 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecover-LoRA for Aggressive Quantization: Reclaiming Accuracy in 2-Bit Language Models via Low-Rank Adaptation with Knowledge Distillation on Synthetic Data
Jun 02, 2026Aggressive weight quantization to 2-bit precision offers substantial throughput and memory gains for large language model (LLM) inference, but typically incurs severe accuracy degradation. These gains are particularly relevant for edge and on-device deployment, where memory capacity and bandwidth are primary constraints. In this work, we extend Recover-LoRA -- a lightweight, data-free accuracy recovery method originally developed for general model weight corruption -- to the setting of ultra-low-bit quantization. We propose a selective mixed-precision strategy in which only gate and up projection layers of the MLP are quantized to 2-bit (W2), while all other linear layers remain at higher precision, yielding a mixed-precision GateUp configuration. We demonstrate via roofline analysis across three model families (4B--20B) and two hardware platforms that a W4/W2-GateUp deployment (4-bit base with 2-bit gate/up) delivers 7.5--23.3\% TPS improvement over uniform W4 depending on model and context length, while confining quantization error to a predictable subset of layers. We then apply Recover-LoRA -- training low-rank adapters on the quantized layers via logit distillation with synthetic data -- to recover accuracy lost from 2-bit quantization of the gate and up layers. In a case study on Qwen3-4B, Recover-LoRA achieves 80--95\% accuracy recovery on 9 of 12 benchmarks, using only 10k synthetic training samples and no labeled data. We further demonstrate that synthetic data performs comparably to curated labeled data for distillation-based recovery, and that recovery generalizes to out-of-distribution evaluation tasks. Our results present Recover-LoRA as a practical post-quantization accuracy recovery tool for aggressive weight compression in deployment settings.
Privatar: Scalable Privacy-preserving Multi-user VR via Secure Offloading
Apr 19, 2026Multi-user virtual reality enables immersive interaction. However, rendering avatars for numerous participants on each headset incurs prohibitive computational overhead, limiting scalability. We introduce a framework, Privatar, to offload avatar reconstruction from headset to untrusted devices within the same local network while safeguarding attacks against adversaries capable of intercepting offloaded data. Privatar's key insight is that domain-specific knowledge of avatar reconstruction enables provably private offloading at minimal cost. (1) System level. We observe avatar reconstruction is frequency-domain decomposable via BDCT with negligible quality drop, and propose Horizontal Partitioning (HP) to keep high-energy frequency components on-device and offloads only low-energy components. HP offloads local computation while reducing information leakage to low-energy subsets only. (2) Privacy level. For individually offloaded, multi-dimensional signals without aggregation, worst-case local Differential Privacy requires prohibitive noise, ruining utility. We observe users' expression statistical distribution are slowly changing over time and trackable online, and hence propose Distribution-Aware Minimal Perturbation. DAMP minimizes noise based on each user's expression distribution to significantly reduce its effects on utility, retaining formal privacy guarantee. Combined, HP provides empirical privacy against expression identification attacks. DAMP further augments it to offer a formal guarantee against arbitrary adversaries. On a Meta Quest Pro, Privatar supports 2.37x more concurrent users at 6.5% higher reconstruction loss and 9% energy overhead, providing a better throughout-loss Pareto frontier over quantization, sparsity and local construction baselines. Privatar provides both provable privacy guarantee and stays robust against both empirical and NN-based attacks.
SDFP: Speculative Decoding with FIT-Pruned Models for Training-Free and Plug-and-Play LLM Acceleration
Feb 05, 2026Large language models (LLMs) underpin interactive multimedia applications such as captioning, retrieval, recommendation, and creative content generation, yet their autoregressive decoding incurs substantial latency. Speculative decoding reduces latency using a lightweight draft model, but deployment is often limited by the cost and complexity of acquiring, tuning, and maintaining an effective draft model. Recent approaches usually require auxiliary training or specialization, and even training-free methods incur costly search or optimization. We propose SDFP, a fully training-free and plug-and-play framework that builds the draft model via Fisher Information Trace (FIT)-based layer pruning of a given LLM. Using layer sensitivity as a proxy for output perturbation, SDFP removes low-impact layers to obtain a compact draft while preserving compatibility with the original model for standard speculative verification. SDFP needs no additional training, hyperparameter tuning, or separately maintained drafts, enabling rapid, deployment-friendly draft construction. Across benchmarks, SDFP delivers 1.32x-1.5x decoding speedup without altering the target model's output distribution, supporting low-latency multimedia applications.
DiP-GO: A Diffusion Pruner via Few-step Gradient Optimization
Oct 22, 2024



Diffusion models have achieved remarkable progress in the field of image generation due to their outstanding capabilities. However, these models require substantial computing resources because of the multi-step denoising process during inference. While traditional pruning methods have been employed to optimize these models, the retraining process necessitates large-scale training datasets and extensive computational costs to maintain generalization ability, making it neither convenient nor efficient. Recent studies attempt to utilize the similarity of features across adjacent denoising stages to reduce computational costs through simple and static strategies. However, these strategies cannot fully harness the potential of the similar feature patterns across adjacent timesteps. In this work, we propose a novel pruning method that derives an efficient diffusion model via a more intelligent and differentiable pruner. At the core of our approach is casting the model pruning process into a SubNet search process. Specifically, we first introduce a SuperNet based on standard diffusion via adding some backup connections built upon the similar features. We then construct a plugin pruner network and design optimization losses to identify redundant computation. Finally, our method can identify an optimal SubNet through few-step gradient optimization and a simple post-processing procedure. We conduct extensive experiments on various diffusion models including Stable Diffusion series and DiTs. Our DiP-GO approach achieves 4.4 x speedup for SD-1.5 without any loss of accuracy, significantly outperforming the previous state-of-the-art methods.
Enhancing One-shot Pruned Pre-trained Language Models through Sparse-Dense-Sparse Mechanism
Aug 20, 2024



Pre-trained language models (PLMs) are engineered to be robust in contextual understanding and exhibit outstanding performance in various natural language processing tasks. However, their considerable size incurs significant computational and storage costs. Modern pruning strategies employ one-shot techniques to compress PLMs without the need for retraining on task-specific or otherwise general data; however, these approaches often lead to an indispensable reduction in performance. In this paper, we propose SDS, a Sparse-Dense-Sparse pruning framework to enhance the performance of the pruned PLMs from a weight distribution optimization perspective. We outline the pruning process in three steps. Initially, we prune less critical connections in the model using conventional one-shot pruning methods. Next, we reconstruct a dense model featuring a pruning-friendly weight distribution by reactivating pruned connections with sparse regularization. Finally, we perform a second pruning round, yielding a superior pruned model compared to the initial pruning. Experimental results demonstrate that SDS outperforms the state-of-the-art pruning techniques SparseGPT and Wanda under an identical sparsity configuration. For instance, SDS reduces perplexity by 9.13 on Raw-Wikitext2 and improves accuracy by an average of 2.05% across multiple zero-shot benchmarks for OPT-125M with 2:4 sparsity.
Towards Scale-Aware Full Surround Monodepth with Transformers
Jul 15, 2024



Full surround monodepth (FSM) methods can learn from multiple camera views simultaneously in a self-supervised manner to predict the scale-aware depth, which is more practical for real-world applications in contrast to scale-ambiguous depth from a standalone monocular camera. In this work, we focus on enhancing the scale-awareness of FSM methods for depth estimation. To this end, we propose to improve FSM from two perspectives: depth network structure optimization and training pipeline optimization. First, we construct a transformer-based depth network with neighbor-enhanced cross-view attention (NCA). The cross-attention modules can better aggregate the cross-view context in both global and neighboring views. Second, we formulate a transformer-based feature matching scheme with progressive training to improve the structure-from-motion (SfM) pipeline. That allows us to learn scale-awareness with sufficient matches and further facilitate network convergence by removing mismatches based on SfM loss. Experiments demonstrate that the resulting Scale-aware full surround monodepth (SA-FSM) method largely improves the scale-aware depth predictions without median-scaling at the test time, and performs favorably against the state-of-the-art FSM methods, e.g., surpassing SurroundDepth by 3.8% in terms of accuracy at delta<1.25 on the DDAD benchmark.
Sparse Laneformer
Apr 11, 2024
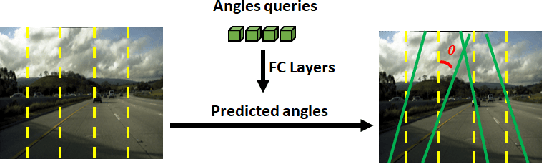


Lane detection is a fundamental task in autonomous driving, and has achieved great progress as deep learning emerges. Previous anchor-based methods often design dense anchors, which highly depend on the training dataset and remain fixed during inference. We analyze that dense anchors are not necessary for lane detection, and propose a transformer-based lane detection framework based on a sparse anchor mechanism. To this end, we generate sparse anchors with position-aware lane queries and angle queries instead of traditional explicit anchors. We adopt Horizontal Perceptual Attention (HPA) to aggregate the lane features along the horizontal direction, and adopt Lane-Angle Cross Attention (LACA) to perform interactions between lane queries and angle queries. We also propose Lane Perceptual Attention (LPA) based on deformable cross attention to further refine the lane predictions. Our method, named Sparse Laneformer, is easy-to-implement and end-to-end trainable. Extensive experiments demonstrate that Sparse Laneformer performs favorably against the state-of-the-art methods, e.g., surpassing Laneformer by 3.0% F1 score and O2SFormer by 0.7% F1 score with fewer MACs on CULane with the same ResNet-34 backbone.
UPDP: A Unified Progressive Depth Pruner for CNN and Vision Transformer
Jan 12, 2024Traditional channel-wise pruning methods by reducing network channels struggle to effectively prune efficient CNN models with depth-wise convolutional layers and certain efficient modules, such as popular inverted residual blocks. Prior depth pruning methods by reducing network depths are not suitable for pruning some efficient models due to the existence of some normalization layers. Moreover, finetuning subnet by directly removing activation layers would corrupt the original model weights, hindering the pruned model from achieving high performance. To address these issues, we propose a novel depth pruning method for efficient models. Our approach proposes a novel block pruning strategy and progressive training method for the subnet. Additionally, we extend our pruning method to vision transformer models. Experimental results demonstrate that our method consistently outperforms existing depth pruning methods across various pruning configurations. We obtained three pruned ConvNeXtV1 models with our method applying on ConvNeXtV1, which surpass most SOTA efficient models with comparable inference performance. Our method also achieves state-of-the-art pruning performance on the vision transformer model.
Separated RoadTopoFormer
Jul 04, 2023Understanding driving scenarios is crucial to realizing autonomous driving. Previous works such as map learning and BEV lane detection neglect the connection relationship between lane instances, and traffic elements detection tasks usually neglect the relationship with lane lines. To address these issues, the task is presented which includes 4 sub-tasks, the detection of traffic elements, the detection of lane centerlines, reasoning connection relationships among lanes, and reasoning assignment relationships between lanes and traffic elements. We present Separated RoadTopoFormer to tackle the issues, which is an end-to-end framework that detects lane centerline and traffic elements with reasoning relationships among them. We optimize each module separately to prevent interaction with each other and aggregate them together with few finetunes. For two detection heads, we adopted a DETR-like architecture to detect objects, and for the relationship head, we concat two instance features from front detectors and feed them to the classifier to obtain relationship probability. Our final submission achieves 0.445 OLS, which is competitive in both sub-task and combined scores.
XRBench: An Extended Reality (XR) Machine Learning Benchmark Suite for the Metaverse
Nov 16, 2022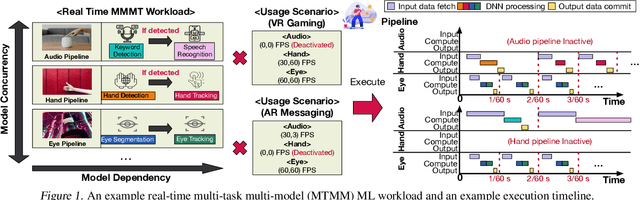
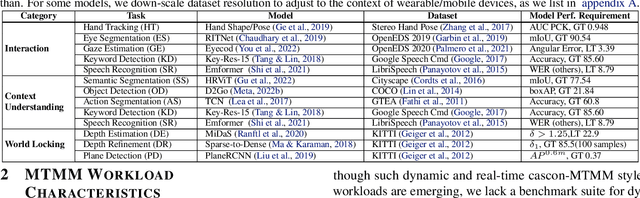

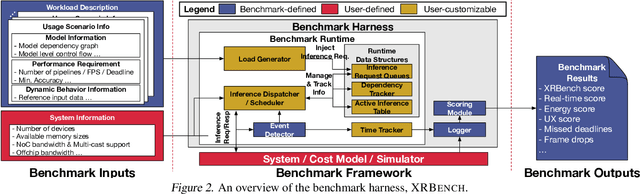
Real-time multi-model multi-task (MMMT) workloads, a new form of deep learning inference workloads, are emerging for applications areas like extended reality (XR) to support metaverse use cases. These workloads combine user interactivity with computationally complex machine learning (ML) activities. Compared to standard ML applications, these ML workloads present unique difficulties and constraints. Real-time MMMT workloads impose heterogeneity and concurrency requirements on future ML systems and devices, necessitating the development of new capabilities. This paper begins with a discussion of the various characteristics of these real-time MMMT ML workloads and presents an ontology for evaluating the performance of future ML hardware for XR systems. Next, we present XRBench, a collection of MMMT ML tasks, models, and usage scenarios that execute these models in three representative ways: cascaded, concurrent, and cascaded-concurrency for XR use cases. Finally, we emphasize the need for new metrics that capture the requirements properly. We hope that our work will stimulate research and lead to the development of a new generation of ML systems for XR use cases.