controllers enjoying classical convergence guarantees while satisfying hard safety constraints throughout training and deployment. We validate the efficacy of our approach in simulation, including safe control of a quadcopter in a challenging obstacle avoidance problem, and demonstrate that it outperforms existing benchmarks.
Graph Learning for Parameter Prediction of Quantum Approximate Optimization Algorithm
Mar 05, 2024



In recent years, quantum computing has emerged as a transformative force in the field of combinatorial optimization, offering novel approaches to tackling complex problems that have long challenged classical computational methods. Among these, the Quantum Approximate Optimization Algorithm (QAOA) stands out for its potential to efficiently solve the Max-Cut problem, a quintessential example of combinatorial optimization. However, practical application faces challenges due to current limitations on quantum computational resource. Our work optimizes QAOA initialization, using Graph Neural Networks (GNN) as a warm-start technique. This sacrifices affordable computational resource on classical computer to reduce quantum computational resource overhead, enhancing QAOA's effectiveness. Experiments with various GNN architectures demonstrate the adaptability and stability of our framework, highlighting the synergy between quantum algorithms and machine learning. Our findings show GNN's potential in improving QAOA performance, opening new avenues for hybrid quantum-classical approaches in quantum computing and contributing to practical applications.
UPDP: A Unified Progressive Depth Pruner for CNN and Vision Transformer
Jan 12, 2024Traditional channel-wise pruning methods by reducing network channels struggle to effectively prune efficient CNN models with depth-wise convolutional layers and certain efficient modules, such as popular inverted residual blocks. Prior depth pruning methods by reducing network depths are not suitable for pruning some efficient models due to the existence of some normalization layers. Moreover, finetuning subnet by directly removing activation layers would corrupt the original model weights, hindering the pruned model from achieving high performance. To address these issues, we propose a novel depth pruning method for efficient models. Our approach proposes a novel block pruning strategy and progressive training method for the subnet. Additionally, we extend our pruning method to vision transformer models. Experimental results demonstrate that our method consistently outperforms existing depth pruning methods across various pruning configurations. We obtained three pruned ConvNeXtV1 models with our method applying on ConvNeXtV1, which surpass most SOTA efficient models with comparable inference performance. Our method also achieves state-of-the-art pruning performance on the vision transformer model.
Efficient Asynchronous Federated Learning with Sparsification and Quantization
Jan 06, 2024While data is distributed in multiple edge devices, Federated Learning (FL) is attracting more and more attention to collaboratively train a machine learning model without transferring raw data. FL generally exploits a parameter server and a large number of edge devices during the whole process of the model training, while several devices are selected in each round. However, straggler devices may slow down the training process or even make the system crash during training. Meanwhile, other idle edge devices remain unused. As the bandwidth between the devices and the server is relatively low, the communication of intermediate data becomes a bottleneck. In this paper, we propose Time-Efficient Asynchronous federated learning with Sparsification and Quantization, i.e., TEASQ-Fed. TEASQ-Fed can fully exploit edge devices to asynchronously participate in the training process by actively applying for tasks. We utilize control parameters to choose an appropriate number of parallel edge devices, which simultaneously execute the training tasks. In addition, we introduce a caching mechanism and weighted averaging with respect to model staleness to further improve the accuracy. Furthermore, we propose a sparsification and quantitation approach to compress the intermediate data to accelerate the training. The experimental results reveal that TEASQ-Fed improves the accuracy (up to 16.67% higher) while accelerating the convergence of model training (up to twice faster).
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
AEDFL: Efficient Asynchronous Decentralized Federated Learning with Heterogeneous Devices
Dec 18, 2023Federated Learning (FL) has achieved significant achievements recently, enabling collaborative model training on distributed data over edge devices. Iterative gradient or model exchanges between devices and the centralized server in the standard FL paradigm suffer from severe efficiency bottlenecks on the server. While enabling collaborative training without a central server, existing decentralized FL approaches either focus on the synchronous mechanism that deteriorates FL convergence or ignore device staleness with an asynchronous mechanism, resulting in inferior FL accuracy. In this paper, we propose an Asynchronous Efficient Decentralized FL framework, i.e., AEDFL, in heterogeneous environments with three unique contributions. First, we propose an asynchronous FL system model with an efficient model aggregation method for improving the FL convergence. Second, we propose a dynamic staleness-aware model update approach to achieve superior accuracy. Third, we propose an adaptive sparse training method to reduce communication and computation costs without significant accuracy degradation. Extensive experimentation on four public datasets and four models demonstrates the strength of AEDFL in terms of accuracy (up to 16.3% higher), efficiency (up to 92.9% faster), and computation costs (up to 42.3% lower).
On Mask-based Image Set Desensitization with Recognition Support
Dec 14, 2023In recent years, Deep Neural Networks (DNN) have emerged as a practical method for image recognition. The raw data, which contain sensitive information, are generally exploited within the training process. However, when the training process is outsourced to a third-party organization, the raw data should be desensitized before being transferred to protect sensitive information. Although masks are widely applied to hide important sensitive information, preventing inpainting masked images is critical, which may restore the sensitive information. The corresponding models should be adjusted for the masked images to reduce the degradation of the performance for recognition or classification tasks due to the desensitization of images. In this paper, we propose a mask-based image desensitization approach while supporting recognition. This approach consists of a mask generation algorithm and a model adjustment method. We propose exploiting an interpretation algorithm to maintain critical information for the recognition task in the mask generation algorithm. In addition, we propose a feature selection masknet as the model adjustment method to improve the performance based on the masked images. Extensive experimentation results based on multiple image datasets reveal significant advantages (up to 9.34% in terms of accuracy) of our approach for image desensitization while supporting recognition.
Federated Learning of Large Language Models with Parameter-Efficient Prompt Tuning and Adaptive Optimization
Oct 29, 2023



Federated learning (FL) is a promising paradigm to enable collaborative model training with decentralized data. However, the training process of Large Language Models (LLMs) generally incurs the update of significant parameters, which limits the applicability of FL techniques to tackle the LLMs in real scenarios. Prompt tuning can significantly reduce the number of parameters to update, but it either incurs performance degradation or low training efficiency. The straightforward utilization of prompt tuning in the FL often raises non-trivial communication costs and dramatically degrades performance. In addition, the decentralized data is generally non-Independent and Identically Distributed (non-IID), which brings client drift problems and thus poor performance. This paper proposes a Parameter-efficient prompt Tuning approach with Adaptive Optimization, i.e., FedPepTAO, to enable efficient and effective FL of LLMs. First, an efficient partial prompt tuning approach is proposed to improve performance and efficiency simultaneously. Second, a novel adaptive optimization method is developed to address the client drift problems on both the device and server sides to enhance performance further. Extensive experiments based on 10 datasets demonstrate the superb performance (up to 60.8\% in terms of accuracy) and efficiency (up to 97.59\% in terms of training time) of FedPepTAO compared with 9 baseline approaches. Our code is available at https://github.com/llm-eff/FedPepTAO.