 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEGSRAL: An Enhanced 3D Gaussian Splatting based Renderer with Automated Labeling for Large-Scale Driving Scene
Dec 20, 2024



3D Gaussian Splatting (3D GS) has gained popularity due to its faster rendering speed and high-quality novel view synthesis. Some researchers have explored using 3D GS for reconstructing driving scenes. However, these methods often rely on various data types, such as depth maps, 3D boxes, and trajectories of moving objects. Additionally, the lack of annotations for synthesized images limits their direct application in downstream tasks. To address these issues, we propose EGSRAL, a 3D GS-based method that relies solely on training images without extra annotations. EGSRAL enhances 3D GS's capability to model both dynamic objects and static backgrounds and introduces a novel adaptor for auto labeling, generating corresponding annotations based on existing annotations. We also propose a grouping strategy for vanilla 3D GS to address perspective issues in rendering large-scale, complex scenes. Our method achieves state-of-the-art performance on multiple datasets without any extra annotation. For example, the PSNR metric reaches 29.04 on the nuScenes dataset. Moreover, our automated labeling can significantly improve the performance of 2D/3D detection tasks. Code is available at https://github.com/jiangxb98/EGSRAL.
Fast Occupancy Network
Dec 10, 2024Occupancy Network has recently attracted much attention in autonomous driving. Instead of monocular 3D detection and recent bird's eye view(BEV) models predicting 3D bounding box of obstacles, Occupancy Network predicts the category of voxel in specified 3D space around the ego vehicle via transforming 3D detection task into 3D voxel segmentation task, which has much superiority in tackling category outlier obstacles and providing fine-grained 3D representation. However, existing methods usually require huge computation resources than previous methods, which hinder the Occupancy Network solution applying in intelligent driving systems. To address this problem, we make an analysis of the bottleneck of Occupancy Network inference cost, and present a simple and fast Occupancy Network model, which adopts a deformable 2D convolutional layer to lift BEV feature to 3D voxel feature and presents an efficient voxel feature pyramid network (FPN) module to improve performance with few computational cost. Further, we present a cost-free 2D segmentation branch in perspective view after feature extractors for Occupancy Network during inference phase to improve accuracy. Experimental results demonstrate that our method consistently outperforms existing methods in both accuracy and inference speed, which surpasses recent state-of-the-art (SOTA) OCCNet by 1.7% with ResNet50 backbone with about 3X inference speedup. Furthermore, our method can be easily applied to existing BEV models to transform them into Occupancy Network models.
DiP-GO: A Diffusion Pruner via Few-step Gradient Optimization
Oct 22, 2024



Diffusion models have achieved remarkable progress in the field of image generation due to their outstanding capabilities. However, these models require substantial computing resources because of the multi-step denoising process during inference. While traditional pruning methods have been employed to optimize these models, the retraining process necessitates large-scale training datasets and extensive computational costs to maintain generalization ability, making it neither convenient nor efficient. Recent studies attempt to utilize the similarity of features across adjacent denoising stages to reduce computational costs through simple and static strategies. However, these strategies cannot fully harness the potential of the similar feature patterns across adjacent timesteps. In this work, we propose a novel pruning method that derives an efficient diffusion model via a more intelligent and differentiable pruner. At the core of our approach is casting the model pruning process into a SubNet search process. Specifically, we first introduce a SuperNet based on standard diffusion via adding some backup connections built upon the similar features. We then construct a plugin pruner network and design optimization losses to identify redundant computation. Finally, our method can identify an optimal SubNet through few-step gradient optimization and a simple post-processing procedure. We conduct extensive experiments on various diffusion models including Stable Diffusion series and DiTs. Our DiP-GO approach achieves 4.4 x speedup for SD-1.5 without any loss of accuracy, significantly outperforming the previous state-of-the-art methods.
Sparse Laneformer
Apr 11, 2024
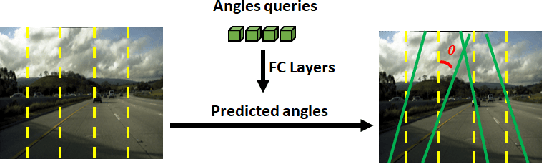


Lane detection is a fundamental task in autonomous driving, and has achieved great progress as deep learning emerges. Previous anchor-based methods often design dense anchors, which highly depend on the training dataset and remain fixed during inference. We analyze that dense anchors are not necessary for lane detection, and propose a transformer-based lane detection framework based on a sparse anchor mechanism. To this end, we generate sparse anchors with position-aware lane queries and angle queries instead of traditional explicit anchors. We adopt Horizontal Perceptual Attention (HPA) to aggregate the lane features along the horizontal direction, and adopt Lane-Angle Cross Attention (LACA) to perform interactions between lane queries and angle queries. We also propose Lane Perceptual Attention (LPA) based on deformable cross attention to further refine the lane predictions. Our method, named Sparse Laneformer, is easy-to-implement and end-to-end trainable. Extensive experiments demonstrate that Sparse Laneformer performs favorably against the state-of-the-art methods, e.g., surpassing Laneformer by 3.0% F1 score and O2SFormer by 0.7% F1 score with fewer MACs on CULane with the same ResNet-34 backbone.
UPDP: A Unified Progressive Depth Pruner for CNN and Vision Transformer
Jan 12, 2024Traditional channel-wise pruning methods by reducing network channels struggle to effectively prune efficient CNN models with depth-wise convolutional layers and certain efficient modules, such as popular inverted residual blocks. Prior depth pruning methods by reducing network depths are not suitable for pruning some efficient models due to the existence of some normalization layers. Moreover, finetuning subnet by directly removing activation layers would corrupt the original model weights, hindering the pruned model from achieving high performance. To address these issues, we propose a novel depth pruning method for efficient models. Our approach proposes a novel block pruning strategy and progressive training method for the subnet. Additionally, we extend our pruning method to vision transformer models. Experimental results demonstrate that our method consistently outperforms existing depth pruning methods across various pruning configurations. We obtained three pruned ConvNeXtV1 models with our method applying on ConvNeXtV1, which surpass most SOTA efficient models with comparable inference performance. Our method also achieves state-of-the-art pruning performance on the vision transformer model.
Separated RoadTopoFormer
Jul 04, 2023Understanding driving scenarios is crucial to realizing autonomous driving. Previous works such as map learning and BEV lane detection neglect the connection relationship between lane instances, and traffic elements detection tasks usually neglect the relationship with lane lines. To address these issues, the task is presented which includes 4 sub-tasks, the detection of traffic elements, the detection of lane centerlines, reasoning connection relationships among lanes, and reasoning assignment relationships between lanes and traffic elements. We present Separated RoadTopoFormer to tackle the issues, which is an end-to-end framework that detects lane centerline and traffic elements with reasoning relationships among them. We optimize each module separately to prevent interaction with each other and aggregate them together with few finetunes. For two detection heads, we adopted a DETR-like architecture to detect objects, and for the relationship head, we concat two instance features from front detectors and feed them to the classifier to obtain relationship probability. Our final submission achieves 0.445 OLS, which is competitive in both sub-task and combined scores.